基于多层特征增强的实时视觉跟踪
2020-11-30费大胜宋慧慧张开华
费大胜,宋慧慧,张开华
(1.江苏省大数据分析技术重点实验室(南京信息工程大学),南京 210044;2.江苏省大气环境与装备技术协同创新中心(南京信息工程大学),南京 210044)
(∗通信作者songhuihui@nuist.edu.cn)
0 引言
目标跟踪一直是计算机视觉中的一个热点问题,在导弹定位、视频监控和无人机侦察等众多领域有着丰富的应用,但是在跟踪过程中仍然存在许多挑战,包括光照变化、角度旋转、比例变化、目标变形、遮挡和摄像机运动等因素,这些问题仍然在不断促进着目标跟踪领域的蓬勃发展。
目标跟踪算法主要分为基于相关滤波的跟踪算法和基于孪生网络的跟踪算法两大类。基于相关滤波的跟踪算法通过循环矩阵将目标函数从频域内转到傅里叶域求解获得滤波器的闭式解,实现许多高速且简易的跟踪器[1-3]。随着卷积神经网络的崛起,基于孪生网络的目标跟踪算法[4-5]充分发挥了卷积神经网络(Convolutional Neural Network,CNN)的作用,将跟踪当作一个匹配任务,把第一帧目标当作模板匹配其他帧,得到目标区域。基于此任务,之后工作也对全卷积孪生网络(Fully-Convolutional Siamese visual tracking network,SiamFC)[5]不断改进。动态孪生网络(Dynamic Siamese network,DSiam)[6]使用一个动态模板和一个快速转变模块更新孪生跟踪模型。高性能的孪生候选区域网络(Siamese with Region Proposal Network,SiamRPN)[7]将目标检测中的候选特征网络Faster RCNN[8]引入到视觉跟踪任务中,解决了SiamFC 多尺度测试消耗计算时间和出框方式过于粗糙的问题。干扰感知孪生网络(Distractor-aware Siamese network,DaSiam)[9]更进一步提出了一种干扰-感知的孪生网络用于更精确的长时跟踪。语义外观双分支孪生网络(Semantic and Appearance Siamese network,SA-Siam)[10]在原有的两分支上多加了两个分支分别为语义分支和外观分支来增加模型的表征能力。
尽管现在的孪生网络跟踪算法在精度和性能上都取得了较大的突破,但是仍有两个问题需要解决:首先,DASiam[4]只是简单地将原始的特征提取网络换成了VGG(Visual Geometry Group)[11]网络,这在一定程度上抽象了目标的表示而忽略了目标的外观纹理特性,当遇到具有相似语义信息的背景时,目标通常会发生漂移;其次,大多数基于孪生网络的目标跟踪算法忽略了高层语义特征对于目标在视频序列中定位的长期依赖性,这限制了目标在遇到相似语义特征干扰时的长期定位能力。
为解决这两个问题,本文提出一种多层特征增强的孪生网络跟踪算法。本文在SiamFC 基础上,通过数据增强技术将浅层特征和高层特征相融合,增强模型鲁棒性。为进一步增强网络模型长时定位能力,提出一种像素感知的全局上下文注意力机制模块(Pixel-aware global Contextual Attention Module,PCAM),最后为验证该算法各模块的有效性,在三个具有挑战性的目标跟踪视频库中做了大量实验,与一些经典跟踪算法进行比较,得到了很有说服力的结果。
1 多层特征增强的跟踪算法
本文提出一种轻量级多层特征增强的跟踪网络(Multilevel Feature Enhanced Siamese network for tracking,MFESiam),如图1 所示。首先本文发现非语义背景和相似干扰物失衡是提升网络性能的主要障碍,所以本文通过一种数据增强策略来增强浅层的特征;此外本文提出一种像素感知的全局上下文注意力机制模块来增强高层模板特征的感知定位能力,最后将提取到的模板特征和搜索特征进行卷积得到下一帧目标位置。
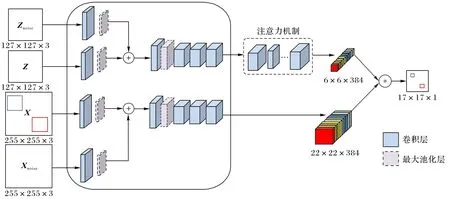
图1 所提算法原理Fig.1 Principle of the proposed algorithm
1.1 基于全卷积孪生网络目标跟踪
近年来目标跟踪孪生网络算法都是基于全卷积孪生网络跟踪算法[5]改进,它是目标跟踪领域的开创性工作。原始孪生网络有两个输入分支:模板分支Z 和搜索分支X,其中Z ∈RW×H×3,X ∈RW×H×3,Z和X分别被裁剪成255×255×3和127×127×3 的图像对输入网络,在搜索图像的初始帧上采取16 个搜索框随机滑动。经过一个全卷积无填充的AlexNet[12]提取图像特征。Z 和X 在共享权重的AlexNet 中最后输出分别为22×22×256和6×6×256,最后经过卷积的相关操作得到一个17×17×1的得分图。得分图中得分最高的一个点即是下一帧预测点的中心位置。SiamFC 设置了三种固定的尺度{0.974 5,1,1.037 5},通过双线性插值从而得到下一帧预测的跟踪框。整个网络通过一个离线训练的匹配函数F(Z,X)获得最终得分图的预测分数,网络的预测函数公式如下:
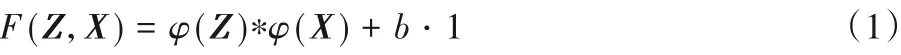
其中:Z 和X 分别为模板和搜索分支输入,φ 为网络特征的嵌入函数,“*”表示相关运算,b为网络的偏置项。整个网络采用二分类的逻辑损失函数,具体表达式(2)如下:

其中:v 表示单个模板-搜索匹配对的真实得分,y ∈{+1,-1}代表这个匹配对的真实标签值,从而计算出一个模板和多个搜索区域匹配的相似性。
1.2 多层特征增强网络框架
本文方法不同于之前的孪生网络只有两支输入分支:模板分支Z 和搜索分支X,如图1 所示,MFESiam 增加了两个输入分支:噪声模板分支Znoise和噪声搜索分支Xnoise。首先,本文的噪声模板分支和噪声搜索分支是通过整个训练数据集在输入若干个模板和搜索匹配对时以5%的概率随机选取一个匹配对;然后,在这个匹配对中随机合成5%的像素值为0 的噪声点和95%的像素值为255的噪声点;最后,将经过数据增强的两个分支:Znoise和Xnoise分别作为孪生网络另外两个并行的输入分支,通过第一个卷积层和第一个最大池化层提取特征后分别与原始模板分支和搜索分支相融合,来模拟一些对目标跟踪具有挑战性的因素。将噪声模板分支和噪声搜索分支在第一个最大池化层之后融合是因为在最大池化层之后,特征图通常会在一定程度上失去一些位置信息,所以在第一个最大池化层之后加入一些合成的椒盐噪声来增强算法的鲁棒性,并且最大池化层由于对局部形变的不变性,所以它对局部的变化是具有鲁棒性的。因此,融合后的浅层特征已经被增强,并且当目标在经历一些复杂场景挑战例如快速运动、遮挡以及相似物干扰等时不会轻易丢失目标。从图2可视化的2D和3D特征中可以看出,在未采用本文数据增强方式下的热力图中会出现因相似语义信息干扰而导致跟踪发生漂移的情况,而在经过了数据增强后的融合特征则在一定程度上抑制了因为相似物体干扰而漂移的情况,使得跟踪器能更为鲁棒地对特定目标进行跟踪。此外,本文还对无填充的全卷积AlexNet网络进行了改进,具体参数如表1,将原始的大尺寸卷积换成了多个小尺寸卷积,并且增加网络层的维度,这样加大网络的深度和维度来学习到更为鲁棒的特征表示。
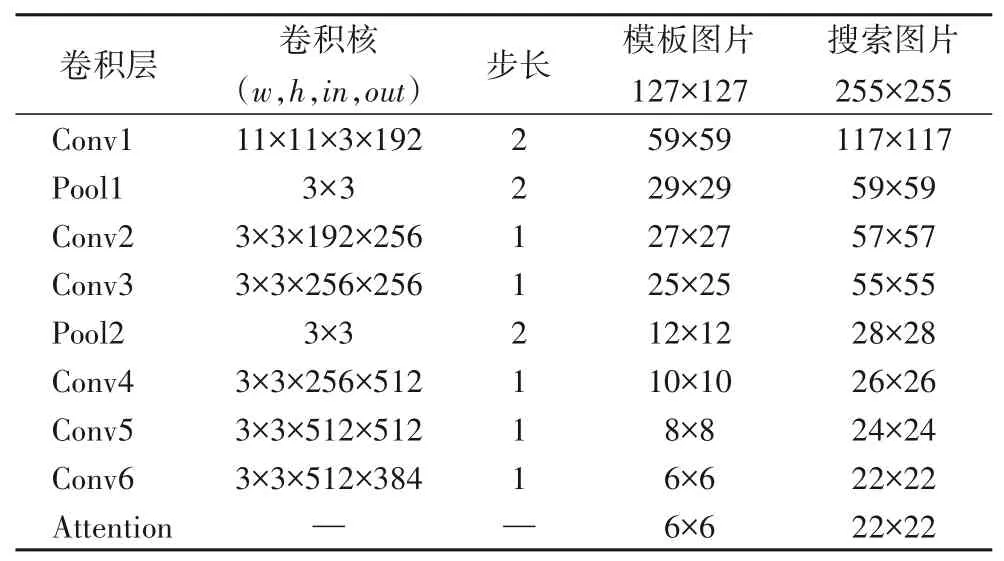
表1 多层特征增强孪生网络参数Tab.1 Multi-level feature enhanced Siamese network parameters
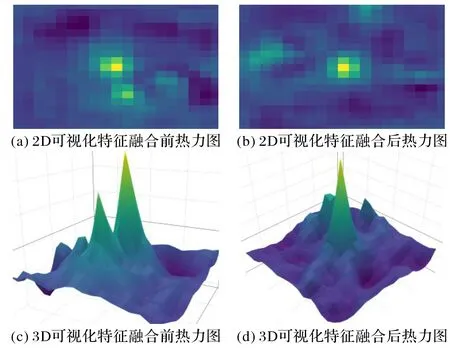
图2 数据增强前后特征可视化图Fig.2 Visualization of features before and after data enhancement
在浅层特征融合的过程中,本文采用了一种新的正则化方式来训练网络,本文在每个训练过程中设置了5%的比率在模板图片(Z)上裁剪出一个30×30的随机掩码,掩码的像素值设置为0。通过这种方式来随机生成一些被遮挡的目标从而提升目标在运动中遭遇遮挡时的鲁棒性,不仅让模型在遇到遮挡的情况下表现得更好,而且使得训练出的模型能更敏感地去考虑环境的变化。
1.3 像素感知的全局上下文注意力机制
鉴于本文提出的MFESiam 对于目标定位是一个典型的匹配模型,模板图片Z 的高层语义特征对模型的目标外观就显得尤为重要。为了进一步捕获目标与背景区域的长时依赖关系,使得跟踪器在经历明显的目标位移下还能有优异的定位能力,本文设计一个PCAM 模块来增强高层语义特征从而加强模板分支的目标定位能力。图3 显示了PCAM 的结构,A ∈RW×H×C作为输入的卷积特征图,H、W 分别代表了特征图的长和宽,C 代表了通道的维数,B 作为输出拥有和A 一样的结构。
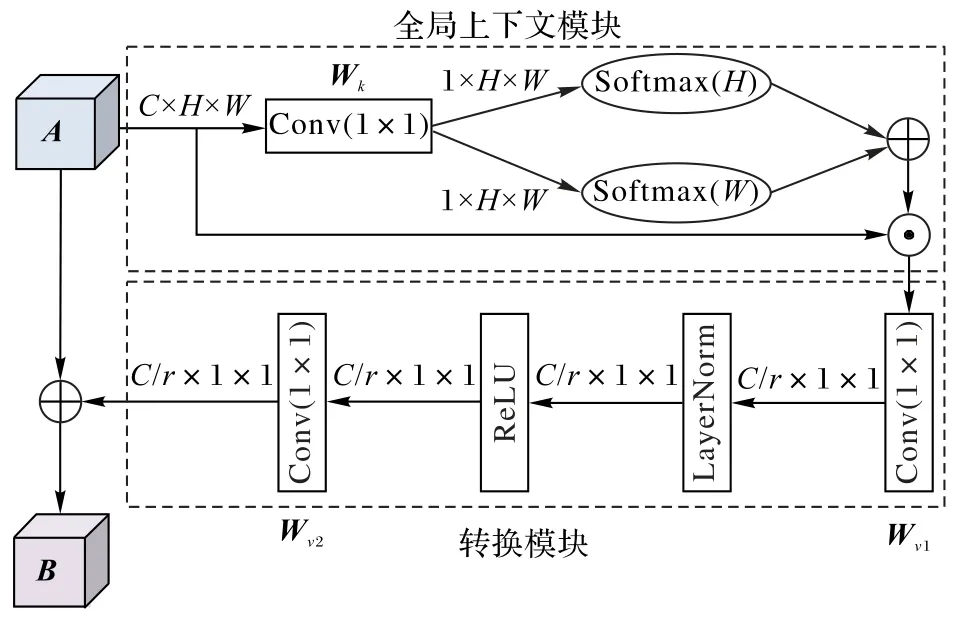
图3 像素感知的全局上下文注意力机制Fig.3 Pixel-aware global contextual attention module
PCAM 由一个全局上下文模块和一个转换模块组成。本文的全局上下文模块是由非局部(Non-local)模块[13]化简而来,不仅极大地降低了原有的计算复杂度,而且可以从全局特征图的时间域和空间域内捕获目标可能存在的位置。首先在模板分支最后一个卷积层Conv6 后增加一个全局上下文模块,将作为整个特征图的输入像素。Np为特征图像素点位置的数目。整个全局上下文模块采用一个1×1卷积Wk将H×W×C 的特征维度转换成一个H×W×1 的特征图,然后在特征图的每个像素点xj上,通过一个行和列双向的Softmax捕获整个全局上下文的像素感知信息。最后,本文使用一个改良的SENet(Squeeze-and-Excitation Network)[14]改变全局特征图的维度到C维并且通过自主学习来获得每个特征通道的重要性。这个转变模块在图中由一个1×1 卷积Wv1、一个归一化层LayerNorm(LN)、一个ReLU(Rectified Linear Unit)激活函数和一个1×1 卷积Wv2构成。对特征通道的相关性进行建模使得激活相应目标对指定通道的响应。设置默认的比率r=8,将转换模块的参数量减少到原始SENet 参数量的1/4,r 指通道的压缩率,C/r 指隐藏特征表示维度。本文在ReLU 激活层之前增加LayerNorm 来减少优化转换模块带来的计算复杂度。是全局上下文池化信息,然后将原始输出X 与带权重的特征矩阵δ(⋅)=Wv2ReLU(LN(Wv1(⋅)))相加构成一个残差网络来提高目标特征的感知能力。像素感知的全局上下文注意力(PCAM)模块的具体细节可以用如式(3)表示:

本文的PCAM 由以下三部分组成:1)全局上下文池化为上下文本建模;2)转换模块捕获通道相关性;3)用于特征融合的广播机制相加。
1.4 网络训练细节
本文随机从GOT-10K[15]和VID2015[16]数据集里提取模板和搜索图片离线训练网络结构,采用随机梯度下降(Stochastic Gradient Descent,SGD)算法随机初始化目标函数,采用二分类交叉熵损失对整个网络进行训练,训练50 个周期。学习率从10-2几何式衰减到10-5。从图4 中可以看出整个训练过程损失是最终收敛的,但是最优值不一定是在最后一个周期内,从而证明本文算法的稳定性。本文的算法是通过PyTorch1.0.1 来实现,硬件由一台配置为英特尔i7-8700k CPU 和一块GTX2080 Ti 显卡支持加速。采用基准SiamFC 的方式,用三种固定的尺度{0.974 5,1,1.037 5}来估计目标尺度。此外,尺度的变化通过线性插值的方式来更新,如式(4)所示,更新因子(scale_lr)设为0.59。x0为中间尺度1,x1为惩罚后的尺度,从而通过线性插值的方式更新尺度信息。
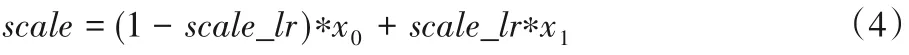
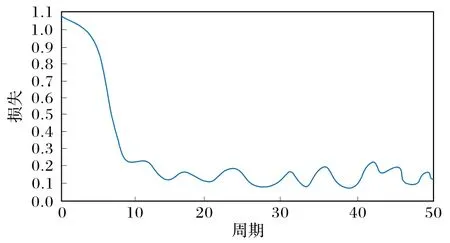
图4 网络训练损失曲线Fig.4 Network training loss curve
2 实验结果分析
为验证本文算法有效性,在三个本领域公认非常具有挑战性的目标跟踪视频库OTB2015[17]、VOT2018[18]和GOT-10K[15]上进行实验,并与多个经典算法进行比较,大量实验显示了本文算法具有比较有竞争力的表现。
2.1 在OTB2015上的评估
OTB2015[17]是目标跟踪领域用于评价算法优异程度的视频跟踪库,它由100 个人工标注的跟踪视频组成。不同的数据集具有不同属性,这些属性可代表当前目标跟踪领域的常见难点,例如光照变化、尺度变化、遮挡和形变等。OTB2015主要使用两个标准评价指标:精确率和成功率。精确率表示为预测目标位置的中心点到真实位置的中心点距离小于给定阈值的视频帧数所占总帧数的百分比。成功率则表示跟踪框与标注框的重叠率得分,即为超过某个阈值的帧个数占视频总帧数的百分比。首先定义重叠率得分(Overlap Score,OS),跟踪算法得到的定位框(记为a)与真实标签给出的框(记为b),重叠率定义如式(5)所示:

其中|a ∩b|表示定位框和真实标签给出的框相交共有区域的像素数目。当某一帧OS大于设定阈值时,则该帧被视为成功,总体成功的帧占所有帧的百分比即为成功率。跟踪算法估计的目标位置中心与目标实际标签的中心点,这两者的距离小于给定阈值视频帧的百分比即为精确率。首先我们在OTB2015 上可视化了目标运动轨迹,如图5,本文利用视频帧中每帧目标框上下左右的坐标点计算出中心坐标(图中圆点)可视化显示每帧运动目标轨迹。

图5 目标运动轨迹Fig.5 Target trajectory
这里将本文算法与六种经典算法进行比较:候选区域孪生跟踪器(Siamese Region Proposal Network,SiamRPN)[7]、空间正则判别相关滤波器(Spatially Regularized Discriminative Correlation Filter,SRDCF)[19]、核化相关滤波器(Kernelized Correlation Filter,KCF)[1]、全卷积孪生网络(Fully-Convolutional Siamese network,SiamFC)[5]、判别尺度空间跟踪器(Discriminative Scale Space Tracker,DSST)[20]和表征学习相关滤波跟踪器(Representation Learning for Correlation Filter,CFNet)[21]。表2显示本文MFESiam 在精确率和成功率上都取得最好效果,成功率达到64.5%的得分,精确率达到85.5%,分别优于2018 年VOT 冠军SiamRPN 0.8 个百分点和0.4 个百分点,且本文的MFESiam 算法在成功率和精确率上分别在基线SiamFC 上提升了6.3 个百分点和8.4 个百分点。优异的结果证明本文所提算法在跟踪中面对一些具有挑战性的因素如快速运动、目标遮挡、相似物干扰等困难情况下是鲁棒的。
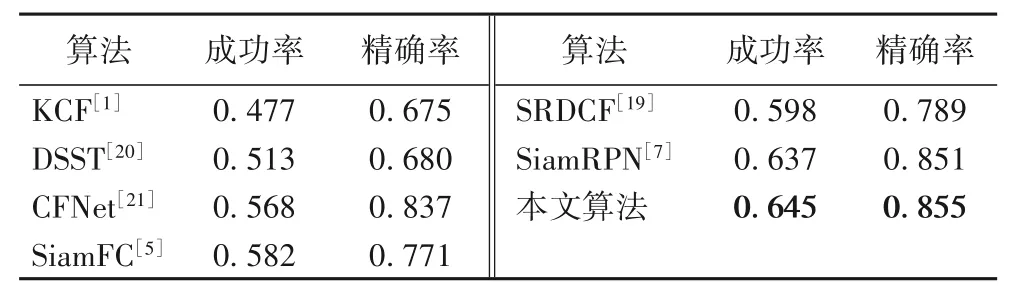
表2 OTB2015上算法成功率和精确率的对比Tab.2 Comparison of algorithms on success rate and accuracy on OTB2015
图6 是本文算法MFESiam 与基线SiamFC 算法在OTB2015上可视化对比。从三个比较有代表性的视频序列中可看出本文算法在快速运动、目标遮挡和相似语义干扰情况下,目标都有优异的跟踪表现。从视频序列(a)可看出,在模板分支的高层特征后添加PCAM 模块提高了目标的长时感知定位能力,在同样的情况下本文基线SiamFC 在第337 帧之后已经丢失了目标,而添加了PCAM 模块后让目标在经历快速运动时也能精确跟踪。而从序列(b)中可以看出采用了随机裁剪的新型正则化训练方式,跟踪器能自发地去思考环境的变化,从而在遭遇遮挡的情况下也能不丢失目标。从序列(c)中可以看出通过数据增强的技术来加强浅层目标的纹理特性,使得跟踪器在遇到相似语义信息背景干扰时目标不会轻易发生漂移。

图6 OTB2015上各算法可视化对比Fig.6 Visualization comparison of different algorithms on OTB2015
对于模板分支的高层特征,本文采用一个像素感知的全局上下文注意力机制模块来提升目标的感知力。像素点特征对目标的遮挡和快速运动都具有比较强的鲁棒性,并且每帧图像的搜索区域不受目标初始模板大小的限制。从图7 仿真实验可看出,本文通过全局上下文模块捕捉全图像素特征,通过转换模块激活对应于特定目标的响应通道,可筛选出较为理想的目标像素点,最后根据强分类器对前景背景像素点进行分类,输出目标位置。

图7 目标像素点实验仿真图Fig.7 Experimental simulation of target pixels
2.2 在VOT2018上的评估
VOT2018 一共有60 个经过精细标注的短时跟踪视频集,且评价指标更为精细。VOT2018 与OTB2015 的最大差异是OTB2015 由随机帧开始,而VOT2018 是给定第一帧初始化,每次跟踪失败时,5 帧之后重新初始化。VOT2018 在跟踪序列上目标的变化更为复杂,跟踪难度更高。VOT 的评价指标主要是期望平均重叠率(Expected Average Overlap,EAO),由精度(Accuracy,A)和鲁棒性(Robustness,R)组成。如图8 所示,在VOT2018 数据库中本文的算法与其他八个算法在基线上进行比较,其EAO 指标排名第一达到了0.256,超越本文基线SiamFC 6.8 个百分点,表明本文所提算法在跟踪难度较大的小目标上也有非常良好的竞争力。

图8 VOT2018上的期望平均重叠率排名Fig.8 Expected average overlapping rate ranking on VOT2018
2.3 在GOT-10K上的评估
GOT-10K 包含训练集和测试集两部分,而且为了训练出的模型能有更强的泛化能力,训练集和测试集之间不存在交集。它包含了1 000 个目标跟踪视频,包含150 万个手工标注的边界框。GOT-10K挑战集有两个内部的评价指标,包括:在所有帧中跟踪结果和真实标签平均重合率(Average Overlap,AO)和在一个给定阈值下成功跟踪的视频帧所占的比率(Success Rate,SR)。数据集大部分是户外拍摄的物体,包含许多尺度变化剧烈的跟踪目标。从表3 可以看出本文的算法在AO 的指标下超越了基线SiamFC 4.1 个百分点,在SR0.50上超越基线SiamFC 4.7 个百分点,这也证明本文算法在大尺度变化跟踪序列上有着优异的定位与跟踪能力。
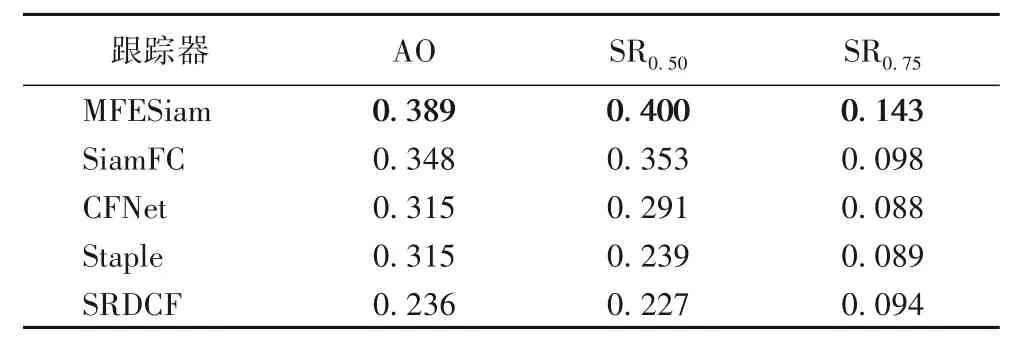
表3 GOT-10K挑战的指标排名Tab.3 Indicator ranking on GOT-10K
2.4 消融实验
本文也在OTB2015 上进行消融实验来验证本算法各个模块的有效性,如表4所示。
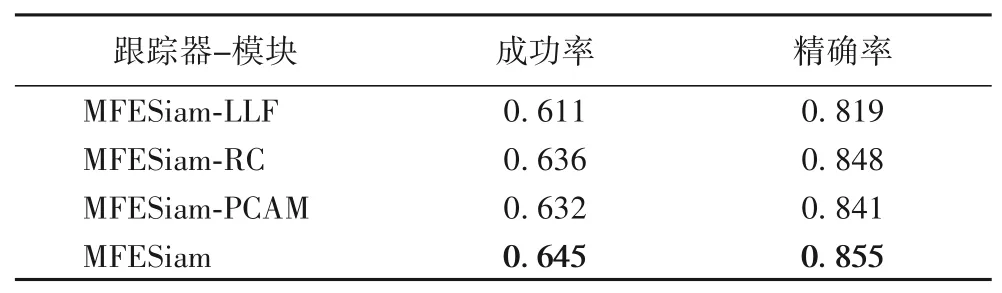
表4 OTB2015上的消融实验Tab.4 Ablation experiment on OTB2015
首先,本算法在移除了PCAM 后成功率下降了1.3 个百分点,这证明PCAM 模块可以提升模板分支高层语义特征的感知定位,从而加强对于目标的长时定位能力;然后,从本算法中移除随机裁剪(Random Cutout,RC)的训练方式,算法成功率下降了0.9 个百分点,由此可见采用这种新型正则化的训练方式来模拟目标在遭遇遮挡的情形,可以让模型能够更自发地去思考目标周围所发生的变化,以达到更好的跟踪效果;最后,本文移除了浅层特征融合模块(Low Level Fusion,LLF),算法成功率下降了3.4个百分点,性能大幅度地降低证明了浅层特征融合模块对于加强浅层的纹理特征,从而提高目标在跟踪相似语义信息干扰是有效的。相较于原始基线SiamFC 成功率为58.2%,MFESiam 取得了最好的成功率为64.5%,这也充分证明本算法各模块的有效性。
3 结语
本文提出一个实时跟踪方法,通过设计一个有效的浅层特征增强模块和一个用于模板分支高层语义特征增强的PCAM 模块。浅层特征增强模块使用一个简易且高效的数据增强策略来加强网络的鲁棒性;而PCAM 模块则是一个双向像素感知的全局上下文注意力模块,旨在于提升高层语义特征的感知定位能力。整个网络通过离线训练,在测试时不需要花费时间用于模型的在线更新。在OTB2015、VOT2018 和GOT-10K上充足的实验表明本文所提算法在精度和速度上所取得了优越性能,并且其实时性能以满足实际的工业需求。但是本文方法在目标旋转角度过大、光照变化明显等因素出现时,跟踪结果仍不理想,接下来将对目标旋转角度过大和光照变化明显等情况进行下一步的研究。
