基于用户兴趣的微博溯源算法
2020-12-18杨潇陈秀真马进梁浩喆李生红
杨潇,陈秀真,马进,梁浩喆,李生红
基于用户兴趣的微博溯源算法
杨潇1,2,陈秀真1,2,马进1,2,梁浩喆1,2,李生红1,2
(1. 上海交通大学网络安全技术研究院,上海 200240;2. 上海市信息安全综合管理技术研究重点实验室,上海 200240)
微博信息溯源通过分析在平台采集的话题数据集,挖掘相关话题的真正源头,即发布时间较早且影响力大的微博集合,实现网络舆论的管控与引导。提出一种基于用户兴趣的微博溯源算法,该算法根据博主的兴趣计算博主影响力,同时根据评论人、转发人的兴趣计算评论人、转发人的影响力,结合博主关注度和发表时间等因素,利用网页排序算法对微博评分,根据微博得分进行排序溯源。实验结果表明,该算法相较于传统溯源算法在查全率上提升了约21%。
信息溯源;微博;兴趣;影响力;关注度
1 引言
微博作为国内最大的自媒体平台之一,往往存在各类谣言、敏感话题等相关信息。微博信息的溯源,不仅对维护信息安全有重要意义,在信息传播研究以及在线社交平台分析上有较多应用。
在信息溯源方面,有学者做过相关研究。时国华等[1]根据微博的发表时间、原创性和中心性,同时结合微博的转发关系对微博进行溯源。信息传播中,用户特征有一定参考性,基于此,基于用户特征的算法被提出。刘荣叁[2]等根据用户粉丝数、评论数等信息计算用户影响力,同时结合排序算法计算出微博源头。米昂、张跃伟、刘岗等通过博主的发博频率,微博的原创性系数、转发量、评论量、转发关系等因素计算得到微博源头[3-5]。Wang等[6]利用用户的特征信息构建信息矩阵来判断用户之间的传播关系。吴信东等[7]通过构建信息传播结构以及分析用户行为来确定微博信息传播的源头。近几年,一些基于网络结构与模型的溯源算法被广泛研究。Sadikov等[8]通过构建K树模型来得到信息传播路径,从而对信息溯源。杨静等[9-10]将网络传播模型AN与微博参与者的数量结合起来,利用公式递推微博源头。尹熙成等[11]通过构建微博信息传播中的主路径来计算各个传播节点的权值从而找到影响力最大的节点作为源头。Leskovec[12]通过提取出信息传播路径中的主干路径来寻找信息源头。何冰心等[13]在原有病毒传播模型的基础上,利用信息社区划分以及人群结构特征等属性提出了一种群行为特性划分的信息传播模型(CAPIR)对信息进行溯源。社交网络用户之间,往往存在社会性拓扑结构。基于此,王梦迪等[14]提出一种基于克罗内克网络模型的初始邻接矩阵生成算法来迭代求得信息源头。Xiao等[15]从多消息传播网络入手,引入话题传播树的传播模型,利用信息传播网络来构建话题传播树,从而确定传播路径并且溯源。部分学者将数理分析的方法用来分析信息溯源。Soheil等[16]根据时间、内容以及关联性等因素构建数学传播概率模型来判断源头信息。INUI等[17]基于twitter平台,将推文进行分割,并结合相关内容发布次数建立了一种新闻源头溯源模型。
当前对于微博溯源的研究方法主要分为两类。一类是根据微博文本相似度,或者利用微博的评论数、粉丝数等参数进行简单计算来溯源。另一类是根据转发关系以及传播的拓扑结构等信息利用数学模型迭代求得路径源头。但是两类方法都没有考虑微博的文本内容、其他用户对该微博所评论的内容以及转发内容所产生的影响。针对该问题,本文提出了一种基于用户兴趣的微博溯源算法(ITM, interests-based tracing algorithm)。该算法根据博主以前微博的内容计算出博主的兴趣,然后根据博主兴趣计算博主影响力,同时计算微博评论人、转发人的兴趣,求得评论人、转发人的影响力。最后结合博主关注度以及微博发表时间等因素利用网页排序算法对所有微博进行评分,根据微博得分进行排序溯源。与现有的两类方法相比,本文所提算法考虑到了微博信息的文本内容对信息传播带来的影响,从而更准确地分析用户的影响力。该算法利用用户兴趣,挖掘计算出博主对于拥有类似兴趣的用户社区的影响,从而更准确地定位信息源头。
2 用户兴趣的计算
微博用户的行为往往可以反映用户的一些兴趣爱好。例如,某个用户喜欢娱乐方面的内容,该用户发表、评论以及转发的微博会倾向于娱乐方面的信息。因此通过用户以前的微博信息,可以分析出用户的兴趣倾向。
通过对大量微博数据的分析,用户兴趣可以分为以下5类:文娱、经济、科教、政治、军事。一条微博的内容与某个兴趣的相关程度越高,那么这条微博中的关键词汇与该兴趣的相关度越高。因此,本文通过提取用户以前博客信息中的关键词,并计算其与上述某个兴趣关键词在知网词林中的距离得到微博与该兴趣的相关程度。

知网词林是一种分层次体系的词典,利用义项和义原来定义词汇。义项是对一个词的一种描述,一个词可以有多个义项,而义原就是描述一个义项的基本单位。在知网词林中,义项的基本结构如图1所示。
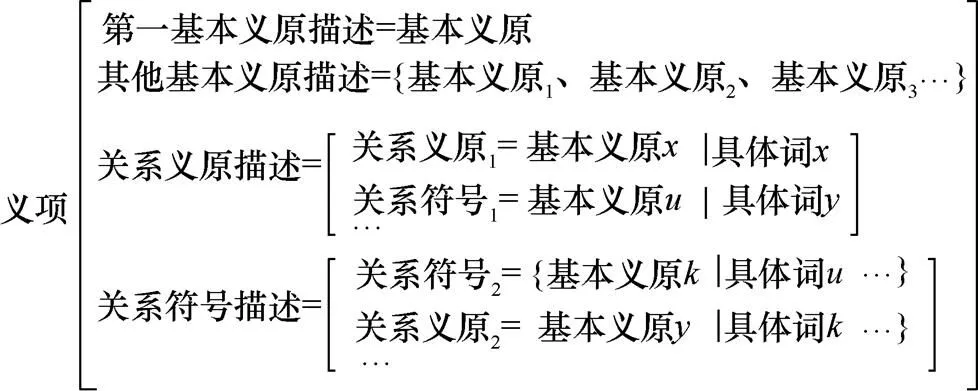
图1 义项结构
Figure 1 Sememe structure
词语之间的距离使用义项来计算,如果有两个词语1,2,其中1的义项为11,12,13,…,1n,而2的义项为21,22,23,…,2m,则1,2的距离计算公式如下。

由式(2)可知,词语之间的距离是两个词各个义项之间相似度的最大值,而义项是由义原定义的,所以义项之间的相似度由义原计算。由图1可知,义原呈树形结构,通过考虑义项的义原层次树中4类义原描述之间的距离,可以得到其义项间的相似度,如下。



3 基于用户兴趣的微博溯源算法
微博话题的溯源是指在给定关于某个事件的微博数据集的情况下,根据一定指标和方法,从中找出信息传播的源头。
基于对各类话题下源头微博的研究,本文认为发布时间较早并且对社会大众拥有较大影响力的微博为源头微博。影响力较大微博的博主一般具有一定的兴趣倾向,并且博主与粉丝有相似的兴趣,博主发布一条微博时其粉丝可以获得该微博的相关推送。所以博主的粉丝数量越多,发布的微博与博主兴趣越相似,其对微博社区产生的影响越大。同理,微博的评论内容和转发会推送给对应用户的粉丝,评论人、转发人的粉丝数越大,并且评论人及转发人的兴趣与原微博内容越相关,影响力越大。如果博主近期发布的其他微博的关注度较高,也会为新发布的微博带来一定的关注度,从而为新微博的传播贡献一定的影响力。同时,微博发布时间是判断源头的重要参数之一,发布越早的微博能越快得到人们的关注,其成为源头微博的可能性越大,但微博的源头不一定是发布时间最早的微博,因为有些微博可能是经由一些影响力大的人转发才被关注。本文所提ITM算法综合考虑博主影响力,评论人、转发人的影响力、关注度、时间,通过计算得分来对微博进行排序溯源,ITM算法流程如图2所示。
对应的算法伪代码如算法1所示。
算法1 Interest-based Tracing Method (ITM)
1) Input: Topic blogs Blogs = {Blog1,Blog2,…,BlogM}, source blogs Sources = {}, blog score set Scores = {}, number of sources N;
2) Output: Source blogs Sources;
3) for k = 1: M do
4) Calculate user influence: BloggerInf = User Influence Calculation(Blogk);
5) Calculate comment influence: CommentInf = Comment Influence Calculation (Blogk);
6) Calculate user attraction Attra;
7) Standardize time T;
8) Calculate blog score: Score = Blog Score Calculation(BloggerInf, CommentInf, Attra, T)
9) Add blog score Score in Scores: AddinScores(Score)
10) end for
11) Pick the N blogs with highest scores in Scores into Sources;
12) return Sources
3.1 基于兴趣的博主影响力计算
博主所发的微博内容能反映博主的兴趣爱好,其粉丝一般与其有着相同或者相似的兴趣,所以博主所发微博的内容与其兴趣相似程度越高,对其粉丝和大众的影响力越大。同时博主的粉丝数越多,微博的影响力越大,但是当微博粉丝数超过一定数量级之后(如千万级),粉丝数贡献的影响力会趋紧饱和,其影响力的增长趋于平缓。
基于以上分析和式(1)、式(5),博主的微博在兴趣方面(文娱、经济、科教、政治、军事之一)的影响力计算公式如下。
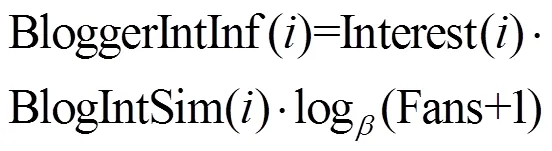
其中,是博主对兴趣i的感兴趣程度,由式(5)计算。是微博内容与兴趣的相关程度,用式(1)计算。表示粉丝数的影响力,使用函数计算,该影响力会随着粉丝数的增长变大,但当粉丝数超过一定数量级后,增长会变缓。由式(6)可以看出,博主影响力与、以及分别呈正相关关系。
Figure 2 Algorithm flowchart
在各个兴趣下的博主影响力之和为总的博主影响力,计算公式如下。
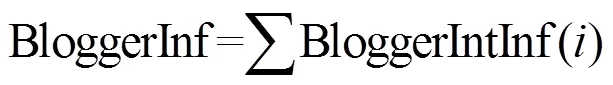
博主影响力计算的算法2如下。
算法2 User Influence Calculation
1) Input: Topic blog Blogk, interest fields I = {i1,i2,i3,i4,i5}, user influence BloggerInf = 0;
2) Output: User influence BloggerInf;
3) for k = 1: 5 do
4) Employ Blogkto calculate user influence under a certain interest BloggerIntInf(ik)by Eq.(6);
5) Add BloggerIntInf(ik) in total influence BloggerInf: BloggerInf += BloggerIntInf(ik);
6) end for
7) return BloggerInf
3.2 基于兴趣的评论人、转发人影响力计算
用户可以在微博下方发表评论,评论可以被其他人点赞和留言,并且评论人的粉丝会被推送该评论的相关信息,所以评论人可以为其评论的微博贡献一定的影响力。评论人与其粉丝一般有相似的兴趣,评论人的兴趣和微博的话题越相似且评论人粉丝越多,影响力越大。同理,转发可以附加评论,也能为原微博贡献一定的影响力。
评论人、转发人在各个兴趣下的影响力的和即评论人、转发人总的影响力,计算公式如下。




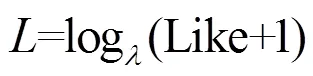
评论人、转发人的影响力计算过程使用算法描述如下。
算法3 Comment Influence Calculation
1) Input: A Topic blog Blogk’s comments Com = {com1,com2,…,com}, interest fields I = {i1,i2,i3,i4,i5}, comment influence CommentInf = 0;
2) Output: Comment influence CommentInf;
3) for k = 1: 5 do
4) ComIntInf(ik) = 0;
5) for i = 1: N do
6) Calculate single comment influence under a certain interest SinComIntInf(ik)by Eq.(9);
7) Add all single comment influences in total influence under a certain interest: ComIntInf(ik) += SinComIntInf(ik);
8) Add all total comment influence under different interests together to get the final influence: CommentInf += ComIntInf(ik)
9) end for
10) return CommentInf
3.3 关注度
博主近期的其他微博被关注的程度越高,其他用户在浏览这些微博时越有大概率看到话题微博,并且微博用户倾向于浏览关注度较高的博主所发的微博,这也会为当前话题微博带来一定的关注度,从而为话题微博的传播贡献一定的影响力。所以,计算微博得分时,应该考虑博主关注度。
微博博主的关注度,由最近一个月内除话题微博外的其他微博的点赞、转发和评论的数量来计算,数量越多则关注度越大。本文认为用户近期发布的微博带来的关注度比较有影响力,所以取一个月内发布的微博来计算关注度,其计算公式如下。


从式(13)可以看出,近期发布的微博权重较高,其关注度造成的影响较大,而较早以前发布的微博权重较小,其关注度造成的影响较小。
3.4 时间
微博发布时间是判定微博源头的重要指标之一,发布时间越早的微博成为微博源头的概率越大。
微博发布时间可以转化为相对应的持续时间(以小时为单位),本文所提算法所有的微博持续时间需要进行标准化,本文使用的标准化函数如下。

3.5 微博综合得分计算

算法4 Blog Score Calculation
1) Input: A Topic blog Blogk's user influence BloggerInf, comment influence CommentInf, user attraction Attra, blog Standardized time T;
2) Output: Blog score Score;
3) Calculate blog score: Score = hacker news (BloggerInf, CommentInf, Attra, T)
4) return Score
Hacker News排序算法是一种网络社区平台的文章排序算法,对于每篇文章,其他用户可以选择为这篇文章投上一票(其他用户阅读、评论文章会为文章投上一票),后台管理器会根据文章的得票和发布时间对所有文章进行评分排序。但是该排序算法会将发布时间较晚的文章排在较前面,从而对新的文章进行推广,防止得分很高的文章霸榜。Hacker News排序算法如式(15)所示。

在式(15)中,较晚发布的信息得分会高于早发布的信息,然而在微博溯源中,较早发布的信息影响力一般越大。通过对Hacker News算法公式进行优化,使发布时间较早、得票较高的文章排名靠前,优化后的微博评分公式如下。


AHP通过对比两两参数之间相对重要性,确定某个参数相对另一参数所占的比重,从而构建判断矩阵,之后计算其最大特征向量,以该特征向量代表各个参数的权重。最后通过判断矩阵的特征值计算一致性比率进行一致性检验,如果一致性比率小于阈值,则认为计算出来的权重值是较为合理的。
综合各项因素,通过专家评判得到判断矩阵,如表1所示。

表1 判断矩阵
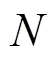
4 实验结果
实验选用新浪微博作为数据平台,新浪微博作为现今为止国内用户最多的社交平台之一,其数据具有较好的代表性。利用爬虫软件,从微博平台采集“李飞飞离职”“高锟去世”“美国重启登月计划”“雷克萨斯将实现国产”和“国科大星命名”5个事件的微博数据用于测试本文所提算法ITM,采集时间为2018年9月11日到10月12日。实验采集的微博共计12 110条,包含具有评论、转发或点赞的微博以及相关的博主信息、评论人信息,过滤了评论、转发和点赞都为0的微博,这主要考虑到这些微博没有对信息传播造成实质的影响。同时使用文献[1]所提出的基于文本中心度的微博文本溯源(OR)算法以及文献[2]所提出的基于用户影响力的微博溯源算法(UITA)进行对比。之所以使用OR算法和UITA算法作为对比,是因为它们分别是通过拓扑结构和参数计算来进行溯源的方法(已有的两类方法),具有一定代表性,且算法效果较好。使用人工标注的方法对微博的源头进行标注,对比两种算法找到源头正确的个数,并计算相应的查全率。查全率是指从文档数据集中检索出关联文档成功率的一种指标,即检索出来的关联文档占所有关联文档数据的百分比,实验采用的查全率计算公式如下。

同时查看两种算法的溯源结果在相应话题下对应的热门微博个数,热门微博是微博官方在搜索提示中标记的热度较大的微博,并且往往对公众造成较大的影响,源头微博往往是热门微博之一,因此溯源结果中的热门微博个数越多,其准确性越高。
实验参数设置以及结果如表2和表3所示。
从表3可以看出,总体来说本文所提ITM算法在溯源微博正确个数上优于OR算法以及UITA算法,并在查全率上分别提升了17.9%和25%,平均提升了21.45%。在事件1李飞飞离职和事件5国科大星命名等事件上,OR算法以及UITA算法没有考虑到受众具有明显的兴趣倾向,所以本文所提ITM算法在溯源准确性上有一定提升。在事件3美国重启登月计划上,人工标注源头微博中影响力较大的几个微博的文本内容非常相似,而ITM算法和基于文本相似中心性的OR算法的溯源正确数相同,所以即使是在微博文本相似度较大的情况下,ITM算法也能保证溯源的准确性。

表2 实验参数设置

表3 实验结果
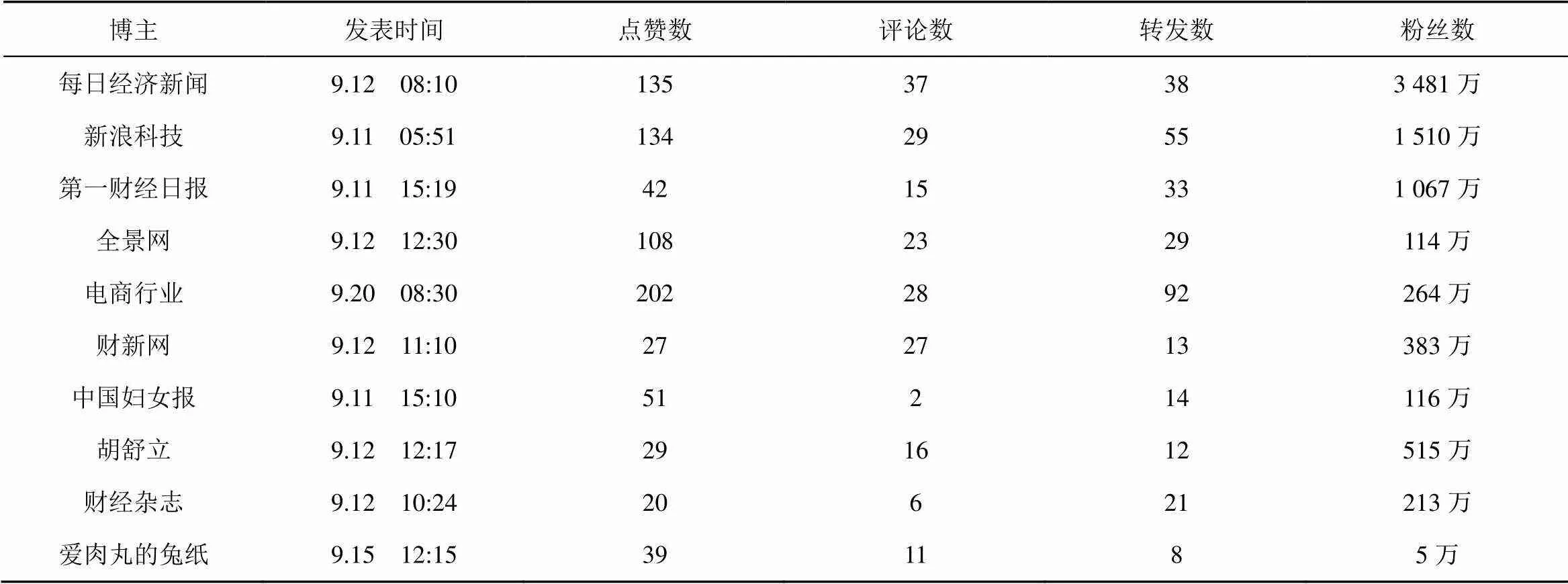
表4 李飞飞离职事件微博基本信息
在热门微博个数方面,由于OR算法只考虑文本的相似度和中心度,并未考虑微博在话题各方面的影响,所以ITM算法相对于OR算法准确性较高。UITA算法只是单纯基于微博参数来计算影响力,未考虑微博文本的影响,所以相对于UITA而言,ITM算法的准确性较高。
选择上述的事件1李飞飞离职,ITM算法的微博溯源结果以及微博基本信息如图3和表4所示(为便于分析,将微博得分换算为百分制)。
从图3可以看出,每日经济新闻和新浪科技等博主的微博得分较高,根据表4中的信息,发现得分较高微博发布时间较早,在点赞、评论、转发数量上相对较多,并且拥有较多的粉丝数量,通过对比人工标注的源头和话题热门微博,发现溯源结果较为准确。全景网发布的微博虽然有较多关注,但由于发布时间较晚所以得分不高,结果符合实际情况。中国妇女报发布的微博虽然时间比较早,但由于没有收到太多的关注并且粉丝数较少所以造成的影响比较小,结果符合实际情况。

图3 李飞飞离职事件微博的得分
Figure 3 Scores of blogs for Li Feifei's resignation event
5 结束语
本文主要研究微博平台中的信息溯源问题,并提出一种ITM算法对信息进行溯源。ITM算法利用用户兴趣计算博主影响力以及评论人、转发人影响力,同时结合关注度和时间参数对所有微博进行评分,从而对微博进行排序溯源。相比以前基于文本相似度和转发关系的溯源算法,ITM算法考虑到了微博文本以及其他用户的评论转发对信息传播带来的影响。实验结果表明,ITM算法在溯源准确率上相对传统溯源算法有一定的提升。
下一步的研究将主要着眼于信息跨平台传播的情况并且考虑微博中的图片内容来提升溯源的准确性。
[1] 时国华. 微博信息溯源及传播面分析技术的研究与实现[D]. 长沙: 国防科学技术大学, 2012.
SHI G H. The research and implementation of microblogging initiator detection and dissemination analysis[D]. Changsha: National University of Defense Technology, 2012.
[2] 刘荣叁, 张宇, 王星. 面向新浪微博的信息溯源技术研究[J]. 智能计算机与应用, 2017, 7(2):94-98.
LIU R S, ZHANG Y, WANG X. Research of information trace technology based on Sina micro-blog[J]. Intelligent Computer and Applications, 2017, 7(2):94-98.
[3] 米昂. 结合影响力分析的微博舆情溯源研究[D]. 北京: 北京交通大学, 2015.
MI A. Research on source tracing of public opinion on micro-blogs combined with impact analysis[D]. Beijing: Beijing Jiaotong University, 2015.
[4] 张跃伟. 基于微博客话题的热点预测及传播溯源[D]. 北京: 北京邮电大学, 2014.
ZHANG Y W. Hotspot prediction and analysis of propagating of topics based on microblog[D]. Beijing: Beijing University of Posts and Telecommunications, 2014.
[5] 刘岗. 基于微博事件的话题溯源方法[D]. 哈尔滨: 哈尔滨工程大学, 2015.
LIU G. A method to track topics based on events of micro-blog[D]. Harbin: Harbin Engineering University, 2015.
[6] WANG D, ZHOU W, ZHENG J X, et al. Who spread to whom? inferring online social networks with user features[C]//2018 IEEE International Conference on Communications (ICC). 2018: 1-6.
[7] 吴信东, 李毅, 李磊. 在线社交网络影响力分析[J]. 计算机学报2014, 37(4): 735-752.
WU X D, LI Y, LI L, Influence analysis of online social networks[J]. Chinese Journal of Computers, 2014, 37(4): 735-752.
[8] SADIKOV E, MONTSERRAT M, JURE L et al. Correcting for missing data in information cascades[C]// WSDM '11 Proceedings of the fourth ACM International Conference on Web Search and Data Mining. 2011:55-64.
[9] 杨静, 董圆, 张健沛. 一种基于话题影响力的微博话题溯源方法[J]. 小型微型计算机系统, 2015, 36(9):1939-1942.
YANG J, DONG Y, ZHANG J P. Method for tracing the source of micro-blogging topic based on the topic influence[J]. Journal of Chinese Mini-Micro Computer Systems, 2015, 36(9):1939-1942.
[10] 董圆. 一种基于话题影响力的微博话题溯源方法[D]. 哈尔滨: 哈尔滨工程大学, 2015.
DONG Y. Trace of microblogging topic initiator based on the influence of topic[D]. Harbin: Harbin Engineering University, 2015.
[11] 尹熙成. 在线社交网络中信息传播主路径的识别与应用研究[D]. 南京: 南京邮电大学, 2017.
YIN X C. Research on the identification and application of the main paths of information diffusion in online social networks[D]. Nanjing: Nanjing University of Posts and Telecommunications, 2017.
[12] LESKOVEC J, MCGLOHON M, FALOUTSOS C, et al. Patterns of cascading behavior in large blog graphs[C]//Proceedings of the 2007 SIAM International Conference on Data Mining. 2007: 551-556.
[13] 何冰心. 社交网络中信息传播和溯源模型研究[D]. 大连: 大连理工大学, 2018.
HE B X. A study on information diffusion and source locating model in social network[D]. Dalian: Dalian University of Technology, 2018.
[14] 王梦迪. 基于OSN的信息溯源问题研究[D]. 北京: 中国人民公安大学, 2018.
WANG M D. Research on information tracing based on OSN[D]. Beijing: People's Public Security University of China, 2018.
[15] XIAO Y, YU H, LI Q, et al. MPURank: a social hotspot tracking scheme based on tripartite graph and multimessages iterative driven[J]. IEEE Transactions on Computational Social Systems, 2019, 6(4): 715-725.
[16] FEIZI S, MEDARD M, QUON G, et al. Network infusion to infer information sources in networks[J]. IEEE Transactions on Network Science and Engineering, 2018.
[17] INUI T, MASAKI S, MIKIO Y. Automatic news source detection in twitter based on text segmentation[C]//Proceedings of the 28th Pacific Asia Conference on Language, Information and Computing. 2014.
[18] 葛斌, 李芳芳, 郭丝路. 基于知网的词汇语义相似度计算方法研究[J]. 计算机应用研究, 2010, 27(9):3329-3333.
GE B, LI F F, GUO S L. Word’s semantic similarity computation method based on hownet[J]. Application Research of Computers, 2010, 27(9):3329-3333.
[19]刘群, 李素建. 基于知网的词汇语义相似度计算[J]. 中文计算语言学, 2002, 7(2): 59-76.
LIU Q, LI S J. Word similarity computing based on how-net[J]. International Journal of Computational Linguistics & Chinese Language Processing, 2002, 7(2): 59-76.
[20] 周雪妍. 在线社会网络关键用户挖掘方法研究[D]. 哈尔滨: 哈尔滨工程大学, 2016.
ZHOU X Y. Research on key users mining of online social network[D]. Harbin: Harbin Engineering University, 2016.
[21] 曹秀英, 梁静国. 基于粗集理论的属性权重确定方法[J]. 中国管理科学, 2002, 5(5): 98-100.
CAO X Y, LIANG J G. The method of ascertaining attribute weight based on rough sets theory[J]. Chinese Journal of Management Science, 2002, 5(5): 98-100.
[22] SALIHEFENDIC A. How hacker news ranking algorithm works[EB].
User interests-based microblog tracing algorithm
YANG Xiao1,2, CHEN Xiuzhen1,2, MA Jin1,2, LIANG Haozhe1,2, LI Shenghong1,2
1. Institute of Cyber Science and Technology, Shanghai Jiaotong University, Shanghai 200240, China2. Shanghai Key Laboratory of Integrated Administration Technologies for Information Security, Shanghai 200240, China
Microblog information tracing refers to finding the source set of microblog topics according to the analysis of crawled microblog texts and it’s of great significance in the aspect of public opinion control and information security. A user interests-based tracing method (ITM) was proposed. The proposed method calculates the influence of the blogger based on the interest of the microblog blogger, and also calculates the influence of the commentators based on the interest of the commentators. The ranking algorithm was used to score the blogs according to publication time, notability and influence, and the source of the blogs was traced according to the blog score rank. Experimental results show that the accuracy of the proposed algorithm improved about 21% compared with the traditional tracing algorithms.
information tracing, microblog, interest, influence, notability
s: The National Key R&D Program of China (2016YFB0801003), The National Natural Science Foundation of China (61562004, 61431008)
TP391
A
10.11959/j.issn.2096−109x.2020086

杨潇(1993− ),男,重庆人,上海交通大学硕士生,主要研究方向为社交网络数据分析、自然语言处理。
陈秀真(1977− ),女,山东聊城人,博士,上海交通大学副教授,主要研究方向为社交网络数据分析、车联网信息安全、安全检测与评估。

马进(1977− ),女,山东滕州人,博士,上海交通大学高级工程师,主要研究方向为大数据与人工智能应用、车联网信息安全、网络空间安全综合管理新技术。
梁浩喆(1994− ),男,广西柳州人,上海交通大学硕士生,主要研究方向为浏览器安全、分布式计算。

李生红(1971− ),男,辽宁绥中人,博士,上海交通大学教授、博士生导师,主要研究方向为信息安全、人工智能。
论文引用格式:杨潇, 陈秀真, 马进, 等. 基于用户兴趣的微博溯源算法[J]. 网络与信息安全学报, 2020, 6(6): 164-173.
YAGN X, CHEN X Z, MA J, et al. User interests-based microblog tracing algorithm[J]. Chinese Journal of Network and Information Security, 2020, 6(6): 164-173.
2019−11−20;
2020−09−23
陈秀真,chenxz@sjtu.edu.cn
国家重点研发计划(2016YFB0801003);国家自然科学基金(61562004, 61431008)
