基于深度学习的蛋白质亚细胞定位预测
2020-11-30王艺皓丁洪伟保利勇张颖婕
王艺皓,丁洪伟,李 波,保利勇,张颖婕
(云南大学信息学院,昆明 650500)
(∗通信作者电子邮箱893885847@qq.com)
0 引言
随着蛋白质组学、基因组学等领域研究[1]的快速发展,大量的生物基因信息被不断挖掘,海量实验累积的蛋白质数量更是呈指数式增长,传统的实验方法耗时费力,已经难以满足蛋白质定位研究的需要,因此需要通过生物信息学方法进行蛋白质亚细胞定位预测。
近年来,基于机器学习的蛋白质亚细胞定位算法[2-7]已经取得了突破性的进展:Wang 等[2]针对革兰氏阳性和革兰氏阴性细菌蛋白提出了两种有效的多标记预测因子,并通过集成学习的方式进一步优化了分类器性能;Wan 等[3]提出了一种mGOASVM(multi-label protein subcellular localization based on Gene Ontology and Support Vector Machines)算法,该算法将基因本体(Gene Ontology,GO)术语出现频率引入特征向量的表达,并采用多位点支持向量机(Support Vector Machine,SVM)分类器进行分类预测,最终在Virus proteins和Plant proteins数据集上分别取得了88.9%和87.4%的实际准确率;Wan 等[5]结合了GO 术语出现的频率与其词之间的语义相似性,提出了一种HybridGO-Loc(mining Hybrid features on Gene Ontology for predicting subcellular Localization of multi-location proteins)算法,该算法分别在Virus proteins和Plant proteins数据集上取得了93.7%和93.6%的实际准确率。综上所述,传统机器学习方法应用于提高蛋白质定位预测的准确性已经取得了相当多的成就,但大多数的传统机器学习方法仍需通过手工操作来表示特征,而深度学习的出现良好地解决了这个问题。
与传统的机器学习方法相比,深度学习能够通过多层次深度网络结构从输入数据中自动学习良好的特征表示。经典的深度学习框架主要有深度置信网络(Deep Belief Network,DBN)[8]、堆栈式自编码器(Stacked AutoEncoder,SAE)[9]和卷积神经网络(Convolutional Neural Network,CNN)[10]等。由于深度网络强大的学习能力和泛化能力,近几年已经开始逐渐应用于生物信息学领域[11-14]中。例如:Wen 等[11]利用DBN 提出了一种用于预测药物-靶标之间的相互作用的深度学习算法——DeepDTIs(Deep learning-based Drug-Target Interaction prediction),该算法性能超过了当时最先进的传统机器学习算法;Alipanahi等[12]基于CNN 提出了一种称为DeepBind的深度学习算法,该算法用于预测DNA和RNA结合蛋白的序列特异性,取得了不错的效果;Liu 等[13]结合支持向量机和深度神经网络提出了一种用于蛋白质折叠识别的算法——DeepSVMfold,该算法取得了明显优于其他传统机器学习算法的性能表现。随着越来越多的研究者们将注意力转移到深度学习的应用研究中,大量新颖有效的深度学习算法不断涌现,这也为蛋白质亚细胞的定位预测研究工作提供了一定的便利条件。
张颖婕[7]基于特征融合和集成学习的思想,结合了伪氨基酸组成法(Pseudo-Amino Acid Composition,PseAAC)、伪位置特异性得分矩阵(Pseudo Position Specific Scoring Matrix,PsePSSM)和三肽组成三种特征提取方式,然后通过主成分分析法(Principal Components Analysis,PCA)降维,最后输入集成SVM 分类器完成了蛋白质定位预测任务。虽然文献[7]取得了较好的预测准确率,但是也带来了以下几个问题。
首先,采用PCA 对融合后的特征向量进行降维处理,虽然可以有效剔除冗余信息并避免维度灾难带来的影响,但同时它也会带来一些消极影响:1)对于主成分的解释往往具有一定的模糊性,进而导致降维后的特征表示可能与原始数据有所差异;2)某些主成分虽然贡献率小,但是它们往往包含了关于样本差异的重要信息,特别是像蛋白质这样的不平衡数据集;3)PCA作为无监督学习算法,仍需通过手工操作来确定主成分和表示特征。
其次,集成支持向量机的使用,虽然在一定程度上提高了预测准确率,但同时它也增加了算法复杂度。
本文针对以上问题,对特征提取模型和分类器进行了改进和优化。首先对PseAAC 和三联体编码法(Conjoint Traid,CT)进行了改进,进一步丰富了特征融合后的蛋白质序列表征模型;接着将融合后的特征向量输入到本文构造好的堆栈式降噪自编码器(Stacked Denoising AutoEncoder,SDAE)深度网络,SDAE 网络可以进一步深入学习到表达能力更强、泛化能力更好、更接近真实数据的特征表示,避免了PCA 降维对蛋白质序列表征模型产生的消极影响;然后输入Softmax 回归分类器进行分类预测,这降低了算法的复杂度;最后采用留一法分别在Virus proteins 和Plant proteins 数据集上进行交叉验证,并将实验结果与其他现有算法进行比较。实验结果表明,本文提出的新方法能够有效提高蛋白质亚细胞定位预测的准确性。
1 构建多位点蛋白质序列特征提取模型
1.1 改进型伪氨基酸组成模型
Chou[15]提出了伪氨基酸组分(PseAAC)方法,在氨基酸组分法(Amino Acid Composition,AAC)的基础上引入了λ 阶相关因子更好地表达序列信息。传统的PseAAC 模型仅考虑了疏水性、亲水性和侧链分子量三种理化特征,本文在此基础上增加了极性、极化率、溶剂化自由能、曲线形状指数、转移自由能、氨基酸组分、回归分析相关系数、残基可及表面、分配系数、氨基酸边链体积、表面区域溶解能力、网络负荷指数共12种氨基酸理化性质,构造了一种包含15 种氨基酸理化性质的改进型PseAAC模型。
根据改进型PseAAC模型,每条蛋白质序列可以表示为:

其中每个元素pu可由式(2)求出:
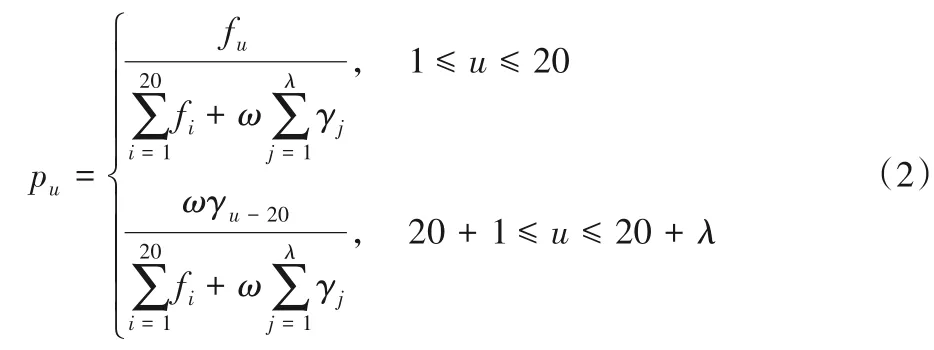
其中:fu表示每种氨基酸在蛋白质序列中出现的概率;ω 是权重因子,本文默认取0.05;γj表示j个紧邻相关因子,反映了不同氨基酸之间的顺序信息,可由式(3)求得:

Ji,i+k称为相关函数,其定义为:
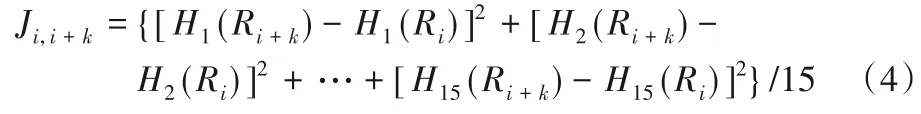
其中H(Ri)由式(5)求得:

其中:h0(Ri)为氨基酸Ri对应理化性质的原始特征值为对应理化性质下20种氨基酸原始特征值的平均值,ν(h0)表示其对应的方差。
由于λ 的取值会影响最终分类预测的结果,故要通过实验选取最佳参数。实验中λ 分别取1~30,输入支持向量机在数据集上进行实验,采用留一法对预测结果进行检验,通过比较得出,当λ=15时预测准确率达到最高。因此,通过改进型PseAAC,一条蛋白质序列可以转化为一个35维的特征向量。
1.2 伪位置特异性得分矩阵
Jones[16]提出了位置特异性得分矩阵(Position Specific Scoring Matrix,PSSM),该方法充分考虑了氨基酸的序列进化信息。本文选用了PSI-BLAST[17]来获取PSSM 矩阵,设置阈值为0.001,最大迭代次数为3,选取NCBI 的非冗余蛋白质数据库(non-redundant,nr)[18]作为对比,其下载网址为ftp://ftp.ncbi.nih.gov/blast/db/nr。由此可以获得一个L × 20 的PSSM矩阵,即:


由于不同蛋白质序列的长度L 是不同的,故需要将不同蛋白质序列的PSSM 矩阵转化为维度相同的矩阵。从PSSM矩阵中提取氨基酸组分(AAC)则得到了PSSM-AAC模型,即:
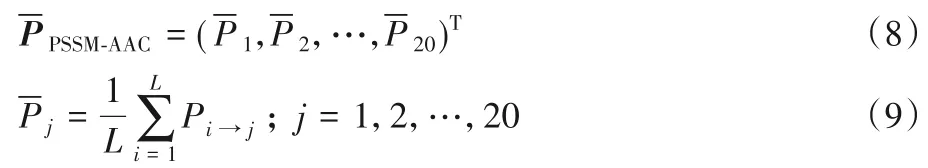

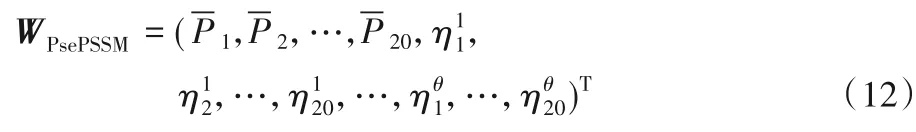
1.3 三联体编码
Shen 等[20]提出了三联体编码方式(CT)用于预测蛋白质相互作用的工作中,该方法考虑了蛋白质序列中相邻氨基酸分子之间的相互作用。氨基酸的分类依据决定了三联体的构成方式,与按照亲疏水性划分为6 类[7]不同,本文根据偶极性和侧链体积将20 种氨基酸重新划分成7 类,接着再引入紧邻三联体,将连续的三个氨基酸看作是一种三联体结构,故可得三联体共有343(7×7×7)种构成方式。由CT 可得,每条蛋白质序列有343 个特征因子fi。由于fi的大小与蛋白质序列的长度成正比关系,而且不同的蛋白质序列长度相差较大,故要进行归一化处理,引入以下定义:
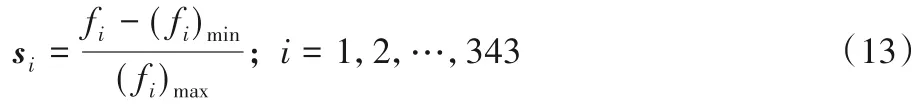
其中:si表示标准化后的特征向量,且si∈[0,1]。接下来将蛋白质对的两条序列串联起来以表示其相互作用信息:

其中DA和DB表示蛋白质对的两条序列。综上可得,每条蛋白质序列可以转为343(7×7×7)维的特征向量表示,即:
在企业绩效管理工作的开展中,最终目的都是将企业绩效管理工作的开展提升整体企业业绩开展能力,并且在企业业绩开展能力的提升过程中,能够将对应的绩效管理工作和对应的绩效管理因素协调好。保障了绩效管理因素控制关系的协调性建设,同时按照这种绩效管理因素的考核实施来看,在石油装备企业的建设和管理中,要想保障HU绩效考核管理体系建设能够满足石油装备企业的自身性绩效管理工作开展需求,对应的石油装备企业绩效考核管理者,应该在绩效考核管理工作的开展中,将对应的绩效考核管理工作与激励制度的建设结合在一起,这样不仅能够调动企业员工的工作积极性,同时也能够提升绩效考核管理效率,保障了企业的科学化绩效管理。

1.4 多特征融合
本文基于多特征融合的思想,将改进型PseAAC、PsePSSM 和三联体编码法三种特征提取方式结合,构成了一种全新的蛋白质序列特征提取模型。融合之后的蛋白质序列信息可由式(16)表达:
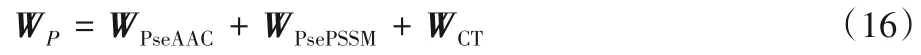
将数值代入之后,每条蛋白质序列可以转化为458(35+80+343)维特征向量表示。
2 堆栈式降噪自编码器
堆栈式降噪自编码器(SDAE)[21]是由多个降噪自编码器(Denoising AutoEncoder,DAE)逐层连接而成的一种深度神经网络结构。它通常主要包括两个过程:无监督的预训练和有监督的微调。预训练过程会以无监督方式逐层学习深层特征并初始化深度网络的参数,同时它会使用反向传播算法以微调的监督方式进一步优化预训练过程生成的参数,从而提升模型性能。因此,SDAE 具有良好的学习能力和泛化能力。SDAE模型架构如图1所示。
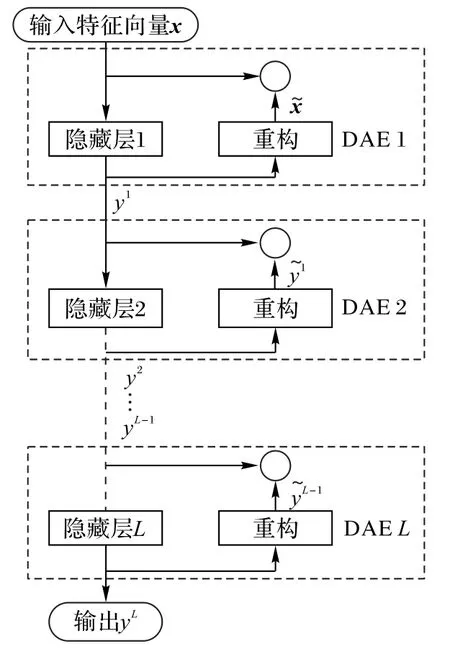
图1 SDAE模型架构Fig.1 Model architecture of SDAE
自编码器(Auto Encoder,AE)是一种无监督表征学习的高效深度神经网络,本文默认输出层与输入层参数相同。AE由编码器和解码器组成。假设AE输入特征向量其中dx表示输入的维数,编码器通过以下映射函数h将x从输入层投影到隐藏层y ∈Rdy:

其中:W 表示dy× dx权重矩阵表示映射到隐藏层对应的向量维度)表示偏差向量。本文选取ReLU(Rectified Linear Unit)函数作为激活函数af。
在解码器中,隐藏层y 通过以下映射函数h*映射到输出层

在AE 中,每个输入特征向量xi通过函数h 映射到隐藏层yi,再通过函数h*映射到输出层输出重构向量。为了使重构输出与输入x 尽可能相似,本文选取ReLU 函数作为隐藏层的激活函数af,选取Softplus 函数作为重构层的激活函数,同时引入以下均方误差:
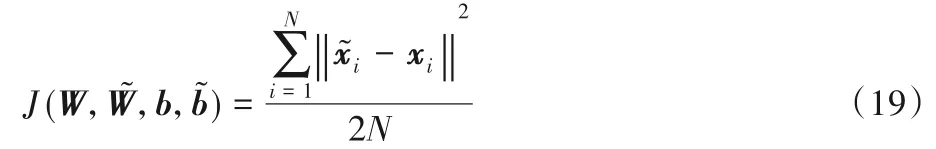
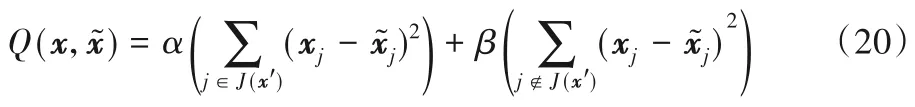
其中:α 为噪声污染维度重构代价权重,β 为无噪声污染维度重构权重。
本文在此基础上,提出了一种堆栈式降噪自编码器(SDAE)用在蛋白质定位预测任务中。SDAE 训练过程如图2所示。
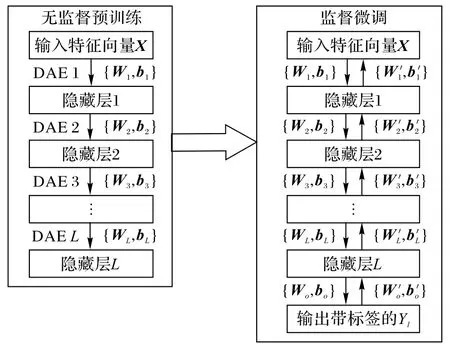
图2 SDAE训练流程Fig.2 Training flow chart of SDAE
如图2 所示,SDAE 主要进行两个步骤,分别是无监督预训练和监督微调。在预训练中,对于首个DAE 按照最小化重构误差原则将输入的原始特征向量映射到第一个隐藏层,训练完首个DAE后得到参数{W1,b1},接着将第一个隐藏层的输出会作为第二个隐藏层的输入,继续训练第二个DAE 得到参数{W2,b2}。以这样的方式来对整个SDAE 层进行逐层预训练,直到得到最后一个DAE 层。在无监督预训练之后,通过预训练得到的权重参数{Wk,bk}(k=1,2,…,K)来初始化每个隐藏层的权重,然后通过反向传播对整个深度网络进行微调,通过最小化目标变量的预测误差来获得更新权重,k=1,2,…,K。其反向传播函数定义如下:

其中:rj表示第j条蛋白质序列标记值表示其预测值。SDAE深度网络最后一层选用Softmax 回归函数进行分类。本文SDAE算法采用DeepLearing Tutorials 软件包在Matlab2018a中实现,实验环境为Intel Core i7-9750H CPU 2.90 GHz 16.0 GB。
3 性能评估
目前,常用于模型性能检测的主要方法有独立性检验、自相容检验、K 折交叉验证和留一法(leave-one-out cross validation)等。其中,留一法由于其客观公正的特点,被广泛应用于蛋白质亚细胞定位预测模型的性能评估工作当中[23]。故本文选取留一法对模型性能进行评估。对于评估指标,本文采用生物信息学中最常用的5个指标[24]来对模型性能进行全方位的评估:

4 实验结果与分析
4.1 数据集
本文选用数据集来自被研究者们广泛认可和使用的Plant proteins、Viral proteins 两个数据集(可以从http://www.csbio.sjtu.edu.cn/bioinf/下载):数据集Plant proteins 共包括1 055 条蛋白质序列,涉及12 个亚细胞位点标签;数据集Viral proteins 共包含252 条蛋白质序列,涉及6 个亚细胞位点标签。数据集的详细信息如表1所示。
在Plant proteins 和Viral proteins 两个数据集中,同时拥有大量的单位点蛋白和多位点蛋白,适用于本文对于蛋白质亚细胞的多标签分类预测的研究。其具体位点分布情况如表2所示。

表1 实验中使用的Viral proteins和Plant proteins数据集Tab.1 Viral proteins and Plant proteins datasets used in the experiment

表2 Viral proteins和Plant proteins数据集中蛋白质序列位点分布情况Tab.2 Distribution of protein sequence sites in Viral proteins and Plant proteins datasets
4.2 实验结果与分析
4.2.1 特征提取算法性能分析
首先在Viral proteins 和Plant proteins 数据集上分别用改进型PseAAC、PsePSSM、三联体编码法、多特征融合法和本文提出的新方法进行实验并使用留一法进行验证,其实验结果如表3所示。
从表3可以看出,多特征融合法由于结合了前三种特征提取方法构造了更为丰富的蛋白质序列表征模型,其分类预测结果在各项指标上完全碾压其他三种单一特征提取方法。多特征融合法与三种单一特征提取方法中表现最好的改进型PseAAC 相比,其Coverage、Aiming、Accuracy 和Absolute True均提升了6个百分点以上,同时Absolute False降低了1个百分点左右。同时可以看出,本文方法由于加入了堆栈式降噪自编码深度(SDAE)网络进一步筛选并提取了更加鲁棒和真实的特征表示,其实验各项指标相对多特征融合法来讲又有了大幅度的提升。对于Viral proteins数据集,本文方法和多特征融合法相比,前者的Coverage、Aiming、Accuracy 和Absolute True 分别比后者高出了4.1、4.91、0.94 和1.6 个百分点,而Absolute False 降低了0.58 个百分点;对于Plant proteins 数据集,本文方法的Coverage、Aiming、Accuracy 和Absolute True 分别比多特征融合法提高了4.25、5.75、1.51和3.93个百分点,而Absolute False 降低了1.27个百分点。综上所述,本文方法可以有效提高多位点亚细胞分类预测的准确性。

表3 不同方法在Viral proteins数据集和Plant proteins数据集上的实验结果对比 单位:%Tab.3 Comparison of experimental results of different methods on Viral proteins dataset and Plant proteins dataset unit:%
4.2.2 分类器性能分析
本节主要对目前用于多位点亚细胞定位任务四种表现较好的分类器进行了实验和对比。这四种分类器分别为:朴素贝叶斯(Naive Bayesian,NB)、SVM、随机森林(Random Forests,RF)以及Softmax 回归。首先将SDAE 网络得到的特征向量分别输入NB、SVM、RF 和Softmax 回归分类器中,采用留一法在Viral proteins 和Plant proteins 两个数据集上进行交叉验证。其中,NB和RF均采用默认参数;SVM 中的核函数选择高斯核函数。实验结果如图3所示。
由图3 可以看出,在Viral proteins 数据集上,NB、SVM、RF分别取得了91.2%、93.7%和96%的整体准确率,而本文所选用的Softmax回归分类器取得了98.2%的整体准确率,相比前三种分类算法分别提高了7、4.5 和2.2 个百分点;而在Plant proteins 数据集上,NB、SVM、RF 分别取得了89.5%、92.9%和95.2%的整体准确率,本文所选用的Softmax 回归分类器取得了97.6%的整体准确率,相比前三种分类算法分别提高了8.1、4.7 和2.4 个百分点。综上所述,本文所选用的Softmax回归分类器分类效果最好。
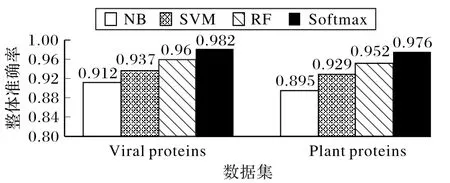
图3 在两个数据集上四种分类算法的预测结果对比Fig.3 Comparison of prediction results of four classification algorithms on two datasets
4.2.3 与其他算法比较
接下来将本文方法所取得的实验结果与其他现有算法模型取得的实验结果进行对比,均采用留一法进行测试。先依次对各位点标签所取得的预测结果进行分析比较,在Viral proteins数据集上的实验对比结果如表4所示。
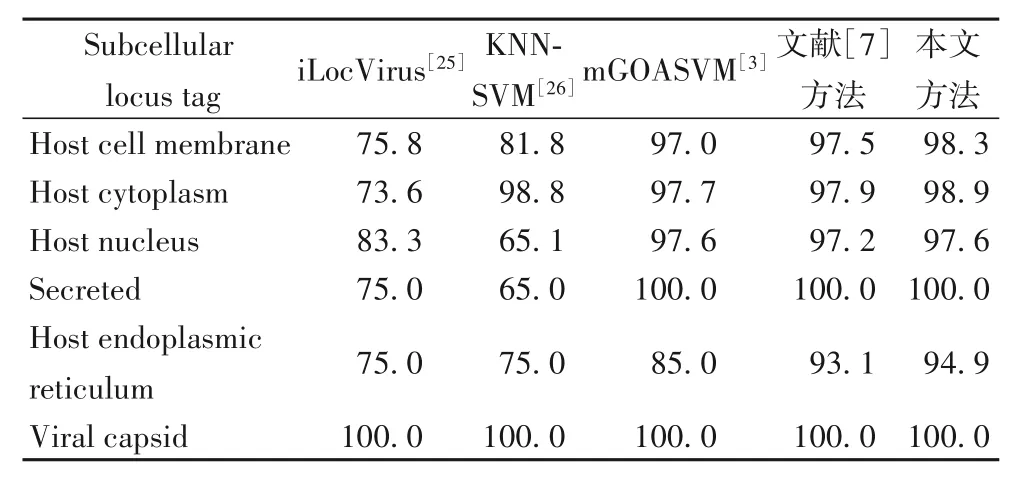
表4 Viral proteins数据集上不同方法性能的比较结果单位:%Tab.4 Performance comparison of different methods on Viral proteins dataset unit:%
由表4 可以看出,本文所提新方法与iLoc-Virus、KNNSVM、mGOASVM 算法的实验结果相比,均有较明显的提高。特别是与文献[7]算法相比,本文方法在Host cell membrane、Host cytoplasm、Host nucleus 和Host endoplasmic reticulum 位点上的预测准确率均有不同程度的提升,说明了本文在特征融合后引入SDAE 深度网络的有效性和科学性。为了进一步验证新方法的优越性,将预测结果与现有算法中表现较好的mGOASVM 和文献[7]算法进一步进行比较,其详细对比结果如表5所示。
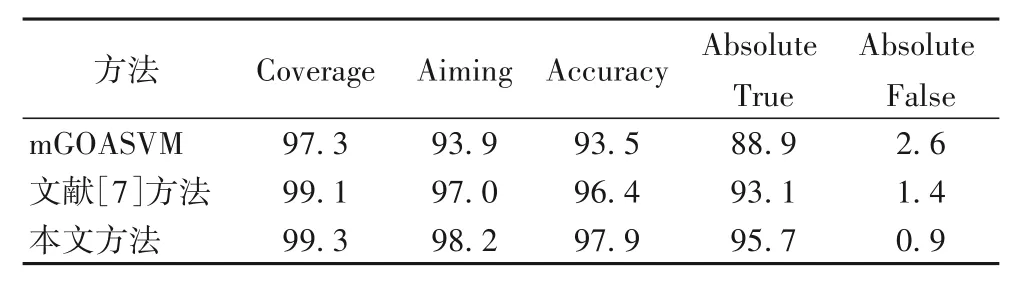
表5 Viral proteins数据集上三种方法的实验性能对比 单位:%Tab.5 Comparison of the experimental performance of three methods on Viral proteins dataset unit:%
由表5 可得,在Viral proteins 数据集上,本文方法与mGOASVM 算法相比,前者的Coverage、Aiming、Accuracy 和Absolute True 分别比后者提高了2、4.3、4.4 和6.8 个百分点,其Absolute False 降低了1.7 个百分点,可以看出整体提升幅度还是蛮大的;进一步分析,本文方法与文献[7]相比,其Coverage、Aiming、Accuracy 和Absolute True 分别提升了0.2、1.2、1.5 和2.6 个百分点,而Absolute False 降低了0.5 个百分点,可以发现整体提升效果还是很明显的。综上可得,本文方法在数据集Viral proteins上表现出了良好的分类预测性能。
为了进一步验证本文方法的优越性,继续在数据集Plant proteins 上进行实验分析,将各位点标签上得到的预测结果与其他现有算法模型取得的实验结果进行比较,其对比结果如表6 所示。由表6 可知,与传统的蛋白质定位算法iLoc-Plant相比,本文方法在蛋白质各位点标签上的预测准确率有显著的提升。而相较于mGOASVM 和HybridGO-Loc 这两种算法,本文方法除了在Cell wall proteins 和Mitochondrion proteins 位点的预测准确率稍有下降以外,其他位点的预测准确率均有一定程度的提高;与文献[7]算法相比,本文方法除了在Nucleus proteins 位点预测准确率稍有下降,其他位点的预测准确率都基本提升和持平。特别的,本文方法在Extracell proteins、Peroxisome proteins、Plastid proteins 和 Vacuole proteins 位点上取得了100%的预测准确率。由于这四种方法各位点亚细胞预测准确率较为接近,为了进一步验证本文方法的有效性,接下来引入多标签预测评估指标,对四种方法进一步分析比较,其详细对比结果如表7所示。
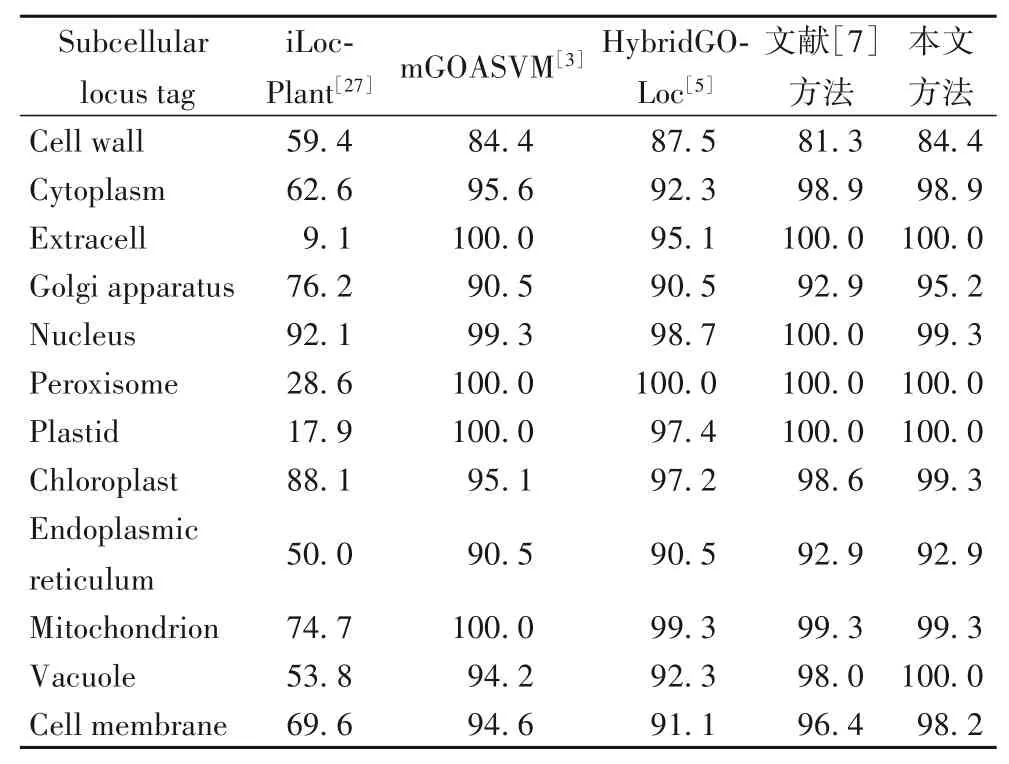
表6 Plant proteins数据集上不同方法性能的比较结果 单位:%Tab.6 Performance comparison of different methods on Plant proteins dataset unit:%
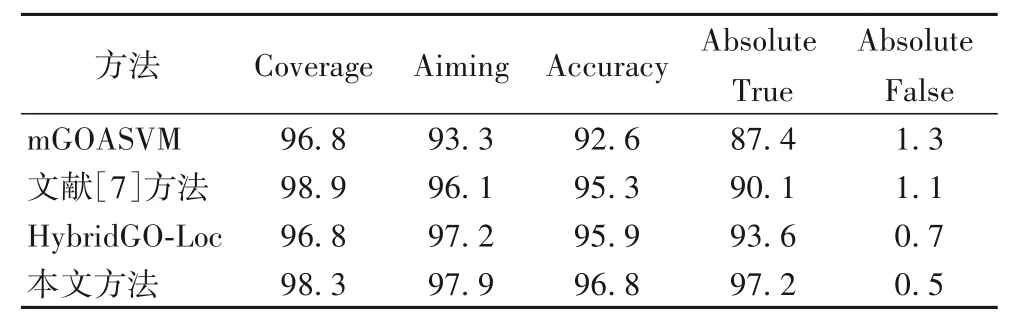
表7 Plant proteins数据集上四种方法的实验性能对比 单位:%Tab.7 Comparison of the experimental performance of four methods on Plant proteins dataset unit:%
由表7 可知,在Plant proteins 数据集上,HybridGO-Loc 算法的分类预测效果明显要优于mGOASVM 和文献[7]算法,故本文方法与三种算法中相对表现更好的HybridGO-Loc 算法相比,其Coverage、Aiming、Accuracy 和Absolute True 分别提升了1.5、0.7、0.9 和3.6 个百分点,而Absolute False 降低了0.2个百分点。进一步分析,本文方法与文献[7]方法相比,虽然其Coverage 略有下降,但其他指标均有明显改善,其Aiming、Accuracy 和Absolute True 分别提升了1.8、1.5 和7.1 个百分点,而Absolute False 降低了0.6个百分点,这再一次证明了本文方法优化策略的有效性和科学性。综上所述,本文方法能有效提高多位点亚细胞定位的预测效果。
5 结语
本文提出了一种基于深度学习的蛋白质亚细胞定位预测新方法。首先,分别通过改进型PseAAC、PsePSSM 和三联体编码法对蛋白质序列信息进行特征提取,并将三种方法提取的特征向量进行融合,构造了一种全新的蛋白质序列信息表达模型,该模型不仅包含了蛋白质序列中氨基酸的理化性质、频率信息和顺序信息,还充分考虑了氨基酸之间的进化信息以及相互作用,进一步丰富了蛋白质序列表达信息;接着,将融合后的特征向量输入SDAE 深度网络,通过预训练和微调的方式得到最优的深度学习网络,该网络可以自动学习并提取更加鲁棒、真实的特征表示信息;然后,输入Softmax 回归分类器进行分类预测;最后,采用留一法在Virus proteins 和Plant proteins 数据集上进行交叉验证。通过将实验结果与多种现有算法进行比较,充分证明了新方法可以有效提高蛋白质亚细胞定位预测的准确性。下一步将继续扩大数据集,在此基础上丰富蛋白质序列表征模型,并对深度学习网络进行优化,进一步提高蛋白质亚细胞定位预测的准确性。
