面向HPC互连网络的低延迟前向纠错编码研究与实现 *
2020-11-30曹继军赖明澈徐炜遐
王 超,曹继军,罗 章,赖明澈,徐炜遐
(国防科技大学计算机学院,湖南 长沙 410073)
1 引言
面向HPC的高性能互连网络的特征是高带宽、低延迟和高可靠等。数据在网络物理信道中传输往往不能保证完全无误,而且随着传输速率的不断提升,数据传输通道产生错误的概率也会增大。要保证数据传输可靠主要有3种方式:自动反馈重传(Automatic Repeat-Request)、前向纠错(Forward Error Correction)、混合重传(Hybird Automatic Repeat Request)。当前,主流高性能互连网络端口速率已达到100~400 Gbps,其单通道速率已达到25~50 Gbps[1,2]。以这种速率传输数据,使用较多的是混合重传方式,即发生少量错误时,可以由前向纠错码纠正,超出前向纠错码纠错能力时,进行反馈重传,这就需要采用合适的前向纠错编码。前向纠错原理就是在数据发送之前编码端根据一定的编码规则增加一定的冗余,使原来不具有相关性的数据产生相关性,在译码端根据译码规则,利用冗余所产生的数据相关性来纠正信道中发生的错误,恢复发送的码序列。
纠错编码有很悠久的历史,自1950年提出汉明码发展到现在有很多子类,还包括BCH码、RS码、TURBO码和LDPC码等[3],但它们各有优缺点,目前比较前沿的是TURBO码和LDPC码,但TURBO码的延迟过大,LDPC码由于良好的性能需要比较长的码长且实现复杂,因此这2种纠错码不符合互连网络高效性的要求。由于RS编码是迄今为止发现的一类很好的线性纠错码,其纠错能力很强,特别是在较短和中等码长下,性能接近于理论极限,且构造方便,编码和译码相对规则简单,因此被广泛应用于光传输系统、数据存储、数字电视、卫星通信、深空探测和互连网络等多种领域。
当前IEEE 802.3以太网规范中100 Gbps技术标准采用RS(528,514)和RS(544,514)2种码型的编码子层[4],200/400 Gbps技术标准采用RS(544,514)码型的编码子层。RS-FEC编解码在提高纠错能力的同时,存在译码延迟大等问题,就这2种RS编码而言,RS(528,514)延迟比RS(544,514)低,但纠错能力相对较差。对于延迟较为敏感的高性能计算应用而言,在保证数据传输可靠性要求的前提下,延迟要求越低越好,这2种RS码延迟较大,难以满足延迟敏感型计算应用的通信需求。因此,研究低延迟的RS-FEC编码对高速互连网络发展具有重要意义。
2 RS编解码延迟分析
RS码是1960年由Reed和Solomon提出的[4],RS码是BCH码的一种分支,GF(q)上(q≠2,通常q=2m),码长n=q-1的本原BCH码称为RS码。GF(2m)域中,RS码型一般表示为RS(n,k),其中m表示符号长度,例如m=8表示符号由8位二进制数组成;n=2m-1表示码块长度;k表示码块的信息长度;K=n-k表示码块的校验元长度;t=(n-k)/2表示能够纠正的错误数目。
GF(2m)域中,n=2m-1的RS码型通常称为系统码或母码,可以通过减小n或k变为缩短码或打孔码,但会失去循环码的特性,不再是循环码。例如,当前IEEE 802.3以太网规范使用的RS(528,514)和RS(544,514)均为缩短码。其中RS(528,514)中以10位二进制数为1个符号,码长为528个符号,信息码块为514个符号,校验码块为14个符号,最多纠正7个错误。
2.1 RS编码原理
RS码的编码原理是根据一定的编码规则增加一定的冗余,使原来不具有相关性的数据产生相关性,主要有基于乘法、除法和校验多项式3种编码器。其中基于除法的编码流程分为以下3步:
(1)将信息多项式m(x)预乘xn-k,即右移n-k位,得到nx-km(x)。
(2)将nx-km(x)除以生成多项式g(x)[5,6],得余式r(x),其中g(x)确定了唯一的RS(n,k)码。
(3)由nx-km(x)+r(x) =c(x),即得到编码后的码字多项式。
图1为基于除法的编码器结构示意图[7]。

Figure 1 Structure of encoder based on division图1 基于除法的编码器结构示意图
2.2 RS译码原理
译码原理是利用冗余所产生的数据相关性来纠正信道中发生的错误,恢复发送的码序列。通用的译码流程[8]分为以下5步:
(1)由接收多项式R(x)求出伴随式Sj,j=1,2,…,2t。
(2)根据伴随式Sj求解关键方程,得出错误多项式σ(x)和错误值多项式ω(x)。
(3)用钱搜索算法[9]解出错误多项式σ(x)的根,得到错误位置。
(4)用福尼公式[9]计算错误值,得到错误图样E(x)。
(5)计算M(x)=R(x)-E(x),完成纠错。
图2为RS译码结构示意图。
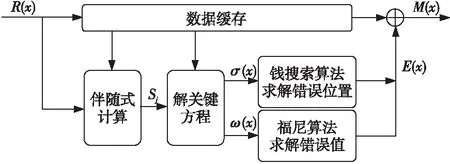
Figure 2 Structure of decoder图2 译码结构示意图
2.3 RS延迟分析
RS编解码延迟包括数据发送端的编码延迟和数据接收端的解码延迟,编码延迟主要是编码逻辑电路的固定延迟,由于数据编码不需要缓存参与,相对较小,因此RS-FEC的处理延迟主要来源于译码过程。根据译码流程,译码过程大致可分为3个过程:(1)伴随式计算;(2)关键方程求解;(3)Chien搜索算法、Forney算法求解和纠错输出。在不考虑多路并行的情况下,伴随式计算需要的时间约为k/δ,其中k为信息数据长度,δ为每周期传输的数据长度;关键方程的求解时间约为2t,其中t为校验元长度;Chien搜索算法、Forney算法求解和纠错输出的求解时间约为k/δ,因此总的译码延迟约为2k/δ+2t,即码长和校验元长度越长,延迟越大。因此,减小码长或校验元长度都可以减小FEC处理延迟。
3 新型低延迟FEC-RS(271,257)
根据第2节分析,减小码长和校验元长度可以减小FEC延迟,因此设计新RS码型可以从这2方面着手。当前以太网协议中,RS(528,514)和RS(544,514)比较成熟,所以本文以这2种RS码作为出发点。考虑RS(271,257)编码,其信息元长度是RS(528,514)和RS(544,514)的一半,码长是RS(544,514)的一半,校验元长度和RS(528,514)一样,比RS(544,514)减少了约一半。
从RS码参数上分析,这3种RS码的性能对比如表1所示。
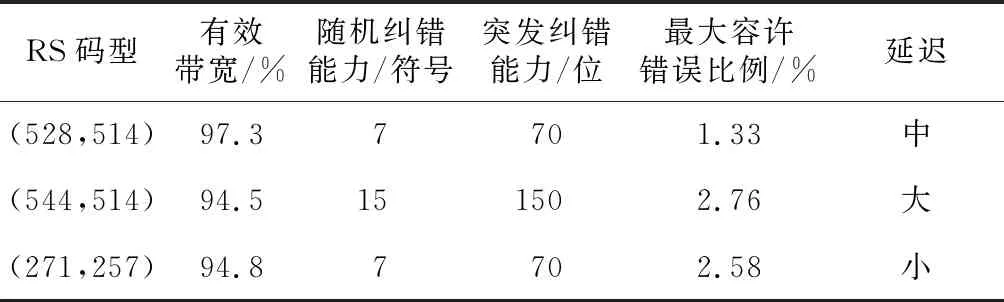
Table 1 Performance comparison of the three RS codes
从表1看,RS(528,514)带宽利用率最高,纠错能力最低,延迟大小适中;RS(544,514)纠错能力最高,延迟最大,带宽损耗最大;RS(271,257)带宽损耗和纠错能力与RS(544,514)相差不大,但延迟最小。经Matlab软件模拟分析,其纠错性能对比如图3所示。
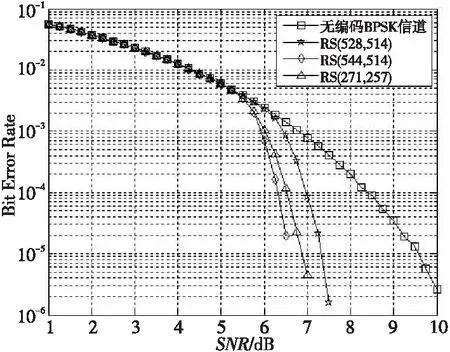
Figure 3 Comparison of error correction performance图3 纠错性能对比图
如图3所示,RS(271,257)的纠错能力强于RS(528,514)的,略低于RS(544,514)的,与理论数据分析结果相符。
4 基于RS(271,257)的编码子层设计
按照分层设计理念,面向HPC的高速互连网络的底层通常可分为事务层、链路层和物理层。而物理层又可分为物理编码子层PCS(Physical Coding Sublayer)、物理介质附加子层PMA(Physical Medium Attachment)和物理介质相关子层PMD(Physical Medium Dependent)。PCS主要负责实现编解码、多通道绑定、数据同步等功能。编解码是PCS的主要功能,也是PCS的重要特征。在高速互连网络物理层单通道传输速率规格为QDR(Quad Data Rate)(10 Gbps)时,其PCS采用8 b/10 b编码;物理通道为FDR(Fourteen Data Rate)(14 Gbps)规格时,其PCS采用64/66编码;物理通道为EDR(Enhanced Data Rate)(25 Gbps)和HDR(High Data Rate)(50 Gbps)时,单纯的64/66编码已经难以保证数据传输的可靠性,必须引入具有前向纠错能力的FEC编码才能提高数据传输质量,以弥补高速率物理通道误码率升高带来的数据传输可靠性下降。针对当前HDR通道规格,本文基于RS(271,257)实现了面向HPC互连网络的低延迟编码子层。
4.1 编码子层总体结构设计
如图4所示,编码子层的总体分为数据发送模块(PCS_TX)和数据接收模块(PCS_RX)。

Figure 4 Flow chart of coding and decoding process 图4 编译码处理流程图
PCS数据发送模块从数据链路层接收数据,先后经过64/66编码和速率匹配、264/257编码、加扰、插入对齐标记、FEC编码、符号分发处理后,将数据发送给物理介质。
PCS接收模块从物理介质接收数据,先后经过通道锁定对齐和重定序、FEC解码、删除对齐标记、解扰、257/264解码、66/64解码和速率匹配处理后,将数据发送给数据链路层。
4.2 模块接口设计
编码子层模块向外部主要提供3种接口,分别是用户数据发送和接收接口、高速SERDES数据发送和接收接口、配置与状态寄存器访问接口。
(1)用户数据发送与接收接口。在数据发送端,用户数据发送与接收接口接收上层数据链路层的数据,对其进行编码处理后发送给底层的高速SERDES;在数据接收端,用户数据发送与接收接口接收底层SERDES的数据,对其进行数据块边界锁定、同步、解码后发送给上层的数据链路层。为了匹配底层4通道SERDES速率,用户数据发送和接收接口数据宽度为256 b,工作频率为800 MHz。
(2)SERDES数据发送与接收接口。在网络端口的不同工作模式下,SERDES存在2种信号调制模式,分别是NRZ和PAM4。在NRZ调制模式下,编码子层支持的SERDES数据发送和接收单通道并行接口数据位宽是32,其最大可支持的单通道速率为25 Gbps。在PAM4调制模式下,编码子层支持的SERDES数据发送和接收单通道并行接口数据位宽是64,其最大可支持的单通道速率为53 Gbps。单个编码子层模块并行向底层4个SERDES发送数据,并从这4个SERDES接收数据。
(3)配置与状态寄存器访问接口。通过该接口可以对编码子层模块的配置寄存器和状态寄存器进行读写访问。可读写访问的配置包括:旁路示错控制、旁路纠错控制、对齐标记AM(Align Marker)插入周期控制等;只读访问的状态包括:链路状态、通道锁定状态、纠错计数、不可纠错计数、通道符号错误计数、通道映射关系等。
4.3 时钟域的划分
编码子层模块的时钟通常可划分为用户时钟域、参考时钟域和SERDES恢复时钟域。
用户数据发送与接收接口工作在用户时钟域。编码子层模块的大部分逻辑(包括编码和解码逻辑等)都工作在参考时钟域。除此之外,SERDES的发送端也使用参考时钟。SERDES恢复时钟域:一种方式是,为SERDES每个接收和发送通道(Lane)各提供一个时钟。在各个通道的时钟之间,以及一个通道内部的接收和发送时钟之间,均不存在任何频率和相位的关系(异步时钟)。另一种方式是,SERDES的接收端为每个通道提供异步时钟,但SERDES的发送端使用统一的参考时钟,这带来的好处是允许编码子层模块发送逻辑和SERDES发送逻辑使用同一个时钟,从而省去发送端的跨时钟域处理,进而降低延迟。
本文中编码子层模块的SERDES数据发送接口使用参考时钟,而SERDES数据接收接口的每个接收通道对应一个恢复时钟。同时,为了降低编码子层处理延迟,本文将用户时钟域和参考时钟域合并为同一时钟,从而进一步省去用户时钟域和参考时钟域之间的跨时钟域处理。唯一需要进行跨时钟处理的逻辑是SERDES各个通道接收端恢复时钟域和参考时钟域之间的跨时钟处理。
4.4 数据发送处理设计
数据发送端的处理流程为:
步骤164/66编码和速率匹配:编码层将256 b的报文FLIT进行64/66编码产生264 b数据块。
步骤2264/257编码:编码层将264 b数据块压缩编码为257 b的数据块。
步骤3加扰:编码层对数据进行加扰,加扰的多项式为X+X39+X58。其中X代表当前加扰的数据位,X39和X58分别代表当前数据的前39 b和58 b,“+”为异或运算符。
步骤4插入对齐标记:编码层周期性地向数据中插入特定符号串作为FEC块的对齐标记,插入周期通常为4 096个FEC块,每个FEC块包含2 570 b用户数据。
步骤5FEC编码:编码层对每个FEC块2 570 b用户数据产生140 b的校验和,并将校验和插入FEC块尾部。
步骤6符号分发:编码层将数据以10 b符号为单位顺序轮转发送到4个物理介质的适配层接口。
在插入对齐标记处理过程中,AM插入周期会受到相关配置寄存器的控制,如果AM插入周期控制位域设置为“0”,表示AM插入周期为4 096个FEC块,如果该位域设置为“1”,表示AM插入周期为300个FEC块。该配置位域的默认值为“0”,只有当需要模拟加速时,才将该值设置为“1”,此时能将编码子层的初始化过程提速约14倍。
FEC编码过程如图1所示,其中g0~gn-k-1是生成多项式的系数,信息多项式的系数被顺序送入编码电路执行除以g(x)的除法运算,同时被送至输出端,经过k个时钟周期后在移位寄存器b0~bn-k-1中保留的是余式r(x)的系数,这样前面n-k个时钟周期输出的是信息元,后k个时钟周期输出的是校验元。
符号分发是将上一批编码产生的校验数据与本批数据的第1个周期数据同时传输,在进行信道传输之前,需对数据进行分配,为4个信道分配相同的数据量,符号分发规则如表2所示。
表2中第1个周期传输的是上一批数据的校验符号和本批数据的前25个符号,第7个周期中包含了1个全0符号,以平衡信道数据量。

Table 2 Symbol distribution rule
4.5 数据接收处理设计
数据接收端的处理流程为:
步骤1通道锁定对齐和重定序:编码层从4个物理介质的适配层接口接收数据,识别数据中各自包含的对齐标记,依据对齐标记重新排列4路数据,对齐数据并上传至FEC解码模块。
步骤2FEC解码:编码层对每个2 710 b FEC块解码。如果配置使能了旁路纠错功能(Bypass Correction=1),则直接取出FEC块的2 570 b用户数据并上传至下一模块;否则,根据FEC块的140 b校验和对数据检查2 570 b用户数据的正确性,如果错误则纠错。
步骤3删除对齐标记:编码层删除数据中周期性出现的FEC块对齐标记。
步骤4解扰:编码层对数据进行解扰,解扰的多项式为X+X39+X58。
步骤5257/264解码:编码层将257 b的数据解压缩编码为264 b的数据块。
步骤666/64解码和速率匹配:编码层将264 b的数据块进行66/64解码产生256 b数据块并交给链路层。
FEC解码器采用BM算法[10]求解关键方程,Chien搜索算法求错误位置,Forney算法求错误值。当校验和验算发现无差错发生时,经旁路选择器直接选择前面的信息元数据进行输出;当发现有错误发生时,由校验核利用BM算法计算关键方程,再经Chien算法和Forney算法计算偏移量和误码量,并进行数据纠错,当错误个数在纠错能力内时,选择纠错后的信息元数据输出,当错误个数超出纠错能力时,纠错失败,需要进行反馈重传。

Figure 5 Model of decoding delay analysis图5 译码延迟分析模型
根据译码原理和工程实现,RS(271,257)和RS(528,514)的解码延迟分析如图5所示。可见,在RS(271,257)解码处理流程中,校验核验算需要10时钟周期,关键方程求解需要15时钟周期,Chien搜索算法和Forney算法求解需要2时钟周期,纠错输出需要10时钟周期,考虑到最长通路,整体延迟约为39时钟周期,与RS(528,514)相比,校验核验算和纠错输出各减少了10时钟周期,共减少了20时钟周期,延迟性能有较大提升。
4.6 其它关键功能设计
除了提供通道数据块锁定、多通道绑定、加解扰、编解码等基础性编码子层功能外,为了增强RAS(Reliability、Availability、Serviceability)特性,本文设计的编码子层还提供如下功能:
(1)通道自动极性翻转和重定序:高速网络物理通道采用SERDES技术传输,其串口为P/N差分信号。通常2个SERDES对接时,其P和N信号应该对应相接。如果P和N信号相反相接,则称为通道极性翻转。编码子层在数据接收处理的通道锁定对齐步骤中,通过同时检测对齐标记及其反码,判据通道极性是否翻转。如果发生极性翻转,则将数据的反码输出给后续逻辑处理。这种自动翻转处理机制无需配置SERDES支持而实现通道极性反接,为PCB布线设计和调试带来了便利。自动极性翻转针对的是单通道间的P/N差分信号对接。而通道自动重定序针对的是2个网络端口(本文中每个端口绑定了4个物理通道,且分别编号为0~3)之间的通道乱序相接,其实现机理如下所示:由于单个端口各个通道在发送数据中插入的对齐标记是不同的,所以编码子层接收方通过对齐标记识别出各个通道,然后对各个通道的数据重新排序组合后再上传给上层逻辑。通道自动重定序也是一种降低PCB布线设计难度的技术。
(2)通道容错:综合考虑逻辑实现的复杂性和容错性目标,编码子层模块实现了对x1,x2,x4通道绑定模式的支持,而且在部分通道出现故障的情况下,链路2端编码子层状态机通过自动协商,实现通道绑定模式的降级(故障通道数目分别为1,2,3时,通道绑定模式分别为x2,x2,x1),从而避开故障通道发送和接收数据,保证网络端口的可用性和可靠性。
(3)旁路纠错和示错:实际网络物理介质应用场景多种多样,并不是所有应用场景的物理介质数据传输都存在误码,所以编码子层的解码模块实现了纠错旁路(Bypass Correction)和示错旁路(Bypass Indication)功能。根据链路质量灵活配置旁路示错和旁路纠错功能,可以降低编码子层处理延迟。根据图5所示的解码延迟分析模型,只旁路纠错就可以减少10时钟周期处理延迟,而既旁路示错又旁路纠错可以减少20时钟周期处理延迟。
5 资源消耗与延迟性能评估
为了验证本文提出的基于RS(271,257)的低延迟编码子层结构及其关键技术,本节使用Verilog硬件描述语言实现了编码子层RTL模块。同时,为了评估RS(271,257)相比以太网标准的RS(528,514)的性能优化,也使用Verilog语言实现了基于RS(528,514)的编码子层。为了便于表述,将上述2种编码子层模块实现分别表示为RS271-PCS和RS528-PCS。
5.1 资源消耗评估
为了评估RS271-PCS和RS528-PCS 2种编码子层实现实际使用的逻辑资源情况,对这2种逻辑实现的RTL代码在FPGA设计平台上进行了综合。综合工具是Xilinx公司的Vivado v2018.2(64-bit),综合目标器件选用了Virtex UltraScale系列xcvu440-flga2892-2-e。综合策略采用默认策略(即Vivado Synthesis Defaults)。在FPGA中,主要的逻辑资源包括:查找表LUT和查找表存储器LUTRAM等。资源消耗情况如表3所示,可见与RS528-PCS相比,RS271-PCS的LUT资源消耗降低了约6.32%,LUTRAM资源消耗降低了约0.13%。
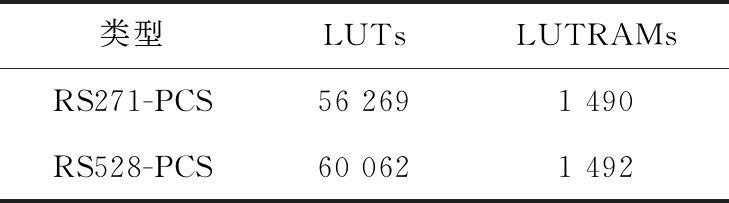
Table 3 Resource consumption
5.2 延迟性能评估
为了评估RS271-PCS和RS528-PCS 2种编码子层实现的处理延迟,本文分别以这2种逻辑实现的RTL实现作为DUT(Device Under Test),采用System Verilog语言构造了统一的性能测试环境,并使用Synopsys公司的VCS工具进行模拟。依据当前的工艺水平,设置DUT的参考时钟工作在800 MHz。为了简化测试环境,将DUT的SERDES数据发送接口与数据接收接口直接相接。由于旁路模式会影响编码子层处理延迟,所以本文的测试覆盖了3种旁路模式。延迟统计测量的是数据从用户数据发送接口进入DUT,到从DUT接收接口出来的通过时间。
延迟的模拟测试结果如表4所示,可见:(1)与RS528-PCS相比,RS271-PCS在2种旁路配置(纠错&旁路示错、旁路纠错&旁路示错)模式下的处理延迟分别降低了17.74%和22.73%;(2)与RS528-PCS相比,RS271-PCS在非旁路模式(纠错&示错)下的处理延迟降低了25 ns,大大降低了编码子层处理延迟。

Table 4 Delayed performance simulation results
除了对编码子层的延迟性能进行了评估,我们还利用该测试环境构造了各种测试场景,对编码子层的各项功能,例如通道自动极性翻转、通道自动重定序、通道容错、通道SKEW容限等进行了验证,验证结果表明了结构设计的可行性和功能实现的正确性。
6 结束语
目前,物理介质的传输速率已经达到25~50 Gbps,在该速率范围下,为了保证数据传输的正确性,IEEE 802.3cd标准的编码子层使用RS(528,514)和RS(544,514) 前向纠错编码(FEC)以纠正数据传输中的差错。
本文根据下一代HPC互连网络低延迟需求,基于当前成熟的前向纠错编码,分析RS编码参数与延迟之间的关系,提出一种面向HPC互连网络的低延迟RS(271,257)的FEC编码,并对基于该编码的网络编码子层进行了设计和实现,通过模拟验证,该互连网络编码子层处理延迟最高为75 ns,相较于目前成熟的RS编码有较大提升,更适合于下一代HPC互连网络的低延迟需求,且其纠错能力也有较大程度的保留。下一步将研究多种编码的融合设计与实现,以满足不同融合网络的设计需求。
