基于DRN和空洞卷积的图像语义分割算法改进
2020-12-14高建瓴韩毓璐孙健
高建瓴 韩毓璐 孙健

摘 要: 为了提高图像语义分割时的识别和分割能力的问题,本文提出了一种基于DeepLabV3+改进的算法。改进的算法以DeepLab模型作为主体,结合了DRN的结构,减少了分割过程中图像出现网格化的情况。同时为了能够检测到更多边缘信息,有效提高检测分割结果,算法中改进了空洞卷积的部分,提高了分割精度,避免遗漏太多图像信息。通过PASCAL VOC 2012数据集开展的语义分割实验显示,改进的算法有效的提高了在分割时的精度和准确率,本文所提出的网络对图像分割有极大的参考价值。
关键词: 语义分割;空洞卷积;扩张残余网络
中图分类号: TN391 文献标识码: A DOI:10.3969/j.issn.1003-6970.2020.09.040
【Abstract】: In order to improve the problem of recognition and segmentation ability in image semantic segmentation, this paper proposes an improved algorithm based on DeepLabV3+ model. The improved algorithm takes the DeepLab model as the main body and combines the structure of the dilated residual network to reduce the gridding of the image during the segmentation process. At the same time, in order to be able to detect more edge information and effectively improve the detection segmentation results, the dilated convolution part is improved in the algorithm. The segmentation accuracy is improved, and the image avoid missing too much image information. The semantic segmentation experiment carries out through the PASCAL VOC 2012 dataset shows that the improved algorithm effectively improves the accuracy and accuracy of the segmentation. The network proposed in this paper has great reference value for image segmentation.
【Key words】: Semantic segmentation; Dilated convolution; Dilated residual network
0 引言
隨着当今社会人工智能愈发成熟,人工智能中与计算机视觉相关的应用越加广泛。图形处理已经成为当今社会计算机视觉等领域的研究重点,其中图像分割[1]又在图像处理中具有重要的意义。图像分割可以看做是像素级的分类,也就是说将图像中的每一个像素都归为同一类别。而图像语义分割作为一类典型的像素级别的分类任务,它在场景理解、环境感知、医疗图像处理等具有十分广泛的应用场景。图像语义分割其主要目标是对图片进行逐像素分割,从而将图片分成若干个具有相似特征的区域,用于后续的图像分析和语义概念分析任务。传统的图像语义分割[2]模型主要是通过人工添加标签并且人为设置规则来进行规范的,但是这样处理人工工作量太大,难以实现复杂问题的处理[3]。因此近些年来不断有人提出了模型来进行语义分割的工作。
随着技术逐渐进步,基于深度学研究图像语义分割成为当下热点[4]。2012年,Krizhevsky等人提出了AlexNet架构,使大家看到了深度学习解决复杂计算机视觉任务的可能性。于是卷积神经网络被不断应用,研究人言提出了多种改进方法[5],其中最著名的包括VGGNet、GoogleNet和ResNet等。2015年,Vijay Badrinarayanan等人提出来SegNet[6],拥有较少参数的轻量级网络。同年,Lonjong等人提出了全卷积网络(FCN),FCN是以VGG16为基础改进而来的,其将后半部分的全连接层改成卷积层,从而支持任意尺寸图像输入的分割功能,相比于早期的算法,效果明显提升。Google[7]团队在2015年提出了一个DeepLabV1模型,是由DCNN和CRF模型的结合,二者结合极大的提高了效率,精准度高并且结构简单。DeepLabV2就是在DeepLabV1模型的基础上进行了改进,但是特征分辨率低和空间不变性导致的细节信息丢失还是有待改进。而在2017年提出的DeepLabV3则改进了级联的方式,综合运用串行和并行的方式,同时在ASPP中使用了BN层,实现对多尺度物体分割。2018年,Google团队进一步改进,提出了DeepLabV3+,对原来的模型进行改进。他将原来的DeepLabV3作为编码器,同时加入ResNet101[8]和深度卷积,可以更快的实现了分割,但是输出图的放大效果不够好,信息太少,有待改进。
为了进一步的提高图像分割时的准确度,本文为了增强对复杂图像的分割处理的精度改进了空洞卷积,同时引进了DRN模型,提升了模型的精度,并通过实验对改进的网络结构的效率进行了验证,在PASCAL-VOC数据集上有着一定的提升。
1 相关工作
1.1 DRN扩张残余网络
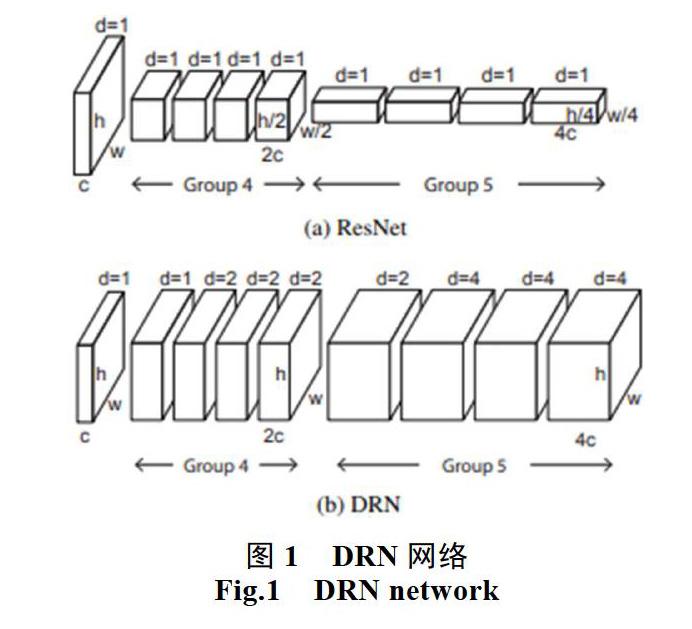
卷积网络的图像分类过程中会逐步降低分辨率,直到图像被表示为微小的特征图,而图片中有场景的空间结构则会变得不明显。这种空间敏锐度的丧失会限制图像分类的准确性。这些问题可以通过扩张来缓解,扩张可以提高输出特征图的分辨率,而不会减少单个神经元的接受域。在不增加模型深度和复杂性的情况下,扩展的残差网络在图像分类方面优于非扩展残差网络。
扩张残余网络(DRN, dilated residual network)[9]是在卷积网络中保持空间分辨率以进行图像分类的网络。虽然渐进式下采样在对物体或图像进行分类时非常成功,但空间信息的丢失可能不利于对自然图像进行分类,并可能严重妨碍转移到涉及空间详细图像理解的其他任务。自然图像通常包含许多对象[10],这些对象的身份和相对配置对于理解场景非常重要。当关键对象在空间上不占主导地位时,分割任务就会变得困难,也就是说例如,当被标记的对象是薄的(例如,一个三脚架)或图像中有一个大的背景物体。物体的信号由于向下采样而丢失,那么在训练过程中恢复信号的希望就很小。然而,假设在整个模型中保持高空间分辨率,并提供密集覆盖输入域的输出信号,那么反向传播可以学会保存关于更小、更不突出的对象的重要信息。
DRN是以Resnet为基础,提出了一个改进方法,在resnet的top layers移除下采样层,这可以保持feature map的空间分辨率,但后续的卷积层接收野分辨率下降了,这不利于模型聚合上下文信息。针对这一问题,论文使用扩张卷积替换下采样,在后续层合理使用扩张卷积,在保持feature map的空间分辨率同时维持后续层接收野的分辨率。
1.2 空洞卷积
因为现有的模型在进行图像分割任務的时候,存在着个关键的问题:下采样过程中导致部分信息丢失[11]。一般来说我们采用下采样[12],是为了能够使感受野扩大,使得每个卷积输出都包含较大范围的信息,但这种情况下,会导致图像的分辨率不断下降,包含的信息越来越抽象,而图像的局部信息与细节信息会逐渐丢失,还是不可避免的会造成信息的损失。
空洞卷积可以明确的设定深度卷积网络的特征图大小,同时也可以通过设定卷积核感受视野大小通过卷积操作提取多尺度信息。下图2(a)为常规的卷积操作,使用扩张率为1的空洞卷积生成,对应的感受野为3*3,9个红点代表卷积核的9个权重。图2(b)为atrous rate 等于2的空洞卷积,使用了扩张率为2的空洞卷积处理,是第一次空洞卷积的卷积核大小等于第二次空洞卷积的一个像素点的感受野,即生成的感受野为7*7。同样有9个权重,但是这个卷积核的感受视野变大了,在卷积运算时只与红点所在位置的输入进行运算,而绿色部分输入被忽略。图2(c)为atrous rate等于4的空洞卷积,处理同上,第二次空洞卷积的整个卷积核大小等于第三次空洞卷积的一个像素点的感受野,生成的每一个点感受野为15*15。相比之下,如果仅仅使用stride为1的普通3*3卷积,三层之后的感受野仅仅为7。
1.3 DeepLabV3+网络模型
DeepLabV3+模型是由Google团队来提出的,在VOC比赛中取得了非常优异的成绩,是目前应用广泛的一种语义分割网络,效果优秀,但是DeepLabV3+模型中也存在着一些限制缺点和不足。针对现有的图像数据原模型很容易出现多目标检测效果不够好的情况,因此希望对现有的DeepLabV3+模型进行一定的改进,以提升效果。DeepLabV3+的输出能够编码丰富的语义信息,其利用空洞卷积来控制编码输出的特征分辨率。DeepLabV3+通过添加一个简单而有效的解码器模块来恢复对象边界,扩展了DeepLabV3原有的模型。DeepLabV3+中使用了两种类型的神经网络,分别是空间金字塔模块(Atrous Spatial Pyramid Pooling,ASPP)和编码器-解码器(Encoder-Decoder)结构做语义分割。DeepLabV3+结合了这二者的优点,扩展了一个简单有效的模块用于恢复边界信息。
图3(a)是原来DeepLabV3的结构,使用ASPP模块获取多尺度上下文信息,直接上采样得到预测结果。图3(b)是通用的编码器-解码器结构,高层特征提供语义,解码器逐步恢复边界信息。图3(c)是DeepLabV3+结构,以原有的DeepLabV3为编码器,解码器结构简单。
在DeepLabV3+中使用了空间金字塔池化, 即带有空洞卷积的空间金字塔结构,增加了不同尺度范围内的语义信息的提取和区分,以实现对目标图像中多尺度的物体进行分割。
原有的模型中使用了DeepLabV3当做编码器。 DeepLabV3 采用了使用了空洞卷积的深度卷积神经网络可以以任意分辨率提取特征。此外,DeepLabv3+增强了ASPP模块,该模块通过应用具有不同比率的空洞卷积和图像级特征来获取多尺度的卷积特征。经过ASPP模块再经过1×1的分类层后直接双线性插值到原始图片大小。但是这种方法得到的分割结构不够优秀,故DeepLabV3+模型中借鉴了编码器-解码器结构,引入了新的解码器模块。首先将编码器得到的特征,然后与编码器中对应大小的低级特征concat,如ResNet中的Conv2层,由于编码器得到的特征数只有256,而低级特征维度可能会很高,为了防止编码器得到的高级特征被弱化,先采用1×1卷积对低级特征进行降维。两个特征concat后,再采用3×3卷积进一步融合特征,最后再双线性插值得到与原始图片相同大小的分割预测。
2 本文模型
2.1 引入扩张残余网络的deeplabv3+模型
扩张残余网络是在Resnet网络的基础上改进的来的,他们具有相同的参数和类似的网络结构。DRN在Resnet网络的基础上移除了最大池化层,这样有效的减少了gridding的影响。同时考虑到gridding的影响,在网络末端加入了去除残差模块的卷积网络,这样能够有效的避免过程中出现混叠的情况发生。DRN-D-105采取了残差模块和去除了残差的卷积网络组合在一起,与Resnet相比在精度上由明显提升。因此在本文当中
Deeplabv3+的卷积模块就选用了DRN-D来代替Resnet,能够获得更佳的效果。图5展示了本文所用模型框架。
2.2 引入改进ASPP的deeplabv3+算法
一般来说,空洞卷积是通过不使用池化和下采样的操作来增加感受野的效果,让每一个卷积都能够拥有较好的效果。ASPP是以空洞卷积为基础的,让图像通过同样一个feature map,接下来使用不同的dilation rate的空洞卷积去处理它,然后将得到的各个结果连接在一起,扩大了通道数,最后再通过一个1*1的卷积层,将通道数降到我们想要的结果。
3 实验分析
本实验所用配置为linux操作系统openSUSE Leap 42.3,选用intel(R)Core(TM)i5-7500的CPU,GeForce RTX2080Ti的GPU,深度学习框架为Pytorch。实验所用数据集为PASCAL VOC数据集,该数据集包括20个类别,即飞机、自行车、鸟、船、瓶子、公共汽车、小轿车、猫、椅子、牛、桌子、狗、马、摩托车、人类、植物、羊、沙发、火车、电视,共12023张图片。
3.1 评价指标
本文对分割结果的评价使用了四种业内公认的评价指标,分别为PA,MPA,MIou,FWIou。假设pij表示应该属于i类语义但却被误判为j类的像素点数量,pii表示预测正确的像素点的数量,k+1代表共有类的数量,PA(Pixel Accurary,像素精度):像素精度顾名思义就是描述图像的精准度,用于标记正确的像素占总像素的比例。
3.2 数据分析
实验中设置初始的训练数据由:batch-size为8,初始学习率为0.007,epoch为50,得到最终的模型。本文中每个模型都使用的是同样的训练数据,并在PASCAL VOC2012数据集上验证模型的性能,并计算出所有的实验数据所对应分割图像相对应的评价指标值作为最后的标准。
本文选用了Segnet,FCN8s,原模型和本文改进后的模型进行对比试验,下图为实验得到的数据结果。
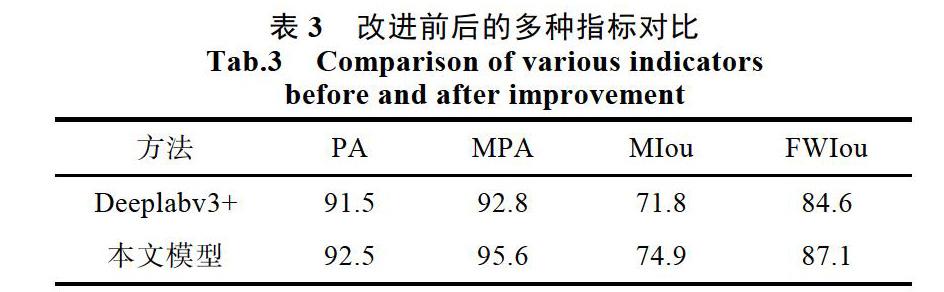
从上面可以看出本文模型不仅在MIou指标上,且在各个指标上都超过了Deeplabv3+,有了明显的提升。本文模型在PASCAL VOC数据集上的PA达到了92.5%,与Deeplabv3+相比有了1%的提升,而MPA值相比较于Deeplabv3+也有了2.8%的提升。而在其他两项评判指标上,本文方法也分别达到了74.9%和87.1%,均优于Deeplabv3+的结果,分别超出3.1%和2.5%。本文的模型不仅在分割精度的指标上超过Deeplabv3+和FCN8s等,同时因为改进了ASPP模块,获得了更大的感受野而得到了更好的边缘信息,PA也有了较大的提升。
但是改进的网络确实因为网络的改进,参数量的提升而导致网络模型的整体速度不如Deeplabv3+,整体略有下降,这也是有待改进的地方。
4 总结
本文中,我们为了提高语义分割的精度和准确度,使用了基于深度学习的语义分割网络模型,改进了DeepLabV3+网络,提升了其分割精度和准确度。通过实验对比,改进的网络相比较于原网络在精度等多项指标上得到了大幅提升,优化了网络结构处理图像数据的效果。但是本文改进的方法并没有达到极限,接下来我思考逐步改进模型,使其能够提升精度的同时减少计算量,进一步提升模型各方面的性能。
参考文献
[1]Simonyan K, Zisserman A. Very deep convolutional networks for large-iamge recognition [J] . Computer Science, 2014.
[2]周飞燕, 金林鹏, 董军. 卷积神经网络研究综述[J]. 计算机学报, 2017, 40(6): 1229-1251.
[3]郭璇, 郑菲, 赵若晗, 等. 基于阈值的医学图像分割技术的计算机模拟及应用[J]. 软件, 2018, 39(3): 12-15.
[4]尹宗天, 谢超逸, 刘苏宜, 等. 低分辨率图像的细节还原[J]. 软件, 2018, 39(5): 199-202.
[5]De S, Bhattacharyya S, Chakraborty S, et al. Image Segmentation: A Review[M]//Hybrid Soft Computing for Multilevel Image ang Data Segmentation. Springer International Publishing, 2016.
[6]Badrinarayanan V, Kendall A, Cipolla R. SegNet: a deep conzolutional encoder-decoder architecture for scene segmentation[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 99(12): 2481-2495.
[7]Chen L C, Papandreou G, Kokkinos I, et al. DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2018, 40(4): 834-848.
[8]赵勇, 巨永锋. 基于改进卷积神经网络的人体姿态估计[J]. 测控技术, 2018, 37(6): 9-14.
[9]Yu F, Koltun V, Funkhouser T. Dilated residual network[C]// Proceddings of the IEEE conference on computer vision and pattern recognition. 2017: 472-480. 赵
[10]罗笑玲, 黄绍锋, 欧阳天优, 等. 基于多分类器集成的圖像文字识别技术及其应用研究[J]. 软件, 2015, 36(3): 98-102.
[11]文可, 孙玉国. 弹性RBF神经网络在人脸识别中的应用研究[J]. 软件, 2018, 39(5): 203-206.
[12]张晓明, 尹鸿峰. 基于卷积神经网络和语义信息的场景分类[J]. 软件, 2018, 39(01): 29-34.