主机操作系统指纹探测技术分析
2020-12-09李红伟王耘翔王成
◆李红伟 王耘翔 王成
(云南电网有限责任公司曲靖供电局云南 655000)
随着我国电网多年的建设发展,电力监控系统网络规模日益庞大,接入的二次测控装置种类也越来越多。电网自动化专业运维人员,需要时常维护网络资产及拓扑,针对资产情况(比如终端设备的系统版本及内核)及时发现并修复电力监控系统、管理信息系统网络及终端设备的安全隐患,这是二次设备安全防护的基础性工作。当前,网络拓扑类管理工作主要还是处于全人工或半自动状态,由于一些嵌入式设备和国产操作系统,对其内核版本操作系统进行了剪裁和改造,运维人员可以通过ping包发现设备,但无法确认设备的一些详细信息[1],从而给后期设备台账辨识带来麻烦。目前,一些软件如天擎360、X-Probe、Nmap提供这方面的探测支撑,概括来说主要采用以下几种方案:(1)主机安装代理程序,搜集主机信息,自动上送数据中心[2],例如天擎360,该方案适合对办公网络内的PC主机进行管理,优点是探测准确、可定义功能较多,缺点在于需要安装维护工作量较大、且很多二次装置的系统都较小,难以适配和安装。(2)探测网络内主机通信服务端口,通过服务端口返回数据包中的特征获得主机操作系统类型,原理在于不同类型的操作系统,安装的不同软件服务会对请求数据返回接受和拒绝服务,在这类相关的信息里暴露出操作系统及版本号。该方案优点是识别比较准确,缺点是命中率不能保障,一些主机会通过系统补丁加固屏蔽这类问题,从而使扫描期望获取的信息丢失。(3)堆栈查询技术。该方案充分利用了TCP/IP协议在定义时留有了一部分自由实现和扩充空间,不同的操作系统厂商乃至不同的系统版本,在进行系统级设计时,由于编码和处理的不同,产生不同的响应,有些是可接受的响应(比如针对开放端口的数据请求),有些则是拒绝服务(比如针对关闭端口的数据请求),这些响应在满足TCP/IP协议的基本要求的同时,也给出了不同的响应特征,这些特征的组合,就像是系统的指纹。该方案优点命中率比较高,特别是操作系统类型的识别,缺点是使安全评估软件在较小的延迟内,得到一些关于类型和版本之类的信息,会比较困难,往往需要采用并发方式采集数据。
1 探测方法
以上三种主要的解决方案各有优缺点,在电力系统内部网络中,存在着纵向加密、横向隔离二次安全防护的结构[3],并且厂站内部很多网络设备终端存在各类异构剪裁的操作系统,因此,选择探测网络内主机通信数据包中的特征获得主机操作系统类型的方案,可以预测获得的收益和准确率较高。而在网络设备的扫描上又存在主动发包扫描和被动流量数据包探测两种,由于发现设备的工作数据测试类,而非监测类工作,因此在本中采用了主动探测技术。
1.1 原理说明
指纹识别在生物学上是指由于每个人的指纹都有差异,利用人的指纹特征,通过特殊的光电扫描和计算机图像处理转换,对指纹信息进行数字化转换后,再将结果与庞大的已有指纹库进行比对,从而快速精准鉴别出个人身份。由于 TCP/IP协议知识在 RFC[4-6]文档中描述,并没有一个完全统一的产品标准,造成了各操作系统在 TCP/IP协议实现上的差异,正是这些差异产生区分操作系统的依据。文中采用该原理对不同操作系统的TCP/IP协议栈细微差别类鉴定操作。
1.2 探测过程说明
(1)根据选定的访问表格、网段、IP等规则生成扫描对象组。
(2)开启对象组所有对象端口扫描,枚举出可用、不可用、过滤等清单。
(3)开启数据捕获进程,对目标和源头方向的数据进行监听,记录下双方之间的发送和接收数据包。
(4)由计算机根据对象列表进行扫描,每个扫描对象需要发送五组测试数据。大概说明如下:第一组测试数据通过发送6个TCP包,分析检查响应的各种细节,可获得包含WIN、T1 SEQ、OPS(每个代表一组特征值)。第二组测试发送两个不同的 ICMP echo请求,检测其响应特征。第三组测试发送一个 UDP包给一个关闭的端口,然后看下ICMP的端口不可达回复。第四组测试是 端显式拥塞通知”测试。该测试会发送带ECN位的TCP请求,比较其响应情况。第五组是发送六个不同的TCP包,其中T2-T4会发给打开的TCP端口,T5-T7会发给关闭的TCP端口。这六个TCP包的响应结果可获得对应的T2到T7的各项指标。
(5)解包进行各项指标计算。
(6)对指纹库进行匹配,计算相似度。
(7)按照相似度优先级给出答案。
2 关键技术分析
2.1 指纹库解析(图1)

图1 Nmap 指纹库格式
(1)TCP ISN最大公约数(GCD)
SEQ测试会将六个 TCP SYN数据包发送到目标机器的开放端口,并回收应答的SYN / ACK数据包。 这些SYN / ACK分组中的每一个包含 32位初始序列号(ISN)。 此测试目的是尝试区分不同类型的主机,由于很多设备序列的增加是按照固定数值增加的,有的是1,有的则是256等等。
计算此问题的第一步是在探测响应之间创建一系列差异。 第一个差值是第一和第二探测响应ISN之间的差异。 第二个差值是第二个和第三个响应之间的差异。 如果探测进程回收到对所有六个探测的响应,则会有五个差值构成一个数组。由于接下来的几个测试的值也使用了这个数组,我们接下来将其称为 diff1。如果后来的报文的ISN低于它的前一个,则会计算从第一个值中减去第二个值的大小,或第二个值减去第一个值,对比这两个值中较小的一个存储在 diff1数组中。比如第一个ISN 0x10000后跟第二个ISN 为0x05000之间的差值是0x0B000。最后,该测试值记录所有这些差值的最大公约数。该GCD值也用于计算接下来的SP的结果。
(2)TCP ISN计数率(ISR)
此值反映返回的报文中TCP初始序列号的平均增长率。每两个连续的探测响应之间存在差异,比如计算最大公约数GCD时的diff1数组。 这些差异除以发送产生它们的两个探测报文之间经过的时间之差(通常以 0.1秒为单位)。结果也将是一个数组,我们称之为seq_rates,其中就含有每秒 ISN计数器增加的速率信息。该数组对diff1数组中每个值都有一个对应值。我们接下来取该数组值的平均值,如果该平均值小于1(例如,系统使用恒定的ISN),则记录ISR为0。否则,ISR是计算该平均值的二进制对数再乘以8的值,这里要四舍五入到最接近的整数。
(3)TCP ISN序列可预测性指数(SP)
前面ISR测试测量的是初始序列号增量的平均速率,而SP值测量的是 ISN的可变性。它会粗略估计从六个探测响应的已知序列,来分析预测下一个 ISN值的困难程度。计算时要使用上述差异数组(seq_rates)和GCD值。并且我们只有在看到至少四个响应时才执行此测试。如果先前计算的GCD值大于9,则用先前计算的seq_rates数组的每个值除以该GCD值。我们不用较小的GCD值进行除法,因为这些值通常是偶然引起的。 然后获得所得值的阵列的标准偏差。如果结果为1或更小,则SP取0。否则,计算结果的二进制对数,然后将其乘以8,四舍五入到最接近的整数,存储为SP的值。
SP值在操作系统分析中具备足量参考作用,但是预测值始终不能百分百准确,因此SP难以预测。
(4)IP ID序列生成算法(TI,CI,II)
这三个测试会检查响应的IP头ID字段。TI基于对TCP SEQ探测的响应。CI基于对发送到关闭端口的三个TCP探测的响应:T5,T6和T7。II基于ICMP对两个IE ping探测报文的响应。对于TI,必须至少收到三个响应才能有测试结果。对于 CI,至少需要两个响应。对于II,必须收到对应的ICMP响应。
对于这其中每一个测试,目标的IP ID生成算法会基于以下规则进行分类。需要注意这些测试值之间的细微差别。注意,该差值假定计数器可以循环。因此,如果IP ID为65,100后面跟着的IP ID值是700的话,它们之间的差值为1136。 如果2000之后跟的是1100的话,之间的差值是64636。以下是测试值规则:
如果所有IP ID号都为零,则测试值为Z。
如果IP ID序列增量大于等于20000,则测试值为RD(随机)。II不可能是这个结果,因为没有足够的样本来支持它。
如果所有IP ID都相同,则将测试值设置为十六进制的该值。
如果任何两个连续响应之间的ID差值超过1000,且不能被256整除,则测试的值为RI(随机正增量)。如果差值可以被256整除,则必须至少为256000才能产生此RI结果。
如果所有差值都可以被256整除并且不大于5120,则将测试设置为BI(递增增量)。 这种情况会发生在Microsoft Windows等系统上,其中IP ID以主机字节顺序而不是网络字节顺序发送。它能够正常工作并且没有违反任何类型的RFC规则,尽管它确实泄露了对攻击者有用的主机架构细节。
如果所有差值都小于10,则值为I(增量)。我们允许这里差值大小达到10(而不是需要所有的都完全按顺序增量排序),因为可能有来自其他主机的流量导致序列间隙。
如果前面的规则都没有识别生成算法的测试结果,则从指纹中省略该测试。
(5)共享IP ID序列布尔值(SS)
SS是指TCP与ICMP是否存在共享IP ID序列的行为。比如,我们六个TCP IP ID值与ICMP值是一组连续的值,比如100,101,102,103,104,105,ICMP则是106和107,SS在库中表达为S。如果ICMP是很大的不相关的值,那么SS就是不共享。
这里仅当II和TI为RI,BI或I且二者相同时才进行此测试。但是ICMP与之前TCP IP ID不连续时,测试以下规则进行:
令avg为最后一个TCP序列测试报文响应的IP ID减去第一个TCP序列测试报文响应的IP ID,再除以之间探测报文数的差值。如果第一个ICMP回应响应的IP ID小于最后一个TCP序列响应的IP ID加上该avg的三倍,则SS测试结果为S,否则就是O。
(6)TCP时间戳选项算法(TS)
TS是另一个测试,根据生成一系列数字的方式确定目标操作系统特征。这个测试查看 TCP SEQ探测的响应中的TCP时间戳选项(如果有的话)。它检查的是TSval(选项的前四个字节)而不是回显的TSecr(最后四个字节)值。取每个连续TSval之间的差值,并除以探测进程发送两个探测报文之间,响应经过的时间。其结果值给出了每秒时间戳增量的速率。探测进程会计算所有连续探测报文的时间戳每秒平均增量,然后按如下方式计算TS:
如果任何响应都没有时间戳选项,则TS设置为U(不支持)。
如果任何时间戳值为0,则TS设置为0。
如果每秒的平均增量落在0-5.66或150-350的范围内,则TS设置为1,7或8。 这三个范围会被特殊处理,是因为它们对应于许多主机使用的2 Hz,100 Hz和200 Hz频率。
在所有其他情况下,探测进程记录每秒平均增量的二进制对数,四舍五入到最接近的整数。由于大多数主机使用1,000 Hz频率,因此A也是常见结果。
(7)TCP选项(OPS,O1-O6)
TCP头部选项字段(TCP option)的响应值也可以作为测试特征值记录下来,具体可以参考TCP/IP定义,它保留了其中的原始顺序,并提供了有关选项值的一些信息。由于RFC793中不需要我们有任何特定的排序,因此不同系统对这里的实现通常会提供独特的顺序。
当将所有这些不同的实现顺序,与对不同选项值使用的数量都组合在一起时,此测试就提供了一个真实有效的信息库。WIN、ECN、T1-T7等参数组就不再一一说明了,可以参考相关材料。
2.2 决策树指纹匹配度算法
文中通过测试项各个属性参数的值进行匹配的方案并不能百分百对应到设备,实际网络中很多因素制约着百分百的理想匹配情况。针对这类分类问题,还是采用分类办法解决,通过一些研究类文献的证实,采用决策树进行评估比较适合,原因在于一方面提供的系统指纹库可以转化成很多样本,另一方面在实际过程中不能很好耦合的结果,可以人为补充指纹库(很多系统设备采购具备延续性,因此可以获得好的结果拟合度)。
具体做法是将属性例如进行转化,操作系统的类型就是几种不同的种类,即枚举型,将MSS、SP、等属性设置为numeric类型即数值类型,比如将TTL、LEN、WIN、WS等属性值转为十进制值,如果没有值则用空格代替;S、N与T这四项分别用1代表该项出现,用0代表该项未出现,D项用1表示DF不分段标志位置1,否则用0表示,F项为1表示是SYN包,为2表示是SYN+ACK包。
假设给定的操作系统特征组集合为S,并且训练样本分为k类,即为C={C1,…={C此时集合S的信息熵为:

p(Si)属于样本中值属于Ci的比例
假设实际主机扫描中,某个属性集为A,且A={A1,…,Am},选择Aj作为测试属性进行划分,则Aj对应的信息增益为GAIN:

其中,「S」为样本集合的总个数,SV中属性为Aj的值对应的个数。因此,该属性值的信息分裂计算:
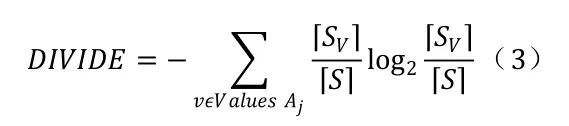
从而C45计算所需的信息增益率为:
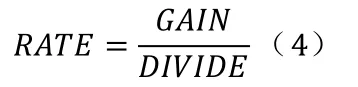
逐个计算每个属性对应的信息增益率;选择信息增益率最大的属性作为父节点,在逐步计算下一级子节点,以此类推,直到操作系统枚举型的叶子节点。
3 应用分析
选择 Center OS、VxWorks、凝思磐石、RedHat、Center OS、WINDOWS 10、WINDOWS SERVER 2010、VxWork等操作系统终端或主机进行盲测,结果如表1:

表1 探测方法盲测结果表
3 总结
网络拓扑分析工作中开展终端主机操作系统类型分析,有助于对网络中的设备详细情况进行快速全面了解,降低自动化运维人员的工作强度。进一步的,有助于明确网络中不同设备系统后期基线管理与加固的内容和要求,正确开展安全管理工作。由于不同应用场景存在不同的网络环境,指纹探测在应对调度主站侧和变电站内部网络的分析时,将较为准确,但如存在较为严苛的防火墙环境,分析起来还是会存在一定的不确定度,但针对操作系统类型分析准确率还是很高的,如何不断利用相关数据信息,提高指纹识别的匹配度,这也是下一步研究的重点。
