VoLTE业务IP承载网潮汐流量预测模型建模与分析
2020-11-23于增源
于增源
(中国移动通信集团终端有限公司黑龙江分公司,黑龙江 哈尔滨 150028)
0 引言
网络流量预测问题,一直是通信行业面临的重要问题。要想明确地了解网络性能和负载,提升网络可用性,保证网络安全,离不开可靠的网络预测技术。因此,流量预测技术广受各界关注,很多企业和供应商都已经在流量预测领域投入了大量资源进行研究。如文献[1-2]中,流量预测不能单纯利用泊松模型,而需要建立更为复杂准确的模型。目前主流的流量预测模型一般可分为2类:线性模型和非线性模型。其中,线性模型一般采用短相关的自回归模型、自动回归滑动模型和差分自回归滑动平均模型等;而主流的非线性模型则包括小波预测模型、分期布朗模型等。这几种模型目前的预测能力相对较好,但也有其巨大的局限性。IP承载网网络流量情况一般是数据量庞大且极其复杂的,包含很多相关性及其他影响因素,但是采用以上几种方法时,由于预测的数值区间很大,会导致预测的误差不断累积,最终的误差会极大,对于刻画承载网流量变化情况是很困难的[3]。此外,根据文献[3-4],流量统计和预测也深受地域以及时间影响,在偏僻地域数据流量消耗明显要小于繁华地带,不同地区的流量消耗也会随着季节、节日以及每日时间的变化而呈现复杂的变化趋势。
对网络流量的负载水平评估和预测也是一个关于时间的数组序列问题,需要根据不同时间在同一地点采集一定时间的网络流量数据,并根据已经采集的数据计算出未来某时刻的流量数据。根据文献[5],一般来讲,网络流量分布被认为是服从泊松分布,亦或是被认为是马尔可夫过程。大部分网络业务被定义为泊松分布,但是在文献[6]中说明,采用泊松分布构建网络模型是有缺陷的,因为采用这种方法会丧失网络的自相关性特点,所以使用泊松模型会导致对流量的评价不够准确。此外,网络预测方法中还有一种应用较为广泛的方法,也就是深度学习算法,例如神经网络方法,该方法经过改进和融合后有较强的数据处理能力,并且更加灵活。根据文献[7]和一些实验数据可知,采用神经网络的非线性算法一般比线性算法的预测准确率相对更高。
随着人工神经网络的发展,流量预测技术也开始可以与众多的神经网络模型相结合,解决数据处理与预测的问题。如文献[8]所述,人工神经网络利用计算机模拟人脑的神经系统,采用不同的数学模型如卷积神经网络(Convolutional Neural Networks,CNN)等来处理复杂的数据问题,具有很强的学习能力。常在数据处理中应用到的人工神经网络模型包括多层感知机、受限玻尔兹曼机等,多层感知机的网络结构是全连接的,其结构是由多个输入最终汇总到一个输出上,最终获得输出数据集。
在人工神经网络的不断发展中,神经网络越来越复杂,中间的隐藏层也越来越多,会导致严重的梯度消失问题。通过研究,不断产生了新的传递函数来代替之前常用的Sigmoid函数。在这之后,各种新的神经网络模型如CNN、循环神经网络(Recurrent Neural Network,RNN)以及深度神经网络(Deep Neural Networks,DNN)等,更广泛地应用于图像数据处理、文本识别、有时序性的数组处理等更复杂的项目场景。伴随着神经网络的逐渐发展与进步,流量预测模型也不断更新与发展。文献[9]针对IP承载网核心网络的流量变动问题,搭建人工神经网络模型,并根据预测所得值对IP承载网核心资源进行更合理的分配,提高网络效率。此外,在数据预测成功后的光网络资源分配方面,有研究人员采用蒙特卡洛树搜索的办法实现光网络弹性数据分配的功能,使网络短时间内自适应变化。但是目前提出的各种方法,在IP承载网负载增加时成本增加迅速,资源消耗也迅速增多[9-10]。
随着机器学习和通信网络流量预测技术的紧密结合,光网络也与计算机技术联系得越来越紧密,令光网络有机会越来越智能,越来越自动化,为光网络自我优化提供了可能。目前,已有的光网络与计算机技术结合成功的案例包括设备异常检测和物理层故障检测等[11-12]。4G/5G无线接入网技术也在不断发展,并且需要采用虚拟化技术科学分配网络负载资源,文献[13-15]考虑基于IP承载网的多业务综合通信。总之,目前的4G/5G网络面向大规模接入,更需要科学地运用网络负载分配和及时准确的流量预测技术。因此,本文以VoLTE业务在IP承载网的流量为研究对象,进行业务预测模型建模与分析,利用人工智能方法考虑流量数据时间上的相关性问题,从而实现对IP承载网流量的预测,进一步降低网络拥塞并提升服务质量。
1 基于VoLTE的IP承载网网络模型
采用深度学习技术与流量预测技术相结合的方法,通过建立相应的BP-ANN模型,实现对未来时间的流量预测,并判断是否到达潮汐迁移时段。需要获取在潮汐现象较强的网络模型中各个用户节点的网络流量数据。目前,互联网上关于城市的网络流量数据相对较少,流传较广的是2015年意大利米兰市于米兰电信大赛上公布的米兰市及附近几个月的各种业务以及网络流量数据,但是该数据更注重网络数据各地区之间的相关性,对于城市不同地区的流量变化反映得不明确,因此本文拟建立反映潮汐现象的IP承载网拓扑模型,采集各个节点的流量数据。
在城市中,一般工作区相对较为集中,而住宅区可能相对更加分散,并且占据的节点更多,峰值的业务量更大。为了模拟IP承载网光网络各个节点的流量和负载情况,要符合之前所说的要求。基于此,将IP承载网的光层抽象为如图1所示的拓扑模型。由图1可以看出,1,2,3,4这4个节点作为商业区的用户节点,而9,10,11,12,13,14这6个节点作为住宅区的用户节点,这样满足之前的要求,剩余的节点作为整个链路中剩余地段的用户节点。
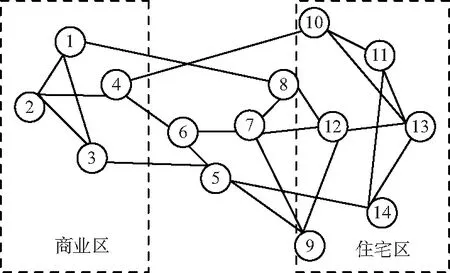
图1 IP承载网分区域的拓扑模型结构Fig.1 Topology model structure of IP Network
利用NS2进行IP承载网分地区业务流量的仿真处理,各个节点之间采用光纤直连的方式。由于承载网中网络器件存在噪声会影响信道链路,在链路上添加高斯白噪声来模拟器件噪声。在仿真中,各个节点发生业务请求要符合泊松分布,同时,整个模型在任意时刻,请求发生的概率是随机的,但不是均匀的。根据IP承载网流量的潮汐现象,在一段时间内按照白天的情况设置商业区节点的请求概率为住宅区的节点发送概率的2倍,在其余时间按照夜晚处理,二者发送概率相反。此外,系统中的业务传输也按照IP承载网特点,依据最短路径和首次命中算法设置网络传输路径和资源分配方法。在采集数据时,规定每4 min采集一次数据,一共统计2 h,采集各个节点与链路上的流量数据。之后,对流量数据按照数据的最大值进行归一化处理,获得各个链路和节点的负载情况。针对流量数据的自相关性,将同一时间段的流量数据放在同一样本中。最终,将采集到的时间信息和2 h内流量的归一化数据作为最终得到的数据样本进行分析。
2 基于深度学习的流量预测模型
针对本文提到的IP承载网潮汐流量特点,在分析之前常用的线性回归法对流量预测的问题和局限性的基础上,主要研究目前主要流量预测方法的适应性,并提出最优的IP承载网流量预测方法,构建准确率能达到85%以上的流量预测模型。
2.1 传统时间序列的预测方法
一般在流量预测中常采用传统时间序列的预测方法。传统方法一般采用流量数据的回归性来进行预测,但是IP承载网流量还受到地理位置和时间因素的影响,也就是说传统方法的考虑是不够全面的,所以基于深度学习的方法是更好的选择。先介绍线性回归和自回归移动平均模型2种方法[16-17]。
2.1.1 线性回归模型
(1)
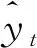
(2)
也就是说在有2个影响因素的情况下,可以记观测值为:
{(yt,x1,x2,t)},
(3)

2.1.2 自回归移动平均模型
(4)

相对于这些传统的基于时间序列进行流量预测的方式,采用ANN等神经网络对流量进行预测会更加灵活,应用范围也会更广。在设置神经网络时,只需要改变隐藏层节点数目和相应的偏置与权重值就可以模拟任意一个连续的函数,对于未来进行较好的预测。神经网络不仅仅可以处理数值序列,也可以对图片文字等进行识别。此外,针对数组的自相关性,采用LSTM等循环神经网络也会有很好的效果。所以本文选择利用神经网络预测流量数据。
2.2 基于BP-ANN网络的数据预测方法
ANN网络与之前介绍的线性预测算法不同,属于非线性统计性模型,它模拟了人脑神经元的网络结构,可以实现相对复杂数据的存储和处理功能。ANN网络具有逐层的结构,由多层的神经元逐个逐层相连。各层之间相互映射,通过各个层上节点的连接实现数据的并行处理。与线性预测不同,ANN网络的映射是非线性结构的,适合处理较复杂的数据和算法,并能够通过训练来符合系统要求,提高预测准确率。
ANN网络有很优秀的学习能力,所以可以获得较为真实的预测值,得到数值合理的真实系统。同时,这样做的好处是网络无需知道系统的具体信息,只需要知道系统的输入值,根据设定的具体模型以及隐藏层结构,最终获得输出值。所以ANN网络一般会用于解决模式识别等较为复杂的问题。在设计BP神经网络时,最多的情况是采用3层神经网络,也就是隐藏层只有1层的情况。在考虑3层网络的情况下,对于输入数据也有一定要求,因为有些时间采集的数据由于某种情况可能会存在数据的跨度大,数据收敛性差等情况,最终网络的训练时间就会很长,并且最终结果可能不会收敛。在网络训练之前,需要对数据进行预处理,同时为了使无论大或小的数据对网络训练的影响相同,需要将数据归一化,使数据的均值减小。所以就需要把数据最终归一化为(0,1)的数值或者(-1,+1)的数值。同时,还要考虑网络的学习速率,这个数据是为了反映在训练过程中每次的迭代步长等。
为了提高准确率,减小算法的误差,还需要反向对数据进行处理,基于此,本文提出BP模型,用于计算ANN网络中各级的权重。该算法通过逆向的误差传播,反向训练其中的隐藏层和输入层的神经元,借由其拥有的自我学习、自我调整能力实现获得各层的偏重,最终使输出迫近期望。一般的BP神经网络模型如图2所示。由图2可以看出,分为输入层、输出层和隐藏层各神经元节点。输入层和输出层的数量都为1,而隐藏层有可能是1层,也有可能更多。
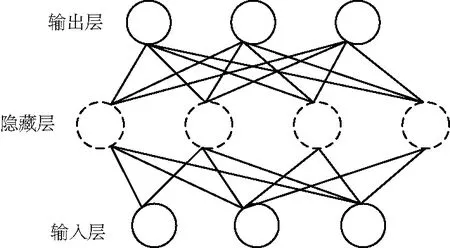
图2 BP神经网络模型Fig.2 Model of BP neural network
在BP神经网络中,除了计算加权求和,激活函数f(t)也十分重要。BP神经网络是非线性的,所以需要有一个非线性的激活函数来给它提供一个非线性的变换。常用的激活函数有Sigmoid函数和ReLu函数,它们是2种最基本的激活函数。
Sigmoid函数图像如图3所示,

图3 Sigmoid函数图像Fig.3 Function of Sigmoid
Sigmoid函数为:
(5)
其取值范围为0~1,便于处理分类问题,但是在考虑反向传播算法时,易发生梯度消失。
ReLu函数如图4所示。
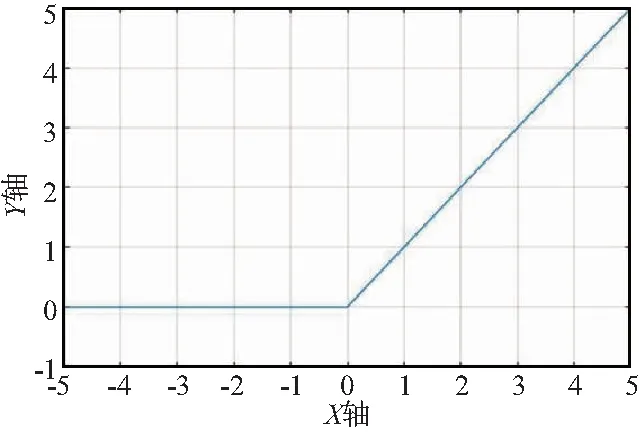
图4 ReLu函数Fig.4 Function of ReLu
ReLu函数为:
φ(x)=max(0,x),
(6)
其特点是结构简单、收敛快,但是在处理一些连续的负数时,会对数据有激活现象。BP算法最重要的2个特点就是数据在向前传播,同时误差在进行反向传播。
前向传播的流程是数据通过输入层进入网络,通过隐藏层的处理,最后传播到输出层,获得预测数据。对于只有一个隐藏层的网络,即单隐藏层网络,零输入层数值为xi,隐藏层数据为cj,输出层数据为yk,最终输出的期望为qk,此外,各层的数据权重和偏置分别为wij,pjk,θj和bk,那么:
cj=f(∑wijxi-θi),
(7)
yk=f(∑pjkcj-bk),
(8)
这样就根据输入层的数据获得了最终的数据。
对于反向传递,误差的流经路径与正向传播正好相反,误差通过反向传播修正各级的权重。一般输出层的误差都会用均方值来评判:
(9)
经过多次计算,进行数次正向和反向传播,使全局误差收敛至极小值即可。归结起来,BP神经网络的训练步骤主要为:
① 初始化网络数据,设定网络的初始参数;
② 计算输出层的输出;
③ 获得在特定点的数据均方误差;
④ 采用梯度下降的方法获得更好的权重值和偏置;
⑤ 更新阈值;
⑥判定均方误差是否达到特定值的要求,选择结束迭代还是继续训练。
2.3 BP-ANN网络模型参数设置与训练方法
需要对IP承载网流量进行预测,而承载网的流量数据已经被处理为一个数据包,再通过BP-ANN[18]网络模型以及LSTM网络模型进行学习和预测。建立模型的目的是通过输入一段时间的历史网络流量数据以及时间数据,预测未来某时刻的网络流量数据。此外,还可以判断某一时刻网络是否进入潮汐迁移时段,更好地为IP承载网用户提供高质量网络服务。在预测结果中分为已经进入和未进入迁移时段,所以是一个典型的神经网络的二分类问题。
在数据采集和处理过程中,还需要注意的是注意力机制,也就是要将数据处理以获得最终适合网络输入的数据,对于目前的BP-ANN网络和LSTM网络都有一定的必要性,一般会采用Seq2seq模型来对数据进行处理。Seq2seq是一种编码解码器的结构,其输入和输出都是一种数据序列。在模型中的编码器可以将输入序列转化为固定长度的中间序列,也称为隐向量,这个中间序列会影响最终的输出序列和预测结果。在解码器端,模型会根据当前时刻隐向量的数据和之前时刻的模型输出获得当前时刻最终的模型输出,然后再将序列转化为需要长度的序列。但是需要注意的是Seq2seq模型有很大的缺点,在这个模型中,不同的值都有相同的数值权重,但是在一些实际案例中,比如本文的流量预测环境中,当前时刻的网络流量应该是与临近时刻的流量数据相关性比和较远时刻的相关性要弱,所以序列的不同输入数据权重应该有所区分。所以处理数据构建神经网络必须要采用注意力机制。注意力机制中,主要采用的是Global Attention机制和Local Attention机制。首先,获得所有编码器时刻的隐藏层状态输出,再得到某时刻的解码器的隐藏层的状态输出;然后,利用平分函数,也就是attn(htarget)得到某个时刻的时间对应的权重并进行归一化,得到编码器的输出进行权重平均;最后,获得最终的输出概率。目前一般采用固定的函数来计算序列的权重和注意力数值:
(10)
式中,htarget是最终获得序列的某时刻状态;hi是此时刻的隐向量的值。根据匹配程度获得其权重值,匹配度越高值越大,最终再将其归一化,获得方便计算的0~1的值。因此,设计了如图5所示的BP-ANN神经网络结构模型来进行IP承载网流量数据预测。
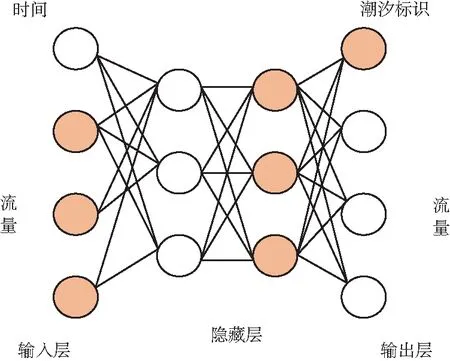
图5 潮汐流量预测BP神经网络模型Fig.5 BP neural network model for tidal traffic prediction
对于这个网络的输入,考虑为当前的2 h内每4 min采集的共15组数据以及时间数据,所以输入层共31个节点。而输出层也需要16个节点,包括未来1 h内的15次网络流量数据以及判断是否到达潮汐迁移时段。此外需要注意的是,为了判断是否到达潮汐迁移时段,需要引入潮汐标识位,该输出为1表示即将到达潮汐迁移时段;如果输出为0则表示还未到达潮汐迁移时段。这是一个深度学习网络中的分类问题。而流量预测问题则是一个回归问题[19]。
对于隐藏层的层数以及每层上的节点数目,可以根据Kolmogorov公式来选取。Kolmogorov公式是一个经验公式,可以为隐藏层提供一个范围,然后可以在训练过程中来选取最优的隐藏层数据。
在深度学习不断发展的过程中,学者们给出了许多用于确定隐藏层结构的方法,其中最具代表性的就是经验公式Kolmogorov公式[20]。Kolmogorov公式表明,对于仅有3层的简单神经网络,隐藏层节点数目h一般可以表示为:
(11)
式中,m为输入层中神经元节点的数目;n为输出层神经元节点的数目;a为一个范围为1~10的调节系数,可能取到其中的任意值。在本文中,输入层有31个节点,输出层中有16个神经元节点,根据经验公式可得当仅有一层隐藏层时,隐藏层的神经元的数目取值范围在7~16之间。为了让学习过程相对简便,可以先令隐藏层神经元节点数为7,减小初始的计算量。经过相关研究论证,一旦隐藏层节点数目增多,BP-ANN网络的学习效率将会不断降低,所以要尽量减少隐藏层神经元节点的数目。
在训练的过程中,会通过学习,预测30 d的网络流量数据,然后再根据实际值进行验证。总共统计30 d,每天会得到24组数据,一共得到720组数据,按照8∶1的比例,选取640组进行模型的训练,利用剩余的80组数据来验证该模型的分类能力和回归[30]能力。
3 预测结果与数据分析
根据本文设计的BP-ANN网络进行网络流量数据预测,需要在计算机中搭建深度学习的平台。本文中运用Tensorflow学习框架,利用Tensorflow来搭建上述的BP-ANN网络,并进行数据集的训练与学习。利用Tensorflow得到本模型训练中loss值的变化如图6所示。随着训练与迭代的次数逐渐增大,模型的loss值逐渐减小至收敛装填,模型也逐渐稳定。
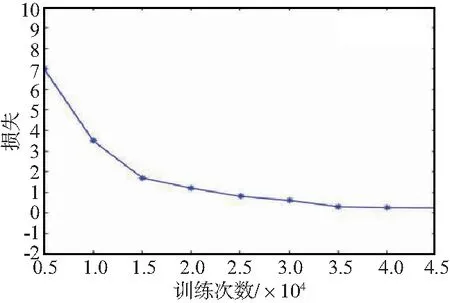
图6 Tensorflow中损失随训练次数变化趋势Fig.6 Variation trend of loss with training times in Tensorflow
可以看出,在训练中,迭代次数会影响本算法的准确性和预测结果。为了明确本模型的可用性,需要对其性能进行评价。可以采用平均绝对误差(MAE)来衡量本模型性能。MAE的计算表达式为:
(12)
该值通过计算绝对值之和,来衡量模型的预测值对于真实值的偏差。平均绝对误差与训练次数的变化趋势如图7所示。由图7可以看出,MAE随着训练次数不断增大,而平均误差缓缓减小,预测值越来越接近真实值,也就是说,模型能够对IP承载网的流量数据进行较为准确的预测。

图7 平均绝对误差与训练次数的变化趋势Fig.7 Variation trend of average absolute error with training times
预测潮汐迁移时段的准确率随训练次数变化的趋势如图8所示。由图8可以看出,对于模型的分类能力,也就是模型能够准确预测潮汐迁移时段的能力,训练次数越大、迭代次数越多,模型准确率越高,最终趋向于90%。

图8 预测潮汐迁移时段的准确率随训练次数变化的趋势Fig.8 Variation trend of accuracy of tidal migration period prediction with training times
由于隐藏层的神经元节点数目在7~16,需要对节点数对于MAE的影响进行评估。可以预见,随着隐藏层神经元节点数目增加,完成训练的时间会不断增大。MAE随着隐藏层变化的数值关系如图9所示。可以看出,当节点数少时,MAE相对较大,而当神经元节点数不断增加,MAE值的变化也逐渐趋于平缓。

图9 MAE随着隐藏层变化的数值关系Fig.9 Numerical relationship between MAE and hidden layer
对于模型的分类能力与隐藏层节点数的关系的判断,引入预测准确率的概念。预测的准确率反映的是模型对所有样本的判断能力,表达式如下:
(13)
式中,TP为实际到达预测对的次数;FP为实际未到达预测错的次数;TN为实际到达预测错的次数;FN为实际未到达预测对的次数。
预定进行10 000次训练,然后改变隐藏层神经元节点的数目,获得二分类模型的准确率与隐藏层节点数的关系如图10所示。可以看出,模型的分类能力整体相对较好,与节点数基本无关。
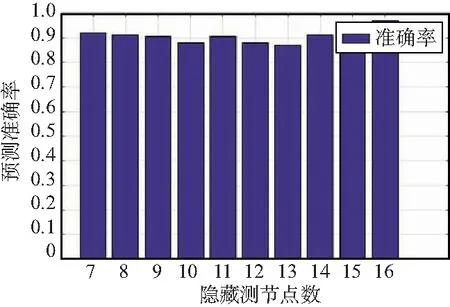
图10 二分类模型的准确率与隐藏层节点数的关系Fig.10 Relationship between accuracy of binary classification model and the number of hidden nodes
按照31-15-16的结构构建BP-ANN神经网络,设置迭代次数为100 000次,对模型进行预测,最终得到二分类模型的准确率与隐藏层节点数的关系如图11所示。可以看出,模型预测能力相对较好,并且对于潮汐迁移时段的预测能力也相对较好,较好地预测了在18~19时会有IP承载网流量数据进行大幅度迁移,具备较好的预测性能。

图11 BP-ANN网络预测潮汐迁移标识出现随时间的准确率Fig.11 Accuracy of BP-ANN network in predicting the occurrence of tidal migration markers with time
在IP承载网的资源重新分配和业务重构过程中,首先,要收集一段时间的网络某些区域的网络流量数据,通过已经建立的BP-ANN网络利用采集到的数据进行处理后学习,再配置不同的权重以及偏置,预测未来某段时间的网络流量数据;其次,需要不停地采集数据,对不同时刻的流量数据进行动态处理,不断地获得未来时刻的预测流量数据;然后,还要利用网络的分类能力来判断网络是否达到潮汐迁移时段,如果达到了迁移时段,为了应对潮汐迁移现象,需要对业务进行重组,对信道网络环境中的业务进行分类,根据其占用的带宽以及持续时长和优先级进行归类,将其按照权重归入待处理业务中;最后,再为其动态的分配各个业务占用的频带资源等,就可以尽可能提高网络的利用率。
4 结束语
分析常用的线性回归法对流量预测的问题和局限性,采用基于深度学习的BP-ANN算法讨论了基于VoLTE业务IP承载网的流量的预测问题,并验证了模型的准确率和可靠性。首先利用BP-ANN神经网络以对IP承载网流量进行预测以获取某地区未来一段时间的网络流量;然后,针对流量的未来变化以及其潮汐现象对网络设备和配置进行动态调整,以提高网络的利用率,同时,针对IP承载网流量的潮汐现象,在注意力机制的前提下通过设置合适的相关参数创建合适的BP-ANN神经网络,并考虑流量数据在时间上的相关性,实现对IP承载网流量的预测。仿真结果表明,通过寻找预测模型的合适迭代次数,不断减小模型的流量预测的误差,可以使流量预测准确率基本达到85%以上,可以为现有IP承载网QoS部署策略进行优化提供有效的解决方案。
