建筑类网站聚焦爬虫策略研究
2020-11-23林汨圣王扬
林汨圣 王扬

摘 要:在工作和研究中持续更新大量的资料和数据是建筑师的职业基础。传统人工搜索互联网的方式工作量大且挖掘率低,对网站数据源的利用往往不够充分。国内大部分建筑类网站采用HTML文本标记数据,对HTML采用网络聚焦爬虫有助于建筑师高效定位并规范化储存专业数据。通过对建筑类主流网站结构特征进行分析,总结建筑学3种专业爬虫需求。基于Python的语言特征,提出公开数据类和建筑档案类2种爬虫策略。实测结果表明爬虫策略具有数据采集实时性好、易管理维护的优点,同时均运行高效且稳定,可为建筑专业大数据分析提供更多高质量的数据源。
关键词:聚焦爬虫;网络爬虫;HTML;Python;建筑学
中图分类号:TU17 文献标志码:A 文章编号:2095-2945(2020)33-0001-06
Abstract: It is a professional basis for architects to keep updating a large number of data and statistics in work and research. Due to the heavy workload and low work rate of the traditional artificial Internet search mode, the utilization of website resource is often insufficient. Most of Chinese architectural websites use Hyper Text Markup Language. Through focus crawler of HTML, it is efficient for architects to locate and store data in a standard way. Based on the analysis of common websites of architecture, three kinds of professional crawler requirements of architects are summarized. Based on the features of Python, two crawler strategies, namely numeral data strategy and building archives strategy, are proposed. Results show that these strategies are highly effective, stable, and have advantages of good real-time data collection, easy management and maintenance, which can provide more high-quality data sources for architectural big data analysis.
Keywords: focused crawler; web crawler; HTML; Python; architecture
建筑师是与时俱进的职业,保持对专业资讯的敏感度是一种基础素养。随着互联网的普及,世界各地的建筑资料均可在互联网自由共享。对大部分建筑师而言,面临的不再是缺乏资料的问题,而是高效地从海量资料中筛选信息的问题。随着编程技术的普及,基于Python的网络爬虫技术可为建筑师订制建筑相关数据的专用搜索引擎。本文根据网络爬虫的运行原理,在分析建筑学主流网站的特征后提出面对建筑专业需求的爬虫策略,为建筑专业数据挖掘和大数据分析提供可靠的研究基础。
1 建筑专业爬虫需求与实现技术
1.1 建筑学网络需求
建筑学专业常规采集数据的方法有3种:查阅书刊、实测与问卷、搜索互联网。其中多数建筑人员搜索互联网的方式是通过浏览器手动搜索并下载数据。这种手动操作方式是一种传统的网络数据挖掘方式。如今互联网普及的时代,建筑专业对高效获取网络信息的需求日益增加。研究项目时需要基础资料、设计构思时需要参考案例、会议总结时需要规范模板,等等。然而,海量数据的筛选也占用了工作的大量时间和精力。特别是国内大部分建筑相关网站都是免费提供资源,网站内不可避免地安插广告、验证码、个性推荐等干扰信息。因此,准确、直接且高效地定位所需网络数据,按照用户意愿规范化存储到本地是建筑相关从业人员和研究人员的切实需求。
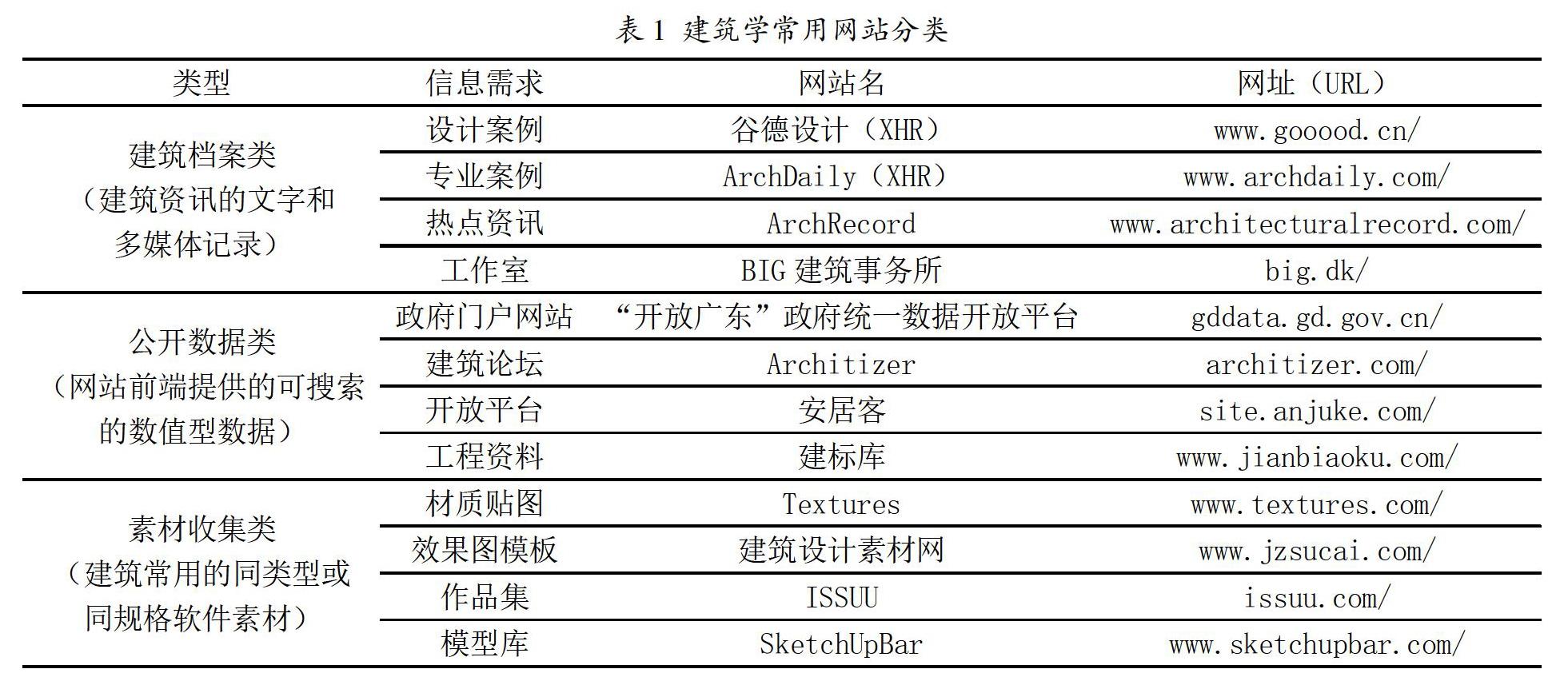
目前与建筑相关的爬虫研究并不多。比如,房产信息研究者关注通过爬虫获取某地区房价及相关数据,借此分析房价趋势[1]。地理研究者借助爬虫提高獲取地理国情房屋建筑专题数据的精度和效率[2]。规划研究者爬取多源数据并融合应用于城市规划研究[3]。大部分研究都是从数据研究员的视角出发,但从建筑学的专业需求出发解决网络爬虫问题的专项研究较少。参考有关建筑类网站建设的有关研究[4,5],总结建筑学常用网络资源如表1所示。建筑类网站分为3类:建筑档案类、公开数据类、素材收集类。也有整合资源的大型综合网站涵盖了上述3类,比如,筑龙学社(www.zhulong.com/)、建筑学院(www.archcollege.com/)和土木工程网(www.civilcn.com/)等。查看网站主页源代码可知,国内建筑学常用网站大多仍采用传统的HTML文档(Hyper Text Markup Language,超文本标记语言)编写。HTML指带有CSS(Cascading Style Sheets,层叠样式表)属性的文本,是专门用于描述网页的一种标记语言。HTML层级结构分明,所需下载的数据按上下级目录有序存储在网页源代码中。通过定位HTML文档的标记(Tag)或属性(class)可实现聚焦爬虫获取数据。
1.2 基于Python的网络爬虫技术
网络爬虫(Web Crawler)也叫网络蜘蛛(Spider)、网络机器人(Robot)等,指自动依照用户定制的规则搜索并获取网络数据的机械程序。爬虫可代替用户通过网站的URL(Uniform Resource Locator,统一资源定位符)向服务器请求数据。服务器响应后,爬虫可以代替浏览器解析网站源代码,然后根据设定的规则批量提取数据。最后,爬虫可按要求规范地把数据存储到本地,便于日后处理。本质上爬虫就是程序超高速模仿人工上网,让非网站管理员的用户从网站获取批量数据。一个考虑周到的爬虫程序可以与服务器形成良性互动,很大程度辅助建筑专业解决网络资源的采集需求,让建筑学数据库容量更贴近大数据要求[6]。Python语言可在大多数情况下高效地实现建筑专业爬虫需求。
Python是一门面向对象编程(Object Oriented Programming)的语言,其具象和简洁的特性更适合跨专业编程人员阅读使用。Python跨平台广、开源代码库量大,从爬虫、数据分析到机器学习、图像识别等,可以辅助建筑专业完成机械性的重复工作[7-8]。通常在建筑类数据的爬虫中,搜索对象都是具象且明确的,操作思路是清晰明确的。使用Python爬虫可以尽可能接近建筑师思维完成工作。Python不一定最适应爬虫,但很大程度是最适合建筑师使用的编程语言。基于Python编写的爬虫程序不仅是获取专业数据的良好基础,也是大数据分析的科学基础。本文借助Python3语言引用requests、BeautifulSoup、openpyxl、os等代码库编写爬虫代码。其中requests用于请求URL数据,BeautifulSoup用于解析HTML文档,其他代码库联动用于获取并规范化储存数据。
1.3 适应建筑专业需求的爬虫策略
网络爬虫按照实现的技术和结构分为通用爬虫、聚焦爬虫、增量式爬虫和深度爬虫等。由于建筑网站具有较高专业性,网站彼此较为独立,很难只用通用爬虫技术实现全网数据爬虫。使用聚焦爬虫和深度爬虫能更有针对性地实现专业数据爬虫。聚焦爬虫(Focused Crawler)指按照预先定义好的主题有选择地进行网页爬取。聚焦爬虫可把目标定位在与建筑主题相关的网页中爬取指定数据,从而节省大量的服务器资源和带宽资源,对特定专业内容的爬取具有很强的实用性。深度爬虫(Deep Crawler)是以网页深度优先,把所需信息逐层打开,记录所需信息的页面列表,直到爬取满足深度要求再结束。建筑类网络爬虫主要是这几类爬虫技术的组合体。
如表1所述,建筑类网络资源丰富且专业性较强。对应的建筑学网络爬虫需求主要有3种:图文档案资料,数值型数据,批量同类型素材。通过数据类爬虫策略和档案类爬虫策略可基本解决上述需求。其中数据类爬虫以聚焦优先,档案类爬虫以深度优先。通过调研发现,我国政府门户类网站(*.gov.cn)内大部分的公开数据信息已经过整理。用户通过公民信息注册登录即可获取信息。目前爬虫对这类网站针对性不强,同时也不提倡对这类网站进行爬虫。本文通过两个实例分别实现数据类爬虫和档案类爬虫策略。
2 公开数据爬虫策略
2.1 数据请求与解析
数据类爬虫指与连续数值关联度较高的信息。比如:高度、面積和时间等。数据的影响因子涉及越全面,数据变动规律的预测越准确[9]。因此数据类爬虫策略往往优先限定提供数据样本的网页目录。如非必要不深入网页内页,避免数据报错。本文以anjuke.com为例,搜索2020年3月广州市越秀区二手房的房源信息。房价及其相关信息是时刻随着市场交易变动的。通过爬虫保持量大且长期的数据库才能基本满足大数据的研究基础。该网站网络结构层次清晰,数据量大且实时更新速度较快,能保证爬虫的长期稳定运作。
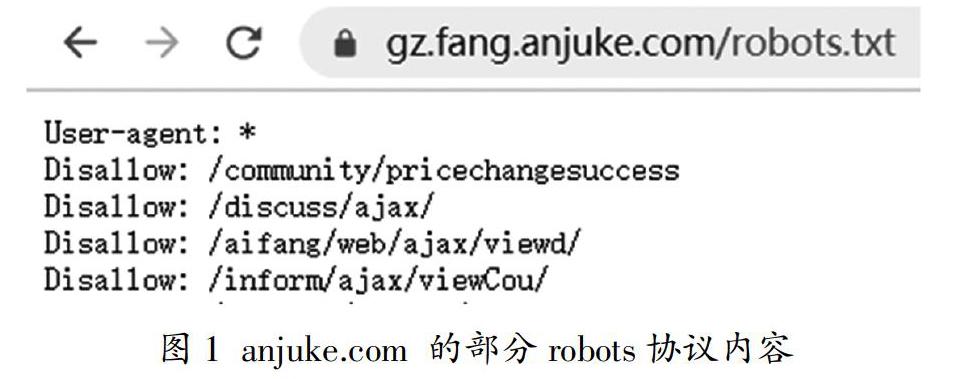
尊重robots协议的科学爬虫是实现用户与服务器间良性互动的基础。robots协议(robots exclusion protocol,网络爬虫排除标准)是互联网爬虫的一项公认的道德规范,用于公示允许爬虫的内容。如图1所示anjuke.com的部分robots协议内容,禁止了具体目录下的爬虫。本文对建筑类网站爬虫均遵循网络协议,研究重点在于准确、便捷、稳定地提取所需的有效信息,而不刻意强调爬虫速度。程序内合理设置限速(Crawl-delay),避免对网站服务器造成负担。尽管合理设置了限速,爬虫策略依然比人工搜索高效。
该网站主要的源数据基本记录在HTML文档中。因此,对HTML数据的爬虫策略主要分为四步:发出请求、解析文档、定位数据、规范存储。首先,通过网站的URL向网站服务器发出请求,征求服务器响应。如图2、3所示,当Request Method显示为“GET”时,即为可请求的HTML文档。Status_Code显示为“2XX”时代表服务器成功响应了请求。当响应成功后,服务器返回的是一个二进制数据包,根据编码方式进行解码即可获取HTML文档数据。
解码所得HTML文档数据可用第三方的bs库解析为bs4.BeautifulSoup类,即一种容错能力较强的数据。解析后的网页数据仍量大且杂乱,在获取数据时需锁定所需数据。通常先找寻数据的上级标记(tag),再往下级缩小范围定位每个数据,从而避免数据干扰。有组织的数据定位可保证数据储存的规范化。通常使用表格对这类型数据进行储存,既便于Python直接分析,也便于第三方软件读取分析。
2.2 数据爬虫实现
如图4展示了数据爬虫策略的程序核心代码和执行结果。本次爬虫设置结束条件为定数循环搜索同一词条前50页信息。网页URL特征中‘guangzhou代表广州市,‘yuexiu代表越秀区,‘x代表页码。日后维护只需要修改上述关键参数即可搜索其他地区房源信息。通过requests.get()向该网站提出请求并自动解码返回的二进制数据。通过res.content确认该网为utf-8编码,与Python3内置编码一致。因此确认网站响应成功后可直接用BeautifulSoup解析返回所得的HTML文档。锁定数据时用find()定位房源信息的总标记(
- ),并用find_all()找出每个单位信息所有的上级标记(
- )。在单位信息范围内分别定位每个单位的名称、户型、面积、楼层、年份、地址和价格等数据。其中难点在于地址数据被独立列出,其上级标记()与其他数据的同级标记是完全相同的。如不进行区分则会出现定位报错,因此前者用上下级关系定位,其他数据用序列关系定位,明确区分了定位路径。在此基础上深度爬虫能继续定位单位小区容积率、绿地率、区位及配套等影响因子。遵守网络协议,本程序设置每页执行总延时大于6.5秒,确保爬虫与服务器间的良性互动。需要特别注意的是由于国内建筑类网站自身的建设与维护大多仍依靠人工。网站数据的录入与输出不可避免出现个别疏漏或不规范,因此程序设置了错误信息修正方式。比如设置except IndexError可避免个别单位由于缺失“年份”、“地址”等数据导致爬虫信息录入出错。
如图5展示了爬虫获取的信息部分统计结果,最终结果显示本次爬虫了3030条广州市越秀区二手房房源信息。结果显示2020年3月越秀区二手房均价52076.9元/m2。数据经过清理、量化后可进行简易统计。如建筑面积60m2以下的单位均价41001.5元/m2,60~100m2的均价51997.5元/m2,100m2以上的均价64429.8元/m2。将数值型数据输入模型回归模拟,回归方程能解释89.18%的房价变动,数据样本趋势符合预期,可供后续分析。本例爬虫总耗时442秒,可高效地辅助建筑师完成数据收集工作。同时,程序编写后只需少量维护即可长期多次重复运行。
当程序稳定适应平台的大部分数据后,该策略通过广度爬虫可拓宽数据的丰富性和时效性。比如,依然以该网站为例,横向获取2019年4月至2020年3月广州全市与广州越秀区每月的新房和二手房均价,综合计算后生成折线图对比一年内房价变化趋势。如图6所示,结果显示当年广州市新房与二手房房价变化差距较小,总体持平,略微偏升。越秀区新房均价同比上涨16.8%,环比持平微升,比全市均价高出约159.4%。越秀区二手房均价同比上涨7.3%,环比持平微跌,高出全市约66.7%,样本趋势符合预期。
3 建筑档案爬虫策略
3.1 需求分析与策略解析
档案类爬虫指与离散数值相关的信息。比如:符号、文字和图像等。建筑师在日常学习、方案构思和项目研究时都会参考大量的建筑案例。在搜寻案例时不仅要获取文字描述,也要案例图片、视频等多媒体数据。也有建筑学者需要下载电子书、期刊、论文等大篇幅字符类数据。当档案型数据收集满足一定数量和质量,通过人工分析或机械学习辅助解析,可以在一定程度分析出科学规律。数据表现的共性越多,数据内在联系的越紧密。
档案爬虫策略请求服务器与解析HTML的方式与数据类策略相近。在此基础上,增加网页列表的筛选和图文资料的分渠处理两步。这些内容重复判断较多,写成一条主程序既不简洁也不便维护。因此在建立主程序前需要先封装成几个小程序。本文以zhulong.com为例,爬取展览建筑案例,包括文字描述、图片和链接,并按相同格式存储同一档案中。由于zhulong.com属于大型综合网站,架构复杂且信息繁多,需分层结构特征,避免信息干扰或报错。该网站的内置搜索引擎实为全站搜索引擎,即没有专门案例信息的高级搜索。传统人工搜集展览建筑案例的用户只能手动翻页,逐页找寻符合要求的案例资料。因此在网页列表时优先采用聚焦爬虫,通过设置若干关键词,让计算机筛选出只符合要求的案例信息,提高搜索效率。过滤出网页列表后再通过深度爬虫请求并解析每个案例网页的内部信息。分别定位文字和图片数据后再按规定路径储存。
3.2 档案爬虫实现
如图7所示,为案例档案爬虫程序核心代码。首先分别封装3条小程序:mkdir()通过传入路径参数新建档案名为案例名的文件夹;getphoto()通过传入单张图片URL下载图片并单独存放;getpageinfo()通过传入网页列表下载案例图文信息并自动排版到文档中。主程序要求简洁、稳定,因此核心代码只负责获取参数和传入参数。通过分析网站特征聚焦至建筑案例统计页(bbs.zhulong.com),并把分类限制在文化建筑案例(101010_group_201808/simple)。定位案例的题目(('a')['title'])和案例URL(('a')['href'])。设置关键词“展覽”,令符合筛选规则的案例URL传入网页列表。网页列表完成后传入getpageinfo(),逐一提取列表中的每个案例进行深度爬虫。进一步分析源代码发现该网内部格式分歧较多,初步推测网站主站和内页可能分包给不同的工程师构建。因此编程时要多次测试,把所有情况都考虑周全。先检测案例内页是否响应,如响应成功,启用mkdir()建立档案,否则返回错误代码和案例URL。通过上级标记(
)中的所有 和标记定位文章文字内容,然后再通过标记(
)定位图片。程序试运行发现所有图片数据都会输出两遍,但没有报错。分析发现图片的标记和夹页( 结果显示截止2020年3月bbs.zhulong.com有274页合共5462条关于文化类建筑的案例信息。本例爬虫总耗时4118秒,共爬取有关展览建筑案例83例。爬虫程序自动完成从资料搜索、文档建立到图文储存。资料数据完整度高,格式统一,具有较高的研究和再利用价值。
4 结束语
本文分析了建筑专业的常用网络需求,总结了3类建筑类网站。在分析Python语言优势和网络聚焦爬虫特征后,提出2种适用于建筑类网站的爬虫策略。通过实例展示了爬虫策略的深度和广度。其中数据类爬虫策略可快速定位数值型数据并规范整理到表格中,便于读取和分析。档案类爬虫策略对多媒体文件有高效的处理能力,有利于建筑师查阅和深入研究。对大数据长期的观测有助建筑从业人员更好地把握行业动态,调整自身,是实施决策前的重要基础。
参考文献:
[1]姜东民,张永正,陈雅静.基于网络爬虫的房产价格信息获取及分析——以青岛地区为例[J].信息技术与信息化,2018(08):108-111+114.
[2]秦思娴,傅晓俊,余咏胜,等.基于Python实现地理国情房屋建筑专题信息提取[J].测绘与空间地理信息,2015,38(08):1-3+6.
[3]裴莲莲,唐建智,毕小硕.多源空间大数据的获取及在城市规划中的应用[J].地理信息世界,2019,26(01):13-17.
[4]张良,吴农.我国绿色建筑类网站的发展与现状分析[J].河北工程大学学报(自然科学版),2012,29(01):37-40.
[5]王琳琳,方立新,顾建新.建筑师网站的信息构建研究[J].情报探索,2008(04):60-62.
[6]何愉舟,韩传峰.基于物联网和大数据的智能建筑健康信息服务管理系统构建[J].建筑经济,2015,36(05):101-106.
[7]葛金刚,刘晗晗.基于PYTHON的多软件模型转换程序的开发[J].工业建筑,2014,44(S1):324-326.
[8]孙一凫,吕浩宇,陈毅兴,等.基于EnergyPlus-Python联合模拟和强化学习算法的室内环境控制优化[J].建设科技,2019(24):52-58.
[9]汪亮.对利用大数据掌握房地产市场价格的思考[J].中国房地产,2017(31):50-52.
猜你喜欢
杂志排行
