基于增强型对抗学习的无参考图像质量评价算法
2020-11-30曹玉东蔡希彪
曹玉东,蔡希彪
(辽宁工业大学电子与信息工程学院,辽宁锦州 121001)
(∗通信作者电子邮箱lgcaixb@163.com)
0 引言
图像质量评价(Image Quality Assessment,IQA)是图像处理与图像理解中的一个热点问题,在图像编码以及视频监控中都有重要的应用,因此,建立一个有效的图像质量评价模型至关重要。依据利用参考图信息的情况,图像评价模型通常分为全参考(Full-reference)、半参考(Semi-reference)和无参考(No-reference)三种类型[1]。全参考图像质量评价(Full-Reference Image Quality Assessment,FR-IQA)方法需要参考未失真原图像的信息来评估图像的质量分数;无参考图像质量评价(No-Reference Image Quality Assessment,NR-IQA)方法不利用任何参考信息,又称为盲图像质量评价(Blind Image Quality Assessment,B-IQA)方法;半参考图像质量评价是部分利用参考图的信息。综上,FR-IQA 方法最大的优势在于可以基于失真图像和参考图像之间的不同来量化视觉敏感性,这能有效模拟人类视觉系统(Human Visual System,HVS)。由于NR-IQA 方法缺乏参考信息,只能从图像的统计特性和特征学习出发,尽力提取符合HVS 系统特性的特征,而HVS 的特性又很复杂,使得NR-IQA 的性能很难与FR-IQA相媲美。
NR-IQA方法直接评价待测图像的质量,是符合实际需求的[1],但是效果不如FR-IQA 方法好。文献[2]分别提取参考图像和失真图像的相位一致性、梯度、视觉显著性和对比度特征,采用机器学习的方法自动预测图像质量分数。文献[3]提出一种专属任务类型的人脸图像质量评价模型,最终目的是想解决由于人脸图像质量差带来的低识别率问题。文献[4]提出了一种针对非对称失真的立体图像质量评价算法,利用自适应的支持向量回归模型将感知特征向量映射成质量评价分数。2014 年Goodfellow 等[5]提出生成对抗网络(Generative Adversarial Network,GAN),采用对抗思想和深度学习技术生成样本数据,此后GAN 模型在学术界和工业界得到高度重视并不断演进,在迁移学习、对抗样本、表示学习、超分辨率和数据增强等方面表现出色,被广泛应用于计算机视觉、人机交互、自然语言处理等领域。但是现有的GAN模型[6-8]不能完全获取到模糊图像丢失的细节和纹理信息,所以生成高质量的新样本图像仍旧是一件比较困难的事情[9]。文献[10]做了比较成功的尝试。
由于FR-IQA方法能利用未失真的参考图,大多数的研究工作围绕失真图像和未失真图像的差异展开。例如,经典的结构相似索引测度算法(Structural SIMilarity index,SSIM)[11]把HVS 敏感性融入结构信息中,从亮度、对比度和结构三方面计算2 张图片的结构相似性,模拟人类视觉过程,判断图像的失真程度。此后,很多学者又在此基础上进行改进[12-14]。
NR-IQA由于缺乏可参考的图像,只能从失真图像本身出发,提取图像的统计特征。文献[15]根据失真图像丢失的信息,在空间域中不同的子集上计算区域互信息,进而来预测质量分数;文献[16]将RGB 图像转换到YCbCr 颜色空间,提取关键点特征,用于图像质量评价;文献[17]基于结构、自然属性和感知特性提取具有统计性的度量值,结合无监督学习方法实现图像质量评价;文献[18]用局部质量图的梯度方差来预测整体图像的质量;文献[19]在4 个不同的尺度上计算DLM 特征,然后通过SVR 预测质量分数;文献[20]认为在小波域上图像的失真会影响小波变换的子带系数,因此用广义高斯分布和daubechies 小波基变换的系数来描述失真特性;Kim 等[21]使用4 种传统的FR-IQA 算法得到图像块的质量分数,以此作为基准进行有监督学习。
NR-IQA 方法通常都假设失真会改变自然图像的某种特性,但仅依靠手工特征很难提取到完整准确的特征,不便于模拟HVS 系统。近几年,随着以深度卷积神经网络为代表的深度学习技术的进步,自动特征学习逐渐代替了手工特征提取,出现了一些基于深度学习IQA 的算法。例如,文献[22]将图像分割为图像块,结合不同块的权重,通过卷积层提取失真图像和未失真原图像的特征以及它们特征的差异,基于深度学习模型预测质量分数;Hou 等[23]提出了一个基于深度学习的B-IQA 评价模型,通过回归网络将失真的程度分为5 个等级,预测图像的质量分数。
由于缺乏参考图像,NR-IQA很难将失真的程度量化为一个具体的分数,导致最终的评判不够准确。本文提出一种基于增强型学习的无参考图像质量评价方法(Enhanced Adversarial Learning based Image Quality Assessment,EALIQA),通过改进GAN 模型,加强对抗学习,生成更可靠的模拟仿真图充当“参考图”。
1 基于增强对抗学习的无参考图像评价
IQA 算法就是用一种客观的和计算机可执行的方法预测图像质量的分数。由于现实应用中很难获得对应的原始图像,因此无参考图像评价算法最具应用价值。GAN 是一种新兴的深度生成模型(deep generative model),需要同时训练两种模型:生成模型G 和判别模型D,由生成模型和判别模型的相互博弈产生输出。在训练G 的过程中,以随机噪声作为输入生成难以区分的样本试图欺骗判别模型D,最大限度地提高D 犯错的可能性[5]。也就是在定义了生成模型G 和判别模型D 的情况下,通过对抗学习完成训练。训练GAN 模型是比较困难的,除了对算力要求较高外,经常面临梯度消失的困扰,采用ReLU(Rectified Linear Unit)激活函数可以缓解这一问题。
提出的EAL-IQA 主要包括3 个步骤:1)首先利用失真的图像和未失真的原图像作为输入,通过增强对抗学习训练GAN 模型;2)利用失真图及其标签和已经训练好的GAN(输出模拟仿真图像),训练图像评价系统中的图像特征提取模型和回归网络模型;3)在测试阶段,将待测图像输入NR-IQA 网络系统,输出质量评价分数。步骤1)和步骤2)为训练过程,步骤3 为测试过程。综上,改进的GAN 结构通过增强型对抗学习,能获取更可靠的仿真图。
无参考图像质量评价可以被看作回归问题,提取图像特征,输入回归模型,然后输出图像质量评价分数。如果无参考图像质量评价算法没有参考图,则无法模拟人的视觉比较过程。提出的无参考EAL-IQA 算法利用由深度卷积神经网构建的GAN 模拟生成了仿真“参考图”,使得评价过程类似FRIQA,能模拟人的视觉比较过程。HVS 是复杂的非线性系统,深度神经网络有类似特性。
为了进一步提升NR-IQA 方法的性能,设计了双输出的生成对抗网络模型,通过加强对抗学习训练,生成更可靠的仿真图,提高图像质量评价系统的性能。
1.1 生成模型
改进后的G网络模型架构如图1所示。使用GAN 模型的目的是通过对抗学习生成可靠的新样本图像(模拟仿真图)Ir',弥补图像评价系统没有参考图的缺陷。生成器模型G 的结构以文献[24]中卷积神经网络结构为基础,仅仅依靠生成的仿真图Ir'训练GAN 模型,效果并不理想,然后在其末端增加1个2层的卷积神经网络,将仅能输出仿真图Ir'的单输出网络改进为还能输出显著图Is'的双输出网络,根据文献[11]提出的SSIM 算法,通过学习失真图Id和对应的未失真原图Ir之间的结构相似性,输出结构相似图(简称为SSIM 图)Is,SSIM图能够描述图像的失真特性。生成网络学习模拟仿真图Ir'和失真图Id之间的相似性,输出显著图Is'。在GAN 中,无论是输出的仿真图Ir'还是显著图Is',都描述由失真带来的变形,不同之处在于仿真图学习如何还原图像的细节、边缘和纹理等信息,显著图学习失真图像Id与模拟仿真图Ir'之间的差别。SSIM 算法在设计时充分考虑了HVS的特性,在对抗学习中引入SSIM 的另一个目的就是希望提出的无参考评价方法能更好地模拟人的视觉比较过程。
1.2 判别网络模型
改进的双输出生成器模型G同时生成模拟仿真图Ir'和显著图Is',根据生成对抗网络的博弈思想,需要判别模型D分辨2组图像:未失真的原图像和仿真图像、显著图和SSIM图。如果只设计1 个判别器同时分辨2 组图像,效果会很差,进而影响生成器G 的性能。如图1 所示,采用2 个卷积神经网络(CNN)架构的判别器模型D1和D2完成此任务,即判别模型D1用于区分未失真原图Ir和仿真图Ir',判别模型D2用于区分显著图Is'和结构相似映射图Is。通过增强对抗训练后,训练好的生成器模型G 能生成更逼真的仿真图。如果D1和D2分辨结果经常出错,说明生成器生成仿真图和原图极其相似,对抗学习取得成功。改进后的GAN 可以输出令人满意的模拟仿真图,充当NR-IQA算法中的参考图。

图1 改进的GAN模型结构Fig.1 Structure of improved GAN model
1.3 损失函数
给定一系列的失真图像Id以及随机噪声矢量v,由生成模型G得到对应的新样本图像(即为模拟仿真图)Ir',原图Ir和模拟仿真图Ir'之间的距离度量损失函数为:

式中:G 为生成器函数,其输入为失真图像Id、参考图像Ir和随机噪声v,度量距离时使用l1范数生成的图像更清晰,比使用l2范数的效果好[25]。对抗损失函数为:

将距离损失函数和对抗损失函数合并,生成器模型期望合并后的损失函数值最小化,判别器模型期望合并后的损失最大化,即:
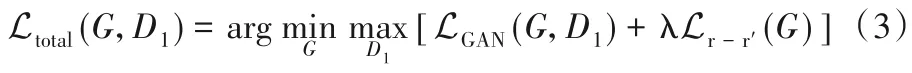
式中:λ 为学习系数,判别器函数D1学习分辨参考图像Ir和模拟参考图像Ir',最小化Ltotal(G,D1)能够增加判别模型的识别难度。输入失真图像Id和对应的参考图Ir,得到SSIM 映射图Is,生成器模型输出显著图Is',距离度量损失函数为:
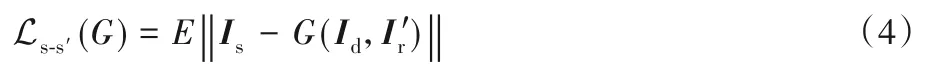
对抗损失函数为:
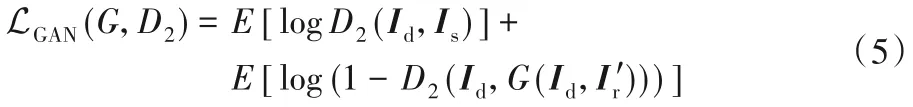
类似的,将距离损失函数和对抗损失函数合并,则有:

综上,最终的损失函数为:
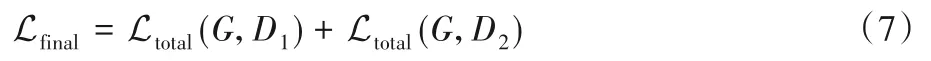
借鉴文献[5]的方法,对生成模型G 和判别模型D1+D2轮流应用梯度下降法,即采用minibatch SGD 和Adam 算子优化模型参数[25]。
1.4 IQA回归网络模型
基于深度学习技术建IQA 网络,旨在模拟人类视觉过程,给出更可靠的图像的评测分数。IQA 主要由特征提取模型、特征融合以及回归网络三个部分组成,图2 给出了IQA 网络模型的测试流程。其中2 个特征提取模型的结构是一致的,以VGG 卷积网络为原型,卷积神经网络结构主要包含卷积层和池化层,其主要特点是非全连接和共享权值,在卷积和池化的过程中包含了对图像样本进行特征提取的过程。回归网络是由2 个卷积层构成的全连接结构,通过训练优化模型参数。由1.1节和1.2节,已经训练好的生成网络G也作为回归网络模型的一部分。将失真图像、失真图像的真实质量分数作为标签,作为特征提取模型和回归网络的训练数据。
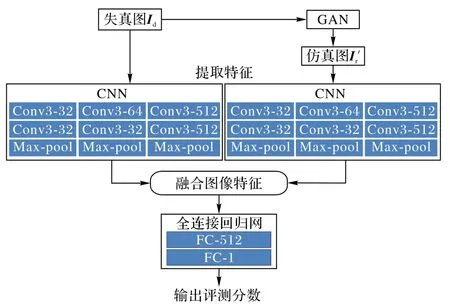
图2 IQA回归网络测试流程Fig.2 Test flowchart of IQA regression network
假设失真图像提取的特征矢量为f1,仿真图的特征矢量为f2,则输出的融合图像特征矢量为{ f1,f2,f1-f2}。测试时,输入待测图像以后,质量回归网络会输出预测分数。总结提出的EAL-IQA算法,描述如下:
输入 失真图Id;
输出 失真图Id的评价分数。
训练阶段:
1)利用训练集中的失真图Id和对应的未失真原图Ir生成SSIM映射图,用于对抗学习。
2)向GAN 模型输入失真图Id,通过对抗学习生成仿真图Ir'和显著图Is'。
3)利用已经训练好的生成网络G,输入失真图Id,训练IQA的图像特征提取模型和回归网络模型。
测试阶段:
1)输入待测失真图Id;
2)提取待测失真图Id,输出仿真图Ir'的融合特征,送入IQA回归网络,输出图像质量评价分数。
2 实验
2.1 数据集
实验使用的数据集为LIVE[26]、TID2008[27]和TID2013[28]。LIVE 数据集总计有25 幅参考图像,982 幅失真图像包含白噪声、高斯模糊、瑞利衰减、JPEG2000、JPEG 等5种失真类型,图像质量用范围为[0,100]的平均主观得分差异(Differential Mean Opinion Score,DMOS)值表示,161 人参加主观实验评分。数据集TID2018按照失真类型分为17类,总计1 700幅图像,838 人参加主观实验评分。数据集TID2013 总计3 000 幅图像,包括25 幅参考图像和24 种失真类型,源自不同的加性高斯噪声、稀疏采样重构等,给出了峰值信噪比、结构相似度等信息,931 人参加主观实验评分。TID2008 和TID2013 的图像质量用范围为[0,9]的主观得分差异(Mean Opinion Score,MOS)值表示。图像文件的命名方式为“参考图像号_失真类型_失真水平.bmp”。图3为采自该数据库的样本图像。

图3 数据集TID2013的样例Fig.3 Samples of TID2013 dataset
2.2 评价测度
评价测度采用均方根误差(Root Mean Squared Error,RMSE)、斯皮尔曼秩相关系数(Spearman Rank Order Coefficient,SROCC)和皮尔森线性相关系数(Pearson Linear Correlation Coefficient,PLCC)[29]。RMSE 预测相关的一致性,RMSE 的值越小说明算法的预测分数与人的主观评价分数越接近;SROCC 指标度量评测算法的单调性,计算结果越接近1,表明与主观评测结果越接近;LCC 指标使用相对距离度量预测值与主观评分在非线性回归后的线性相关性,计算结果越接近0,表明相关性越弱。3 个评价测度都用于衡量算法性能与人类视觉评测结果的符合程度。SROCC的计算公式为:
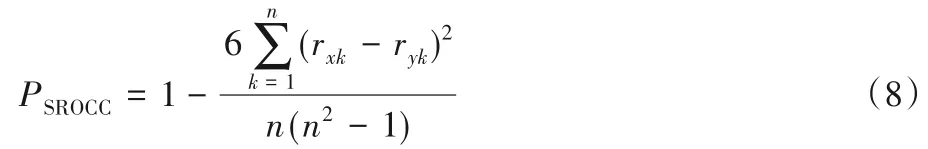
式中:n表示数据对的数量,rxi和ryi分别表示xi和yi在各自数据样本的排名。PLCC的计算公式为:
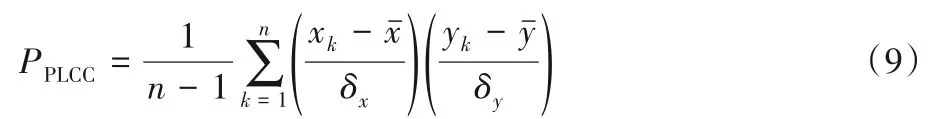
将提出的无参考EAL-IQA算法和文献[30]列出的具有代表性的FR-IQA方法在LIVE数据集上做性能比较,实验结果如表1 所示。可以看出:提出的EAL-IQA 算法在LIVE 数据库上表现出与主观评价很好的一致性,RMSE性能已经远远超过列出的其他全参考比较算法,SROCC和PLCC性能指标已经超过大部分全参考算法,诸如RFSIM(Riesz transforms based Feature SIMilarity index)[31]、NQM(Noise Quality Measure index)[32]、IFC(Information Fidelity Criterion index)[33]、UQI(Universal Quality Index)[34]。提出的EAL-IQA 的SROCC 值略低于MSSSIM(Multi-Scale Structural SIMilarity)全参考算法[35],与FSIM(Feature Similarity Index Method)[13]、VIF(Visual Information Fidelity index)[36]方法接近。与无参考算法相比,全参考算法的质量预测结果更符合人的感知特性[31],本文的目标之一是希望借助对抗学习生成模拟的参考图像,从而像全参考算法那样,在功能上实现“模拟”人的视觉主观评价过程,这也是将提出的无参考算法和全参考算法做性能比较的原因。
将提出的无参考EAL-IQA 算法和文献[1]列出的具有代表性的同类无参考IQA 方法在LIVE 数据集上进行性能比较。由表2 可以看出,提出的算法的性能已经超过同类算法。SROCC 性能比MVG(MultiVariate Gaussian model)算法[17]提高6个百分点,比BIQI(Blind Image Quality Index)[20]高10个百分点,比 ILNIQE(Integrated Local Natural Image Quality Evaluator)[37]提高7个百分点,比BRISQUE(dubbed Blind/Referenceless Image Spatial QUality Evaluator)[38]提高2 个百分点,比CNN(Convolutiona Neural Networks)[39]和HOSA(High Order Satistics Aggregation)算法[40]提高1 个百分点。PLCC 性能比CORNIA(COdebook Representation for No reference Image Assessment)[1]提高1个百分点。总结表1和表2,在LIVE 数据集上,本文算法虽有优势,但是并不明显,分析原因可能是LIVE数据库较小,容易导致本文算法产生过拟合,造成测试性能偏低,如果采用数据增强的办法,会失去比较的公平性,考虑在更大的数据库TID2008和TID2013进行实验,后续的实验也验证了上述分析的正确性。
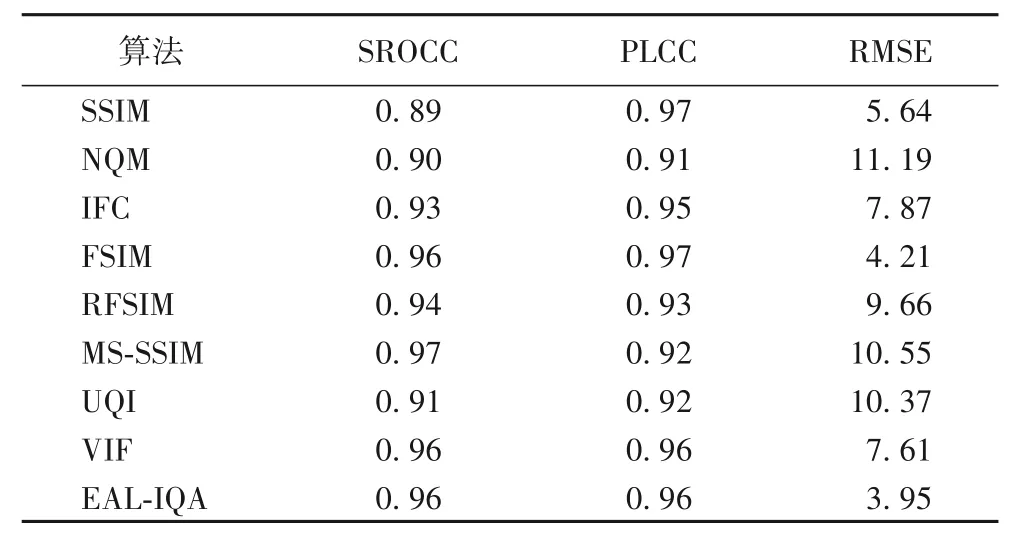
表1 在LIVE数据集上与全参考算法的性能比较Tab.1 Comparison between EAL-IQA and full-reference algorithms on LIVE dataset
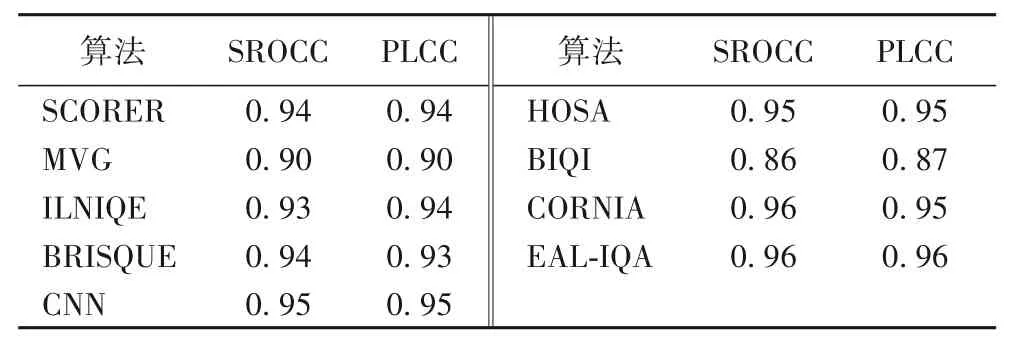
表2 在LIVE数据集上EAL-IQA与无参考算法的性能比较Tab.2 Comparison between EAL-IQA and no-reference algorithms on LIVE dataset
将提出的算法与文献[10]和文献[41]列出的具有代表性的算法在TID2008 数据库上继续做对比实验,结果如表3 所示。在该数据集上,提出算法的性能明显优于传统的SSIM[11]、FSIM[13]、IW-SSIM(Information content Weighted SSIM index)[14]、VIF 算法[36]、VSI(Visual Saliency-induced Index)[41],略微优于H-IQA(Hallucinated-Image Quality Assessment)算法[10]、CNN[39]和SOM(Semantic Obviousness Metric)[42]。3 个算法中,SOM算法采用了关联图像感知评测的语义级特征,CNN算法采用了卷积神经网络技术,H-IQA 算法使用了GAN 和深度卷积神经网络。
深度学习技术的特征之一是需要大数据支撑才能取得较好的效果,然后在更大的数据库TID2013上继续做实验,实验结果参见表4。此次增加3 个具有代表性的基于深度学习的算 法,其 中VI(Vgg and Inception net)[43]是使用 了VGG 和Inception 融合深度神经网和感知视觉特性的图像质量评价算法、DIQaM-NR(Deep Image Quality assessment Metric-No Refenence)被称为无参考的加权平均深度图像质量评价算法和 WaDIQaM-NR (Weighted-average Deep Image Quality assessment Metric-No Refenence)算法[22]被称为无参考的深度图像质量评价算法。DIQaM-NR 和WaDIQaM-NR 算法都用了深度卷积神经网络,共计10 个卷积层、5 个池化层,也使用ReLU作激活函数,被作者统称为DeepIQA。
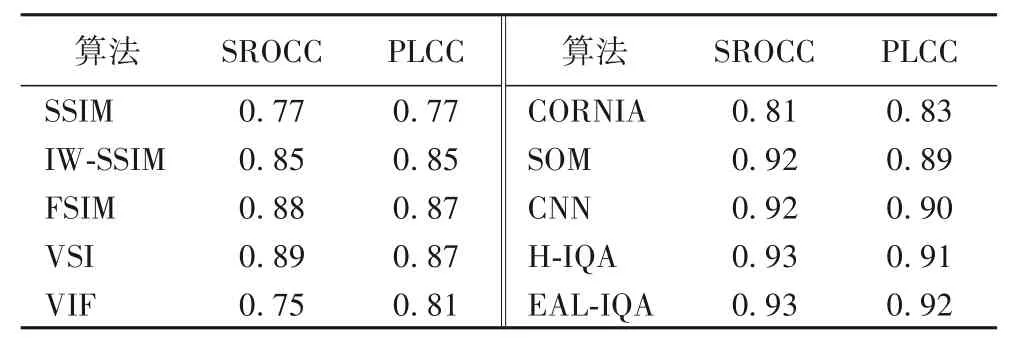
表3 在TID2008数据集上几种算法的性能比较Tab.3 Performance comparison of several algorithms on TID2008 dataset

表4 在TID2013数据集上几种算法的性能比较Tab.4 Performance comparison of several algorithms on TID2013 dataset
由表4 可以看出:在较大的数据库TID2013 上,5 个基于深度学习技术的评价算法的性能优于传统算法,在5 个基于深度学习的算法中,提出的EAL-IQA 算法又最具优势。一般来说,在大型数据库上,采用了深度学习技术的图像质量评价方法的性能要好于传统算法,可能是目前的数据量还不能满足DIQaM-NR 和WaDIQaM-NR 算法中使用的深度神经网络,导致其性能偏弱一些。
目前,深度学习技术是人工智能领域的主流技术,基于深度神经网络模型的生成对抗网络被认为是最具前景的算法之一。在TID2013数据集的24种失真类型[28]上,对VI、H-IQA和EAL-IQA 三种使用了深度学习技术的算法做了逐一比较,其中H-IQA 和EAL-IQA 均使用了生成对抗网络技术,图4 给出了三种算法的比较结果。
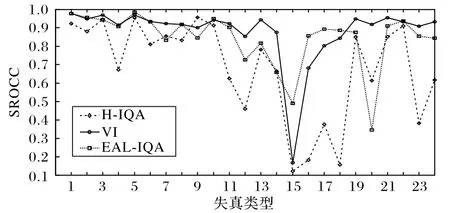
图4 三种算法在TID2013不同失真类型上的比较Fig.4 Comparison of three algorithms on different distortion types of TID2013 dataset
从图中可以看出,在第1、2、4、5、6、8、11、12、15、16、17、18、21、23和24种失真类型上,提出的EAL-IQA算法明显优于H-IQA 算法;在第3、7、9 和20 种失真类型上提出的算法劣于H-IQA 算法。同VI 算法相比,提出算法在第15、16、17、18 种失真类型上占有优势,在第3、7、9、11、12、13、14、19、20、21、23和24种失真类型上逊于VI方法。EAL-IQA、H-IQA和VI的SROCC 性能值分别为0.89、0.87 和0.81,提出的EAL-IQA 算法在总体性能上占据优势。总结已有的文献报道和实验结果,目前还没有哪一种图像质量评价算法能在所有的失真类型上都优于其他算法,因此设计通用型、高性能的图像质量评价算法将是以后相关研究工作的目标。
3 结语
为了提升无参考图质量评价方法的性能,本文采用目前流行的深度学习技术设计了双输出生成对抗网络模型,训练期间,利用未失真原图模拟生成可靠的仿真图和显著图;判别模型则负责分辨仿真图和未失真原图、显著图和SSIM 图。通过增强型学习获取可靠的模拟仿真图,弥补NR-IQA在测试中没有参考图的缺陷。由于图像失真类型丰富,每种类型的特性千差万别,如何提高IQA模型的通用性是今后的研究重点。
致谢 感谢马遥同学在论文初期阶段所做的研究工作。
