基于敏感信息邻近抵抗的匿名方法
2020-12-16吕永军程小辉
桂 琼,吕永军,程小辉
(1.桂林理工大学 信息科学与工程学院,广西 桂林 541004; 2.武汉理工大学 信息工程学院,武汉 430070)
0 概述
在大数据背景下,海量数据的共享与应用极大地推动了社会的发展,但同时也带来了隐私保护问题。在这种情况下,数据匿名技术可以有效降低攻击者获取个人敏感信息的概率,同时保证数据的可用性。匿名化以其安全性和有效性成为保护数据隐私的一个有效方法,近年来在社会中受到广泛关注。
匿名化操作方式一般是删除记录中标识符属性,随后发布数据,但是链接攻击会通过发布数据中准标识符属性进行唯一识别元组导致隐私泄露。研究人员提出诸多匿名模型,如k-匿名模型[1]、l-多样性[2]和t-近邻[3]等,在对元组敏感属性赋约束时,提出(α,k)-匿名模型[4]、(k,e)-匿名模型[5]和(,m)-匿名模型[6]等,其中(,m)-匿名模型给出相似性攻击的概念。文献[7]证明如何最优化数据匿名问题为NP-hard。在已发布数据确保隐私保护的同时,支持有效的数据分析有多种不同匿名方法被提出[8-9]。
在信息损失和时间效率优化方面,文献[10]提出一种贪心聚类匿名方法,权衡总体信息损失和匿名时间。依据准标识符对敏感属性分类重要程度,文献[11]提出一种基于权重属性熵的分类匿名方法,根据不同敏感属性的权重属性熵大小对数据集进行有利划分。文献[12]提出面向缺失数据的方法,强调保留原始数据特性,在面向包含关系和事务属性的数据时,又提出(k,l)-多样化模型[13],在保障数据可用性的同时实现更高的效率。文献[14]提出数据中敏感属性分配敏感度级别方法。文献[15]提出基于属性值语义边缘划分方法。文献[16]提出面向多敏感属性的匿名方法。
考虑同一等价类语义相近的敏感属性,攻击者通过相似性攻击提高了个人隐私泄露概率。(ε,m)-匿名模型可以有效抵抗相似性攻击,但未对分类敏感属性分类问题提出解决方案。文献[17]提出一种抵制相似性攻击的(p,k,d)-匿名模型,要求每个等价类至少包含p个d-相异的敏感值阻止相似性攻击,有效保护了个人隐私,但会造成不必要的信息损失。本文对分类敏感属性进行研究,构建一种敏感信息邻近抵抗的(r,k)-匿名模型,并给出基于敏感属性邻近抵抗的匿名方法GDPPR。
1 基本概念
令T为原始数据表,A={A1,A2,…,An}分别对应表中元组的n个属性。其中,标识属性表示唯一识别个人身份的属性,如“Name”属性,在发布的原始数据中被移除。准标识符属性表示通过组合可以唯一标识个人身份的属性,如“Age”“Gender”和“ZipCode”等属性。设定“Disease”为敏感属性,即涉及隐私信息的属性。发布的原始数据表如表1所示。
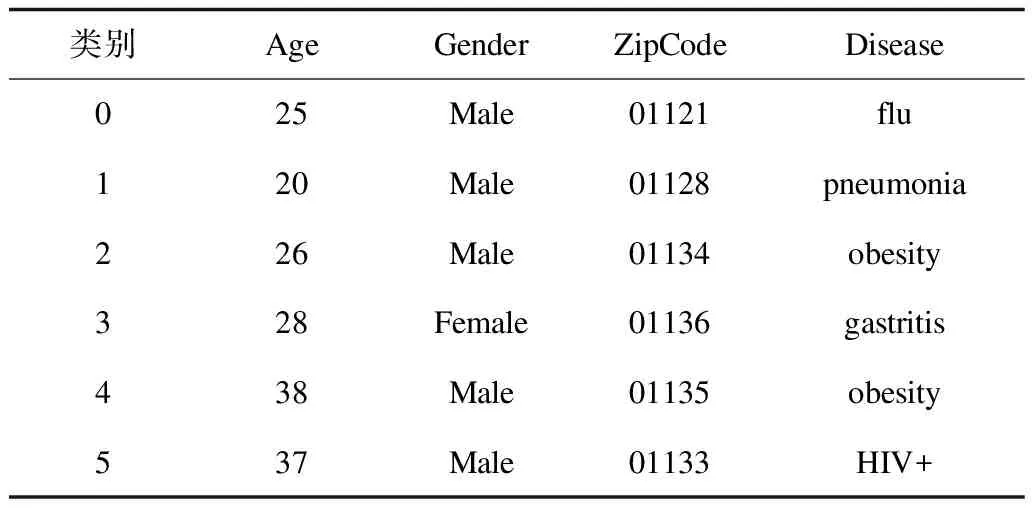
表1 原始数据表Table 1 Raw data table
使用区间或者模糊的值取代原数据中具体的属性值的过程称为数据泛化,为保留数据语义,需要对元组属性建立泛化层次结构,如图1所示。
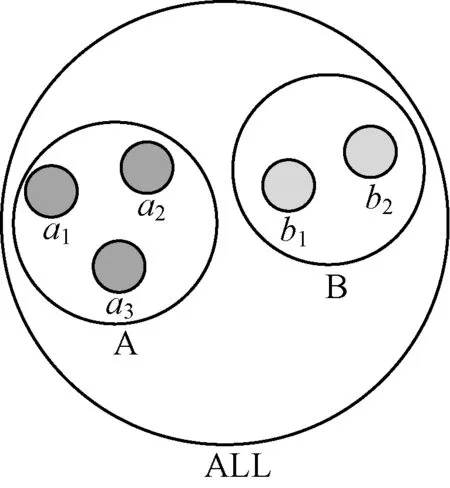
图1 泛化层次结构
不同元组属性有不同的泛化层次,为减少信息损失,需要寻找泛化层次中替代相应取值的最低公共子节点。
在数据表T中,每个等价类满足至少有k个元组准标识符属性不可区分,那么该数据表T满足k-匿名模型。表2为满足3-匿名模型的匿名数据。

表2 满足3-匿名模型的数据Table 2 Data satisfying the 3-anonymity model
定义1(隐私泄露风险) 在数据表T中,同一等价类相邻语义下敏感属性集合取值频率,称为泄露风险。结合分类敏感属性特性,改进泄露风险R[18],定义等价类中的泄露风险R(ci):
(1)
在同一等价类中,cRSA表示用户可容忍发布的最低层次下语义关联敏感属性值,cSA表示敏感属性值。如表2的等价类1中,敏感属性flu、pneumonia属于呼吸系统类疾病,被攻击者推断出,造成隐私泄露。数据被划分为p个等价类时,定义数据表T的泄露风险为:
R(T)=max(R(ci)),i=1,2,…,p
(2)
本文基于属性相似度衡量信息损失,属性间相似度越高,泛化造成的信息损失就越少。
根据原始数据表T,得到匿名表T*产生的信息损失为:

(3)
其中,IL(ci)表示T*中等价类通过泛化产生的信息损失,p表示等价类数量。根据等价类中各元组的准标识符不可区分,产生的信息损失相同,信息损失如式(4)所示:
IL(ci)=|ci|IL(t)
(4)
IL(t)表示元组信息损失,如式(5)所示:

(5)
其中,ωi表示元组中不同的准标识符所占权重,IL(Ai)表示某一准标识符的信息损失,信息损失如式(6)所示:
(6)
其中,f(Ai)表示准标识符节点集合泛化结构层次路径长度,root表示泛化层次根节点路径长度。数值属性的泛化层次结构通过差异程度表示,分类属性的泛化层次结构通过集合表示。
在数据表T中,元组抑制时产生的信息损失最高。T*产生的信息损失与数据抑制产生的信息损失的比值称为损失率,如式(7)所示:
(7)

定义2(距离定义) 在数据表T中,元组相似度距离通过准标识符与敏感属性结合来表示。在准标识符中,元组与簇中心计算公式如式(8)所示:
(8)
其中,dt(ni)、dt(cj)分别表示数值属性和分类属性的相似度距离,n、c分别表示元组中数值和分类属性的数量,ω表示属性权重,取值取决于在聚类过程中元组准标识符对属性选取的重视程度,且需要满足0≤ω≤1。
定义3(敏感属性相异度) 在语义角度分析下,通过敏感属性的相似度构造层次结构,得出元组的敏感属性相异度公式如式(9)所示:
(9)
其中,h(a,b)表示敏感属性值所属泛化分类层次最小公共节点路径长度,roots表示敏感属性语义层次根节点路径长度。
本文采用模糊聚类技术,根据隶属度矩阵划分簇,结合敏感属性相异度得出距离矩阵,矩阵公式如式(10)所示:
(10)
其中,权重α、β分别表示元组准标识符和敏感属性权重参数,体现数据拥有者对元组属性的重视程度,且满足α+β=1。
2 敏感属性邻近抵抗的匿名模型
在匿名模型中通常假定敏感属性值之间相互独立,在相似性攻击下则无法保障个人匿名需求,本文考虑敏感属性相异度,在k-匿名模型基础上加以改进。
定义4((r,k)-匿名模型) 设原始数据表为T,匿名数据表为T*。当匿名表T*满足k-匿名时,等价类中至少有k个除敏感属性外不可区分的元组,同时满足敏感属性的邻近属性取值频率不超过阈值r(0≤r≤1),即:
其中,C={c1,c2,…,cn}为等价类集合,在同一等价类中,cSA表示敏感属性,cRSA表示具有语义关联的敏感属性。
在表2中,由于k-匿名未约束敏感属性,当攻击者通过背景知识推断出患者ANDY在第1个等价类中,将推断其患有呼吸系统疾病。本文设计(r,k)-匿名模型对原始数据表匿名化,如表3所示,由于每个等价类中敏感属性语义层次结构父节点不同,攻击者进而无法分析ANDY患有哪类疾病,从而降低隐私泄露风险。

表3 满足(0.5,3)-匿名模型的数据Table 3 Data satisfying the (0.5,3)-anonymity model
3 GDPPR算法
3.1 算法思想
GDPPR算法的核心思想在于敏感属性基于语义关联定义层次结构,按照元组属于每个簇的概率完成簇的划分。根据不同属性泛化层次结构进行泛化。
算法1GDPPR算法
输入数据集T,匿名参数k,选择聚类数p,模糊指标m,聚类中心阈值f,隐私泄露阈值r
输出满足(r,k)-多样性的匿名数据表T*
1.Random initialization membership matrix Dn×p;
2.Traversing data records tiin T,i=1,2,…,n;
3.for j=1 to p do
4.Calculate Cluster Center cj;
5.end for
6.for i=1 to n do
7.for j=1 to p do
8.Calculating membership dij=αdtij+βdtij(s);
9.end for
10.end for
11.counter e=0;
12.while Number of iterations e > E,E:maximum number of iterations do
13.if Maximum difference between adjacent cluster centers< f then
14.Stop the iteration;
15.else
16.Recalculate the cluster center set C;
17.Update the membership matrix D;
18.e=e+1;
19.end if
20.end while
21.Dividing clusters according to the determined membership matrix;
22.for i=1 to n do
23.if The Privacy disclosure threshold < r then
24.Find the maximum membership probability of the tuple tibelonging to the cluster in the membership matrix cj;
25.Let tuple tibelong to the cluster;
26.end if
27.end for
28.for j=1 to p do
29.Generalize the divided clusters by defining a generalization strategy to obtain equivalence classes C;
30.T*=T*+C;
31.end for
32.Get cluster result T*.
对GDPPR算法描述如下:
1)步骤8计算元组与簇中心距离,形成距离矩阵D。
2)步骤13通过判断迭代前后最大簇中心距离是否小于阈值f,不满足则需重新计算簇中心,更新距离矩阵,直到满足条件为止。
3)步骤29在泛化过程中结合元组的敏感属性值对准标识符进行层次泛化,形成满足(r,k)-匿名模型的等价类,得出匿名表T*。
3.2 算法分析
3.2.1 正确性分析
GDPPR算法最终会得出满足(r,k)-匿名模型的匿名表。当簇中心距离变化小于某一阈值时, 对数据集进行簇的划分,结合敏感信息值语义关联,保证划分后每个等价类敏感属性高度相异,形成的等价类中相邻语义敏感属性取值频率不超过隐私泄露阈值r。
3.2.2 时间复杂度分析
在数据集T中,设数据记录数量为n,准标识符为m,算法中划分p个等价类。首先遍历数据集,时间复杂度为O(n)。初始化距离矩阵并计算簇中心,复杂度为O(p)。循环执行步骤3~步骤10,不断更新簇中心和距离矩阵,当簇中心变化阈值小于f或迭代次数超过指定次数E时循环停止,时间复杂度不高于O(enp),e表示迭代运行次数。步骤24通过距离矩阵划分簇,时间复杂度为O(np)。最后在步骤29依次泛化簇中元组属性,时间复杂度为O(mp)。在整体执行过程中,GDPPR算法总的时间复杂度为O(enp)。
3.2.3 隐私泄露风险分析
针对隐私泄露,对敏感属性给出约束条件,满足每个等价类中相邻语义敏感属性取值频率不超过阈值r。根据数据拥有者对属性的重视程度,结合式(9),当权重值β较高时,可达到较高的隐私抵抗效果。
4 实验结果与分析
本节验证GDPPR算法性能,并与Mondrian算法[19]进行对比,实验从数据效用、隐私泄露风险和执行时间[20]进行对比分析。Mondrian算法采用贪婪算法查找等价类,基于工作负载查询泛化元组属性,泛化策略使用多维重新编码方法。实验选取UCI机器学习库中的Adult数据集和Census-Income数据集,实验环境为Intel®CoreTMi5-4210M CPU @2.60 GHz,4 GB RAM,操作系统为Microsoft Windows10。算法GDPPR和Mondrian均使用java代码实现。
4.1 Adult数据集
Adult数据集描述了1996年美国人口统计数据的一部分,包含15个属性。删除含有缺失值的记录,得到包含有45 222个数据记录的数据表。实验中主要提取其中9个具有代表性的数据属性进行验证,即gender、age、race、marital-status、educations、native-country、workclass、occupation和salary-class。设定occupation为敏感属性,其余8个为准标识符,在准标识符中,age为数值属性,其余7个为分类属性,分类属性的泛化层次结构分别由2个~4个层次结构组成。
本文将Adult数据集中准标识符属性权重均设为1。选取不同匿名参数k下数据集的信息损失、执行时间在准标识符组中(QI)的变化,以及不同QI值下信息损失、隐私泄露风险和执行时间随匿名参数k值的变化情况。设定阈值参数r=0.25,根据式(9)设定重视参数α=0.5,β=0.5。具体实验数据如表4和表5所示。
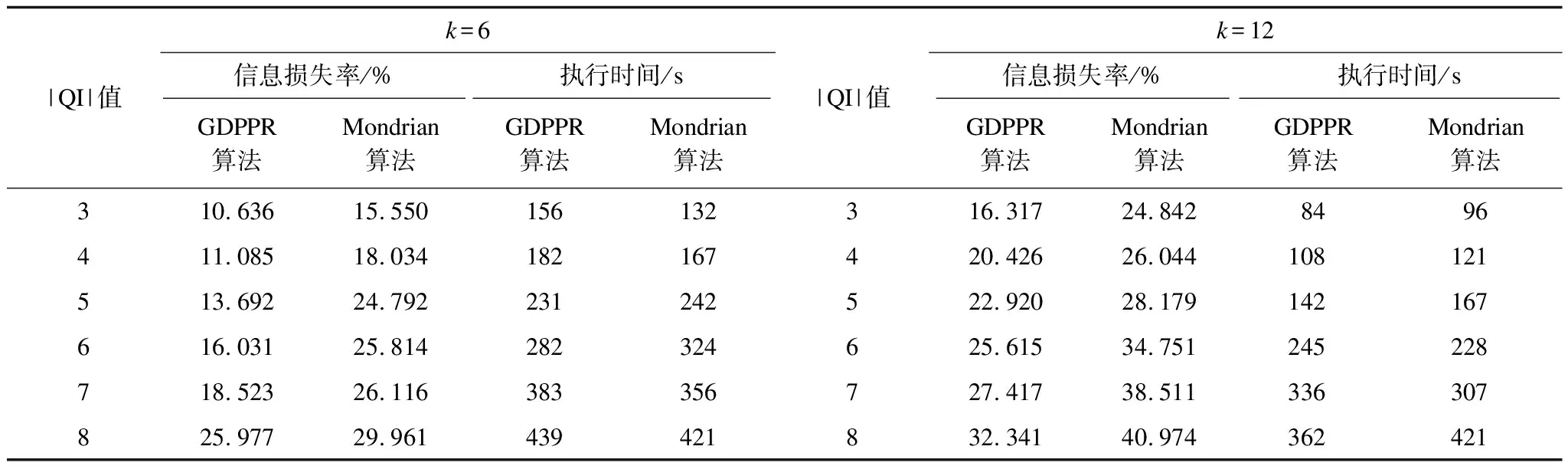
表4 Adult数据集|QI|值变化的运行结果Table 4 Operation results of |QI| value change of Adult dataset

表5 Adult数据集k值变化的运行结果Table 5 Operation results of k value change of Adult dataset
4.1.1 可用性分析
图2给出当k=6和k=12时,|QI|值的变化在GDPPR算法和Mondrian算法中对Adult数据集的信息损失影响,信息损失均使用损失率RIL表示。
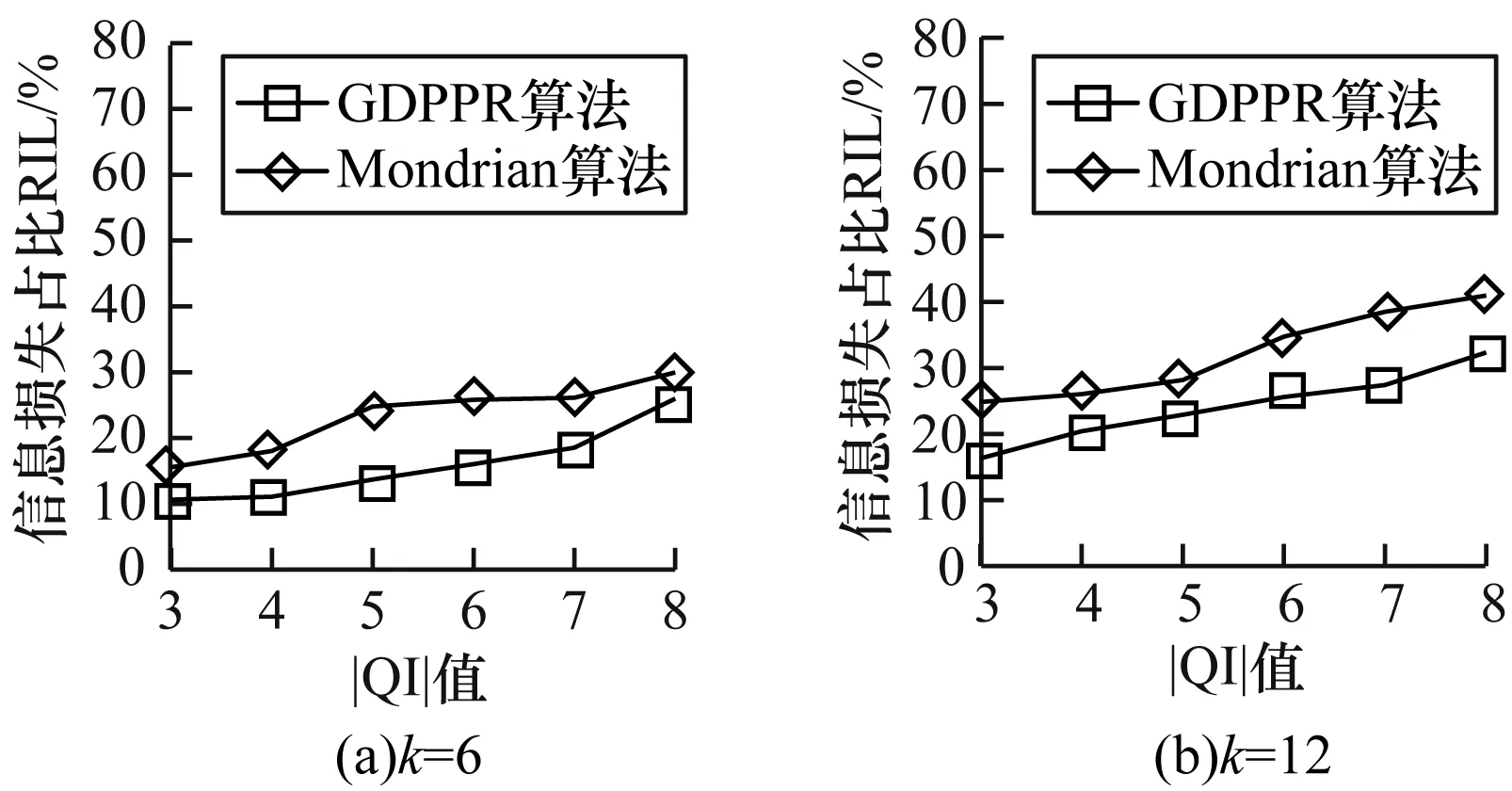
图2 Adult数据集|QI|值变化信息损失的对比结果
从图2可以看出,GDPPR算法泛化产生的信息损失要比Mondrian算法小。随着QI维度的增加,信息损失逐步增加。在同等环境下,GDPPR算法可以减少约7%的信息损失。
图3给出当|QI|=4和|QI|=8时,k值的变化对Adult数据集的信息损失影响。
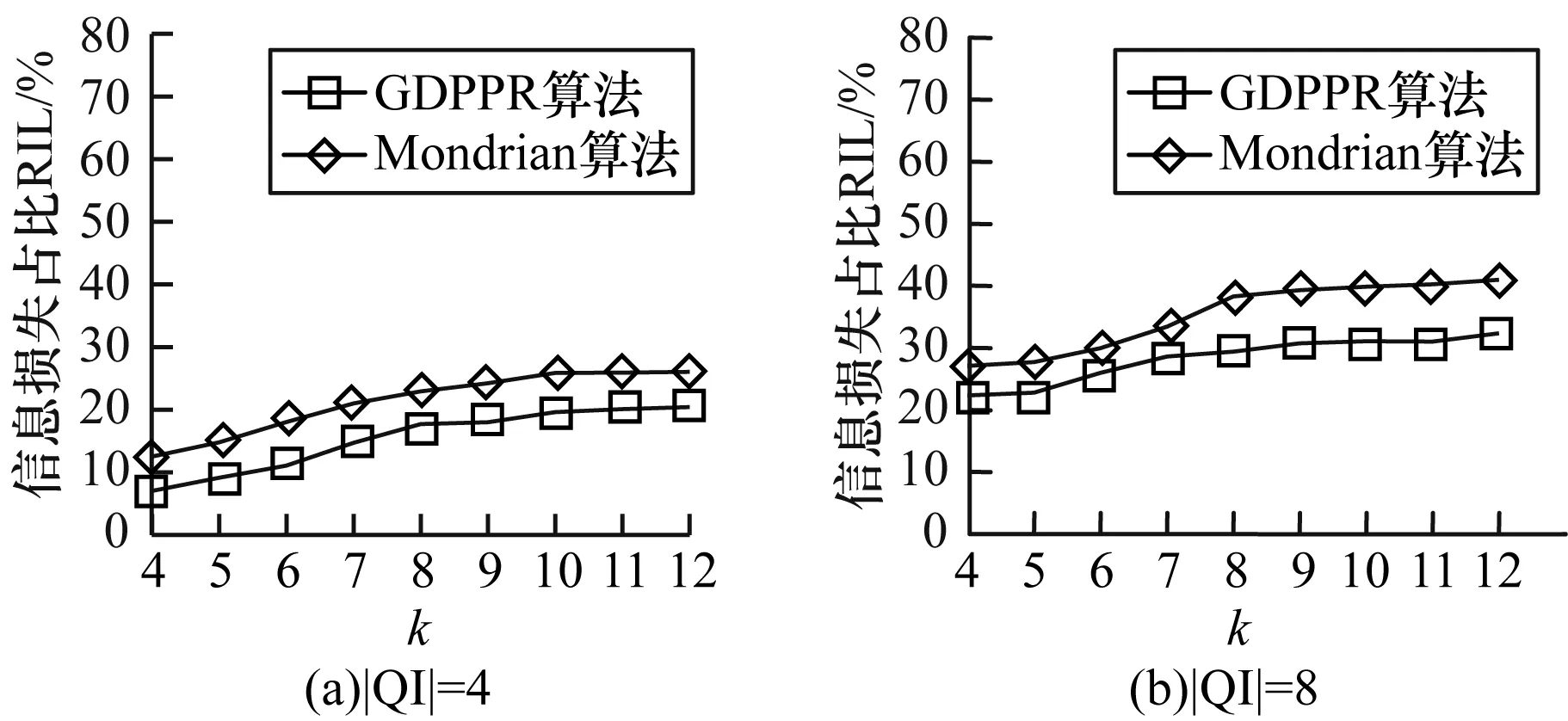
图3 Adult数据集k值变化信息损失的对比结果
从图3可以看出,在k值不断增大时,造成的信息损失在不断增大,由于k值的增大会导致等价类中元组数量增加,进而信息损失增加。但GDPPR算法信息损失在整体上少于Mondrian算法。在同等运行环境下,GDPPR算法减少约6%的信息损失。
4.1.2 泄露风险分析
隐私泄露风险主要取决于k的取值,图4给出|QI|=4和|QI|=8时,k值的变化在GDPPR算法和Mondrian算法中对Adult数据集的隐私泄露风险影响。
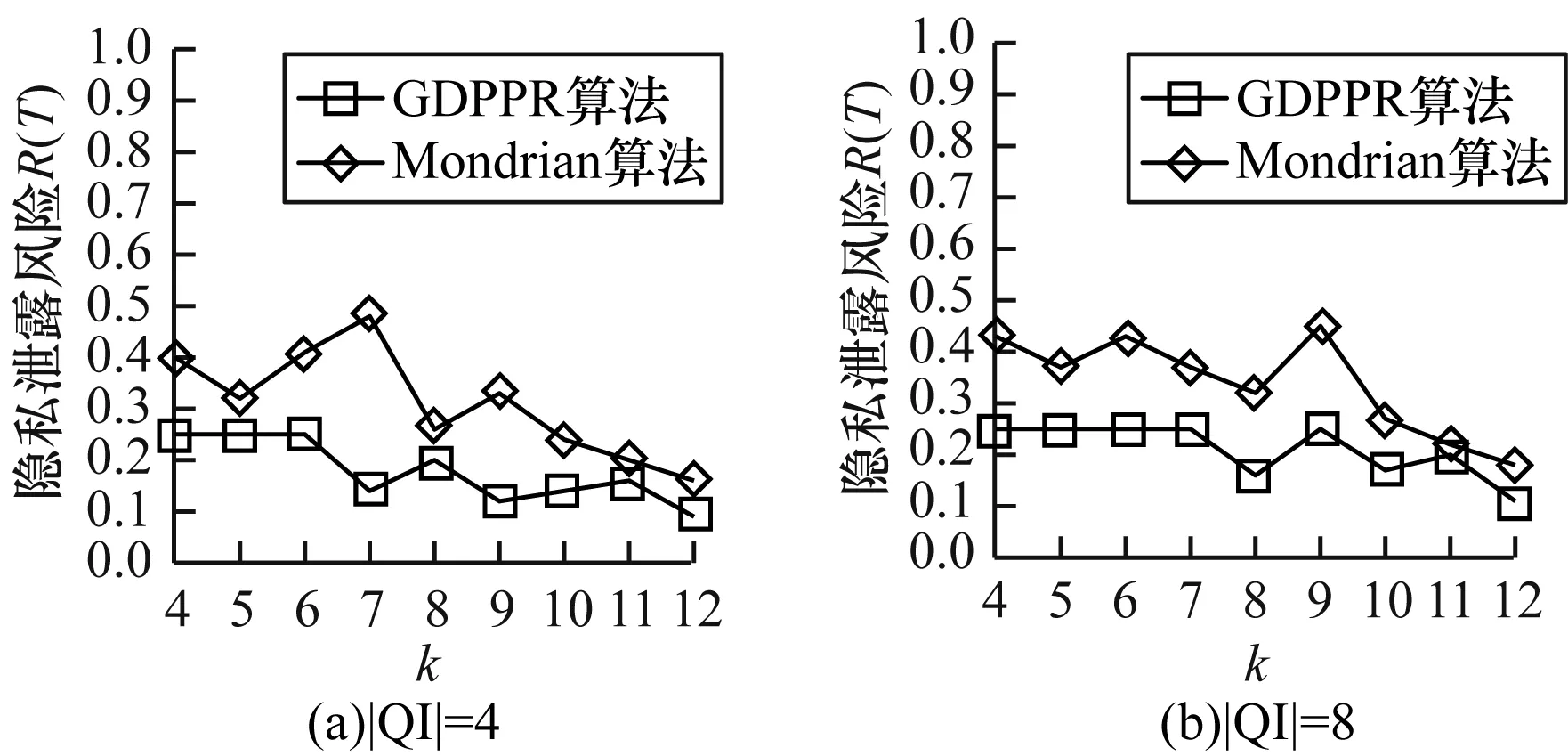
图4 Adult数据集k值变化下隐私泄露风险的对比结果
从图4可以看出,GDPPR算法须满足每个等价类中的敏感属性隐私泄露阈值不得超过0.25,Mondrian算法则无此约束,随着k值的增加,GDPPR算法和Mondrian算法中隐私泄露风险分布无明显规律,但整体上逐步降低。Mondrian算法的隐私泄露风险值偏高,不足以抵抗相似性攻击。
4.1.3 执行时间分析
图5给出当k=6和k=12时,|QI|值的变化对GDPPR算法和Mondrian算法执行时间的影响。
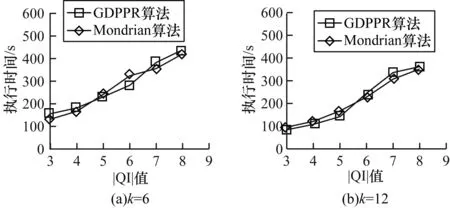
图5 Adult数据集|QI|值变化下执行时间的对比结果
从图5可以看出,GDPPR和Mondrian算法计算开销区别差异不大,随着QI维度的增加,执行时间随之增加。这是由于QI的增加导致元组之间的距离计算开销增加,进而使得实验整体执行时间增加。
图6给出当|QI|=4和|QI|=8时,k值的变化对GDPPR算法和Mondrian算法执行时间的影响。
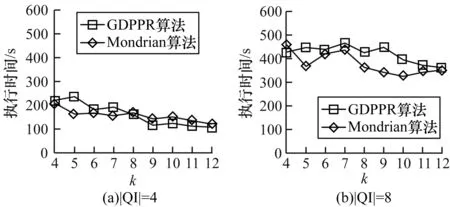
图6 Adult数据集k值变化下执行时间的对比结果
从图6可以看出,GDPPR和Mondrian算法执行时间整体减小,k值增加会导致匿名表中的每个等价类元组数量增加,构造等价类的时间开销将会增大。但整个数据集元组固定,进而出现等价类个数减少,算法整体的运行时间变化幅度不大。
4.2 Census-Income数据集
Census-Income数据集包含1970年、1980年和1990年来自洛杉矶和长滩地区的未加权PUMS人口普查数据,包含有42个属性、199 523条记录,为降低计算开销,本文随机截取20%数据记录并删除含有缺失值的记录,得出包含38 024个数据记录的数据表。主要提取8个具有代表性的数据属性,即age、sex、race、marital-status、education、country of birth self、class of worker、major occupation code。设定major occupation code为敏感属性,其余为准标识符,在准标识符中,age为数值属性,其余为分类属性,泛化层次有2个~4个。
本文将Census-Income数据集中准标识符属性权重均设为1。分别选取不同参数k下Census-Income数据集的信息损失、执行时间在准标识符组中|QI|值的变化,以及不同|QI|值下的据信息损失、隐私泄露风险和执行时间随匿名参数k值的变化情况,实验中设定阈值参数r=0.40。设定重视参数α=0.5,β=0.5。具体实验数据如表6和表7所示。
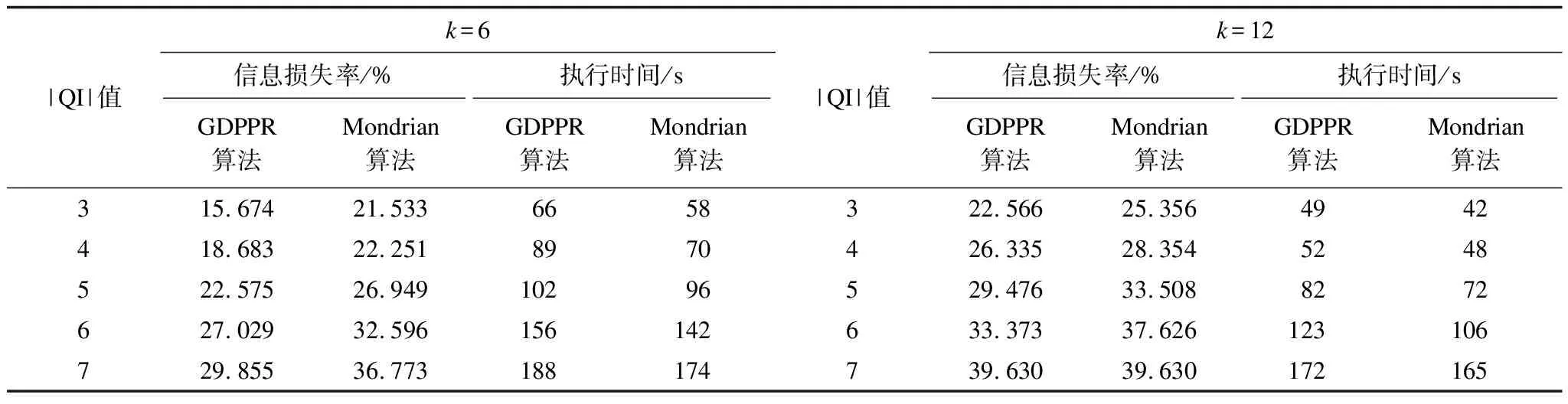
表6 Census-Income数据集|QI|值变化的运行结果Table 6 Operation results of |QI| value change of Census-Income dataset

表7 Census-Income数据集k变化的运行结果Table 7 Operation results of k value change of Census-Income dataset
4.2.1 数据可用性分析
图7给出当k=6和k=12时,|QI|值变化在GDPPR算法和Mondrian算法中对Census-Income数据集的信息损失影响,信息损失通过损失率RIL表示。

图7 Census-Income数据集|QI|变化信息损失的对比结果
从图7可以看出,GDPPR算法在Census-Income数据集下泛化产生的信息损失要比Mondrian算法少。随着QI维度的增加,信息损失也在增加。在同等环境下,GDPPR算法可以实现减少约5%的信息损失。
图8给出了当|QI|=3和|QI|=6时,k值的变化对Census-Income数据集的信息损失影响。

图8 Census-Income数据集k值变化信息损失的对比结果
从图8可以看出,当k值不断增大时,造成的信息损失不断增大,但GDPPR算法略小于Mondrian算法。当k值增大时,导致等价类中元组数量在增加,信息损失也在增加。在同等运行环境下,GDPPR算法可以减少约6%的信息损失。
4.2.2 泄露风险分析
隐私泄露风险主要取决于k的取值。图9给出当|QI|=3和|QI|=6时,k值的变化在GDPPR算法和Mondrian算法中对Census-Income数据集的隐私泄露风险影响。
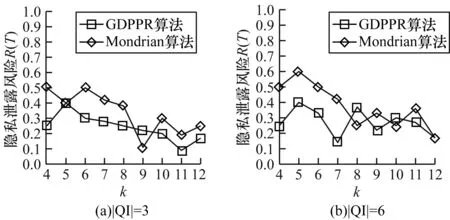
图9 Census-Income数据集k值变化下隐私泄露风险对比结果
从图9可以看出,随着k值的增加,GDPPR算法和Mondrian算法中隐私泄露风险整体上逐步降低。但由于Mondrian算法未考虑敏感属性语义关联,相比GDPPR算法,Mondrian算法的隐私泄露风险值偏高。
4.2.3 执行时间分析
图10给当在k=6和k=12时,|QI|的变化对GDPPR算法和Mondrian算法执行时间的影响。

图10 Census-Income数据集|QI|值变化下执行时间的对比结果
从图10可以看出,GDPPR和Mondrian算法执行时间差异不大,随着QI维度的不断增加,执行时间也随之增加。这是由于QI增加导致元组距离计算开销增加,进而使得执行时间增加。
图11给出当|QI|=3和|QI|=6时,k值的变化对GDPPR算法和Mondrian算法执行时间的影响。
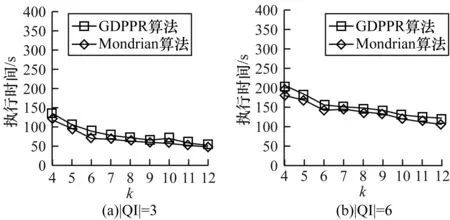
图11 Census-Income数据集k值变化下执行时间对比
从图11可以看出,随着k值的变化,GDPPR算法和Mondrian算法的执行时间逐步减少,但总的执行时间变化幅度较小,且相差也较小。
5 结束语
本文针对相似性攻击造成隐私泄露的问题,设计一种基于敏感信息邻近抵抗的(r,k)-匿名模型,并提出一种满足该模型的匿名方法GDPPR。该方法根据敏感属性的语义关联,保证所发布的数据满足(r,k)-匿名模型。通过多组实验的比较分析验证了该算法有效性,泛化后的匿名表降低了相似攻击造成的隐私泄露几率,减少了信息损失。下一步将考虑元组属性间函数依赖在匿名化后对信息损失的影响,以及匿名模型k值选取的优化问题,进一步提高执行效率。
