基于AOF-LCNN的语音回放攻击场景下的说话人识别算法
2020-12-18蔡晓东侯珍珍
李 波,蔡晓东,侯珍珍,陈 思
(桂林电子科技大学 信息与通信学院,广西 桂林 541004)
说话人识别因为语音获取方便、成本低廉以及支持远程识别,在安防、金融和生活上发挥了重要作用。但因为声音容易被高保真设备录音,会导致说话人识别系统的安全性受到极大威胁,这就是回放语音攻击。语音回放攻击不需要专业手段,只需要一个录音设备即可,获取录音的成本低廉,获取方便,因此语音回放攻击成为说话人识别领域一个巨大的挑战。为了应对这种挑战,一般从2个方面着手:1)改进信号层面特征;2)改进模型。
一般信号层面的特征有如下几种:梅尔倒谱系数(mel frequency cepstrum coefficient,简称MFCC)[1],constant Q transform,简称CQT[2],constant Q cepstral coefficients,简称CQCC[3],fast fourier transformation,简称FFT。梅尔倒谱系数被广泛使用于各种语音场景,如语音识别、说话人识别、语言识别等。而CQT特征则被用来检测各种语音攻击场景,起到了非常好的效果。CQCC特征在语音攻击场景下也是使用广泛的一种特征,它最先被使用于基于语音合成和声音变换的语音攻击场景,后被使用于语音回放攻击场景。FFT特征是对一段语音进行时频变换得到的语谱图,其特征信息较为全面,适合作为神经网络训练的输入特征。本研究采用的信号层面特征为FFT特征。
在模型层面上,传统模型如高斯混合模型(gaussian mixture model,简称GMM)[4],采用2个高斯混合模型分别对真实语音和回放语音进行建模,再利用支持向量机(support vector machine,简称SVM)作为分类器,可取得不错的效果。随着深度学习技术的兴起,深度神经网络(deep neural networks,简称DNN)[5]被用来作为特征提取器对语音样本进行特征提取,通过训练可以对真实语音及回放语音进行分类。更进一步,随着卷积神经网络(convolutional neural networks,简称CNN)[6]在图像识别领域出色的表现,CNN被引入说话人识别领域,并针对语音回放攻击场景下的说话人识别取得了很好的效果。在ASVspoof 2017挑战赛中,基于最大特征图(max-feature-map,简称MFM)[7]结构的 (light convolutional neural networks,简称LCNN)[8]网络的性能取得了不错的效果。
但LCNN网络结构中存在一个问题,容易导致过拟合。针对该问题,提出一种基于 (anti overfitting-light convolutional neural networks,简称AOF-LCNN)的端到端神经网络。首先,设计了一个新的DNN结构分类器作为后端分类网络,将该DNN结构级联在LCNN网络之后,形成一套新的端到端网络结构;其次,因为LCNN结构中的MFM结构可能是造成过拟合的原因,因此在DNN后端结构中采用LeakyReLU作为激活函数,以抵消MFM的过拟合影响。
提出的网络结构主要思路如下:
1)提出的在LCNN网络结构后级联本设计的新的DNN架构,可形成一个新的端到端网络结构,从而可以联合优化,不用分别优化局部模块,因此达到全局最优;
2)设计新的DNN网络后端分类模块,可作为一个良好的分类器将LCNN提取的特征进行分类,可以得到更好的分类结果;
3)在DNN中采用LeakyReLU作为激活函数,可抵消可能由MFM结构带来的过拟合影响。
1 LCNN端到端系统
LCNN系统[8]是一种使用了最大特征图[7]激活函数的CNN网络结构。最大特征图激活函数定义为:
∀i=1~H,j=1~W,k=1~N/2。
(1)
其中:x是尺寸为H×W×N的输入;y是尺寸为H×W×N/2的输出;i、j为时间域和频率域指数;k为信道指数。相对于ReLU激活函数,最大特征图激活函数使用了一个阈值来抑制神经元,从而形成神经元之间的竞争关系,因此最大特征图是一个特征选择器。
LCNN[8]结构包含了5个卷积层,4个NIN(network in network)层[9],10个最大特征图层,4个最大池化层和2个全连接层。
在LCNN系统中,最大特征图激活函数用来计算卷积层后每2个信道元素级别的最大值。在整个网络中,使用最大池化层在时间和频率维度进行降维。最大池化层的卷积核尺寸为2×2,步长为2。全连接层FC6的作用是将信号转化为一个低维高级别特征表示。全连接层FC7是一个softmax分类层,用来区分真实语音和回放语音。
2 AOF-LCNN网络结构
在LCNN网络结构中存在过拟合的问题,提出一种基于AOF-LCNN的网络结构以解决该问题。因为LCNN结构中的最大特征图结构可能是导致过拟合的主要原因,在保留最大特征图结构的情况下,使用LeakyReLU对系统进行补偿,从而减轻过拟合的影响。因此,AOF-LCNN系统中,首先,设计了一个新的DNN结构分类器作为后端分类网络,将该DNN结构级联在LCNN网络之后,形成一套新的端到端网络结构;其次,因为LCNN结构中的最大特征图结构可能是造成过拟合的原因,因此在DNN后端结构中采用LeakyReLU作为激活函数,以抵消MFM的过拟合影响。
AOF-LCNN网络结构如图1所示。图1中:Conv为卷积层;MFM为最大特征图激活层;Maxpool为最大池化层;FC为全连接层。在AOF-LCNN网络结构的前端部分,与LCNN网络结构基本保持一致,区别在于其少了一个全连接层FC7,其结构为第一个卷积层后连接了4个卷积块,其中每个卷积块之间通过最大池化层连接,最后连接了一个全连接层,以生成语音的特征表示。在每个卷积层和卷积块中,均以最大特征图作为激活函数,称为MFM层,其使用在每个卷积层后。其中,在第一个卷积层中,采用卷积核尺寸为5×5,步长为1×1,第一个MFM层的通道数为16。在其后的每个卷积块中,含有2个卷积层和2个MFM层,其卷积层a的卷积核尺寸均为1×1,步长均为1×1,卷积层b的卷积核尺寸均为3×3,步长均为1×1。在每个卷积块中,第一个卷积层后的MFM层,其通道数跟前一个卷积层后的MFM层通道数保持一致,第二个卷积层后的MFM层的通道数分别为24,32,16,16。其中每个最大池化层的卷积核尺寸为2×2,步长为2×2。

图1 AOF-LCNN网络结构
DNN后端结构由5个全连接层构成,每个全连接层的节点数为1 024。输入尺寸为256,输出尺寸为2,分别表示真实语音和回放语音。采用LeakyReLU作为激活函数,并对每层采用批归一化操作和Dropout(随机丢弃),随机丢弃率为0.5。
3 实验结果及分析
3.1 数据集和实验配置
3.1.1 数据集
本实验采用的数据集来自于ASVspoof 2017挑战赛,该数据集中包含3个部分:Train、Dev和Eval。其中Train部分是为了训练模型,Dev数据集是为了验证性能和调参,而Eval部分不同于Train和Dev部分,其包含了新的说话人、环境、回放录音设备以及新的攻击形式。因此,系统的性能主要体现在Eval部分的测试结果,其反映了系统的泛化性能。
3.1.2 实验配置
本实验采用的数据集的语音按照每帧25 ms,10 ms帧移进行分帧,每个语音文件生成一个FFT语谱图,其中语谱图横轴为时间帧数,纵轴为频率,其尺寸为864×400,其中语音文件长短不一,若帧数小于400帧,则通过补零方式处理,若大于400帧,则通过截断方式处理。在AOF-LCNN网络中,随机丢弃率为0.5,优化器为Adam,其中学习率设置为0.007 5,损失函数采用交叉熵损失。
3.2 基线系统
ASVspoof 2017挑战赛官方给出的基线系统是高斯混合模型(gaussian mixture model,简称GMM)[8],其使用了29维的CQCC特征及其一阶微分及二阶微分作为输入特征,后端模型部分采用了2个GMM模型,这2个模型使用EM(expectation maximization)算法和随机初始化方法分别针对真实语音和回放语音进行训练。
3.3 实验结果
将LCNN网络与AOF-LCNN网络结构分别在ASVspoof 2017数据集上开展实验,得到的实验结果及基线系统GMM的结果对比如表1所示,其DET(detection error tradeoff)曲线如图2及图3所示。
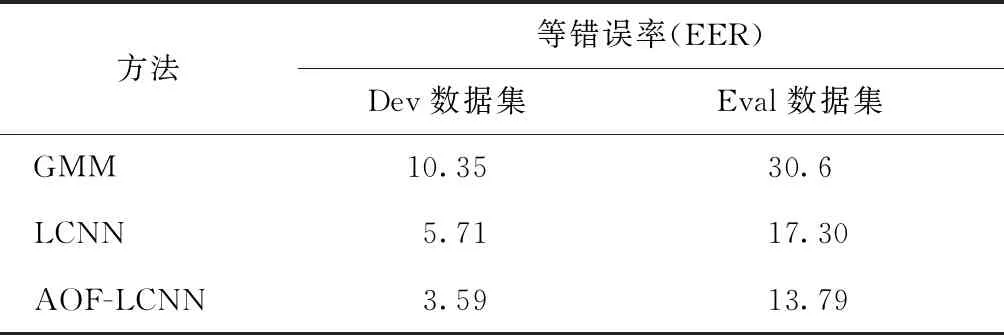
表1 本方法与基线方法实验结果对比 %
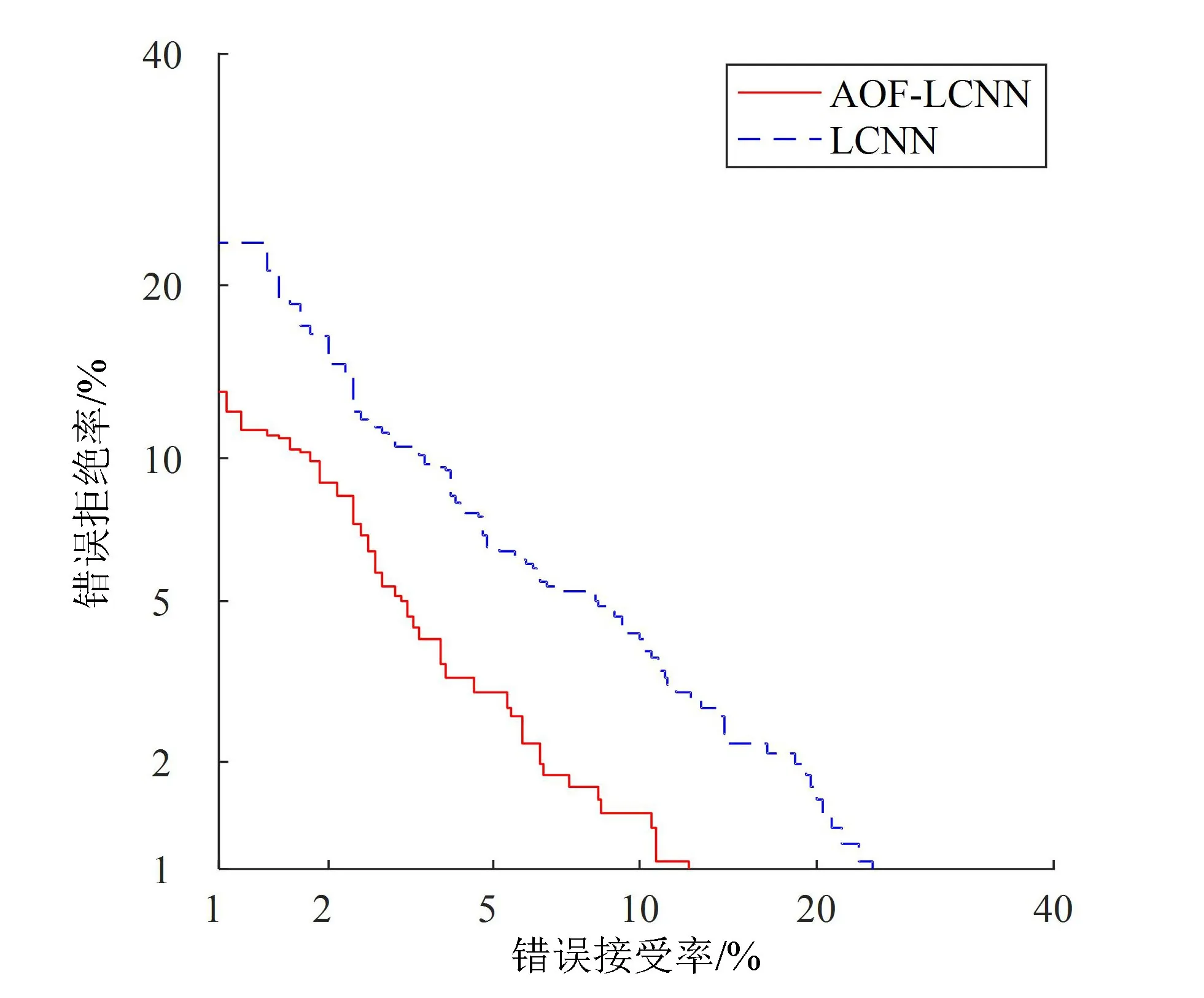
图2 Dev数据集上DET曲线对比图
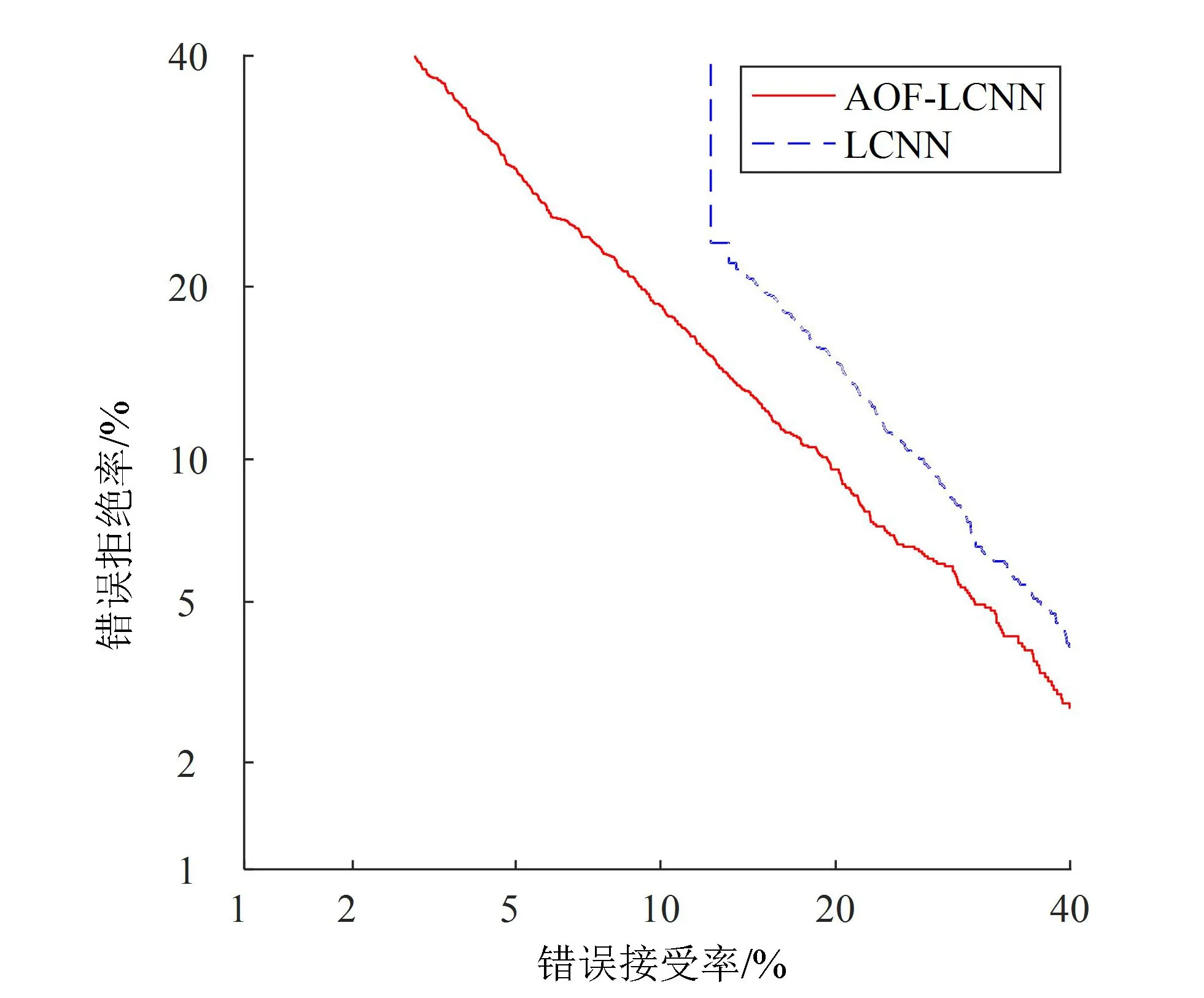
图3 Eval数据集上DET曲线对比图
从表1可知,AOF-LCNN方法在Dev数据集上得到的等错误率为3.59%,比ASVspoof 2017挑战赛官方提供的基线系统方法GMM降低了6.76%,比对标系统LCNN方法降低了2.12%。在Eval数据集上,本方法得到的等错误率为13.79%,比GMM方法降低了16.81%,比LCNN方法降低了3.51%。由图2和图3的DET曲线可知,在Dev和Eval数据集上,本方法得到的DET曲线均处于LCNN系统的下方。
3.4 实验结果分析
从实验结果可知,本方法在Dev数据集上相对于LCNN系统和GMM系统有了较大提高,同样,在Eval数据集上也表现了出色的性能,有了较大提高。而Dev数据集中的说话人和Train数据集中保持一致,且场景相似,在此数据集上本方法的等错误率相对于比赛官方提供的基线系统降低了6.76%,相对于LCNN方法对基线系统降低的等错误率,有了非常大的提高。而在添加了大量无关说话人和变换场景的Eval数据集上,LCNN系统表现较差,表现出了强烈的过拟合,而本方法在Eval数据集上的表现较为出色,相对于LCNN系统在等错误率上降低了3.51%,改善了过拟合,也表现了较好的鲁棒性。
4 结束语
提出一种基于AOF-LCNN网络结构的语音回放攻击场景下的说话人识别方法,以区分真实语音和回放语音。在ASVspoof 2017挑战赛数据集上的结果显示,提出的基于AOF-LCNN网络结构的方法在Dev数据集上的性能要显著优于LCNN系统,同时在与训练数据有非常大差异的Eval数据集上也表现出很好的性能,从而说明本方法不仅在等错误率上提高了系统的性能,而且表现出了较好的鲁棒性。在本研究中,只针对神经网络中存在的问题进行了探究,下一步可在信号层面特征上做更深入的研究。
