基于深度学习利用特征图加权融合的目标检测方法
2020-12-18张世辉王红蕾陈宇翔刘新焕任卫东
张世辉,王红蕾,陈宇翔,刘新焕, 张 健,何 欢,任卫东
(1.燕山大学信息科学与工程学院,河北秦皇岛066004;2.河北省计算机虚拟技术与系统集成 重点实验室,河北秦皇岛066004;3.北京计算机技术及应用研究所,北京100854)
1 引 言
近年来,目标检测成为大量高级视觉任务的必要组成部分,如视觉测量、人数统计、舆情监控、智能交通、场景内容理解等[1~5],因此相关领域的诸多学者致力于目标检测方法的研究,并不断提出新的目标检测方法。
现有的目标检测方法可分为传统的检测方法和基于深度学习的检测方法两大类。传统的目标检测方法主要通过提取Harr、HOG(histogram of oriented gradient)等[6~8]特征,用AdaBoost、SVM(support vector machine)等[9~11]对特征进行分类进而实现目标检测。这些传统方法使用的是人工设计的特征,某些情况下的检测效果与实际需求有一定的差距。基于深度学习的目标检测方法使用的是卷积神经网络(convolutional neural network,CNN)自动提取的特征。其中,文献[12]提出使用SS(selective search)[13]获取区域建议并使用CNN提取区域建议特征的R-CNN方法;文献[14]提出使用SS获取区域建议并利用SPP(spatial pyramid pooling)网络提取区域建议特征的SPP-net方法;文献[15]提出先用CNN提取整幅图像的特征,然后通过映射得到区域建议特征的Fast R-CNN方法;文献[16]提出使用CNN提取图像特征并用RPN(region proposal networks)网络获取区域建议的Faster R-CNN方法;文献[17]提出利用卷积核预测不同尺度卷积层上目标边界框的类别分数和偏移量的SSD方法;文献[18]提出通过将特征图划分为S×S的格子而得到目标的边界框、定位置信度及类别概率向量的YOLO方法。上述文献[12~16,18]中均使用CNN提取输入图像的特征,且都利用了CNN所提取的特征图中最深层的特征图,但均未利用浅层的特征图;文献[17]虽然利用多尺度特征图进行目标检测,但目标检测的精度有待提高。通过分析卷积神经网络提取的各层次特征图的特点发现,浅层的特征图包含更多细节性的特征,有利于提高目标的检测精度。现有的基于卷积神经网络的目标检测方法中,一部分利用卷积神经网络产生的最深层特征图进行目标检测,另一部分是将深层特征图上采样后与浅层特征图进行等权重(即权重比值为1)融合,这部分方法虽然提高了目标检测精度,但会令融合后用于后续网络层的特征图维度变大,从而使计算量增加,同时也不利于目标检测的实时性。综合考虑上述内容,本文提出将卷积神经网络产生的浅层特征图采样后与最深层特征图进行加权融合的思想,并将该思想用于目标检测,以提高目标检测的精度。
2 方法概述
目标检测就是对图像中数目不定的目标进行定位和分类,定位即确定图像中目标的具体位置并以边界框的形式标出目标位置,分类即确定图像中目标是什么类别。
本文所提目标检测方法的总体思想:首先,利用卷积神经网络提取输入图像的特征并得到一系列处于不同层次的特征图;其次,基于特征图加权融合思想并结合用于提取图像特征的卷积神经网络的结构特点确定需要融合的浅层特征图及融合方法;然后,将由特征图加权融合得到的新特征图输入到改进的RPN网络中得到包含更多面积种类的区域建议;最后,将新特征图和区域建议输入到ROI Pooling层中,得到区域建议特征并用Softmax对特征进行分类,从而实现目标检测。总体流程见图1所示。

图1 目标检测总体流程Fig.1 The overall process of object detection
3 基于特征图加权融合的目标检测法
3.1 特征图加权融合思想的提出
生活中,人们可以快速准确地完成对图像中的目标进行检测的任务。但是,若让计算机完成目标检测任务则首先需要通过一定的方法提取图像特征,然后对特征进行分类才能完成目标检测,且检测过程中所用的图像特征直接影响着目标检测的效果。
现有的基于深度学习的目标检测方法中,主要通过卷积神经网络提取图像特征且此过程中会生成一系列处于不同层次的特征图[19,20]。其中,深层的特征图分辨率低、语义信息高;浅层的特征图分辨率高、语义信息低。浅层特征图包含低层的、细节性的特征,有利于提高目标的检测精度。
综合考虑由卷积层产生的特征图的上述特点,本文提出将卷积神经网络产生的浅层特征图与最深层特征图进行加权融合的思想。
图2展示了具有n个卷积层的卷积神经网络结构图,由于不同的卷积神经网络中下采样层的位置和数量各不相同,且用于融合的特征图均由卷积层产生,故该图中暂时未考虑下采样层。由图2可知,卷积神经网络提取图像特征的过程中,每个卷积层产生的特征图的大小即长×宽×通道数(W×H×D)不完全相同,且一般情况下最深层特征图的大小小于浅层特征图,因此,利用特征图加权融合思想进行特征图融合时,需要对浅层特征图进行采样,以使其与最深层特征图的大小相同。在特征图加权融合过程中,虽然需要对浅层特征图进行采样,但是该采样过程是一次性将浅层特征图转换到最深层特征图的大小,并不是像最深层特征图一样由浅层特征图经过多次卷积与下采样得到,因此采样后的浅层特征图仍包含较多的细节性特征。考虑到目标检测方法不仅需要较高的检测精度,还需要较快的检测速度,而随着融合的浅层特征图数的增加目标检测速度也会下降,因此,在确定要融合的浅层特征图时要根据具体情况而定。

图2 卷积神经网络中特征图融合示意图Fig.2 The sketch map of feature map fusion in CNN
3.2 特征图加权融合方法的确定
由上述特征图加权融合思想可知,在确定要融合的浅层特征图时需要综合考虑精度和速度,因此不同结构的卷积神经网络要融合的浅层特征图的层数并不相同,且特征图加权融合的具体方案也会因网络结构的不同而存在差异。鉴于目前常用的卷积神经网络主要为LeNet-5、AlexNet、ZFNet、GoogLeNet和VGGNet等,且现有的经典目标检测方法中大多数以VGGNet(VGG网络)为基础实现,为了与已有方法进行对比,也为了体现所提目标检测方法的普适性,本文目标检测任务的实现仍以VGGNet为基础。
目标检测过程中,用VGG网络中的前13个卷积层(Conv)和前4个下采样层(max pooling)提取图像特征,见图3所示。其中,4个下采样层可以把13个卷积层分为5个卷积阶段,每个阶段中最后一个卷积层产生的特征图表达能力最强,且特征图每经过一次下采样得到的特征图的长宽都会缩减为上一阶段特征图长宽的1/2。若输入到VGG网络中的图像长宽为w×h,则经过4次下采样后所得特征图的长宽为(w/16)×(h/16)。VGG网络中同一个阶段的卷积层产生的特征图间的差别小于不同阶段的卷积层产生的特征图间的差别,因此在VGG网络中的特征图加权融合是在网络的不同阶段间进行的。由于VGG网络产生的不同阶段的特征图大小不同,进行特征图加权融合时需要对浅层特征图进行采样。本文对浅层特征图进行均值下采样(average pooling),其原因有二:一是均值下采样不仅能完成特征图降维,还能更多地保留特征的完整性;二是最深层特征图Conv13是由浅层特征图经过最大值下采样等操作生成,此处用均值下采样对浅层特征图进行降维变换,可实现对同一浅层特征图进行两种不同方式的降维,从而使最终获取的特征具有鲁棒性。同时,虽然浅层特征图与最深层特征图融合后有助于提高目标检测精度,但是两者对提高目标检测精度所做的贡献并不相同,因此为不同层次的特征图设置不同的权重。根据上述特征图加权融合思想,结合VGG网络的具体结构特点,仅将VGG中第10层卷积层产生的特征图Conv10与最深层特征图Conv13进行加权融合生成新特征图。在生成新特征图的过程中,用g表示特征图Conv10,G表示降维后的特征图Conv10,则特征图Conv10的均值下采样过程可表示为:
Gi=αifdown(gi)+βi
(1)
式中:Gi表示G中的第i个通道;gi表示g中的第i个通道;fdown(·)为下采样函数;αi表示乘性偏置;βi表示加性偏置。用Fnew表示所得新特征图,g13表示特征图Conv13,则特征图融合可表示为:
(2)
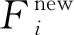

图3 VGG网络特征图加权融合Fig.3 The feature map fusion in VGGNet
3.3 RPN网络的改进
得到新特征图后,需要将新特征图输入到后续的RPN网络中来获取区域建议。为了进一步提升目标检测方法的精度与速度,提出改进的RPN网络:首先,增加RPN网络中候选窗口的面积种类,即在卷积核3×3×512×512经过的每一个位置处生成面积为{64×64,128×128,256×256,512×512}、长宽比为{1:1,1:2,2:1}的12种候选窗口。因为虽然传统的RPN网络会在卷积核3×3×512×512经过的每一个位置处生成面积为{128×128,256×256,512×512}、长宽比为{1:1,1:2,2:1}的9种候选窗口,但是通过增加候选窗口的面积种类,可以使一些待检测目标有更大的几率被包含于候选窗口中,从而提高目标检测的精度。因此,在综合考虑输入图像大小和候选窗口已有面积种类的情况下,增加了面积大小为64×64的候选窗口。其次,降低RPN网络提取的特征维度,即将RPN网络中的卷积核3×3×512×512用3×3×512×128替代。卷积核3×3×512×512在新特征图的每个位置处除了生成候选窗口,还生成一个512-d(512维)向量,并将该向量用于后续计算。由于在RPN网络中新特征图与卷积核3×3×512×512进行卷积后会生成近200个512-d向量,且每一个512-d向量维数较大,因此后续的处理过程计算量较大。为了减小RPN网络中的计算量,提出使用卷积核3×3×512×128来降低提取的特征维度,如图4所示。至此,理论上可以在目标检测过程中得到新特征图和包含更多面积种类的区域建议。

图4 改进的RPN网络Fig.4 Improved RPN network
3.4 目标检测的实现
本文所提目标检测方法本质上是基于深度学习的有监督学习方法,因此该方法中的各层网络(VGG、RPN、ROI Pooling和Softmax等)均需要训练且训练过程是端到端的,故无论采用哪种数据集进行目标检测,都需要将数据集分为训练数据集和测试数据集两部分。其中,训练集用于网络各层的训练,训练所用时间的长短与用于提取图像特征的卷积神经网络和训练集中图像的数量有关。卷积神经网络的层数越多、结构越复杂且训练集中的图像越多时训练所用时间越长。训练过程分为4个阶段:
阶段1:用在ImageNet上的预训练模型对所提目标检测方法中的网络进行初始化,并对改进的RPN网络进行训练,初步确定改进的RPN网络的参数;
阶段2:使用阶段1中训练的RPN网络提取区域建议,对所提目标检测方法中的利用特征图加权融合的VGG、ROI Pooling等进行训练以初步确定参数;
阶段3:利用阶段2训练的VGG、ROI Pooling等对阶段1中RPN网络的参数进行微调,得到微调后的RPN网络,在此过程中阶段2训练的用于提取图像特征的卷积层(VGG卷积层)的参数保持不变;
阶段4:使用阶段3中训练的RPN网络提取的区域建议对阶段2中训练的网络进行微调,同样保持阶段2训练的用于提取图像特征的卷积层(VGG卷积层)的参数不变。至此得到一个完整的用于目标检测的网络模型。
测试集用于对训练好的网络模型进行测试,以获取该网络模型对图像中的目标进行检测的结果以及该网络模型在相应数据集上的目标检测精度。
4 实验及分析
4.1 实验环境及数据集
实验硬件环境为CPU Intel Xeon(R) E5-2620 v4@2.10 GHz×16、内存大小为62.8 GiB、显卡型号NVINIA TITAN Xp以及显存大小为3×12 189 MiB;软件环境为Ubuntu14.0、CUDA-8.0、OpenCV-3.0、MATLAB R2014a、Python2.7和Caffe框架。实验所用的数据集有KITTI、PASCAL VOC2007和PASCAL VOC2012。其中,数据集KITTI中标记出的目标有truck、pedestrian、car、cyclist、tram等8种类别。除了用全部的KITTI数据集中的图像进行多类别目标检测实验外,还用Python程序从数据集KITTI中选取含有车辆目标的6 798张图像(记为数据集KITTI-1)进行单类别目标检测实验。数据集PASCAL VOC2007和VOC2012中标记出的目标有aeroplane,bicycle,bird,boat,bottle,bus,car,cat,chair,dog等20种生活中常见的类别。
4.2 实验结果比较及分析
为了全面、合理地评估所提方法的目标检测效果,本文的实验主要分为两部分进行:第一部分是所提目标检测方法在各种情况下的实验结果及分析;第二部分是所提目标检测方法与已有目标检测方法的比较。实验过程中,确定浅层特征图和最深层特征图的权重分别为0.3和1(即μ=0.3,φ=1),并主要以目标检测的平均精度均值(mean average precision,mAP)、检测一张图像所用时间、精确率(precision)和召回率(recall)作为目标检测效果的衡量标准。其中,目标检测的mAP是多种类别目标检测精度(AP)的平均值,其值介于0~1且越大越好。精确率=(检测出的正确的目标总数/检测出的目标总数)×100%,召回率=(检测出的正确的目标总数/Ground Truth中目标总数)×100%。
4.2.1 所提方法的实验结果及分析
为了验证所提方法的可行性,对所提目标检测方法进行了相关实验。图5展示了所提目标检测方法对数据集KITTI中部分图像进行目标检测的结果。由图5可知, 所提方法能够准确地对图像中的目标进行准确定位与分类。
为了充分地评估所提方法,对所提目标检测方法在不同的特征图加权融合、不同的候选窗口数量以及RPN网络提取不同维度特征时分别进行了实验,实验结果见表1。常用于目标检测的数据集有KITTI,PASCAL VOC2007和PASCAL VOC2012,由于数据集KITTI场景复杂更具挑战性,因此,实验在数据集KITTI上进行多类别目标检测,在数据集KITTI-1上进行单类别目标检测来评估所提方法。其中,在数据集KITTI上检测的目标类别有8种:cyclist,van,tram,car,misc,pedestrian,truck,person_sitting,表1中展示的在数据集KITTI上的目标检测精度均是这8种类别目标检测精度的mAP。为了评估所提方法只检测一种类别目标时的效果,实验过程中选取数据集KITTI中目标总数最多的“car”类作为检测类别,因此在数据集KITTI-1上检测的目标类别只有1种:car,且表1中展示的在数据集KITTI-1上的平均检测精度也是car这一种目标本身的检测精度(AP)。

图5 所提目标检测方法的检测结果Fig.5 The results of the proposed object detection method

表1 不同情况下的目标检测方法在数据集KITTI上的目标检测实验结果Tab.1 Object detection experiment results on dataset KITTI in different situations
由表1可知,当目标检测方法采用特征图加权融合时,通过比较第1、2两种情况可知,目标检测方法的检测精度明显提高了且在两种数据集上分别提高2.22%和5.89%,从而验证了特征图加权融合的可行性;当目标检测方法未采用特征图加权融合时,通过比较表1中第1、3两种情况可知,候选窗口数增加后,目标检测方法的检测精度明显提高,且在两种数据集上分别提高了2.76%和6.2%;同时当目标检测方法采用特征图加权融合时,通过比较表1中第2、4两种情况可知,候选窗口数增加后,目标检测方法的检测精度也明显提高,且在两种数据集上分别提高了2.18%和1.63%,由此验证了增加候选窗口面积种类的可行性;当目标检测方法采用特征图加权融合且在候选窗口数为12时,通过比较表1中第4、5两种情况可知,降低RPN网络提取的特征维度并没有对目标检测精度有明显的影响,从而验证了降低RPN网络提取特征维度的可行性。综上可知,本文所提的目标检测方法具有可行性。
为了验证进行特征图加权融合和改进RPN网络在提高目标检测精度的同时并没有降低目标检测的速度,本文以表1中第1、2、4和5四种情况下的目标检测速度为例,展示了在数据集KITTI上需要检测8种类别目标时检测完成一张图像所用的平均时间,和在数据集KITTI-1上只检测一种类别目标时检测完成一张图像所用的平均时间,具体如表2所示。通过对比分析表2中的数据可知,与未进行特征图加权融合和未改进RPN网络的情况相比,进行特征图加权融合和增加候选窗口面积种类的目标检测方法检测图像的速度几乎没有变化,但在降低RPN网络提取的特征维度后,目标的检测速度有所提高,这进一步验证了本文所提目标检测方法的可行性。

表2 目标检测方法在不同情况下检测一张图像所用的平均时间Tab.2 The average time of object detection method to detect an image in different situations ms
为了清楚地展现本文所提目标检测方法在目标检测过程中精确率和召回率的变化情况,图6给出了表1中第1种情况和第5种情况下,目标检测方法在数据集KITTI-1上进行单类别目标检测时的精确率和召回率的变化情况。
4.2.2 所提方法与已有方法的比较
由于已有的目标检测方法主要基于数据集PASCAL VOC2007和PASCAL VOC2012进行实验,为了便于比较,本文方法也基于数据集PASCAL VOC2007和PASCAL VOC2012进行了实验。表3中给出了文献[13,14,15,16]中4种不同的目标检测方法和本文所提方法在数据集PASCAL VOC2007上的目标检测结果,以及文献[15,16,17,18]中4种不同的目标检测方法和本文所提方法在数据集PASCAL VOC2007+2012上的目标检测结果。

图6 不同情况下目标检测方法的精确率-召回率Fig.6 The precision and recall of the object detection method in different situations
通过对表3中的数据进行比较分析可知,在数据集PASCAL VOC2007上,本文所提方法的目标检测精度高于文献[13,14,15,16]中方法的目标检测精度。在数据集PASCAL VOC2007+2012上,本文所提方法的目标检测精度高于文献[15,16,17,18]中方法的目标检测精度。由此可知,与已有方法相比,本文所提方法的性能较好、精度较高,进一步验证了本文所提方法的可行性和有效性。
表3给出实验结果均是数据集PASCAL VOC2007和VOC2012上多种类别目标检测精度的平均值。为了更充分地验证所提方法的有效性,本文将所提方法在数据集PASCAL VOC2007和VOC2012上的每种类别目标的检测精度与其它方法在相同数据集上的每种类别目标的检测精度进行了比较分析。图7给出了从文献[13~16]中选择出检测精度较高的3种目标检测方法与本文所提方法进行单类别目标检测精度比较。其中,图7中所示的4种方法均是在数据集VOC2007和VOC2012的训练集上进行训练,在数据集VOC2007的测试集上进行测试。

表3 所提方法和其他目标检测方法的比较Tab.3 The comparison of proposed method and other methods

图7 所提方法与其它方法针对不同类别 目标的检测精度比较Fig.7 Comparison between proposed method and other methods for different types of objects
由图7可知,在数据集VOC2007和VOC2012上,本文所提方法对大多数类别的检测精度明显高于文献[15,17]方法的检测精度;而将本文所提方法与文献[16]方法进行比较时发现,两种方法在某些类别上的检测精度虽然相接近,但是所提方法在多数类别上的检测精度高于文献[16]方法,且在“bird”和“bottle”等部分类别上的检测精度明显高于文献[16]方法,从而验证了所提方法的有效性。为了进一步验证所提方法的目标检测精度高于文献[16]方法,本文将两种方法分别在数据集KITTI和KITTI-1上进行了实验,实验结果见表4。
由表4数据可知,无论是在KITTI上进行8种类别的目标检测,还是在KITTI-1上进行1种类别的目标检测,本文所提方法的目标检测精度均明显高于文献[16]方法,从而验证了所提方法的目标检测精度更高,也验证了其有效性。
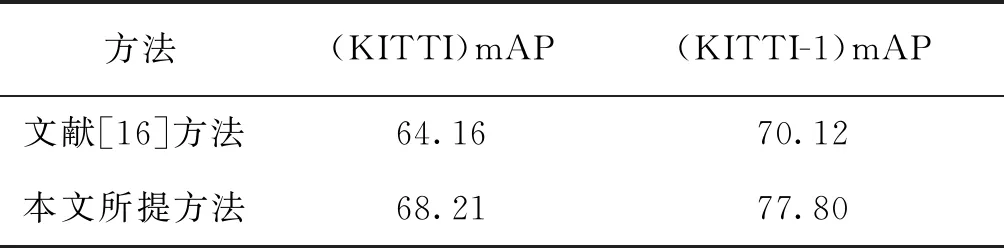
表4 本文方法和文献[16]方法的比较Tab.4 The comparison of proposed method and literature [16] method on dataset KITTI (%)
5 结 论
提出一种基于深度学习利用特征图加权融合实现目标检测的方法。主要贡献:(1) 根据卷积神经网络提取的不同层次特征图的特点,提出将卷积神经网络产生的浅层特征图采样后与最深层特征图进行加权融合的思想,该思想不仅为如何更充分地利用卷积神经网络提取的各层次特征提供了一种思路,而且具有普适性。(2) 根据特征图加权融合思想提出VGG网络进行特征图加权融合的具体方法,并将所提方法用于目标检测任务。与其他目标检测方法相比,本文方法所提取的新特征图包含更多的细节特征,所以目标检测精度较高;尤其是在复杂场景中检测精度的提高较为明显,有利于更好地完成相应的视觉任务。(3) 为了更好地利用由特征图加权融合方法得到的新特征图中含有的细节性特征,对RPN网络进行了改进。与使用原始RPN网络的目标检测方法相比,使用改进RPN网络的目标检测方法精度更高、效果更好。
