基于熵权-云模型的环洞庭湖森林健康评价
2020-12-08李显良李建军
李显良,张 贵,李建军
(1.中南林业科技大学 林学院,湖南 长沙 410004;2.湖南体育职业学院,湖南 长沙 410019)
关键字:熵权法;云模型;森林健康评价;环洞庭湖
森林属于可再生资源的一种,不仅能为经济社会建设提供所需要的木材和其他原料,而且具有无可比拟的生态功能,拥有“地球之肺”的称号[1]。而森林生态和经济功能的正常发挥,在很大程度上取决于森林健康程度,森林健康评价是当前国内外的热点问题,已成为国内外森林状况评估和森林资源管理的重要手段,其评价结果是制定更优可持续经营方案和措施的依据[2-4]。
森林健康评价的研究主要包括森林健康的内涵、评价尺度、指标体系、指标权重的确定、评价方法以及健康等级的划分等方面。其中森林健康评价方法的选择是关系到森林健康评价结果客观科学与否的最关键因素之一[5-8]。王秋燕等总结了目前国内外学者已经应用较多的11 种方法,分别是主成分分析法、层次分析法、模糊综合评判法、指示物种评价法、人工神经网络法、健康距离法、灰色关联度分析法、多元线性回归、指数评价法、聚类分析法和综合指数评价法等,这些方法有的过于主观、有的应用起来过于复杂而应用范围有限、有的对于评价对象要求过于理想化、有的无法解决评价过程中的模糊性与随机性问题,这些评价方法的缺陷直接影响到森林健康评价的效率和准确度[9]。在森林健康评价指标体系中,评价指标既有定量的也有定性的,对森林健康的最后评价结论是定性的,因此在森林健康评价中要解决定性与定量转换问题。云模型是一种由概率论和模糊数学发展演化而来、用语言值表示定性与定量相互发生不确定转换的新模型,具有广泛的普适性[10-11]。本研究将云模型应用到森林健康评价领域以解决森林健康评价中的定性与定量转换问题,以期提高森林健康评价的客观性与科学性。
1 研究区概况与数据来源
1.1 研究区概况
洞庭湖是我国第二大淡水湖,湖区位于荆江南岸,跨湘、鄂两省。洞庭湖的湿地也是我国最大的淡水湿地,面积达61.2 万hm2,作为首批代表中国加入《国际湿地公约》的6 大自然保护区之一,在国际上占有非常重要的地位,被誉为“拯救世界濒危珍稀鸟类的主要希望地”,已载入《世界重要湿地名录》。因此,洞庭湖区对于维护我国中部腹地生态平衡有着极其重要的作用。
本研究选取的环洞庭湖区地处111°41′30″~114°09′01″E,28°15′41″~29°50′43″N,环湖和湖间丘陵5 044 km2,占全区总面积的26.86%,其间保存有天然次生林7.07 万hm2。广义的环洞庭湖区指以洞庭湖为中心的河湖港汉、河湖冲积及淤积平原和环湖岗地、丘陵、低山等组成的一个碟形盆地。环洞庭湖区土壤共有9 个土类、21 个亚类,红壤为本区主要地带性土类,包括红壤、红壤、黄红壤3 个亚类,面积占总面积的一半。环洞庭湖地带性植被为中亚热带常绿阔叶林,由于受到长期人类活动的影响,大多数原始森林被次生落叶阔叶林、针叶林所覆盖,已形成由常绿阔叶林到落叶阔叶林、再由阔叶林到针叶林的由低到高的海拔地带性格局[12]。
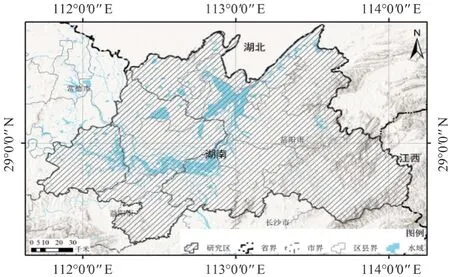
图1 研究区域概况Fig.1 Overview of research area
1.2 数据来源
本文的主要研究数据来源于两类,一是湖南省森林资源二类调查数据,小班调查因子包括面积、长度、地类、海拔、地貌、坡向、坡度、坡位、裸岩率、土壤名称、土壤厚度、土壤质地、土壤母质、土壤侵蚀度、腐殖质厚、立地类型、经营类型、起源、林种、林木所有权、林木使用权、事权等级、生态重要性、生态脆弱性、保护等级、植被类型、植被总盖度、盖度等级、灌木优势种、灌木盖度、灌木均地径、灌木均高、灌木状况、灌木分布、草本优势种、草本盖度、草本平均高、草本生长、草本分布、优势树种、树种组成、造林年度、平均年龄、龄组、平均高、平均胸径、优势木均高、郁闭度、蓄积、自然度、枯枝层厚度等;二是采用2014年全年的由Suomi NPP 卫星VIIRS 数据生产的高级产品VNP13A3 和VNP21A2,通过栅格融合取最大值获取EVI年最值和LST年最值。
2 研究方法
2.1 熵权法
熵权法属于客观赋权法,通过各指标观测值所提供的信息大小来确定权重,能够避免人为主观因素造成的偏差。主要计算步骤如下[13]:
1)构建判断矩阵。设有m个评价对象,n个评价指标,rij表示第i(i=1,2,…,m)个评价对象的第j(j=1,2,…,m)个评价指标的值,由此建立归一化矩阵(rij)mn。
2)指标标准化处理。由于选取的评价指标单位不同,需要进行无量纲化处理,本研究采用极差法的正向指标和负向指标将其量化到0 到1之间。
3)计算各指标的熵值。设第j 项指标的熵值为Hj,其计算方法如下:
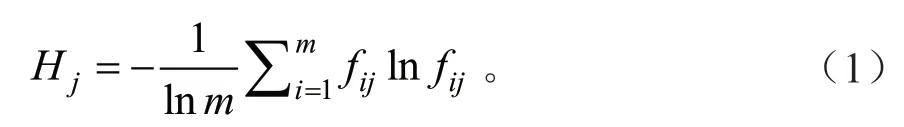
式中:表示各指标的比重,m表示评价对象。
4)计算第j 个评价指标的熵权:
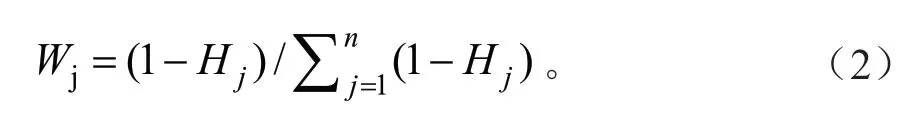
式中,n表示评价指标,Wj即为各评价指标的权重集。
2.2 云模型
李德毅院士针对概率论与模糊数学在处理不确定性方面的不足,提出了定性概念与定量数值之间的不确定性转换模型——云模型,并研究了模糊性与随机性二者之间的关联性,并将二者集中在一起,构成定性和定量间的相互映射。
正态分布是概率理论中重要分布之一,本文中的所有云模型都是基于正态云模型的。
设U是一个精确数值表示的定量论域,C是U上的定性概念,若定量值x∈U,且x是定性概念C的一次随机实现,若满足:x~N(Ex,En′2),其中En′~N(En,He2),且对C的隶属度满足:则称x在论域U上的分布成为正态云。正态云模型用期望Ex、熵En、超熵He三个数值来表征[11,14]。
3 森林健康评价体系的构建
3.1 评价指标体系的构建
本研究在充分研究国内外森林健康评价指标体系的基础上,结合数据的可得性以及评价模型的可行性,从森林结构、活力、可持续性与抗干扰等4 方面初步构建了如下指标体系[15-18]。
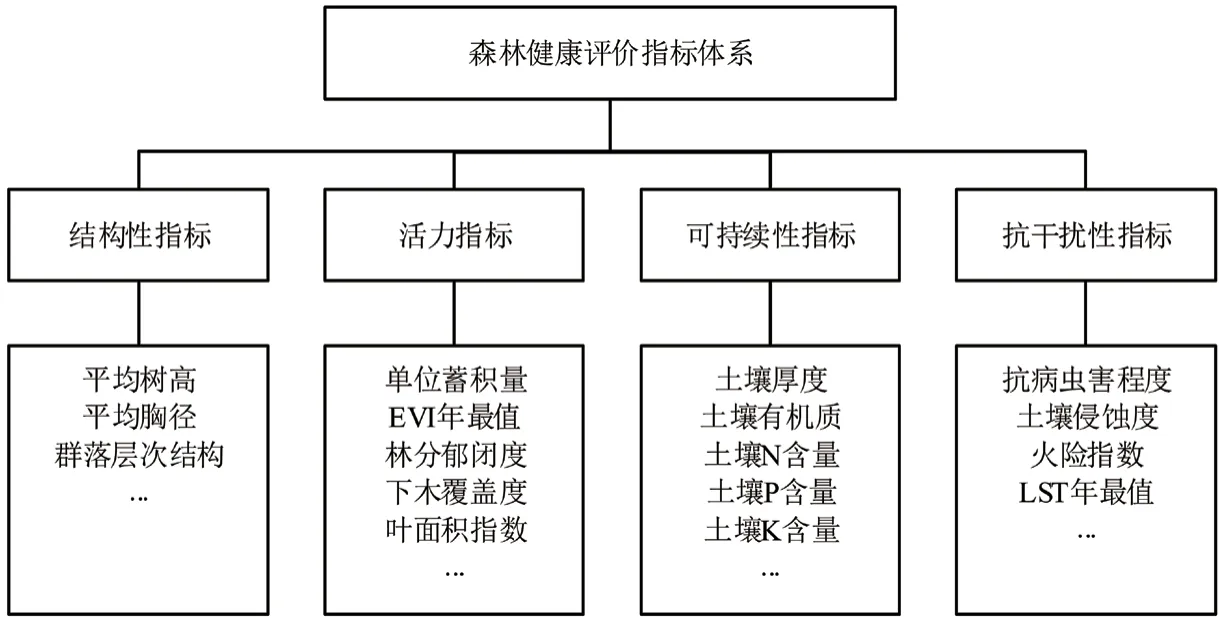
图2 森林健康评价指标体系Fig.2 Assessment index system of forest health
为进一步科学构建评价指标体系,提高评价效率与评价结果的科学性,对图2指标体系进行定性与定量筛选,最后确定本研究评价指标体系。结构性指标中平均树高、平均胸径和群落层次结构是3 个反映小班结构的指标,平均树高和平均胸径主要表征各单元的林木样本的相对水平,而群落层次结构主要表征垂直方向的结构特征,因此保留这3 个指标。活力指标中,单位蓄积量是从森林生产力角度来表达系统的活力程度,EVI 是增强植被指数且可通过遥感手段获取到客观数据,予以保留。林分郁闭度与EVI年最值相关度通过定量分析确定,下木覆盖度反应林木表层一下情况,EVI年最值只能获取到表层信息,而无法获取到下层的信息,所以该指标保留。可持续性指标中,土壤是森林生长的基础,因此选取土壤厚度与土壤有机质。抗干扰性指标中,病虫害是森林健康稳定中的一大影响因素,此指标不可或缺。火险指数和LST年最值存在一定的关联性,火险指数所需要的质变相对较多且计算过程复杂,而LST年最值可以客观获取,因此用LST年最值表征火险情况。
为验证郁闭度和EVI年最值间的相关性,本研究通过SPSS 软件中的相关性分析,得到结果见表1。

表1 郁闭度与EVI年最大值相关性分析†Table 1 Correlation analysis of canopy density and annual maximum of EVI
由表1可知林分郁闭度与EVI年最值的相关系数为0.063,表示两变量的相关性比较低,因此两个指标予以保留。根据上述的定性和定量筛选过程,最终得到如下表所示的评价指标体系,并构成了本研究森林健康评价的因素论域U={U1,U2,U3,…,U11},如表2所示。
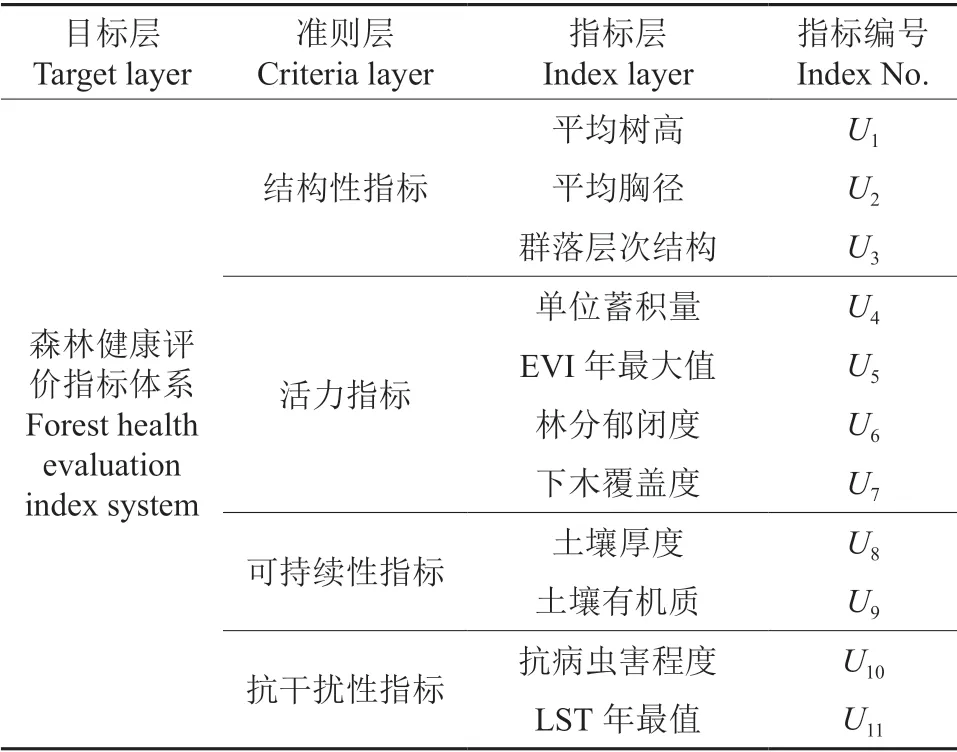
表2 森林健康评价指标体系层次结构Table 2 Hierarchical structure of forest health evaluation index system
3.2 森林健康评价等级划分
根据构建的指标体系,并参考国内外研究成果,从森林的结构特征、活力情况、可持续性、抗干扰性情况,将森林健康分为5 个等级,构建本研究的评价论域V={V1,V2,…,V5},如表3所示[8,15]。
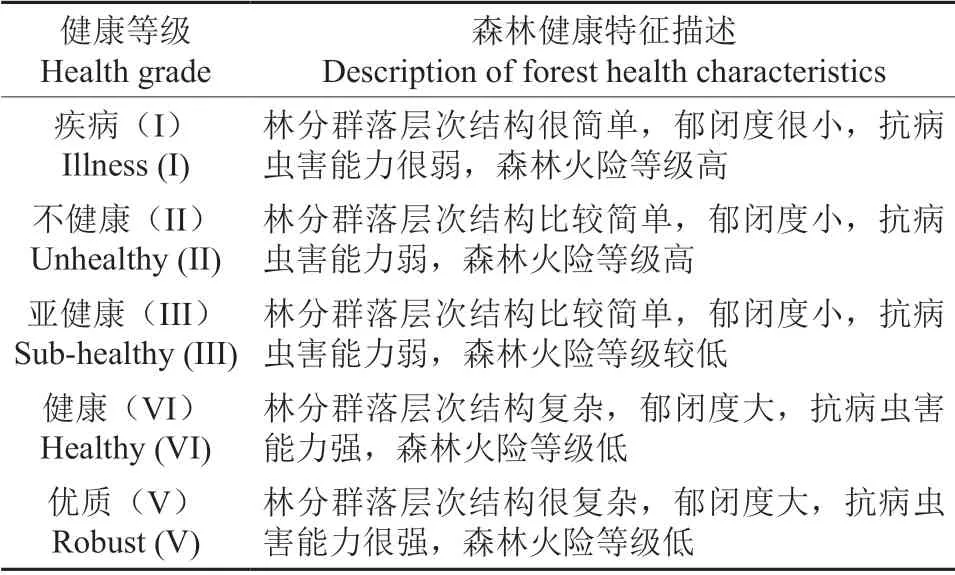
表3 森林健康评价等级分级标准Table 3 Grading standard of forest health assessment
3.3 评价指标分级
根据等距划分方法确定各个评价指标健康等级间的阈值,通过分析样本中各个指标的分布形态,利用ArcMap 的统计功能得到各指标的频数分布,以单位蓄积量为例,如图3所示。依据各指标的频数根据自然分段法将各指标分为5 个等级,分布得出的各指标分级如表4所示。
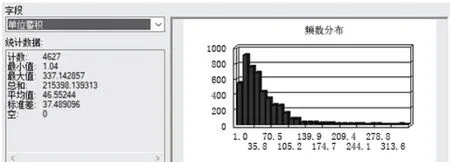
图3 “单位蓄积量”指标频数分布Fig.3 Frequency distribution of “unit volume” index
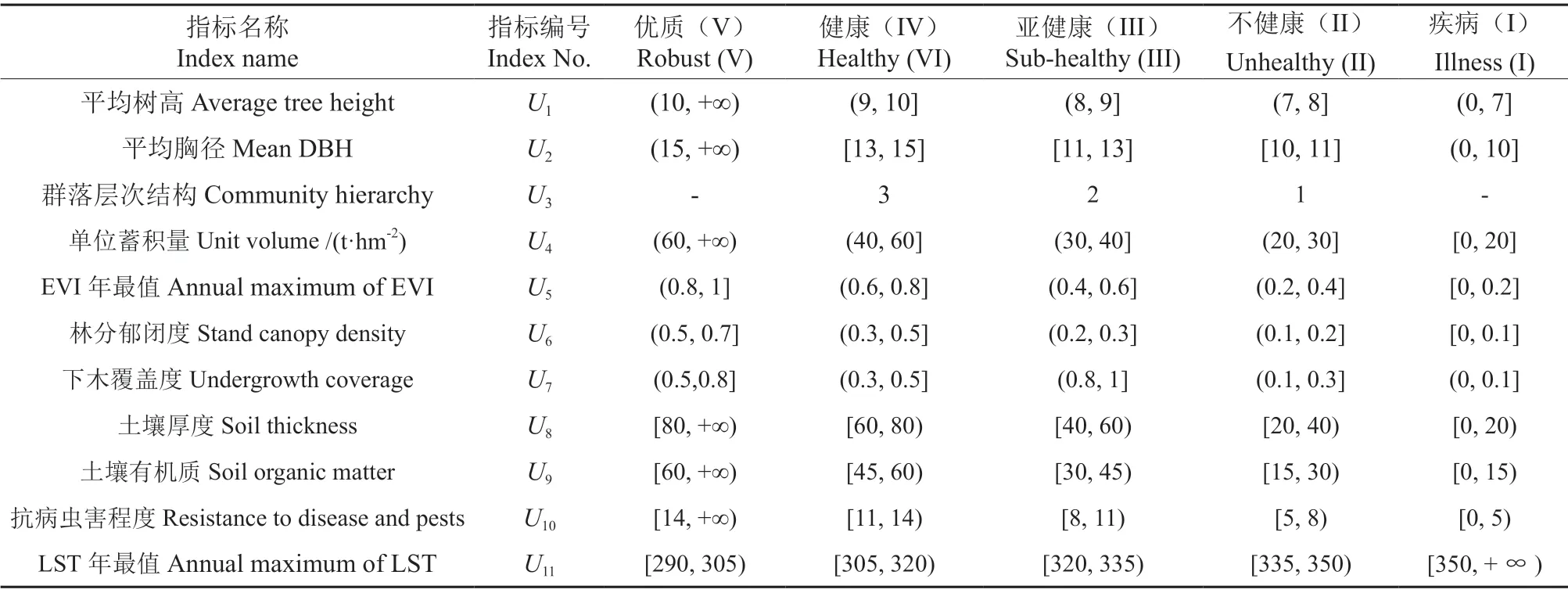
表4 森林健康评价指标等级划分标准Table 4 Classification standard of forest health evaluation indexes
4 实证研究
4.1 数据处理
本研究所用数据为湖南省森林资源二类调查数据结果,所研究区域共有小班382 777 个,其中森林小班315 224 个,分布如图4所示。
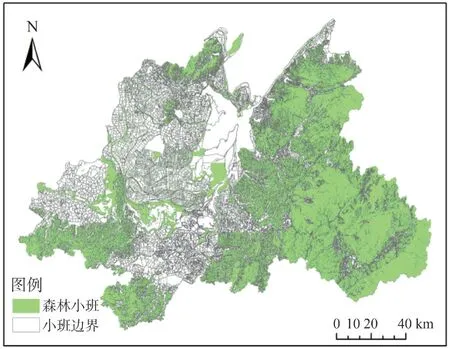
图4 研究区域森林小班分布情况图Fig.4 Distribution of forest subcompartments in the study area
LST 与EVI 数据均来自于2014年NPP-VIIRS生产的空间分辨率为1 km 的高级产品,通过全年数据进行求最大值处理得到如下空间分布图[19-20]。
由于研究区域森林小班数量较多,本研究通过ArcMap 均匀分布采样的方法保留落在林地小班的采样点7 902 个,进一步去除重复采样点与竹林等不符合要求的小班,最终选取4 627 个小班。
4.2 指标权重计算
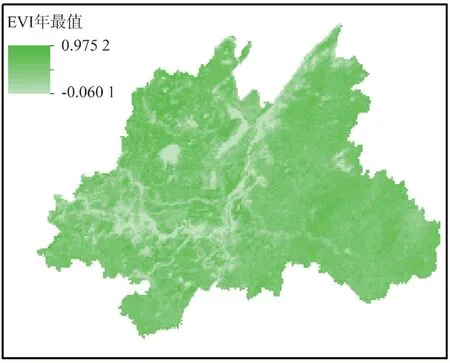
图5 EVI年最大值Fig.5 Annual maximum of EVI
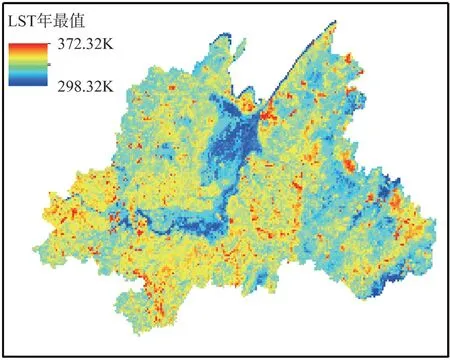
图6 LST年最大值Fig.6 Annual maximum of LST
指标间权重的确定是森林健康评价中很重要的一环,在很大程度上影响着森林健康评价结果,因此,客观合理地依据评价指体系确定指标的权重尤为重要。根据前文熵权法计算方法计算各指标的权重,各指标权重矩阵W 如表5所示。

表5 森林健康评价指标权重矩阵Table 5 Weight matrix of forest health evaluation index
4.3 评价指标云模型参数和隶属度计算
建立指标论域U与评语论域V的模糊关系矩阵R=(rij)。在评估对象的因素论域U与评语论域V之间进行单因素评估,建立模糊关系矩阵R。R中元素rij表示论域U中第i个因素ui对应于评语论域V中第j个等级vj的隶属度。设评价元素ui对应的评价等级vj上下界和,则因素i对应的等级j这一定性概念用正态云模型表示,其中Heij通过经验选取[21]。
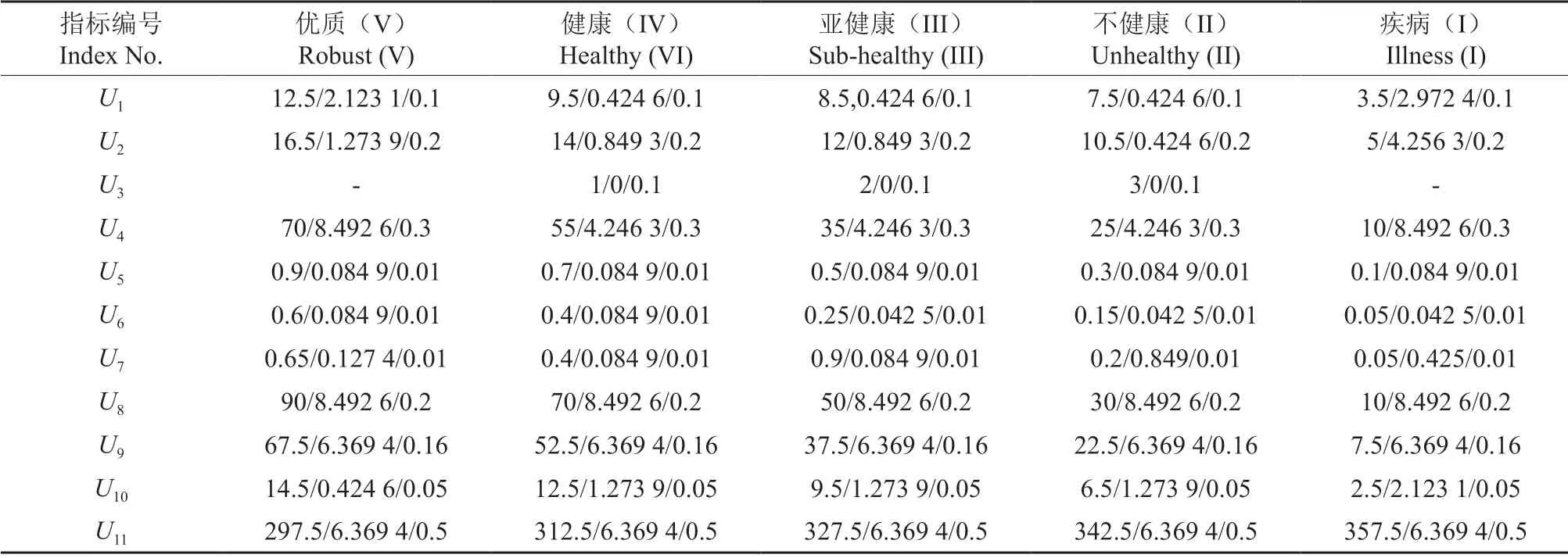
表6 森林健康评价指标正态云模型特征参数矩阵Table 6 Normal cloud model characteristic parameter matrix of forest health assessment indexes
以蓄积量为例,由蓄积量的特征参数和正向云发生器算法,绘制蓄积量对应于不同评价等级的正态隶属云图如图7所示。
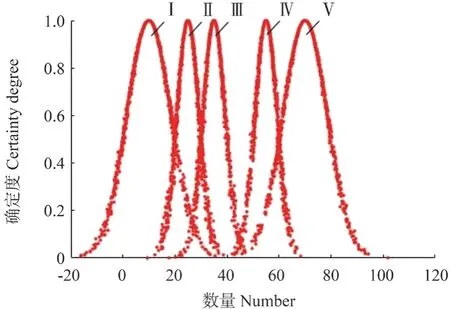
图7 单位蓄积量隶属云图像Fig.7 Cloud chart of unit volume
4.4 模糊隶属度矩阵计算
利用正向云发生器,求各评价因素的隶属度。为提高评估的准确度,重复运行正向云发生器N=1 000 次,计算在不同隶属度情况下的平均值:式中:Zij表示因素i对应的等级j的平均隶属度;表示因素i对应的等级j由正向云发生器计算一次的隶属度;k为正向云发生器运行次数。以4 627 号小班为例,根据评价指标体系中指标等级对应的正态云模型参数,将该小班各指标具体参数值代入到正向云发生器中,得到各评价指标对于不同等级的隶属度,由于正态云模型给出的隶属度具有随机性,为提高结果的可靠性,重复运行正向云模型1 000 次,最终得到4 627 号小班各指标的模糊隶属度矩阵Z,如表7所示[22]。
4.5 森林健康评价结果
利用权重集W与隶属度矩阵Z进行模糊转换得出评价集V上的模糊子集:F=W×Z=(f1,f2,…,f5)。依据最大隶属度原则,选择最大隶属度所对应的第i 个评价等级作为综合评价结果。以4 627 号小班为例,将表7的隶属度矩阵Z 相乘以表5的指标权重矩阵W,得到小班对应的各健康等级的隶属度,根据最大隶属度原则,4 627 号小班的健康等级为I 级,如表8所示[23]。
参照4 627 号小班的评价过程,得出其他4 266 个小班的健康评价结果如表9所示。
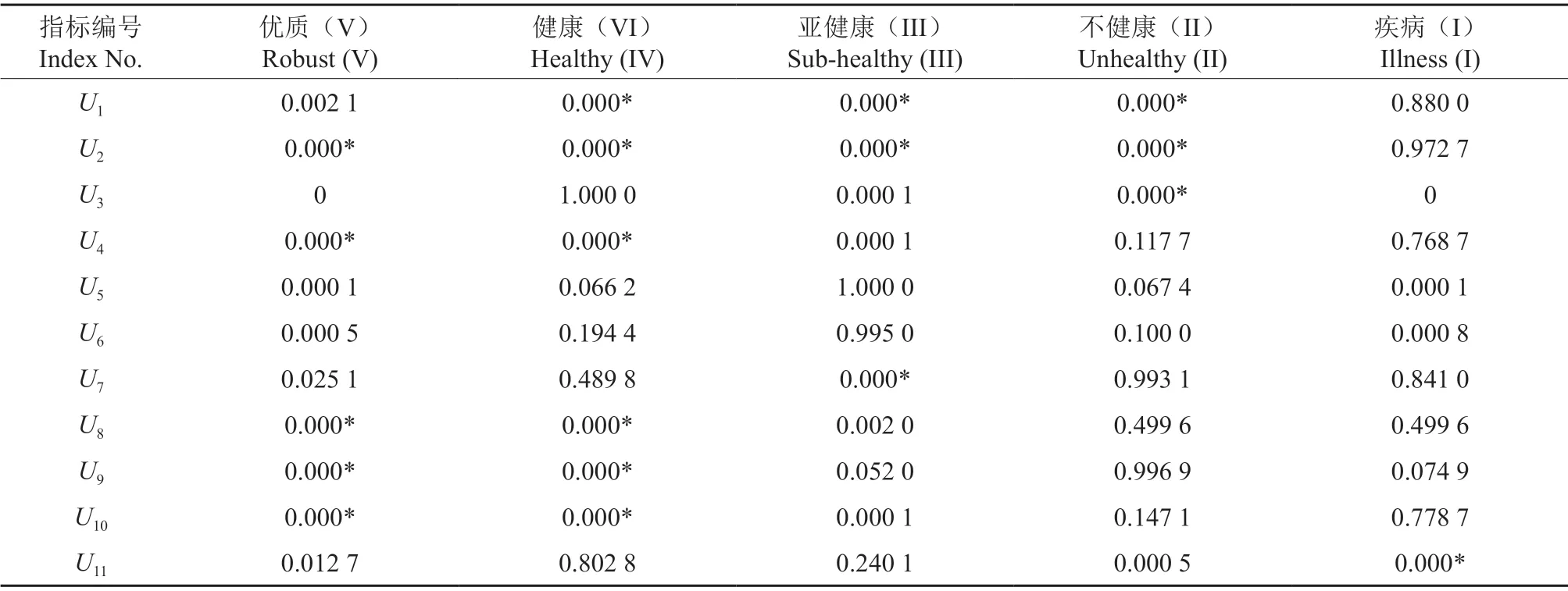
表7 4 627 号小班的评价指标隶属度矩阵Table 7 Membership matrix of evaluation index in subcompartment 4 627

表8 4 627 号小班的健康等级隶属度及评价结果Table 8 Membership degree and evaluation result of health grade in subcompartment 4 627
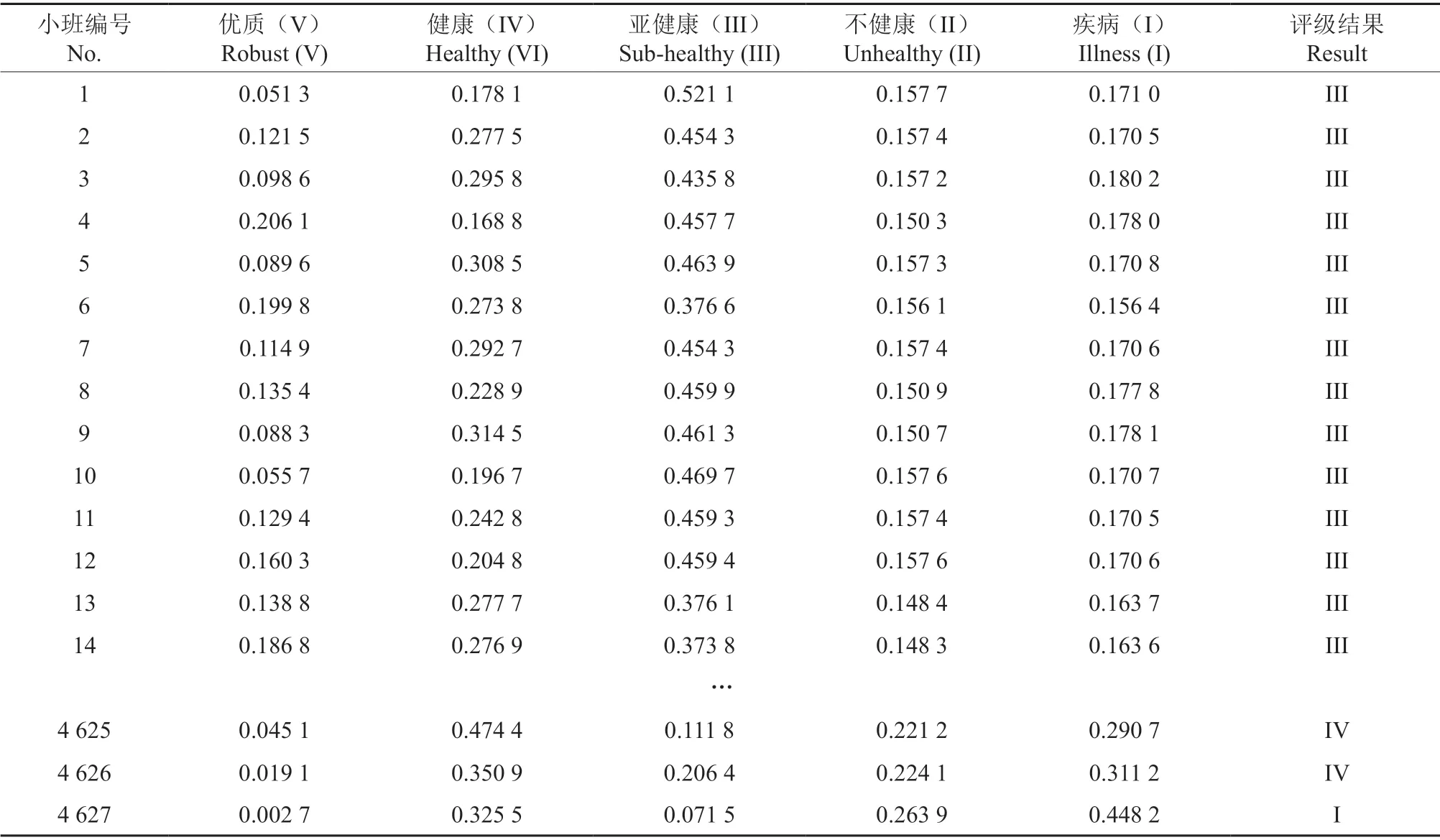
表9 抽样小班森林健康评级结果Table 9 Forest health rating results of sampling subcompartments
5 结果与分析
本研究通过等距离取样方式抽取环洞庭湖区4 627 个小班为评价对象,通过熵权-云模型计算综合隶属度的方法得到各评价小班的健康等级,评价结果统计如表10所示。
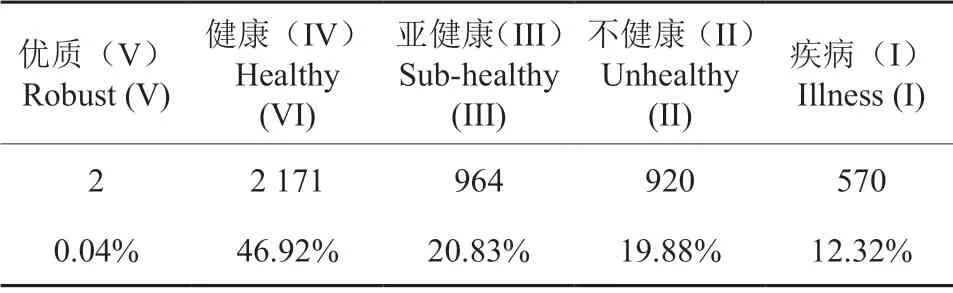
表10 抽样小班健康情况分布表Table 10 Distribution of health status of sampling subcompartments
从表10可知,在评价的4 627 个森林小班中,优质小班数量最少,仅有2 个,占抽样总数的0.04%,这两个小班的林分群落层次结构较复杂,郁闭度大,森林火险等级低,抗病虫害能力很强,但所占比例很低,说明环洞庭湖区森林健康离优质等级相距甚远;健康小班数量最多,有2 171 个,占所选个体总数的46.92%,将近占到一半,这是环洞庭湖区主要的森林健康类型的代表,这些林分群落层次结构较复杂,郁闭度较大,抗病虫害能力强,森林火险等级较低;亚健康小班数量次之,为964 个,占所选个体总数的20.83%,这些林分群落层次结构简单,或为群落演替先锋树种或为引进外来树种,郁闭度小,土壤贫瘠,抗病虫害能力中等,森林火险等级较高;不健康小班数量920 个,占所选个体总数的19.88%,这些林分群落层次结构简单,近自然程度低,抗病虫害能力弱,森林火险等级高;疾病小班数量570 个,占所选个体总数的12.32%,林分群落层次结构很简单,郁闭度很小,抗病虫害能力很弱,森林火险等级高。综合来看,健康小班与亚健康小班数量占到总体的67.75%,约占总数的2/3,说明环洞庭湖区整体森林健康程度一般,不健康与疾病小班占到总数的32.20%,占到总数的仅1/3,说明该区域存在森林健康风险的林分比较多,尤其是疾病等级的森林占到了近1/8。
从小班健康等级分布情况(图8)看来,亚健康及以上的小班主要分布在研究区范围的东部区域以及南部区域,该区域主要是以马尾松与杉木为优势树种的针叶林和以栎类为优势树种的阔叶林。西南区域选取小班较少的主要原因是该区域竹林较多。不健康小班主要集中在中部和西北部区域,该区域主要是洞庭湖平原,以耕地居多,林地小班穿插在其中,相对面积较小,而疾病小班则零散分布在研究区域中。
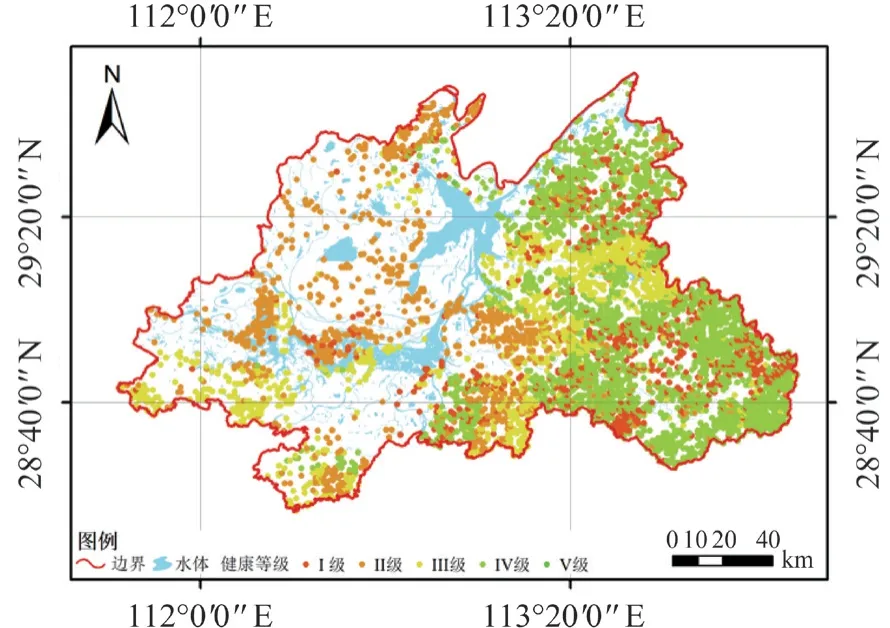
图8 森林健康评价等级分布Fig.8 Distribution map of forest health grade in subcompartment
6 结论与讨论
6.1 结 论
森林健康评价是了解森林经营状况的重要手段,森林健康评价结果受到指标体系、指标权重赋值方法以及评价方法等方面的影响较大。贾大鹏[24]等使用森林清查数据结合遥感影像提取数据,利用层次分析法和熵权法对金沟岭林场各小班的森林健康状况进行评价。赵勇军[18]等针对马尾松人工林使用因子分析、聚类分析和判别分析方法构建了以林分为尺度的综合量化森林健康评价体系,以期解决指标之间的相关性和指标权重的主观性。本研究着重从指标体系的构建、指标权重的赋值以及评价方法的创新等方面进行了研究。
1)基于小班的森林健康评价因子众多,但部分评价因子间相互重叠交错相关性较大,因此,在考虑数据获取的前提下,采取定性与定量分析最终确定了4 大类共11 个评价因子。同时,为了尽可能综合评价森林健康状况,数据来源虽然以二类调查数据为主,但是通过遥感数据弥补了因二类清查数据不能综合评价森林健康的不足,使得评价结果更加客观真实。
2)森林健康评价指标体系中各指标因子对森林健康影响各异,传统方法大多通过专家打分法或者层次分析两两标度法确定指标的权重,具有很大的主观性。本研究采用熵权法计算指标间的权重,这是一种客观的权重赋值方法,客观权重赋值法减少了因主观赋权重或者专家打分的主观影响,使指标权重更具有客观性,有助于提高评价结果的客观性。
3)森林生态系统本身是一个多层次多指标的复杂系统,具有模糊性和随机性的特点。通常认定森林系统是不是有风险,风险大不大,这本身就是一个“模糊”的问题。森林健康的风险来自于森林本身众多的不确定性因素,这些因素对森林健康的影响错综复杂,具有较大的模糊性。传统综合评价法很少考虑森林健康评价影响因素的不确定性、评价指标与健康等级之间的非线性关系,而人工智能的正态云模型能够兼顾评价指标和评价结果存在的随机性和模糊性,使评价结果更加客观。
4)基于云模型的森林健康评价,兼顾了森林健康等级概念的模糊性与随机性,同时实现了评价指标(定量)向评语等级(定性)转换的不确定映射。
6.2 讨 论
森林健康是动态的、可持续的,在同一区域使用不同的评价方法所得出的结果,也会有所差异。因此,针对不同时间、不同的森林类型应因地制宜,具体问题具体分析。目前森林健康评价大多仅对当前状态下的森林健康情况进行评价,缺乏长期有效的监测和预测体系,在未来的研究中可以进一步探究森林健康的影响因子,从而对森林健康的发展趋势进行预测,更好地保护森林资源,进行合理的经营管理。
