时空大数据与云平台的关键技术
2020-11-23朱迅黄世秀沈天贺侯颖合肥工业大学土木与水利工程学院安徽合肥230009
朱迅 ,黄世秀 ,沈天贺 ,侯颖 (合肥工业大学土木与水利工程学院,安徽 合肥 230009)
1 引言
在物联网、移动互联网以及云计算等新兴技术快速发展的背景下,数据的获取途径变得多元化,数据种类变得多样化,尤其是带有时空信息的数据正在迅速增长[1],原有的“数字城市”的城市基础地理空间框架已无法满足需求,城市管理手段现在向以时空大数据为核心的智慧城市建设方向发展[2]。
2 时空大数据的建设

图1 时空大数据构成
建设的总体路线应在先行完成基础地理信息数据的基础和公共规划数据之上,再依次开展实时感知数据以及公共专题数据的建设,层层叠进,确保各类型的数据建设,应根据城市信息化的基础来满足各方应用需求,达到智慧城市顶层设计的要求,同时为后期搭建数据库提供支持。
3 时空信息云平台的建设
3.1 云平台总体架构
时空信息云平台充分利用前期已经建设完成的数字城市,地理信息公共平台建设成果和时空大数据资源,开展地理信息公共平台升级,以数据服务、功能服务、接口服务和知识服务为核心,形成云平台资源池,在云平台中建立服务引擎、业务流引擎、地名地址引擎和知识化引擎,通过统一门户系统,根据用户的应用需求,为各种智慧业务提供时空数据信息服务。时空云平台总体架构如图2所示。
①云平台支撑环境

图2 云平台总体架构图
云平台支撑层通过租赁的方式接入新区的电子政务云,通过软件、网络、硬件等物理环境和机房环境,从而实现基于云计算环境的数据中心。通过这种方式能大幅解决各种分散、多样的信息平台,造成的硬件设施运营成本高、软硬件设施效率低下、能源消耗高等问题。
②云平台服务资源池
资源池是由时空大数据基础上对各种数据进行处理、融合、资源池化,汇集成一系列的服务资源,包括数据资源、功能资源、应用框架资源、调用接口资源等。在第二章时空大数据建设中已经做了详细的介绍。
校园文化环境是高校进行思想政治教育的重要物质载体,包括物质文化环境和精神文化环境。校园文化环境通过有形和无形的方式影响着学生,将工匠精神教育寓于校园文化环境建设之中的这种隐形教育方式有利于大学生接受工匠精神,以校园文化环境为载体开展工匠精神教育有利于实现思想政治教育的目标。
③云平台
云平台作为时空云平台的服务层在支撑环境和服务资源池的基础上,将各类的GIS资源整合,用户可以通过统一门户展示的各类功能来获取相应的服务需求,云平台还提供了云服务引擎、地名地址引擎、业务流引擎、知识化引擎等模块,用户可以在云平台提供的云服务基础上,结合自身需要选用相应的服务或者使用相关引擎模块创建专业的业务系统。
④智慧应用
应用层构建了时空信息应用体系,在时空大数据中心和云平台的基础上满足各种行业智慧应用的需要,包括有智慧人口、智慧经济、智慧城管、智慧园林等行业应用。
4 时空信息云平台关键技术
4.1 时空大数据的分布式存储技术
时空大数据含有海量的数据,数据中包含了大量的非结构数据,传统的结构化数据存储方式,无法解决非结构数据的存储问题。因此针对这些数据的特性以及时空云平台的需要,采用基于HDFS分布式存储系统来解决非结构化数据的存储。HDFS存储流程图如图3所示。
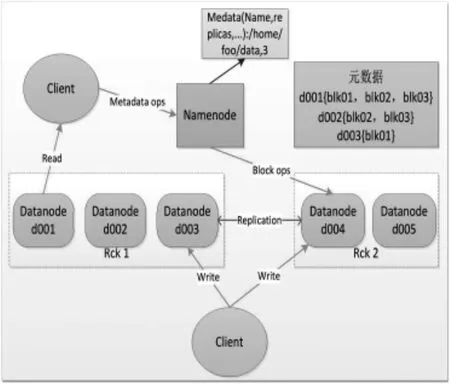
图3 逻辑流程图
①写入流程
第一步:Client通过调用文件系统的create()方法向远程的NameNode发出RPC(远程过程调用)请求,来上传文件。NameNode会进行检查来确保新文件在HDFS文件系统中是不存在的,同时检查相应的创建新文件的权限。检查完毕后,NameNode记录下新文件的内容,返回是否可以上传;
第二步:Client先对文件进行切块,比如一个block是 128MB,则一个500MB的文件就会切成4个block,三个 block为 128MB,一个 block为116MB。再向NameNode请求文件起始block的DataNode地址,NameNode返回最适合用来存放block的一组DataNode地址。比如为Datanode01,Datanode02,Datanode03,Datanode04;
第三步:Client向这组DataNode请求一个Datanode来上传block,记做Datanode01,同时建立 pipeline(数据流管 道 ),Datanode01 再 调 用Datanode02,接着再调用Datanode03,Datanode04,将整个pipeline建立完成后返回给Client。在文件切割时,文件分割成block然后放入一个内部队列,叫做 packet(数据队列),packet就可以作为数据流在pipeline中传输。Client开始上传起始的block,以packet的形式传送给 Datanode01,Datanode01会存储这个packet包,再依次推送给Datanode02,Datanode03,Datanode04,在这个过程中,Datanode会逐级返回ack信息(确认正确写入),直到最后一个Datanode04返回ack给Client,同时Client开始向NameNode请求上传下一个block依次循环直到所有数据的写入。
第四步:Client完成所有数据写入的操作后,对packet调用close()方法,NameNode也存入数据的位置信息,写入流程结束。
②读取流程
Client通过调用文件系统的open()方法向远程的NameNode发出RPC(远程过程调用)请求,来获取请求的文件block所在的DataNode地址。对于每一个block,NameNode会返回一个含有对应的block拷贝DataNode地址,接下来按照集群网络拓扑结构得出的各个DataNode地址与Client的距离值来对DataNode排序,排序依据就近原则和心跳机制,如果Client本身就是一个DataNode,那么优先从本地的DataNode读取数据。如果出现读取错误,Client会再次向NameNode发送请求,获取另一个含有该block拷贝的DataNode地址。在读取过程中,Client反复调用read()方法,以packet方式从DataNode读取数据,直到所有的block读取完毕。读取完成后调用close()方法,读取过程结束。
4.2 时空大数据的空间匹配
在所有数据中,除却矢量数据、影像数据等规整数据,对于公共专题类数据以及部分实时数据来说,其数据内容中带有地名地址信息,却没有空间位置坐标信息。另外的一些媒体数据,其数据内容中既没有地名地址信息,也没有空间坐标位置信息,但在其存储的音频、视频、图像、文本类的文件里含有位置信息。第一类的数据需要进行空间处理,再利用地名地址匹配。第二类的数据则需要地名的识别后附上地址属性,再进行地名地址的匹配。
地名地址匹配技术中的地名地址提取是关键,这项技术在国内外的研究主要有基于词典、统计和机器识别等三种方式[6]。
4.2.1 地名地址的提取
在对数据进行空间统一化处理后,数据的格式和各种属性得到统一。根据地名地址的特性,依据专用名和通用名划分为几部分,以“创新大道祥源城B1-523”为例,如图4所示。

图4 地名地址组合示例图
如图4所示将地名进行分割后可分为5个部分,其中①②③部分组成了专用名,专用名中各部分都有严格的隶属关系,“祥源城”属于“创新大道”,“创新大道”属于“高新区”。④⑤则构成了通用名,一般作为地名地址的后缀,用来描述具体的实体位置,在各种文本中这也是格式最为复杂的,以这个地址为例,有些文本的描述是“B1-5楼”,“祥源城右手边第一栋上5楼”。所以要设计地名地址基因库,以上面的地址为例,如图5所示。
通过地名地址基因库,就可以轻松将地名地址提取,根据文本中不同的部分,寻觅到各组成部分,再将地名地址还原,实现地名地址的识别。在识别过程中,需先对整体信息提取,再依次提取专用名、通用名的信息,具体的算法步骤如下。
①基于网络获取的各种数据源,转化为文本输入。
②事件信息在提取中起到索引的作用,首先对其进行提取,利用正向匹配找到并标记各种信息中事件的描述词。
先将这些描述词记为n个值,把n个值放入集合 A 中,记做集合 A[i],(i=1,2,3……n)。A[i]代表信息中出现的第j个描述词。接下来将信息中出现描述词的字段位置另一个集合iA中,记做iA=[i](i=1,2,3……m),iA[i]代表着信息中出现描述词的字段位置。最后将出现描述词的字段长度值放入集合IA中,记做IA=[i](i=1,2,3……m),IA[i]就代表着描述词A[i]的字段长度。

图5 地名地址基因库结构图
③专用名的提取也是利用正向匹配来获取信息中出现的专用名描述词,同时进行标记,算法与事件一样。
④通用名的提取不同于以上两种,因为通用名一般有固定的搭配,“C号”,“1栋”,“三号楼”等,故采用逆向匹配技术。在逆向匹配过程中,遇到“号”“栋”“楼”“幢”等通用名,若其前面的字符有阿拉伯数字、汉字或者英文类的数字,则将其放入集合 B 中,记做 B[j]=(j=1,2,3……n)。
⑤对搜集的所有描述词,依据各词出现的重复率,选取最高重复率的描述词和字段长度,就能得到地名地址信息。最后利用位置模型进行寻址和匹配,即可得到媒体数据中隐藏的地名地址信息,实现时空大数据的时空匹配。
4.2.2 地名地址的匹配
基于以上对专题数据提出了地名地址提取算法后,对数据进行地名地址匹配,即可实现数据的空间匹配。这种算法的主要特点是其匹配的高效性和对于中文字符的适应性。其高效率的主要来源于算法在地址分词和匹配过程中避免了传统的地址语法语义分析过程,直接采用地址要素词典进行切词和匹配。同时通过关联地址要素(Trie树结构)和标准地址数据结构的节点,实现了倒排索引结构,基于索引进行切分和匹配的过程中,无需访问数据库,这样在大规模并发访问的情况下,不用解决数据库访问瓶颈(如构建数据库集群等),可降低系统物理构架复杂度,并提高系统物理架构复杂度,并提高匹配效率。如图6所示给出了多树结构匹配地址的示意图。

图6 多数结构示意图
5 智慧高新时空信息云平台应用
智慧高新时空信息云平台应用基于本文研究成果,智慧高新时空信息云平台实现了《智慧城市时空信息云平台技术大纲》提出的通用化平台、专业化平台和个性化平台,在时空大数据建设成果和分析模型基础上,实现了空间规划综合信息平台、生态环境监测平台、地理国情综合分析平台的开发,并在智慧水利、智慧城管、智慧国土、智慧安监、智慧管网等展开了行业示范应用,为推进智慧洪泽的建设进程做出了应有的贡献。
6 结语
智慧高新时空信息云平台项目是省级智慧城市时空信息云平台建设试点之一,是“智慧合肥”的重要组成部分,在省市两级政府部门的引导下,在高新区政府的正确领导下,统筹了高新时空地理信息资源开发利用,建成了高新权威、唯一、标准和通用的时空信息云平台,切实解决时空地理信息获取困难、应用不平衡和重复建设等问题,满足政府各部门和社会公众对时空地理信息的需求,加快高新区信息化建设的进程,为建设政府决策科学化、社会治理精准化、公共服务高效化提供有力支撑。
