水声目标分类算法性能评估
2020-12-15徐源超蔡志明
徐源超,蔡志明
(海军工程大学 电子工程学院,湖北 武汉 430033)
机器学习中的许多指标从不同侧面反映分类算法性能,但它们有各自的使用限制[1]。样本不平衡较严重时,性能指标的指示敏感性与波动性将不可忽视[2-3];一些指标具有相似性质[4],应避免重复选择。因此,针对不同场景需求,须选择合适指标,以便恰当描述算法性能。例如医学领域常用灵敏度和特异性,信息检索领域中常用查全率和查准率。水声目标分类研究中,传统上只使用“正确率”等简单指标,这难以客观、全面反映分类算法性能。在水声目标分类领域建立统一的性能指标体系,将有助于分析和比较算法性能,指导算法研究。本文将分析常用性能指标的性质,结合水声场景需求,给出一套分类算法性能指标体系。
确定性能指标后,需设计评估方法,在有限的数据集上估计性能指标值。任何评估方法都存在误差(包括方差和偏差),它们不仅与数据集中的噪声有关,还与划分训练集测试集的方式[5-7]、数据集的大小及平衡性[8]等因素有关。性能评估时要根据具体情况选择合适的评估方法,权衡估计偏差和方差。本文将分析常用评估方法的估值差异,推荐适合水声场景的评估方法。
1 分类算法性能指标
常用分类算法性能指标包括基于混淆矩阵和基于预测得分2大类[1]。分类器包括模型和门限2个部分,模型f对样本xi的评分为f(xi),门限与之比较得到分类结果。模型和门限参数都在训练集中习得,测试集用于估计性能指标值。基于混淆矩阵的指标利用离散的分类结果评估分类器性能,基于预测得分的指标则利用了样本评分。
1.1 基于混淆矩阵的指标
对二分类问题,给定包含m个样本的测试集,用分类器预测样本类别,可得混淆矩阵如表1所示。常用的基于混淆矩阵的指标定义如表2所示。
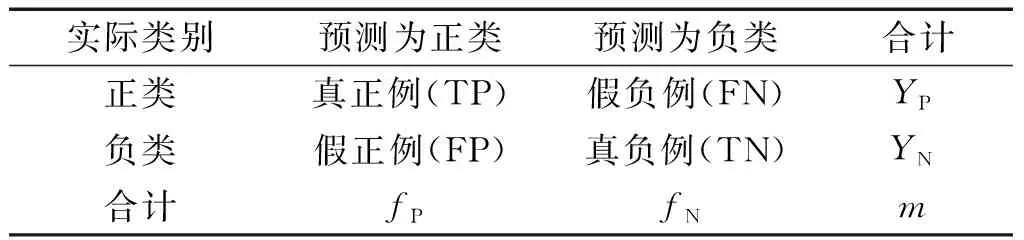
表1 混淆矩阵Table 1 Confusion matrix

表2 基于混淆矩阵的性能指标Table 2 Performance metrics based on confusion matrix
1)真正例率和假正例率对应信号检测中的检测率和虚警率。检测理论中,检测率和虚警率常由似然函数推导求得;而作为分类器性能指标,可理解为基于样本集得到的估计值。2)灵敏度和特异性常用于医疗领域,分别描述分类器对阳性和阴性的检出能力。3)阳性和阴性预测值也常用于医疗,描述检出的阳性(阴性)中确为阳性(阴性)的概率。4)查全率和查准率常用于信息检索领域,分别描述检索目标信息的全面性和检出信息的准确性。
这4组指标描述分类器对2类目标的查全能力(TPR、TNR)和查准能力(PPV、NPV),它们在不同领域根据需求成对使用。TPR和TNR受样本不平衡影响小,PPV和NPV则不然。
每组指标通常相互制约,因此多个指标虽有助于理解分类器却不便于比较,而融合指标可用于综合判断。融合方法一般包括算术、几何和调和平均。可融合分类器对各类的查全能力,或融合对某一类的查全能力和查准能力。
常用的指标正确率实际上就是融合指标:
(1)
样本不平衡时,正确率受样本更多的类别的查全率影响大。均衡正确率AccB对TPR和TNR作权值相等的算术平均,更适用于样本不平衡的情况。
几何/调和平均中的小值会“拉低”均值结果,而算术平均更容忍“偏科”的分类器。F1是查全率和查准率的调和平均值。常用的还有查全率几何平均GM1,查全率查准率几何平均GM2。
1.2 基于预测得分的指标
基于预测得分的指标利用样本评分信息,包括图形指标和标量指标。接收机工作特性(receiver operating characteristic, ROC)曲线是一种广泛应用的图形指标。信号检测理论中,ROC用来分析检测器的性能,确定合适的门限以平衡检测率和虚警率。同样地,ROC曲线描述分类器改变门限时的TPR与FPR关系。若某性能指标可由TPR和FPR表示,就可利用ROC曲线来确定门限[9]。
虽然ROC可直观表达分类器全局(不同门限)性能,但若存在标量指标将更方便:AUC是ROC曲线下面积[10],其值越大表明算法性能越好。
PR(precision-recall)曲线也是常用图形指标,描述PPV与TPR关系。ROC曲线上的点与PR曲线上的点是对应的:
(2)
式中:r=YN/YP指示样本类分布。对于不平衡性很强的样本集,PR曲线有时比ROC曲线更合适[11],因为PR曲线包含了r的信息。PR曲线下的面积(AUC_PR)作为对应的标量指标。
2 水声目标分类性能指标
2.1 水声目标分类的场景分析
在选择性能指标时应讨论具体的应用场景,以下分析典型水声目标分类场景:
1)假设分类在检测之后且虚警很小,分类器对目标做水下(正类)或水面的二分类。
2)水下目标与水面目标的类分布不平衡。文献[12]显示,水面目标总量相对水下目标而言绝对大。若仅考虑有威胁的军用目标以及在声纹上较接近军用目标的部分民用目标,不妨假设声呐检测到水面与水下目标数量比约在103量级。
3)错判水下目标为水面目标的代价大于错判水面目标的代价。具体代价难以量化,但可容忍的FPR可被估计。假设声呐工作24 h内检测到目标1 000个,声呐员听音判型的可靠能力为每天100个;如果机器自动分类产生错误或可信度不高,需人工进一步甄别,那么可容忍的FPR=0.1。
4)类分布将随海域、时间等动态变化。不妨假设水面与水下目标数量比在102~103。
5)样本集不平衡,水下目标样本少是常态。
6)设想在应用阶段,分类器给出对目标的评分需,并给出分类结果;对判为水下的目标,声呐员根据对目标的评分由高到低逐一验证或排除。
2.2 性能指标仿真分析
2.2.1 仿真方法
根据水声场景分析和各指标定义,基于仿真[2]讨论指标性质及其在水声目标分类场景的适用性。
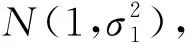
算法B1、B2对正负样本评分的标准差分别为:
利用评分分布函数计算门限,使A1、A2、B1、B2分别控制其FPR于0.05、0.15、0.08、0.12的水平上。仿真产生106个样本评分,使负正样本数量比r=YN/YP在10-3~103内变化,分别画出各指标与r的关系,结果如图1所示。
2.2.2 结果分析
图1(a)、(b)显示TPR和FPR受r影响小,只是当样本极不平衡即其中一类样本太少时,指标值将出现波动,是可靠指标。图1(c)显示PPV随r的变化是单边的:r<1一侧,r减小时PPV变化很小;r>1一侧,r增大时PPV随之减少;r趋于103时,PPV已失去对分类器的鉴别能力。但r变化时,其指标值反映的分类器性能比较结果不变。
图1(d)表明,Acc受样本集的影响大,不同r下分类器的比较结论差别较大,须谨慎使用。
聚焦于查全率的融合,图1(e)、(f)显示算术平均AccB和几何平均GM1这2个指标值均不随r变化,AccB的区分度比GM1稍好些。
聚焦于正类查全率与查准率的融合,图1(i)、(l)中几何平均GM2和调和平均F1随r变化的曲线基本一致。注意到r在102~103范围内各F1值的相对大小与Acc一致,而GM2却有所不同;相比之下,极不平衡条件下F1更能反映真实状况。但这2个指标也对r敏感,且r变化将导致比较结论不一致。
图1(g)、(h)、(j)、(k)是基于预测得分的指标相对r的变化。这类指标是包含全体分类门限取值的系综,因此只比较A、B这2个分类器。图1(g)显示AUC对r不敏感,这是由于TPR和FPR受r影响小。图1(j)是A、B这2个分类器在r=1时的ROC曲线,r不同时ROC曲线变化不大。由于被评估分类器的ROC曲线可能很接近,这时AUC难以显著展现分类器的差异,正如图1(g)中A与B指标值很接近。所以,ROC曲线与AUC虽可反映算法全局性能,且对r基本不敏感,但还不能完全替代基于混淆矩阵的指标。
图1(h)中AUC_PR从r>1开始都可清晰稳定地给出性能鉴别结果,因为该指标包含了样本类分布的信息。图1(k)是A、B这2种算法PR曲线,样本集平衡即r=1时,PR曲线下的面积较大;当增大到r=100,曲线变化明显,对应AUC_PR减小。
2.3 构建性能指标体系
性能评估的目标包括易于比较和易于解释,影响决策的因素有算法的知识建模能力、门限选择和场景需求[13],依此构建性能指标体系。
基于预测得分的图形指标可较全面地反映算法的建模能力。因水声场景中的r值在一定范围内变化,选择对r不敏感的ROC曲线是自然的考虑。但进一步地,水声场景中r很大是确定的,从指标的鉴别能力讲,PR曲线及相应的AUC_PR更有优势。因此选用PR曲线及AUC_PR指标。
基于混淆矩阵的指标反映评分分布结合门限后的分类性能。考虑到实际样本类分布的不确定,显然应选择随r起伏变化小的指标TPR和FPR。考虑到多个指标不便于比较,应设计融合指标。水声场景中希望控制FPR于小值(TNR较大值),更容许“偏科”的算术平均AccB与这一需求相适应。
从学习的角度讲,分类器对复杂知识的建模能力应放在首位。若AUC_PR无显著差异,则需进一步比较AccB。由AccB的定义式可得:
TPR=FPR+2AccB-1
这是ROC曲线图中斜率为1的一族直线,其截距越大表明对应AccB越大。一般地,ROC曲线的切线斜率随FPR单调递减,则ROC曲线上切线斜率为1的切点AccB最大。在水声场景中希望控制FPR=0.1,但FPR=0.1的点不一定是AccB最大点。可修正AccB使FPR=0.1的切点为AccB最大点:
(3)
式中a为ROC曲线上FPR=0.1点的切线斜率。
被比较的分类器有各自的ROC曲线,为统一评价标准,可混合各分类器的样本评分作出平均ROC曲线,然后估计FPR=0.1处的斜率a。若修正AccB依然无显著差异,则选择FPR偏离较小的算法。
综上,由PR曲线及AUC_PR、TPR、FPR及AccB构建性能指标体系。PR曲线反映算法的知识建模能力,标量指标AUC_PR用于比较。AccB和修正AccB反映模型联合门限的分类能力,FPR体现约束,ROC曲线参与对AccB的修正。修正AccB使融合指标更符合水声场景中控制FPR的需求。
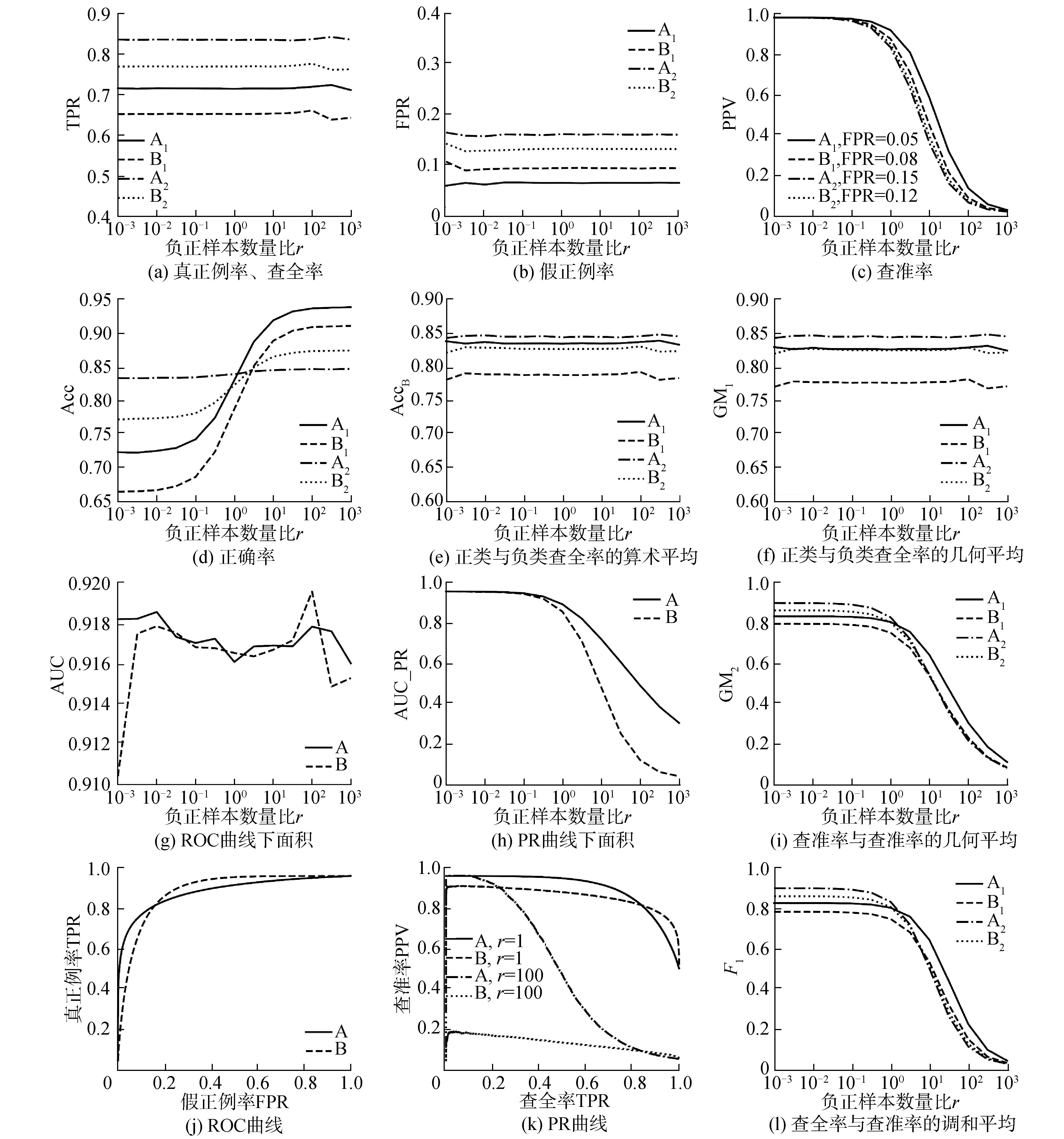
图1 性能指标与r的关系Fig.1 Relationships between performance metrics and r
3 评估方法
3.1 常用性能评估方法
将样本数据划分为训练和测试集,分别用于训练分类器和估计性能指标,这种评估方法称为留置法,需要大量数据。水声目标分类场景中,由于数据有限,应运用重采样的方法来评估算法性能。
重采样是对数据集进行多次划分,综合不同次划分训练集与测试集得到的估计结果,以降低估计误差。从数据集S中选取样本进入训练集,称为采样。重采样方法的选择,就是权衡估计的偏差和方差,以及权衡计算复杂度。本文重点考虑前者。
1)k折交叉验证。k折交叉验证把含有m样本的数据集S随机划分为大小相等且互不相交的k个子集(k≥2)。每个子集轮流用于测试,其余数据用于训练,平均k次估计结果。k增大时估计偏差将变小,因为更多数据参与训练,但估计方差将变大且计算量增加[5]。一般将k设置为10[14]。
2)分层k折交叉验证。样本不平衡时,可控制对数据集S的划分,使k个子集的样本类分布与S的类分布一致,这样可减小估计的方差[15]。
3)自助法。假设S中包含的类模式是充分的,能代表实际对象的全部特征形态,则样本不足时,可通过“有放回采样”得到足够多的训练样本。对含有m个样本的S进行m次有放回采样得到训练集,未被采样到的样本构成测试集,即完成一次划分;如此重复n次(通常n≥200[1])取均值。
由于每次采样后的样本又被放回S,训练集中可能包含重复样本,对于一些无法从重复样本中获得训练增益的算法,自助法将不适用。
4)632自助法。自助法是在每一轮训练中只使用了63.2%的数据,估计偏差较大。可综合训练集与测试集上的指标估计值进行修正:
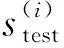
5)重复k折交叉验证。n×k折交叉验证是重复n次k折交叉验证,每次交叉验证作出不同的训练集与测试集的随机划分。最常用的是5×2CV和10×10CV,即重复5次2折交叉验证和重复10次10折交叉验证。对重复的验证结果再做平均。
3.2 评估方法仿真分析
3.2.1 仿真方法
为探究各评估方法在数据集大小不同、样本类分布不同情况下评估结果的差异,设计仿真试验。为简便且不失一般性,假设被评估算法对正类的评分服从N(1,0.52),对负类的评分服从N(0,0.52),算法在训练集上习得门限使AccB最优,并利用测试集估计AccB。由评分分布函数对称性可知最佳门限为0.5,此时AccB≈0.841 3,以此作为真值考察各评估方法的估计偏差和方差。须注意,基于机器学习的分类算法可能存在过拟合,并非数据集S以及训练集在绝对意义上越大越有利。但这里讨论的基于最优AccB的门限选择算法,将倾向于S的规模增长与类分布平衡,这是不难理解的。
考察自助法(Boot.)、632自助法(632Boot.)、10折交叉验证(10CV)、分层10折交叉验证(S10CV)、5×2CV和10×10CV。2种自助法均迭代200次,5×2CV和10×10CV均采用分层方法。设置6组试验:第1组考察样本少的情况,第2、3组考察样本不平衡的情况,第4、5、6组样本量逐渐增加。
图2为试验1 000次估值的箱线图,展示不同样本集设置下各评估方法的估值分布。图中虚线为真值,三角为均值,箱子两端为四分位数,延长线端点为极值。均值相对真值的偏离反映估计偏差,箱子及延长线的长短反映估计方差。为进一步定量比较估计结果差异,在0.05的显著性水平下利用F检验考察方差差异,在0.1的显著性水平下利用Games-Howell单因素方差分析考察偏差差异。
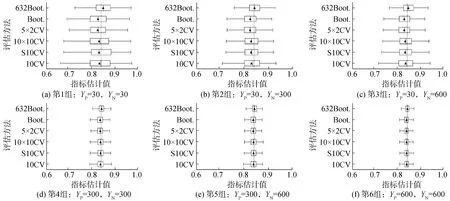
图2 各评估方法在不同样本集下的估计值分布Fig.2 Estimates distribution of each evaluation method in different sample sets
3.2.2 结果分析
总体上看,随着样本量增加,估计的方差和偏差都在减小。虽然第3、4组样本量相当,但第3组估计误差较大。这表明,估计误差受样本不平衡影响,且很大程度上取决于样本最少类的样本量。
2种自助法的方差都较小,特别是第1、2、3组中,2种自助法相对其他方法的方差差异更加显著,其中632自助法偏差较小。因此,样本很少或极不平衡时,采用632自助法是很好的选择。自助法关于模式充分的假设,在水声场景中难以满足,实际上也不会被采用,但这里可合理地将632自助法(以下简称自助法)作为良好的比较对象。
第1、2、3组中,5×2CV与自助法的方差最为接近。第2、3组中,5×2CV相对其他交叉验证的方差差异显著。第2组中5×2CV相对S10CV和10×10CV的偏差差异显著,但第3组的偏差差异已不明显。因此整体上看,样本少或不平衡时推荐5×2CV。
第2、3组中,S10CV与10CV的方差差异显著,而二者偏差相当,说明分层交叉验证可在样本不平衡的情况下减小估计的方差却不增大偏差。
第4、5、6组中,5×2CV、S10CV和10×10CV的偏差均无明显差异;第4、5组中5×2CV相对S10CV和10×10CV方差差异显著,而第6组中三者方差无明显差异。数据集规模从小到大增加过程中,无论数据平衡性的变化,5×2CV方法始终相对较好,样本足够多时3种交叉验证方法则差异不大了。
当然,若可掌握数据集规模与分布的详实知识,可给出其相适应的最优评估方法建议,如表3的归纳所示。但在实际的水声场景中,确认数据集S的规模为大、中、小是比较困难的。

表3 评估方法选择参照表Table 3 Evaluation method selection reference table
3.3 水声场景中评估方法的选择
由于信道时变空变以及目标的动态复杂性,水声目标测量数据模式丰富,短期局部范围内所形成的数据集往往难以代表实际,不宜使用自助法。
水声目标数据不平衡,往往水下目标(正类)数据匮乏。推荐5×2CV,且采用分层交叉验证。
随着数据规模的积累,数据模式逐渐丰富,在采用分层交叉验证的基础上,可考虑根据不同的海域、海况、工况等因素,对数据进一步分层划分训练集和测试集,可保证训练集和测试集中有对应的模式,有望减小估计的偏差。
在构建水声目标样本集时,通常对一段长时间的数据进行分帧,每一帧作为一个样本,时间上相近的样本具有较强的相关性。若训练集和测试集中存在相关性强的样本,将导致评估结果偏乐观。如何在设计评估方法时考虑样本相关性还需研究。
4 结论
1)区别于文献[2],本文针对水声场景设计仿真试验,并进一步设计比较评估方法的仿真试验。
2)本研究关注水声场景中数据匮乏而模式丰富的特点,以及水下目标(正类)相对其他目标的不平衡性,具有现实意义。所提出的指标体系针对当前研究中指标不全面、不统一、不严谨的问题,给出一个有逻辑、有论据的解决方案。性能指标不仅是评估手段,同时也可成为算法优化的目标,对深入理解算法性质、创新算法研究具有指导意义。
本研究构建的性能指标体系只考虑了二分类的情况,针对多分类的问题的性能指标还需进一步研究,具体可围绕“关注水下目标”进行拓展。
