基于深度卷积特征与LLC编码的现勘图像分类
2020-12-17倪天宇王富平刘卫华
刘 颖,倪天宇,王富平,刘卫华,艾 达
(1.西安邮电大学 图像与信息处理研究所,陕西 西安 710121;2.西安邮电大学 电子信息现场勘验应用技术公安部重点实验室,陕西 西安 710121)
现勘图像数据是公安现场勘验信息的重要组成部分,犯罪现勘图像分类 (crime scene investigation image classification,CSIC) 可以给刑侦破案提供重要线索,并且为案件串并研判提供关键信息。随着先进公安刑侦现勘视频图像采集设备技术的革新和功能完善,使得公安现勘系统中图像数据的数量急速增长,且种类众多。传统人工分类和标注的方式已经难以满足海量数据处理的需求。为了节省人力物力及进一步提高公安机关的工作效率,研究高效的现勘图像分类算法尤为重要[1-2]。
现有的现勘图像分类方法主要通过对整幅图像提取全局视觉特征,如颜色、纹理和形状等特征[3-4],然后将这些全局特征输入到分类器中进行分类。如基于纹理与形状特征融合的刑侦图像检索算法,通过双树复小波变换和多参数灰度共生矩阵提取现勘图像纹理特征,并将提取的Hu不变矩形状特征与纹理特征进行融合实现分类任务[3]。基于模糊K最近邻(k-nearest neighbor,KNN)的现勘图像场景分类算法将提取的局部二值模式(local binary patterns,LBP)特征和基于小波变换提取的纹理特征进行融合,利用模糊KNN方法对图像进行分类[4]。但是,全局视觉特征缺乏图像局部信息,而且对光照变化、尺度缩放等图像变换的鲁棒性较差。尺度不变特征变化 (scale-invariant features transform,SIFT)[5]特征可弥补全局特征的不足,其在图像旋转、尺度缩放、亮度变化下能保持较好不变性。为了获得精确和稀疏的图像特征,可将局部特征通过特征编码技术进行编码量化,如词袋模型 (bag of words,BOW)[6]、空间金字塔匹配 (spatial pyramid matching,SPM)[6]、稀疏编码的空间金字塔匹配 (sparse coding spatial pyramid matching,SCSPM)[7]和局部约束线性编码 (local-constrained linear coding,LLC)[8]等方法。BOW是通过投票方式把特征量化为与它最近邻的视觉单词,存在特征的空间信息损失和量化损失两点不足。SPM通过多尺度匹配技术实现了特征的空间分布信息编码,而SCSPM算法在SPM基础上加入稀疏正则项,将每个特征量化到多个视觉单词上,从而减少量化损失,但SCSPM算法选择的视觉单词彼此之间关联度不大,其中被广泛使用的l1正则化函数不是平滑的,且算法计算复杂度较高。将LLC在选择用多个最近邻视觉单词对局部特征进行线性表示的基础上,使不同局部特征之间共享视觉单词,可同时满足稀疏性和局部性,实现图像局部信息的更精细表示[8]。文献[9]将LLC与GIST特征进行串联融合,实现了静态人体行为的分类。基于多尺度空间LLC的图像语义分类算法[10]对图像密集SIFT描述子进行LLC编码,并通过概率潜在语义模型(probabilistic latent semantic analysis,PLSA)对图像进行分类。但是,上述特征编码方法普遍利用图像的SIFT等低级视觉特征,使得目标区域的内容信息提取不够精确[5]。
近年来,深度学习技术在计算机视觉等相关领域应用中取得很好的效果。与传统的低层特征相比,卷积神经网络(convolutional neural networks,CNN)[11]能从复杂的数据中学习到更加抽象的特征表示,并且其在图像分类和检索等任务中都表现出相当优越的性能。因此,针对现勘图像场景多变、背景复杂、拍摄时光照及角度不同因素影响下导致分类准确率不高的问题,本文提出一种基于深度卷积特征与近似LLC编码的现勘图像分类算法。采用滑动窗口的方式对图像进行裁剪,获取密集的图像块;然后采用卷积神经网络提取图像块特征,并通过近似LLC算法对图像密集CNN特征进行编码;最后,通过最大池化和多尺度空间金字塔匹配将编码后的特征拼接成单一向量作为图像整体特征表示。将训练好的卷积神经网络提取图像深层特征,代替传统的低层特征,以期提高特征的鲁棒性和表示能力。
1 基于CNN与近似LLC编码的现勘图像分类算法
基于深度卷积特征与近似LLC编码的现勘图像分类算法的框架如图1所示。利用滑动窗口法将图像分割为N个图像块,将图像块依次输入训练好的CNN中,提取图像密集CNN特征 (黑色圆点),并进行主成分分析(principal component analysis,PCA)降维和白化处理以降低计算复杂度和提升特征鲁棒性;采用近似LLC编码将密集CNN特征编码为M维特征向量(灰色圆点);结合最大池化和SPM方法将空间信息融入多尺度特征中,得到最终特征向量,其中L=∑l2l×2l为多尺度金字塔分层的图像块个数,l为金字塔层数。最后,基于支持向量机(support vector machine,SVM) 分类器实现图像分类。

图1 基于深度卷积特征与近似LLC编码的现勘图像分类框架
1.1 CNN特征提取
采用视觉几何组(visual geometry group,VGG)[12]网络模型提取图像特征,其中VGG19网络模型包括16层卷积层、3层全连接层和最后一层soft-max分类层。直接利用CNN提取的图像全局特征缺乏几何不变性,鲁棒性较差[13-15],将卷积神经网络与滑动窗口方法相结合,利用深度卷积神经网络提取局部图像块特征,可提高局部特征的鲁棒性和识别能力。具体方法是先将图像尺寸规格化为512×512像素,然后以窗口大小224×224像素、步长为8像素将图像分割为1 296个图像块,并利用VGG19深度网络提取每个图像块的4 096维特征向量,得到1 296×4 096维的图像特征矩阵。
1.2 视觉词典生成
运用无监督聚类算法K-means对所有训练图像块的描述子进行聚类,获得视觉中心。从训练图像提取密集CNN特征,随机挑选M个作为初始聚类中心;根据欧式距离计算所有描述子所属的聚类中心,然后计算属于同一聚类中心的所有描述子的均值以更新聚类中心。重复上述过程,直到相邻两次迭代类中心基本不发生变化则停止迭代,得到最终的视觉词典。
1.3 局部约束线性编码
特征编码方法主要包括矢量量化编码[16]、稀疏编码[7]和局部约束线性编码[8]。为了降低空间金字塔模型SPM方法中矢量量化的重构误差,稀疏编码将矢量量化的约束条件‖ci‖l0=1进行松弛,获得l1范式正规化的稀疏编码。假设X是D维特征描述子,X=[x1,…,xN]∈RD×N;字典B=[b1,…,bM]∈RD×M是由M个超完备基构成,则优化模型[7]可表示为
,
(1)
其中,C=[c1,…,cN]是对X的编码特征,λ是正则化参数。
稀疏编码提取的超完备基可以降低重构误差,有助于从稀疏编码向量中获取描述子的显著信息[17]。另外,局部坐标编码(local coordinate coding,LCC)理论认为局部性比稀疏性更有必要,局部性可以保证稀疏性[18]。因此,LLC方法将式(1)中的稀疏约束项替换为局部限制项,使得优化目标函数变为
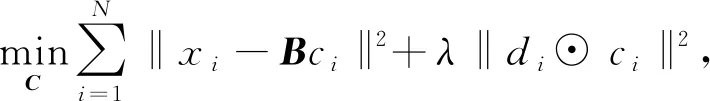
(2)
其中:A是数值全为1的向量;ci表示LLC编码系数;⊙表示对应元素相乘;di是局部调节系数,它根据特征与视觉字典基向量之间的相似性自适应地对LLC编码系数进行加权,表达式为
(3)
式中,dist(xi,B)=[dist(xi,b1),…,dist(xi,bM)]T,dist(xi,bj)是xi和bj的欧氏距离,σ是调节下降速度的因子。
在求解式(2)优化目标函数时,通常将di规范到(0,1],并添加约束条件ATci=1以保证编码的平移不变性。为更好地使式(2)得到闭合解,按照
(4)
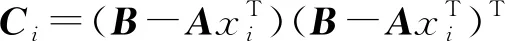
式(4)可保证LLC存在解析解,模型编码效率明显高于SCSPM。图2描述了稀疏编码(sparse coding,SC)以及LLC编码映射方法之间的差异。不同于SC方法中选择不同的原子作为线性组合的基向量,LLC方法中距离相近的描述子会共享多个相同视觉单词,使得相近描述子具有相似的特征编码,从而同时保证稀疏性和局部性。
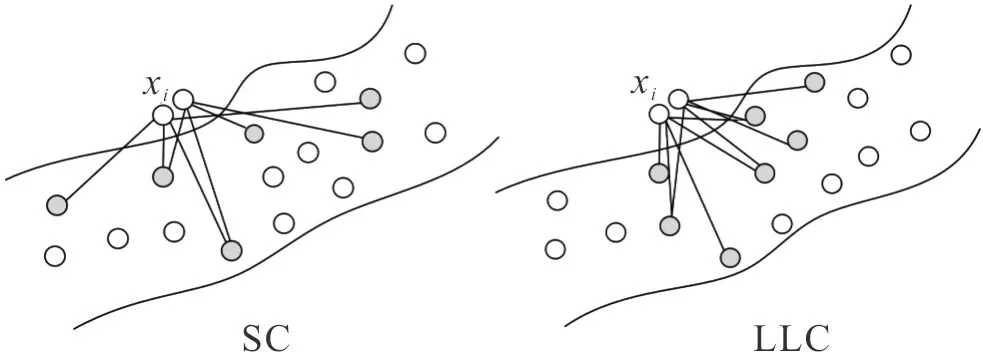
图2 特征编码过程示意图
1.4 近似LLC编码
对式(2)优化模型进行求解时,待重构的特征描述子倾向于选择字典中距其较近的部分视觉单词,从而形成一个局部坐标系统。因此,使用近似LLC编码方式加速编码过程,仍然可保留特征编码的局部性和稀疏性。
近似LLC编码过程主要包括字典学习、K近邻搜索和特征编码等3个阶段。
1) 字典学习
从训练数据集中提取的特征描述子集合中随机抽取一部分,使用K-means算法进行视觉字典的聚类学习B=[b1,b2,…,bM]∈RD×M。
2)K近邻搜索
对于任意待编码的特征描述子xi,设定近邻个数K,并选取视觉字典B中距离其最近的K个视觉单词,形成子字典Bi=[b[1],b[2],…,b[k]]。
3) 特征编码
使用子字典Bi对特征描述子xi进行重构,通过求解优化目标函数

(5)
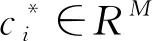
1.5 最大池化
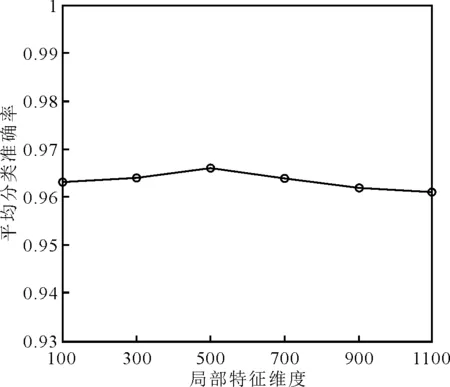
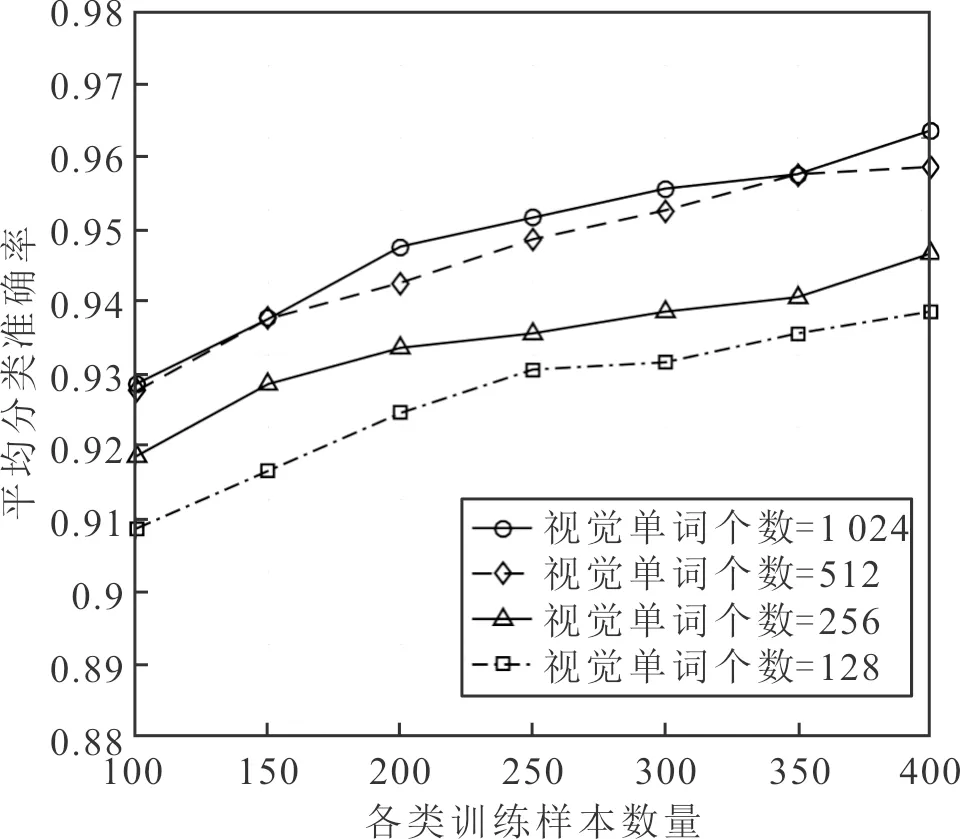
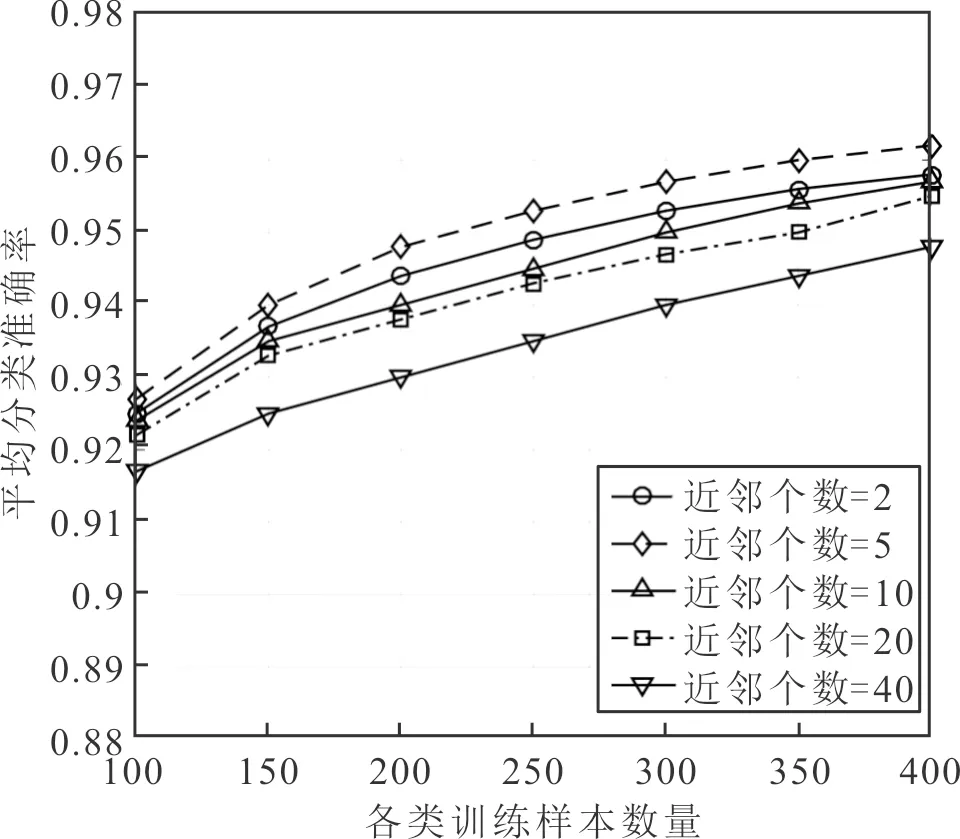
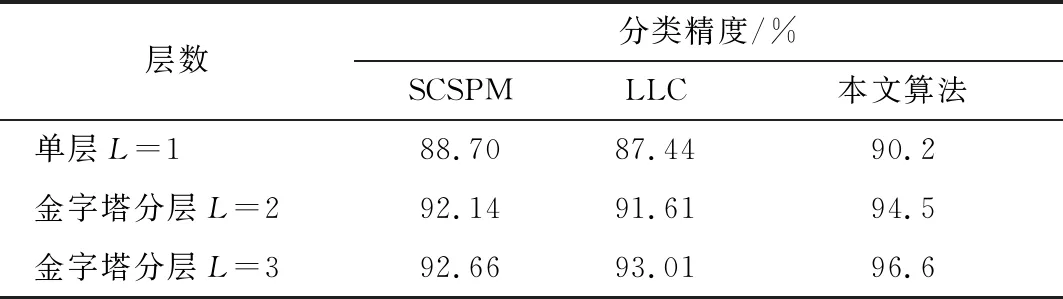
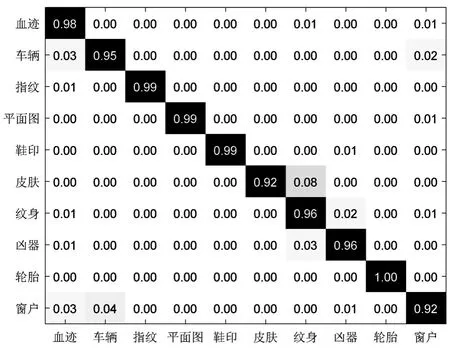
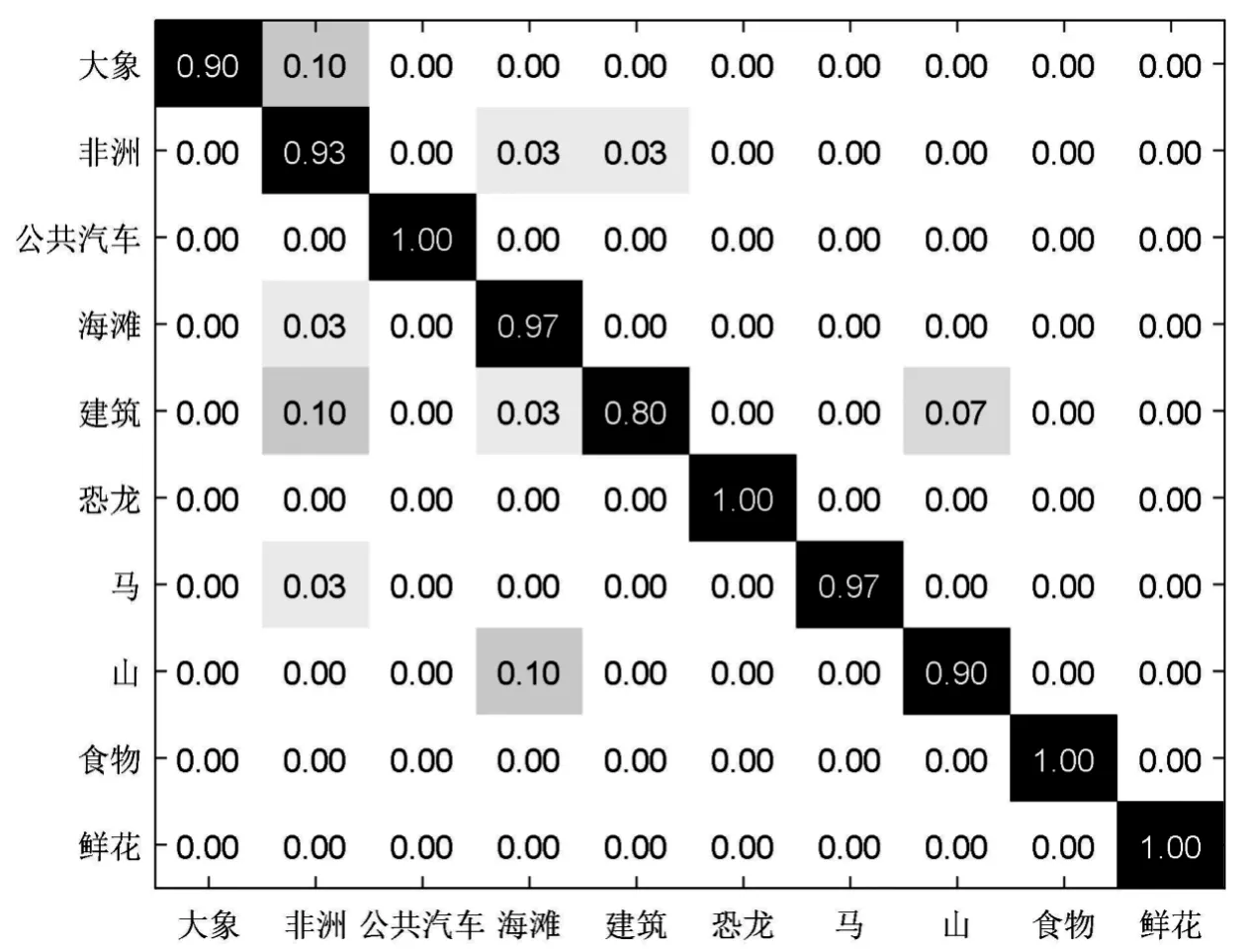
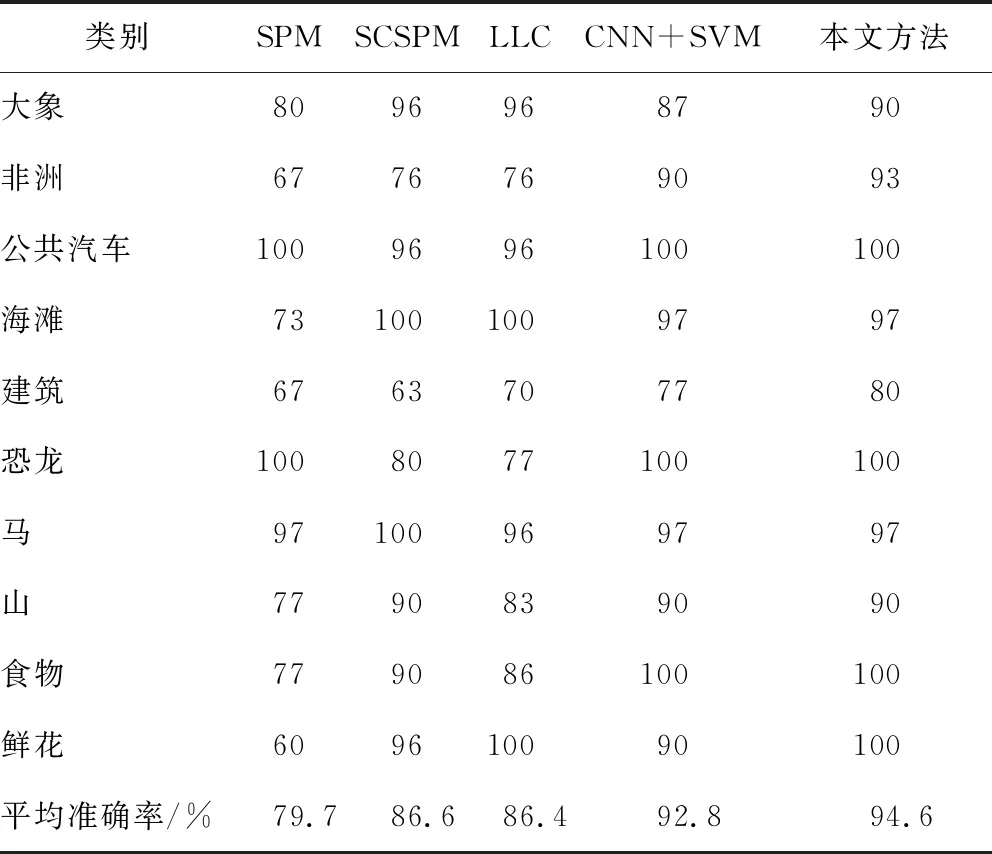
图像描述子的编码特征具有很强的稀疏性,每个描述子的信息可以用与其相关程度最大的K< 为了充分利用描述子的空间位置信息以提升特征向量的表征能力,通过空间金字塔匹配方法将空间信息嵌入到特征描述子中。金字塔分割是对图像第l层(l=0,…,L-1)划分出2l×2l个局部块,通过对多层局部块特征进行融合获得最终编码特征。以L=3层的空间金字塔模型为例,第0层为原图,第1层对图像进行2×2均匀分块,第2层对图像进行4×4均匀分块。设置多层特征的加权拼接权值,其中第0层系数为1/2L-1,第l层系数为1/2L-l-1,则3层金字塔结构的权值系数则为[0.25,0.5,1.0]。最后,对图像每块编码特征进行最大池化,将池化后的特征按分块进行串联,得到维度为(1+4+16)M= 21M的最终图像特征。 采用Liblinear[19]线性分类器。该分类器支持多种l1l2规范的线性SVM,能够提升分类算法效率,其参数可以通过交叉验证的方法确定并设置。每次实验随机挑选图像训练集和测试集,将10次实验的平均分类准确率和标准差作为评价标准。 实验软硬件环境分别为Intel (R) Core (TM) i5-8400H @ 2.8 GHz四核CPU,16 GB RAM,MATLAB 2016a平台。选取现勘5K数据集[20]和Corel 1K数据集进行分类性能测试,现勘5K图像数据集包含10个类别共5 000幅图像,分别为血迹、车辆、指纹、平面图、鞋印、皮肤、纹身、凶器、轮胎和窗户,部分示例如图3所示。Corel 1K数据集包含10个类别共1 000幅图像,分别为大象、非洲、公共汽车、海滩、建筑、恐龙、马、山、食物和鲜花。 图3 现勘5K数据集示例图像 2.2.1 现勘5K数据集图像分类结果 为了充分分析本文算法的分类性能,分别针对局部特征维度、视觉单词个数、近邻个数和SPM层数,在现勘5K数据集上统计各算法分类结果,并比较算法时间复杂度。 当设置近邻个数K=5,视觉单词个数为1 024时,局部特征维度变化对本文算法的平均分类准确率的影响,如图4所示。 从图4可以看出,当局部特征维度为500时,平均分类准确率最高。当局部特征维度小于500维时,随着维度增加,平均分类准确率呈上升趋势。当局部特征维度大于500维时,随着维度增加,平均分类准确率呈下降趋势,主要原因是高维度特征对同类图像个体间的差异比较敏感。 图4 特征维度的大小对分类结果的影响 视觉单词个数M分别取值128、256、512和1 024时,对比不同视觉单词个数对分类准确率的影响,分类结果如图5所示。可以看出,视觉单词个数越大,分类准确率越高,当视觉单词个数为1 024时,分类准确率达到最优。 图5 视觉单词个数对分类结果的影响 当近邻个数K分别取值 2、5、10、20和40时,对比K变化时本文算法的分类性能,结果如图6所示。 图6 LLC编码的近邻个数对分类准确率的影响 从图6中可以看出,较小的近邻个数往往会产生更好的分类精度。当K< 5时,性能开始下降。此外,近邻个数越小,算法运行效率越高,消耗的内存越少。综合考虑分类精度和算法运行效率,K=5为最优近邻个数。 为了进一步证明多尺度SPM[21]中层数对本文算法分类精度的影响,分别与SCSPM和LLC算法在单尺度和多尺度空间情况下进行分类对比实验。实验结果如表1所示。 表1 尺度空间对分类准确率的影响 由表1对比结果可知,图像的多尺度划分粒度越细,3种算法的分类精度越高,且本文算法的分类精度优于SCSPM和LLC算法。 综上实验结果,本文算法的最优参数设置为局部特征维度F=500,视觉单词个数M=1 024,近邻个数K=5,金字塔层数L=3。在最优参数设置下,本文算法在现勘5K数据集分类的混淆矩阵如图7所示。 图7 现勘5K数据集上分类的混淆矩阵 通过混淆矩阵可以看出,血迹、指纹、平面图、鞋印、纹身、凶器和轮胎等获得很好的分类效果,而窗户、纹身类识别精度不够理想,其主要原因是这两类图像的部分内容与其他类别容易混淆。比如,个别窗户图像容易被分类为车辆图像,主要源于窗户玻璃区域与车辆前挡风玻璃区域视觉上十分相似;此外,纹身图像中存在大量皮肤区域,使得其极易被判定为皮肤图像,导致分类错误。 SCSPM编码的时间复杂度为O(M×K),其中K为非零元素个数[8]。近似LLC编码的时间复杂度为O(M+K2),其中M>>K,K为优化算法中近邻个数。SCSPM与近似LLC算法的图像特征编码时间对比如表2所示,可以看出,近似LLC明显低于SCSPM,证明了LLC算法的高效性。 表2 SCSPM与近似LLC平均编码时间 为了验证本文算法的优越性,分别对比本文算法与SPM、SCSPM、LLC和CNN+SVM算法的分类精度,结果如表3所示。 表3 现勘5K数据集上的分类准确率 由表3可以看出,本文算法的分类精度高于SPM、SCSPM、LLC和SVM+CNN等算法,说明通过滑动窗口对图像进行分块并提取CNN特征能有效提高图像内容信息的精确描述,并与特征编码技术进一步结合,能提高图像分类准确率。 2.2.2 Corel 1K数据集图像分类结果 为了进一步验证本文方法的有效性,在Corel 1K数据集上任意挑选70幅图像作为训练样本,剩下的30幅图像作为测试样本。实验结果的混淆矩阵如图8所示。 图8 Corel 1K数据集上分类的混淆矩阵 在Corel 1K数据集上,分别对比本文算法与SPM、SCSPM、LLC和CNN+SVM算法的各类上的分类准确率与平均分类准确率,结果如表4所示。 表4 Corel 1K数据集上的分类准确率 从表4可以看出,本文算法虽然在某些类别中分类精度低于比较算法,但平均分类准确率达到最高。 基于深度卷积特征与近似LLC编码的现勘图像分类算法,使用滑动窗口法对图像分块,并利用CNN网络提取分块图像的深度特征,进而进行PCA降维和白化处理;将局部图像深度特征进行近似LLC编码,并进行最大池化和空间金字塔匹配处理;最后,采用线性分类器实现现勘图像分类。实验结果表明,本文算法的分类准确率高于SPM、SCSPM、LLC和CNN+SVM等分类算法。1.6 分类器选择
2 实验
2.1 实验设置及数据集选取

2.2 实验结果分析


3 结语
