基于层次化标签的人体解析*
2020-11-19胡莉娜高盛华
胡莉娜,高盛华
(1 中国科学院上海微系统与信息技术研究所, 上海 200050; 2 上海科技大学信息学院, 上海 201210; 3 中国科学院大学, 北京 100049)(2019年3月15日收稿; 2019年5月29日收修改稿)
人体解析是计算机视觉领域新兴的研究课题,在人体姿态估计[1]、场景理解[2]、自动驾驶[3]等领域有着广泛应用和重要意义。近年来,随着卷积神经网络在物体分类[4]、目标检测[5]和语义分割[6]等任务的性能上取得大幅度的提升,以及大型人体解析数据集的发布,深度学习作为一个数据驱动的方法同样可以在人体解析任务上进行实践。
针对人体解析,目前已有很多深入的研究工作。这些研究可以大致分为两大类,一种是基于传统手工设计特征的方法,另一种则是基于卷积神经网络的方法。Bourdev和Malik[7]在行人分割问题上提出人体解析的概念,同时发布了具有行人分割标注的PennFudan数据集,包含170张图片。Bo和Fowlkes[8]进一步标注头、上身、下身、鞋子等人体部位。此外, Yamaguchi等[9]提出以服装配饰为主的人体解析数据集Fashionista。基于数据集的不同特性,传统方法设计了不同的解决方案。PennFudan中的行人只对人体的主要部位进行标注,而主要部位有相似的形状。针对这个特性,Bo和Fowlkes[8]提出基于形状特征的方法,首先建立一个包含不同部位的样例池并对样例提取形状特征,然后对图像进行过分割操作,获取潜在区域,并对这些区域进行同样的特征提取,随后与样例特征进行相似性度量,将属于同一部位的区域合并,得到最终的解析结果。类似地,Rauschert和Collins[10]提出先建立包含形状参数的人体模型,然后对该模型进行渲染操作得到对应的图像,通过合成的图像与原图像之间的特征约束得到理想的解析模型。而对于Fashionista数据集,它包含更多的类别,且标注中包含复杂的衣物配件,因此之前基于形状特征的方法不再适用。Dong等[11]提出用树状结构构建人体不同部位之间的关系,第一步仍是利用过分割算法获得潜在区域,但随后利用树状结构对潜在区域建立连接和从属关系,最后对预测的树状结构与真实树状结构进行比较,采用得分机制,进行奖惩以获得最佳的人体解析结果。
随着包含5万张图的大规模数据集LIP[12]的出现,基于卷积神经网络(convolutional neural networks, CNN) 的模型才真正在人体解析问题上得以应用。与之前的数据集相比,LIP数据集结合了人体部位和衣物配件属性,最终得到19类精细标注,如图1所示。LIP数据集包含室内和室外的各种现实场景,复杂多变的人体姿态、光照条件以及不同程度的人体遮挡情况。这些问题使人体解析任务变得更具有挑战性,但同时也让人体解析更具有现实意义和商业价值。

图1 LIP 数据集中的样例图片以及对应的人体解析标注Fig.1 Images on the LIP dataset and their annotations for human parsing
人体解析是对人体在像素层面上进行的分类,它与场景中的物体语义分割具有极大的相似性。目前语义分割问题的研究已经取得了很大的进展,从FCN[13]首次使用全卷积网络进行分割到DeepLab[14]选择用膨胀卷积来替代普通卷积,扩大单个神经元的感受野。对于场景的语义分割,图片的尺度是另一个值得重视的方面,对图片进行不同尺度的放缩,能改善图片中物体尺寸的极端状况。图片中的小物体经过放大后,能够在神经网络的深层保留特征,过大的物体则能缩小到正常的范围,让神经网络感知并提取全局信息。由此,基于注意力机制的Attention-DeepLab[15]被提出,它将输入图片进行不同尺度的放缩,经过同样的网络结构后,对每个尺度的输出结果添加不同的权重,使其对最终的分割结果有不同程度的贡献。近几年,随着卷积神经网络结构的不断改进,分割的准确率也不断提高,以上方法都已经被应用到人体解析当中,但由于两个研究问题之间存在着差异性,对应的网络结构需要做进一步的调整才能提升人体解析的性能。除此之外,针对于人体解析而设计的方法也不断被提出,比如基于自监督机制的SSL[12], 利用每个解析部位的中心坐标来加强对解析结果的约束。考虑到现实场景中人体姿态多变的问题, MULA[16]则是将人体解析与人体姿态估计进行多任务并行学习,通过设计两个任务参数关联的模块,进行不同任务之间的特征迁移,使得估计的人体姿态与解析图结果保持一致性。 此外,还有基于对抗生成网络的MMAN[17]、多尺度图像NAN[18]以及利用人体各部位的边缘图作为额外监督信息的CE2P[19]被提出。
本文提出基于层次化标签的卷积神经网络(hierarchical labeling networks, HLNet),受传统方法中构建解析树结构的启发,同时结合当前基于大数据学习的卷积神经网络CNN,实现对人体更为精确的解析。该方法改进了金字塔特征抽取模块,将人体的精细解析图进行不同程度的类别标签合并,获取由粗糙到精细的解析图,对金字塔结构不同层级的特征进行对应层次的监督,最后将所有层级的特征进行融合,生成最终的人体解析图。
本文的主要贡献如下:
1)提出一种基于层次化标签结构的卷积神经网络,该方法有别于其他方法,是基于人们分层次观察事物的视觉行为特性对语义分割模型做出的改进。针对人体解析任务,改进了特征金字塔的池化模块,使网络获取到图像的上下文信息。
2)设计加权交叉熵损失函数,用来解决图片内类别像素数量不均衡问题。针对数据集上不同类别图片数量不均衡问题,则提出加权采样策略。
3)在LIP数据集上的实验证明,本文所提的方法与之前基于卷积神经网络的方法相比,精度有了明显的改进,具有实际应用价值。
1 基于层次化标签的卷积神经网络
1.1 整体网络结构设计
1.1.1 特征金字塔池化模块
特征金字塔池化模块(pyramid pooling module, PPM) 是由Zhao等[20]提出的网络结构,最先用于场景的语义分割问题中。之前大部分场景理解和人体解析网络都是基于全卷积神经网络,这种结构存在几点明显的问题:1)全卷积神经网络是卷积层和下采样层不断堆叠的单支结构,没有考虑到一个区域的场景信息,比如手腿应在头部的下方,帽子则在头部的上方;2)全卷积神经网络没有考虑不同标签之间的关联,比如人体下半身不可能同时穿着裤子和裙子,它们之间具有互斥关系。另外,全卷积神经网络只利用最深层的特征进行解码,当只占少量像素的小部位经过多层的池化操作后,它们已经丢失了大部分特征,因此在解码操作时,无法恢复出原有的语义信息。
针对这些缺陷,特征金字塔池化模块做出了较大改进。特征金字塔池化模块通过将输入的特征进行不同尺度的池化操作,得到不同大小的特征图,每个尺度的特征图对应不同大小的感受野。针对人体解析任务,实验设计了5个层级上的池化操作,池化后特征图尺寸分别为1×1,3×3,6×6,9×9,12×12, 如表1所示。由于1×1大小的特征图只对全局进行粗糙估计,实验对该层级不进行特征的解码。
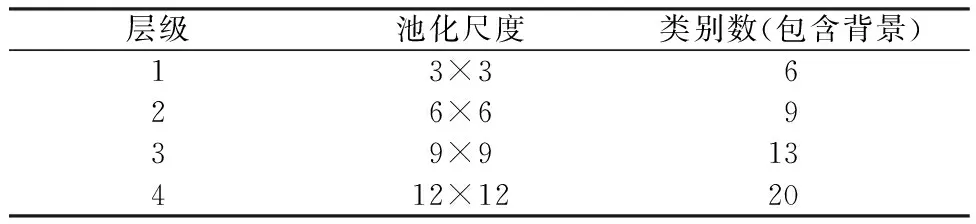
表1 不同层级上的池化尺度和解析类别数Table 1 The pooling sizes and the numbers of parsing categories in different branches
1.1.2 解码模块
如图2所示,解码模块主要由两个卷积层组成,没有使用任何激活函数,中间添加归一化层和Dropout层,分别用来加快网络训练的收敛速度和避免网络陷入过拟合。第一层卷积采用1×1大小的卷积核,用于特征图通道的降维。最后一层卷积则是用于解码成对应类别数量的解析图,因此在不同层级的解析分支上采用不同通道数的卷积核。
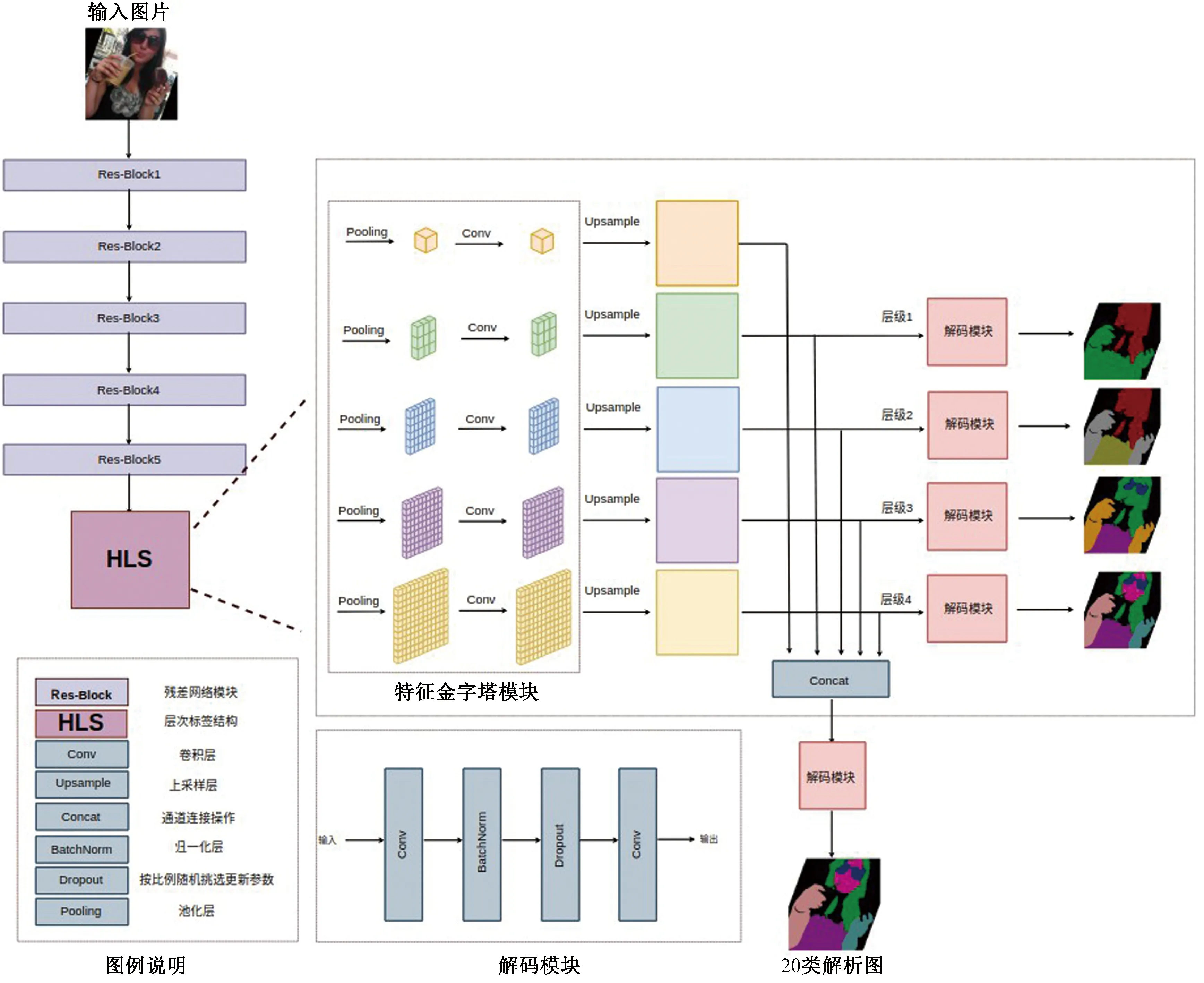
图2 基于层次化标签的卷积神经网络结构Fig.2 The architecture of hierarchical labeling network
1.1.3 不同层级结构的特征融合
为使网络能够捕获不同层级上的特征和场景信息,在网络设计时,将不同层级输出的特征图上采样到同样大小,然后用通道连接操作 (concatenate)实现特征融合,再经过解码模块,获得最终的解析结果。这种融合方式,保留了特征的空间位置结构,让不同层级的特征图在对应区域之间进行信息互补。既能避免大面积的错误分类,又可以维持边缘的细节特性。
1.2 损失函数
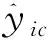
(1)
(2)
2 模型训练
2.1 实验数据集
本次使用的数据集为LIP数据集,包含现实场景中拍摄并截取出的4万张单人图像,其中3万张作为训练集,其余1万张作为测试集。
考虑到现实场景中的人是一个非刚体,与普通的物体相比,存在复杂的姿态变化以及不同程度的衣物遮挡问题,实验中需要对数据做数据增强,包括图片的旋转、放缩和翻转,如图3所示。这些变换可以通过一个仿射矩阵A实现,即利用仿射矩阵建立起同一个像素点在变换前后的两张图片中的坐标位置关系x→y,公式如下
(3)
y=Ax.
(4)

图3 在原始数据集上的数据增强样例Fig.3 An example of data augmentation on the LIP dataset
2.2 训练参数
实验中使用Pytorch 深度学习框架作为实验平台,训练时把ResNet101作为基础网络,使用在ImageNet分类问题训练好的模型参数作为初始化的参数,网络输入的图像大小为473×473。实验采用随机梯度下降(stochastic gradient descent, SGD)优化器进行训练,每次迭代处理24张图片,并使用多项式衰减(polynomial decay)策略来调整每次迭代的学习率,具体公式如下
(5)
其中:lrk为第k次迭代的学习率,lr0为初始学习率,K为最大的迭代次数,α为衰减率,实验中选取lr0=0.001,α=0.9,K=25 400。
3 实验
3.1 评价标准
与通用场景语义分割类似,使用平均准确率(mean accuracy, mAcc.)和平均交并比(mean intersection over union, mIoU)作为模型的性能评价指标。 平均准确率为正确分类的像素个数和该类别总像素数之间的比例,交并比为两个集合的交集和并集之比。在人体解析的任务中,这两个集合为真实解析图的像素和预测解析图的像素,先计算每个类内的交并比,再通过计算均值获得mIoU,具体的公式如下,
(6)
(7)
(8)
其中:nji表示解析图中实际属于第i类而被预测为第j类的像素数量,ti表示图片中所有被预测为第i类的像素总数,C表示解析的总类别数。
3.2 实验的定量分析
由表2可知,与其他算法相比,HLNet在LIP的验证集上平均准确率和平均交并比都有明显的提升,其中CE2P算法使用额外的边缘信息作为监督。实验证明,基于层级的标签结构设计对于人体解析任务是十分有效的。

表2 不同算法在LIP数据集上的性能比较Table 2 Parsing performance comparison among different algorithms on the LIP dataset %
表3对比添加不同层级对于整体解析性能的影响。由此可以看出,依次叠加层级结构,人体解析性能有明显的提升,在添加所有层级后,mIoU达到53.47%。
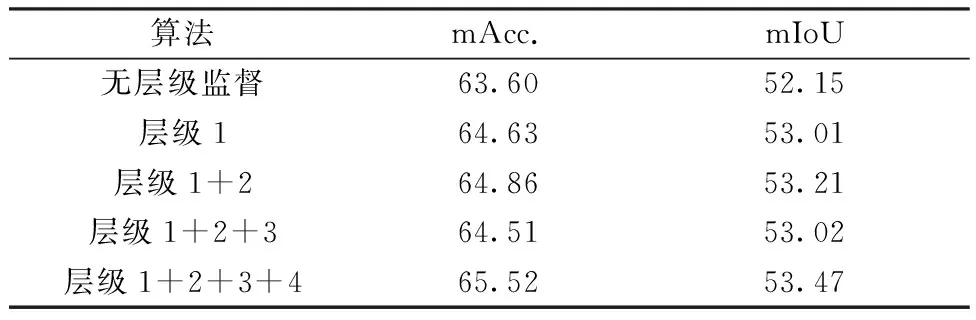
表3 添加不同层级对人体解析性能比较Table 3 Comparison of parsing performance among different branches added %
此外,如图4所示,HLNet在不同类别上存在明显的性能差异,占据大面积像素的部位有较高的准确率,如四肢、上衣和头部,而在小物体如太阳镜、手套、围巾上准确率略低。这样的实验结果与实际情况相符合,因为大部位在经过HLS不同尺度的池化操作后,都有对应的特征表达,但是小部位只能在较大尺度如9×9 和 12×12 上才能保留对应位置的特征信息。值得注意的是,对于连衣裙、连体衣、短裙这几个类别,尽管它们不属于小物体,但IoU值明显偏低,这是由LIP数据集的特性所决定的,包含这3类物体的图片总和在数据集中只占10%。而卷积神经网络是基于数据驱动的监督学习方法,训练过程中这些训练样本的比重过少,直接导致网络无法很好地学习到这些类别的特征,从而很难进行预测。
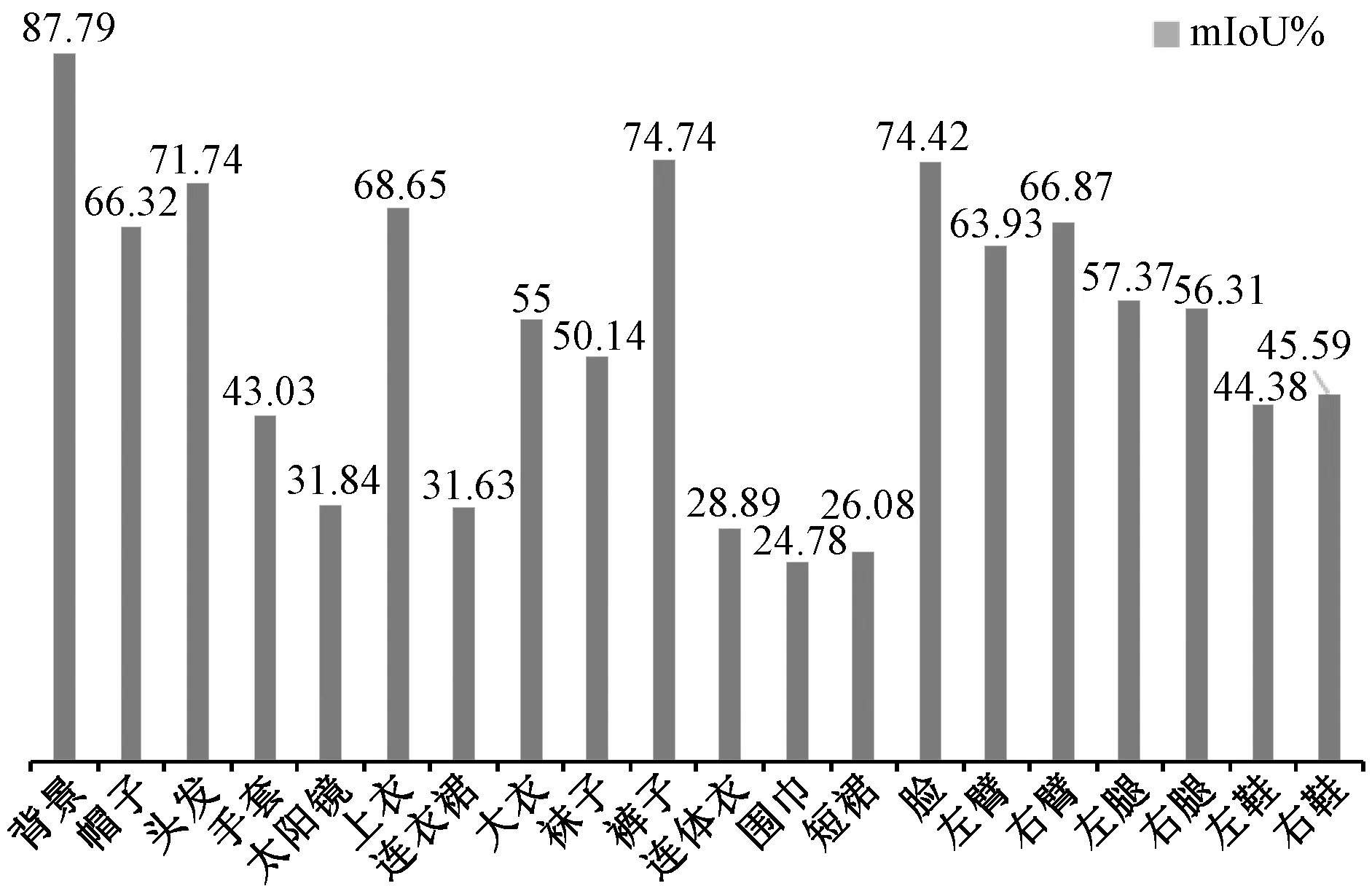
图4 HLNet在LIP数据集上不同类别的性能Fig.4 Parsing performances of different categories on the LIP dataset
根据上述分析,可知单张图片内不同类别所占像素数量具有明显差异,即图片内部的样本不均衡问题,而这直接导致在训练过程中网络模型倾向于优化像素多的大类。在实验过程中,我们改进了损失函数,用加权的交叉熵损失函数Lw替换原来的交叉熵损失函数L,给每个类别的损失值分配不同的权重。考虑到背景类别在图片中的样本数量远高于其他类别,对于整个网络优化有较大的影响,因此在所有图片的训练中,固定背景类别的权重大小,其他类别的权重按其与前景的比例进行分配,具体公式如下
(9)
(10)
(11)
LIP数据集除在图片内存在不同类别像素数量不均衡之外,还存在不同类别图片数量不均衡问题,比如包含连体衣、连衣裙、短裙等的图片数远低于包含头部的图片数,因此也需要采用策略来解决不同类别图片数量不均衡问题。修改数据采样策略能在一定程度上减轻这个问题的影响,实验中采用加权采样策略,以提高采样到稀少类别的概率,加权采样策略的权重计算公式如下所示
(12)
(13)
(14)
(15)
表4显示加权交叉熵损失函数明显提升人体解析性能,但权重调整系数r对网络训练影响较大。实验中选取0.15, 0.25, 0.4共3个不同的值,当r=0.25时,mIoU能达到54.00%,比用一般的交叉熵损失函数,提升约0.6%,此外加权采样策略也能提升0.1%,在每个类别上的IoU变化量比较如图5所示。
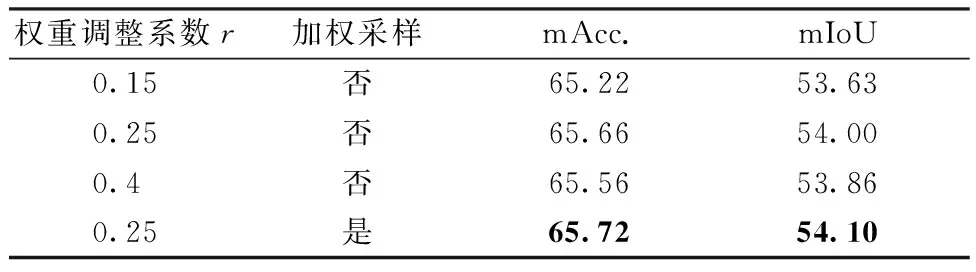
表4 不同权重的加权交叉熵损失函数和加权采样策略的性能Table 4 Parsing performances of the weighted cross entropy loss with different weight ratios and the weighted sampling strategy %
3.3 实验结果的可视化及分析
如图6所示,对不同层级上预测出的解析图进行可视化,用不同颜色标注不同的部位。经过可视化,不同层级的解析图的确呈现出一个由粗糙到细致的解析过程,网络学习到了对应部位的语义信息。在不同层级特征融合后,最终的解析图明显刻画出每个部位的细节,尤其对于头部和面部、腿部之间的间隙做到了精细的分割。
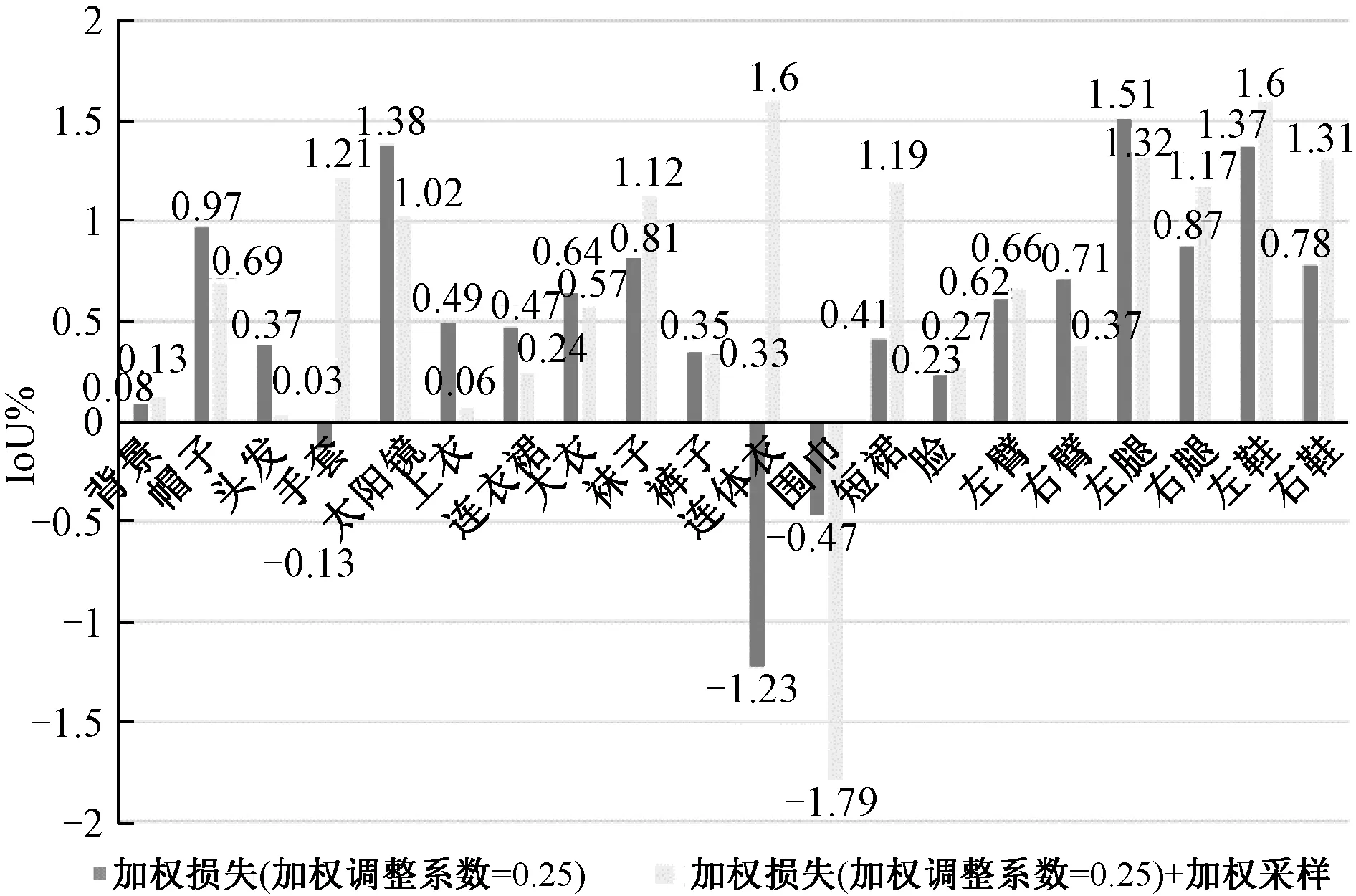
图5 加权交叉熵损失函数和加权采样算法在单个类别IoU指标上的性能Fig.5 The performances of the weighted cross entropy loss and the weighted sampling strategy on the single class-IoU
图7显示HLNet与其他基于CNN的方法的解析结果。由图可知, HLNet有两点明显的优势:1)在边缘细节上有很好的分割效果,同时还能保持同一部位内部的连贯性。在第1行样例中,HLNet并没有丢失任一部位,而另外几种算法都出现不同程度的部位丢失的情况;2)HLNet采用的是层级结构,综合考虑了不同层级上的解析效果,因而在解析人体背面图像时,依然能够正确地区分肢体的左右位置关系,如第3行样例所示。

图6 不同层级上解析结果Fig.6 Parsing results on different scales
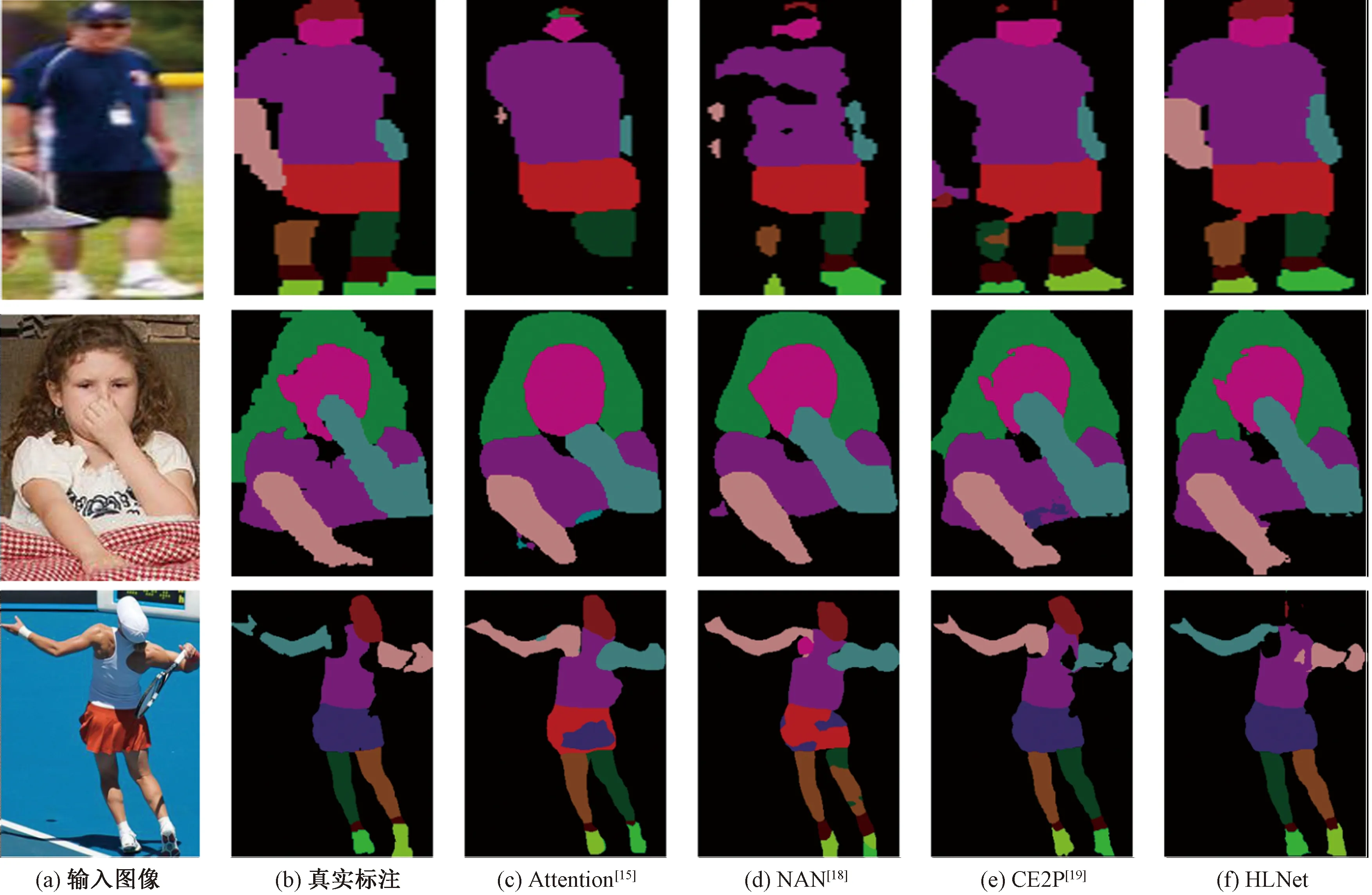
图7 不同算法在LIP 数据集上解析结果的可视化Fig.7 Visualized parsing results predicted using different algorithms on the LIP dataset
4 总结
本文提出一种基于层次化标签的卷积神经网络HLNet,用于人体解析任务。通过层次化的标签监督、特征金字塔池化以及不同层级之间的特征融合,网络能够充分利用人体各个部位的场景信息,并建立起卷积神经网络与现实生活中人类分层观察事物的习惯之间的联系。在LIP数据集上的实验表明,本文方法优于当前其他基于卷积神经网络的方法,具有较强的实际应用价值。
然而,由于本文方法属于基于大数据驱动的方法,数据集中存在的不同类别图片数量不平衡和小物体标注不精准的问题直接影响最终的解析效果。尽管本文采用的加权交叉熵损失和加权采样的策略,不同类别之间仍然存在明显的性能差距。因此,未来还将进一步考虑如何构造新的模块和监督学习方式以增强网络的小样本类别学习能力。
