基于模糊C均值聚类与Bayes判别的致密油储层分类评价
2020-12-03康胜松郭粉转
王 伟,康胜松,高 峰,郭粉转,张 亮
(陕西延长石油(集团)有限责任公司,陕西 西安 710075)
0 引 言
致密油是继页岩气之后油气勘探开发领域新的热点,目前在世界能源结构中占有极为重要地位[1-3]。中国致密油资源丰富[4-13],郑志红等[14]采用7种评价方法计算出中国致密油地质资源总量为146.60×108t,可采资源量超过14.55×108t,但由于中国致密油勘探起步较晚,目前仍处于探索阶段[4,6,15]。与北美地区致密油相比,中国致密油受沉积背景影响,储层的非均质强[16-18],严重制约了致密油的有效动用及高效开发,亟需开展致密储层分类评价,为致密储层压裂选段、优化井位部署等提供地质依据。
众多学者对致密油储层的分类主要从2个方面进行了大量的研究:一方面是在综合分析储层岩石学特征参数的基础上,对致密油储层进行定性划分[19-20];另一方面是通过岩心渗流实验,依据致密储层的孔喉及渗流特征对其进行分类[21-23]。对于实际应用而言,前者存在分类结果多解性问题,后者则因为常规生产井缺乏实验数据而无法对其进行评价。鉴于此,以鄂尔多斯盆地志丹地区长7致密储层为例,首先采用模糊C均值聚类算法[24-26],根据取心井的评价参数建立储层的最佳类别,然后利用Bayes判别分析法[27-29]建立不同储层类别与取心井常规测井属性的关系式,基于此关系式预测未取心长7储层的类别,进而明确储层的展布规律,从而为致密储层的高效开发提供依据。
1 算法求解
1.1 模糊C均值聚类算法
模糊C均值(简称FCM)根据研究样本与聚类中心的加权相似程度,对目标函数进行最小化迭代运算,从而确定样本分类[25-26]。假设数据集为x=(x1,x2,…,xn),样本xj与聚类中心Ci的隶属度为uij,则目标函数J及其约束条件为:
(1)
(2)
式中:‖xj-Ci‖2为样本xj与聚类中心Ci的欧式距离;m为模糊化程度,一般取值为2[30];n为样本
数;c为聚类个数。
在聚类准则式(2)的约束条件下,求取式(1)中J函数的极值,由此,可得隶属度及聚类中心的迭代公式:
(3)

(4)
FCM算法计算步骤为:①设定聚类个数c,模糊化程度m,迭代收敛的精度ε,最大迭代次数Tmax;②用(0,1)间的任一随机数初始化隶属度矩阵U,使其满足式(2)的约束条件;③将U代入式(4)计算聚类中心Ci,并由式(3)更新隶属度矩阵U;④当隶属度变化ΔU<ε或者迭代次数t>Tmax,迭代终止,否则令t=t+1,重复步骤③;⑤计算并输出最优目标函数Jm(U*,C*),C*为最优聚类中心向量,对应最优分类数为c*,U*为最优分类的隶属度矩阵。
1.2 Bayes判别分析法
Bayes判别的基本思想是利用已知的先验概率分布推断后验概率分布,计算每个样本的后验概率和误判率,然后利用最大后验概率推断样本所属类别并使平均错判损失(ECM)达到最小[25]。假设类别总体为G=(G1,G2,…,Gd),d为类别个数,x=(x1,x2,…,xu)为一个样品,u为Bayes的属性个数,其属于某一类Gv的概率为qv,即先验概率为q1,q2,…qd。对于给定样品集R的一个划分r=(r1,r2,…,rd),误判的概率和平均判错损失分别为[18]:
(5)

(6)
式中:pv(x)为样本x属于Gv的后验概率;C(w|v)为样品x来自类别Gv而误判为Gw的损失;P(w|v,r)为误判概率;ECM为平均误判损失。
Bayes算法的判别过程为:①利用已分类的学习样本,按照式(5)构造一个判别函数,分别计算该样品落入d个互斥子域类别的概率;②利用已分类的预测样本,根据式(6)计算样本的ECM,当ECM最小,则得到Bayes判别最优分类。
2 致密油储层分类与判别关系式的建立
2.1 分类属性选取
通过对研究区长7储层69口取心井的调研分析,考虑到属性数据的完整性及获得的难易程度,最终优选出孔隙度(φ)、渗透率(K)、含油饱和度(So)、岩石密度(ρ)、初始月试油的平均日产油量(pD)、含水率(fw)及储层厚度(H)作为FCM聚类的属性参数。其中,孔隙度、渗透率和储层厚度为物性参数,表征致密油储层质量;含油饱和度为含油性参数,反映致密油储层原油富集程度;岩石密度为岩性参数,决定了储层的致密程度;平均日产油量和含水率为生产参数,反映致密油储层的开发效果。
2.2 FCM聚类计算
设定聚类个数为5,模糊化程度为2,迭代收敛的精度为0.000 01,最大迭代次数为100,其中,最优聚类个数根据文献[31]的方法确定。导入69个样本7个属性的矩阵样本,经过63次迭代,目标函数达到收敛精度的要求,各样本的隶属度矩阵值如图1所示,样本在某个类别的隶属度值最大则该样本属于此类。69个样本在日产油及含水率坐标系下的聚类结果如图2所示,5个类别的聚类中心向量属性参数如表1所示。

表1 聚类中心向量属性参数Table 1 Vector attribute parameters of clustering center

图1 隶属度矩阵值分布Fig.1 Value distribution of membership matrix

图2 FCM聚类结果Fig.2 FCM clustering results
根据中国油(气)层工业油流标准[32]及研究区致密储层生产实际情况分析,第I、Ⅱ、Ⅲ类储层日产油均大于0.5 t/d,具有工业开采价值,属于有效储层;第Ⅳ、V类储层日产油小于0.1 t/d,无工业开采价值,属于无效储层。在有效储层中,第I类储层的开发效果最好,判断为油层;第Ⅱ类储层次之,判断为差油层;第Ⅲ类储层日产油较低,含水率较高,判断为油水同层。在无效储层中,第Ⅳ类储层日产油低,含水率高,储层物性、含油性差,岩性致密,判断为水层;第V类储层日产油和含水率很低,储层物性及含油性差,岩性致密,判断为干层。
2.3 Bayes判别属性选取
根据储层的物性、含油性与常规测井曲线之间的相关性,考虑到研究区测井资料的完整程度及实际应用情况,最终优选自然伽马(GR)、自然电位(SP)、声波时差(AC)、深探测感应电阻率(RILD)和泥质含量(Vsh)5个参数作为Bayes判别分析的属性变量。测井曲线均已进行了标准化,其中,泥质含量由自然伽马通过式(7)、(8)求得[14]:
Vsh=2(GCUR·Vsh′-1)/(2GCUR-1)
(7)
Vsh′=(GR-GRmin)/(GRmax-GRmin)
(8)
式中:GRmin、GRmax分别为砂岩和泥岩层的自然伽马值;GCUR是与地层有关的经验系数,文中取值为2.0;Vsh′为归一化GR值的中间变量。
2.4 致密油储层类别与常规测井属性关系的建立
将FCM聚类结果和对应的判别属性数据导入SPSS软件中,检验各组属性变量均值的均等性(表2),即通过变量的单因素方差分析,寻找关键性的影响变量,分析均值不同变量的差异是否有统计意义,从而了解该变量有无作用。表2中威尔克Lambda统计量是组内平方和与总平方和的比值,F统计量是组间均方与组内均方的比值,自由度1为残差平方和自由度,自由度2为回归平方和自由度,显著性为F检验观测值F0对应的概率,显著性越小表示组间差异越显著。将显著性水平设为0.100。由表2可知,SP没有通过显著性检验,故舍弃该属性。Bayes属性参数确定后,针对每个类别得到一个待解的四元一次方程,将69个样本的聚类结果代入方程组中,根据式(6)使平均误判损失最小即可得到最优的Bayes线性判别函数系数(表3)。由表3结果,得到5类储层的判别函数:

表2 各组平均值的均等性检验Table 2 Equality verification of the average value of each group

表3 Bayes判别函数系数Table 3 Bayes discriminant function coefficient
YⅠ=-0.821GR+7.823AC+1.9RILD-221.693Vsh-857.056
(9)
YⅡ=0.685GR+7.482AC+1.478RILD-401.558Vsh-819.663
(10)
YⅢ=1.156GR+7.408AC+1.271RILD-461.436Vsh-814.313
(11)
YⅣ=1.527GR+7.135AC+1.113RILD-477.105Vsh-775.92
(12)
YⅤ=1.476GR+6.848AC+0.946RILD-403.821Vsh-736.567
(13)
为了验证判别函数的准确性,首先应用样本数据进行自身验证和交叉验证,自身验证通过将样本数据依次代入判别函数来验证函数的准确性,交叉验证通过某类别以外的其他判别函数对其进行验证(表4、5)。由表4可知,自身验证中,第I~V类储层的判别准确度分别为90.9%、90.0%、94.7%、100.0%、75.0%,平均为92.8%,69个样本只有5个判别错误。由表5可知,交互验证中,第I~V类储层判别准确度分别为72.7%、70.0%、89.5%、90.5%、75.0%,平均为82.6%,即69个样本中有12个判别错误。交互验证准确度相对较低的原因是由于第I类和第II类储层在广义概念上都属于油层,其储层“四性”特征及开发方式较为接近,难以区别,但实际应用中二者都属于具有较大开发潜力的储层,故其判断误差对实际的开发决策影响并不大。

表4 自身验证结果Table 4 Self verification results
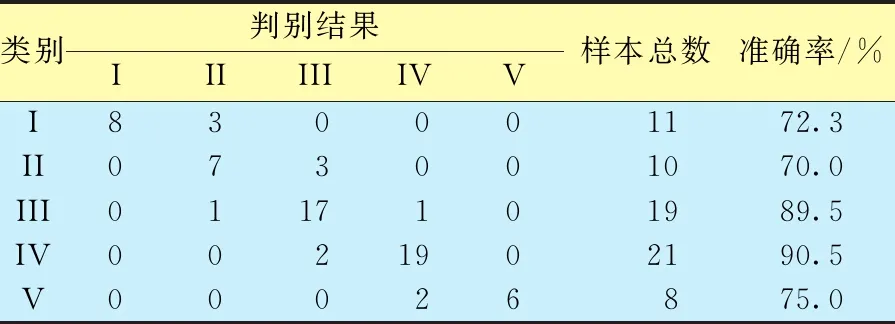
表5 交叉验证结果Table 5 Cross validation results
3 致密油储层分类评价
3.1 研究区概况
志丹地区位于鄂尔多斯盆地中部,区域构造上位于伊陕斜坡中西部,区内构造平缓,地层倾角为0.5~1.0 °,缺乏大型构造,仅局部发育少量低幅度鼻状隆起。根据沉积旋回及油层纵向分布规律,研究区三叠系延长组自下而上划分为10个油层组,其中,长7段沉积时,盆地处于最大湖泛期,湖盆在长7Ⅰ段和长7Ⅱ段发育多期半深湖—深湖相重力流成因砂体,在长7Ⅲ段则沉积优质的厚层烃源岩。湖盆中心由砂质碎屑流、浊积和滑塌形成的砂岩纵向上源储一体或紧邻,平面上优质烃源岩、致密储集层大面积分布,具有形成致密油的良好地质条件。长7油层组孔隙度为0.9%~20.2%,平均为7.3%,渗透率为0.01~2.51 mD,平均为0.31 mD,属于典型的特低孔、超低渗透致密油藏。
3.2 致密油储层分类评价
根据评价对象的尺度不同,采用2种方法对长7储层砂体进行分类评价:①测点评价。以测井采样点的数据为评价对象,根据判别函数,分别计算各测井采样点的判别函数,并划分到对应类别中。该方法评价的精度高,能分辨砂体内较小尺度的储层类别,缺点是计算量较大、效率较低。②砂体评价。以整个砂体为评价对象,通过统计出砂体平均的判别属性值,代入判别函数中计算,划分储层类别。该方法简单直观,缺点是分辨率低,不能细分储层内较小尺度的类别。
F63-1井为研究区的一口生产井,先后在长7Ⅱ6、长7Ⅰ2段射孔压裂生产。长7Ⅱ的试油平均日产液为10.7 m3/d,不含油,测井一次解释为油水同层,试油结论为水层。长7Ⅰ的试油平均日产液为4.51 m3/d,平均日产油为3.91 t/d,含水率为13.3%,测井一次解释为油水同层,试油结论为油层。通过测点评价,长7Ⅰ射孔砂体I类储层占64.7%,Ⅱ类储层占27.4%,Ⅲ类储层占7.9%,综合评价为I类储层,即油层;通过砂体评价,应用Bayes判别函数计算得到该套砂体YⅠ、YⅡ、YⅢ、YⅣ、YⅤ分别为840、830、748、645、685,I类储层的判别函数值最大,故砂体评价为油层。同理,2种评价方法判断长7Ⅱ射孔砂体为水层(图3),判别结果均与试油结论一致。

图3 F63-1井致密储层分类评价Fig.3 Classification and evaluation of reservoirs in Well F63-1
3.3 实际应用效果分析
应用建立的判别方程组,以储层砂体为评价对象,对研究区203口生产井进行了储层类别划分,并与试油结论进行对比,吻合率为89.7%,说明应用FCM-Bayes方法对致密油储层进行分类评价是可行的。该方法解决了储层分类涉及参数多且获取困难的问题,提高了应用常规测井资料识别致密油储层的准确度和精度。
导致判别结果误差的主要原因除地质因素外,还受流体性质、工程因素、能量补充方式样本完备性等诸多因素的影响。在相关属性数据可获取的情况下,收集尽可能多的学习样本数据,可进一步提高致密油储层分类评价的准确性。
4 结 论
(1) 优选孔隙度、渗透率、含油饱和度、岩石密度、初月试油的平均日产油量、含水率及储层厚度作为FCM属性参数,利用FCM聚类方法将研究区的致密油储层分为5类,第I~III类为有效储层,具有工业开采价值,第IV、V类为无效储层,不具备工业开采价值。
(2) 优选自然伽马、自然电位、声波时差、深探测感应电阻率和泥质含量作为Bayes判别分析的属性变量,最终确定不同类别储层的判别函数。
(3) 利用FCM聚类及Bayes判别方法划分研究区长7致密储层分类,吻合率为89.7%,表明该评价体系有效。
