抵御控制流分析的程序混淆算法
2020-11-17乐德广龚声蓉
乐德广,赵 杰,龚声蓉
(1.常熟理工学院 计算机科学与工程学院,江苏 常熟 215500; 2.苏州同程网络科技股份有限公司,江苏 苏州 215123)
0 引 言
为提高程序清晰度和执行效率,程序员们大量使用如if-then-else、switch-case等分支语句,或while、do -while、for等循环语句编写程序[1]。由于这些编程语句具有结构化特点,因此程序的控制流是可归约的,可以通过控制流分析将程序反编译成高级语言。近年来,程序控制流分析成为软件分析的研究热点,许多学者提出了基于符号执行、程序切片和形式化推理等的程序控制流分析技术[2],大大提升了程序控制流的完整性和准确性。利用控制流分析技术可以有效地分析程序结构和行为,给程序安全带来巨大的威胁。为保护程序,许多学者和研究机构对此进行了大量研究,提出了控制流完整性防护[3]、控制流异常检测[4]和控制流混淆等各种程序安全保护方法[5]。其中,控制流混淆常用的策略有计算混淆、次序混淆和聚合混淆[6]。例如,在计算混淆中,插入非透明谓词,增加程序中的条件判断表达式,以此来隐藏真实的程序控制流信息[7]。在次序混淆中,通过控制流平展化打破控制流中结点之间的相关性,使逻辑上相互依赖的结点空间上不相邻,且攻击者很难恢复出原始程序结点的执行顺序[8]。此外,文献[9,10]利用机器学习中分类器的内部规则难以被提取和理解这一特性,分别将随机森林和人工神经网络用于混淆程序的路径分支,将逆向分析路径分支信息的难度等价于抽取分类器内部规则的难度。由于控制流混淆相对于其它两种控制流保护技术具有更好的安全性,是当下程序混淆领域主要的研究热点。
在控制流混淆中,程序的控制流分析复杂度很大程度上依赖于程序中的分支路径。因此,对程序控制流混淆的一种有效方法就是增加程序中的分支路径。本文通过二态非透明谓词插入不相关分支路径和不相关结点,使得原程序控制流的分支路径和结点信息被破坏掉,增加程序控制流的复杂度。此外,为了进一步加强程序混淆的强度,利用switch-case平展化二态非透明谓词控制流。同时,采用GetSt调度函数动态赋值算法强化平展控制流的分支变量。在此基础上,提出了一种程序制流混淆算法。与现有控制流平展化混淆存在控制流结点单一且它们之间的分支路径顺序固定相比,该算法不仅增加控制流分支路径和结点类型,使分支路径复杂化,而且分支路径的执行顺序动态化,进一步隐藏程序的控制流信息。测试结果说明该算法能大大增加混淆强度,并有效抵御控制流分析。
1 控制流安全性分析
程序控制流是其内部逻辑关系的执行路径表示。控制流分析通过构造程序的控制流图分析程序的执行结点,以及由执行结点所组成的分支路径,来生成程序的控制流信息。其中,控制流图中的结点称为基本块,它是程序的一段指令序列且按顺序执行。每个基本块只有一个唯一的出口和入口,其中入口是基本块的第一条指令,可以是程序的第一条指令、无条件跳转的目标指令或条件跳转的下一条指令。出口是基本块的最后一条指令,其一般为程序的结束指令、跳转指令或跳转目标指令的前一条指令。然后,通过路径可达性推理得到程序行为同外部执行环境的输入之间的依赖关系。这些依赖关系可被攻击者用于程序反编译破解、隐私数据窃取和程序算法重构等,对程序安全运行和知识产权的保护构成严重威胁。
控制流图是程序编译器用于寻找编译优化可能以及分析程序安全性相关技术的研究基础,因此程序的反编译可以建立在控制流图分析的基础上进行。文献[11]利用函数定位切分识别函数块依赖关系,从超汇编指令集中产生粗粒度控制流图,接着结合中断标记点处理机制实现对代码执行路径可知,并建立精确的控制流基本块,最终完成以实际控制流引导的程序反编译逆向破解。
由于程序控制流结点的数据流信息会关联用户隐私数据,文献[12]提出一种基于协同式逆向推理近邻路径的控制流分析方法。通过构建程序的控制流图对程序控制流图的循环节点进行处理和静态单赋值来分析用户隐私数据等敏感数据流。从控制流图的出口节点开始逐步迭代到起始节点,结合后置条件和节点的执行语义计算其最弱前置条件。在最弱前置条件信息的引导下利用后向符号分析生成与目标后置条件近邻的路径集合。在此基础上,通过对控制流执行路径的比较识别不可行的近邻路径条件,构建程序的行为轮廓并进一步分析程序的行为特征。
程序的控制流信息包含着程序指令的执行轨迹和程序算法。在程序控制流未被混淆的情况下,程序指令与程序算法的控制流图相同。对于同样的输入,程序算法与指令代码的执行轨迹一致。文献[13]通过提取和分析二进制程序指令的读取过程,进行原始二进制程序指令控制流的构建。另外,原始程序的二进制指令执行过程包含着数据的处理过程,通过对程序指令执行过程中的数据流信息进行整理分析,能够得到程序输入、输出数据之间的运算关系,最终重构出程序算法。文献[14] 在控制流分析基础上,对存在敏感调用的路径约束求解路径条件。最终求解出具体程序行为及触发条件,识别应用程序敏感行为,揭示出程序行为的执行全过程。
因此,通过对控制流分析与利用,引起程序的破解和盗版、隐私数据泄露和知识产权窃取等安全问题。
2 本文程序混淆算法
根据第1节的控制流安全性分析,针对应用程序的保护,最重要的就是如何有效抵御程序控制流结构的恶意分析。为此,本节在基于控制流混淆技术的研究基础上,结合二态非透明谓词插入不相关控制流及控制流平展化,提出一种新的控制流混淆算法,并针对程序特点通过调度函数对该算法做出改进。下面以一个函数为研究对象,图1左侧的代码为例来阐述本文算法,其原始的控制流如图1右侧所示。
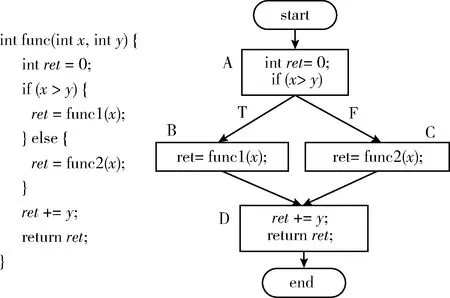
图1 原始函数及其控制流
2.1 二态非透明谓词
二态非透明谓词P是程序中的一种布尔表达式,该表达式的输出对混淆者而言,其输出结果已知,但是对破解者却难以获知。根据二态非透明谓词的输出结果不同,可分为3种类型:如果P在程序的输出永远为真(True,T),则记为PT,例如2|(x2+x) 表达式是一个总是为真的非透明谓词。如果P的输出永远为假(False,F),则记为PF,例如7*y2-1==x2表达式是一个总是为假的非透明谓词。如果P的输出有时为真有时为假,则记为P?,例如xmod 2=0表达式是一时真时假的非透明谓词。在控制流混淆中,基于二态非透明谓词插入不相关分支路径,如图2所示。

图2 不同类型的非透明谓词
图2中实线表示程序执行时,该路径有时会执行的控制路径。虚线表示程序执行时,实际上并不会经过的控制路径,称为不相关分支路径。因此,通过向程序的控制流图中插入非透明谓词,并构建不相关的分支路径,可以提高攻击者还原控制流结构的难度。使用图2(a)中的类型来对原始控制流进行混淆。首先,在原始的控制流图中根据后继基本块的唯一性分析非透明谓词插入的合适位置。然后,根据随机插入混淆策略插入非透明谓词及其不可达路径后的不相关基本块混淆原始控制流。在图1示例的基本块C中添加恒真的非透明谓词使其变成基本块C′,其判断结果永远为真。真的情况的分支路径后连接其原始的基本块D,假的情况的不相关分支路径后插入一个不相关基本块E。最终,形成如 图3 所示的控制流。
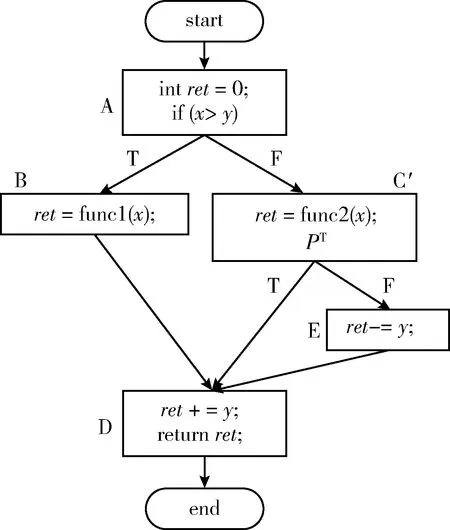
图3 非透明谓词混淆后的控制流
2.2 控制流平展化
控制流平展化是通过去除控制流图中的各种分支结构和嵌套结构,使所有的基本块都处于并列位置,拥有相同的前驱和后继来达到混淆程序控制流逻辑关系的目的。首先,将程序拆分为多个基本块,通过基本块中的转移指令确定基本块之间的跳转关系构建有向边,并由基本块和有向边组成程序的分支路径,如图1所示。然后,将这些原本属于不同层级的基本块放到同一层级。接着,将所有基本块封装到一个Switch选择分支中,使得分支路径的位置是动态确定的。最后,用一个分支变量St来引导接下来要实际执行的分支路径,进行逻辑顺序控制。将图1的控制流图平展化后如图4所示。
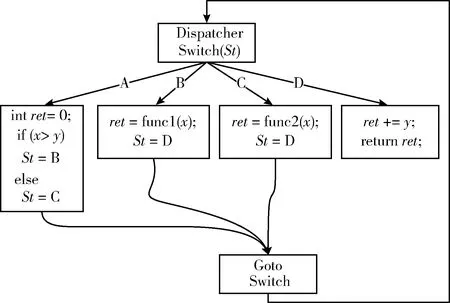
图4 平展化后的控制流
从图4可以看出,程序控制流的分支路径可以通过分支变量St载入地址而不是直接跳转地址,这个分支变量可以称为调度变量。这样在每一个基本块中通过计算St的值后,才能确定下一次跳转到哪一个分支路径。使得每一个基本块没有分支路径目标地址及执行顺序。因此,基本块的放置位置不必遵循执行的顺序,每一个基本块都可能是其它基本块的后继,从而隐藏了基本块的分支路径顺序信息。
2.3 改进的控制流混淆算法
本小节结合控制流平展化进一步对非透明谓词插入不相关控制流进行混淆,算法过程如下所示:
步骤1 非透明谓词插入不相关控制流混淆。根据2.1节,通过二态非透明谓词进行不相关基本块的插入,构造分支路径插入控制流变换,使得原程序的控制流信息被破坏掉。其中,非透明谓词采用Hui Xu提出的抗符号执行的非透明布尔表达式进行构造[15]。在混淆时,根据插入位置的上下文随机使用PT和PF中的一个。
步骤2 定义基本块类型。标记不同基本块(basic block,BB)的类型属性(type attribute,Attr),包含N和I两种基本块。其中,N基本块为混淆前原程序控制流图中的基本块[16],非透明谓词混淆中插入的不相关基本块为I。
步骤3 定义基本块三元组。标记不同基本块的三元组路径信息,其由自身基本块(block of self,BS)、前驱基本块(block of previous,BP)和后继基本块(block of next,BN)构成[16]。其中,BN的路径数量可能0、1或者2。当后继基本块路径个数为2个时,使用一个布尔值分别标记两种不同的分支路径情况。当后继基本块路径个数为1个时,使用恒为真(T)的布尔值标记对应的单分支路径;当后继块路径个数为0个时,则无需用布尔值标记分支路径。当没有前驱或后继块时,则把对应的标号设置为空,如图5所示。
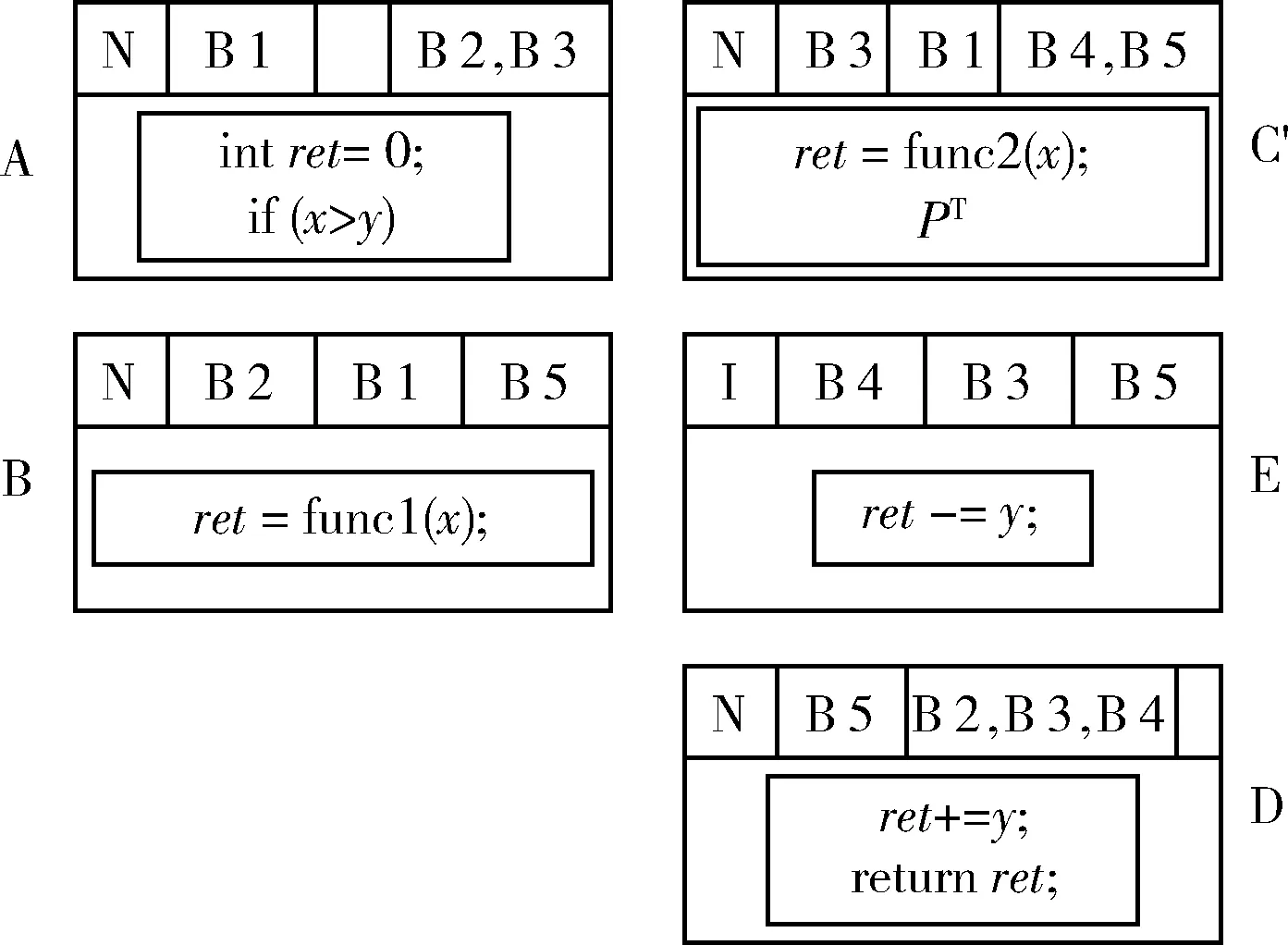
图5 基本块三元组
步骤4 非透明谓词插入不相关控制流平展化。根据2.2小节,创建一个switch-case的分发器结构将程序控制流图进行平展化。在平展后的控制流图中,每个分发结点由一个基本块构成,表示一条分支路径,则设每个基本块的分支路径为St,程序会根据St的不同初始化参数值运行不同的初始分支路径。根据步骤3定义的三元组,使用基本块的自身标号BS作为分发结点的执行路径,后继块标号BN作为下一个分发结点的执行路径,则平展后的控制流如图6所示。
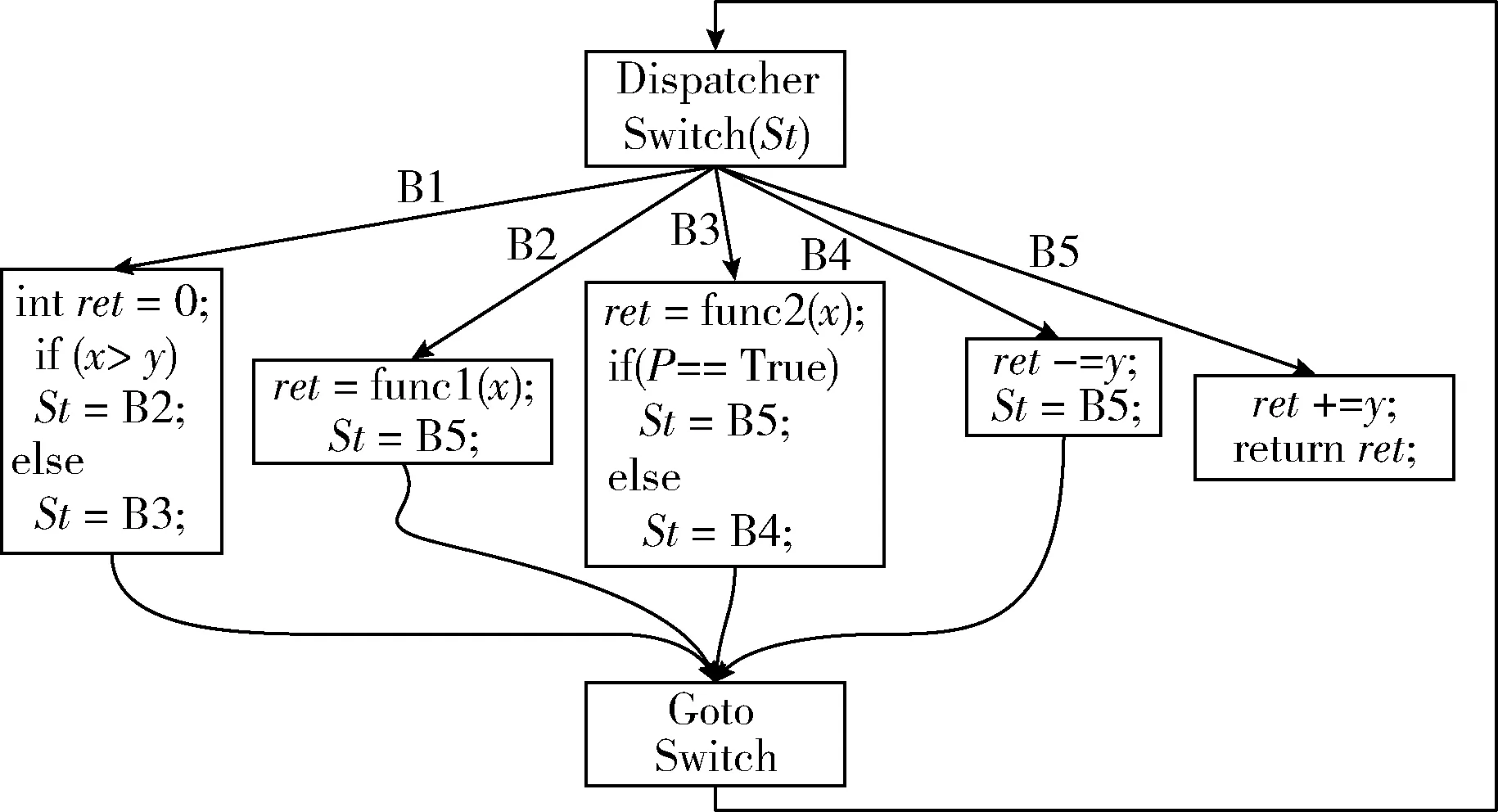
图6 非透明谓词插入不相关控制流进行平展化
步骤5 动态赋值分支变量St。定义一个GetSt(Boo-leanb,Stc)调度函数,其中b表示当前基本块的BN布尔值,c表示当前基本块的St值,则下一个的St分支路径值将通过当前基本块的BN布尔值(Boolb)、St值(Stc)和基本块类型属性(Attr)动态生成。其中,当基本块的BN为2时,则把对应的布尔值(F,T)传入b,当BN为1时,把布尔值T传入b,如图7所示。
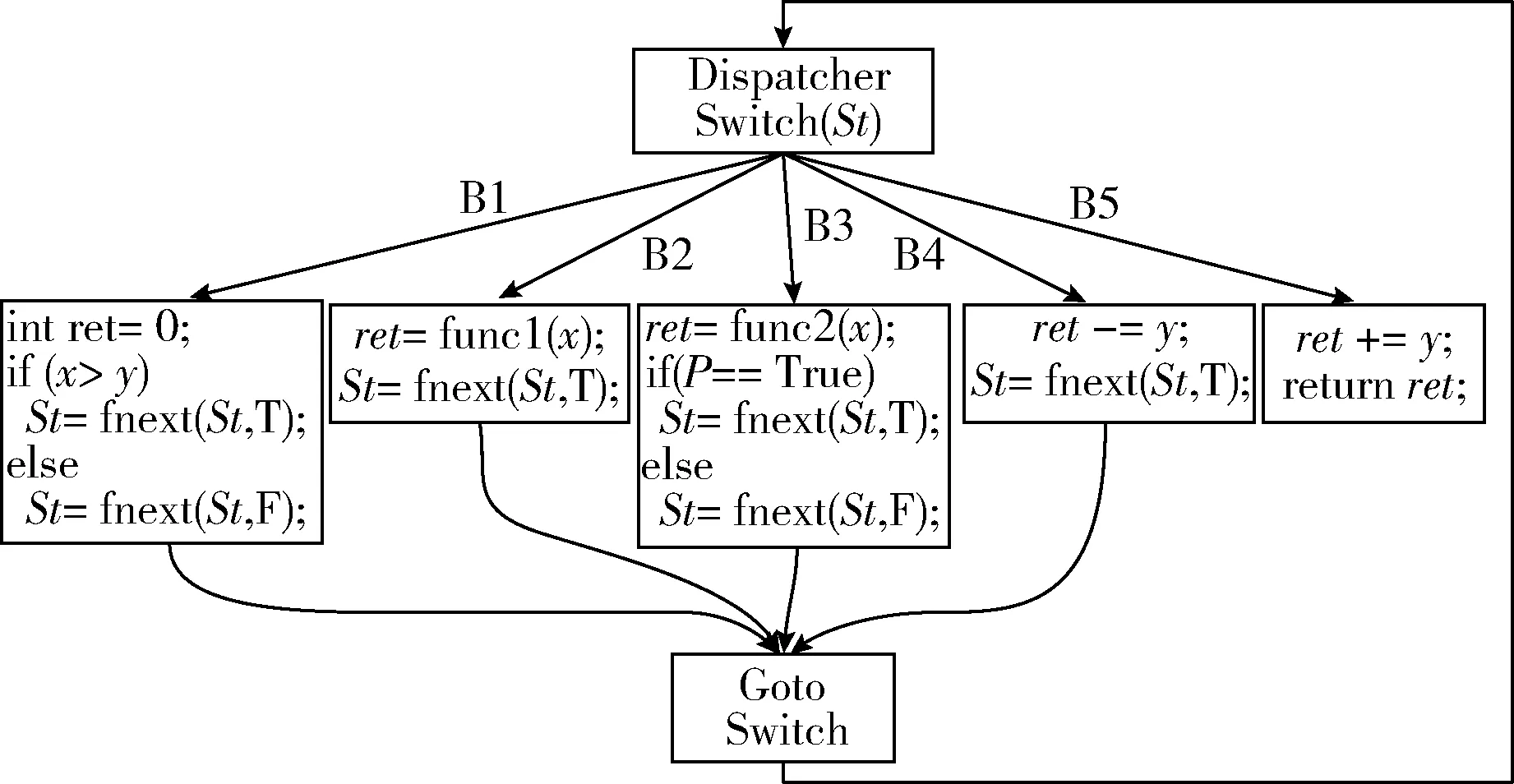
图7 混淆St分支路径
步骤6 GetSt算法。在图7的St分支路径混淆中,GetSt算法将通过控制流图中的基本块类型属性和三元组路径信息实现。GetSt算法规则描述如下:①下一执行基本块由当前执行基本块的路径位置三元组确定;②下一执行基本块的类型由其Attr确定。③原始基本块N的执行与否与原始逻辑一致。④不相关基本块I不被执行,则定义随机被算法返回。根据以上规则描述,GetSt调度函数动态赋值算法的伪代码实现如下。
St GetSt(Booleanb,Stc) {
Std;
intr;
BB=BN(b,c);
if (BB->Attr==N){
d=BB->St;
}else if (BB->Attr==I){
r=rand()%2;
if (r==0){
d=BB->St;
}else{
d=GetSt(BB->St,b);
}}else{
raise an exception;}
returnd;}
从以上伪代码可以看出,首先定义St分支变量d用于动态赋值。然后调用BN(b,c)函数,该函数根据GetSt传入的BN布尔值和St值得到一个新的基本块BB。接着,根据基本块BB的类型属性Attr值分析该基本块执行与否,并将BB的St值动态赋给d。如果基本块BB的类型属性Attr为N,即BB->Attr==N,则直接将该基本块的分支变量值 (BB->St) 赋给d,即d=BB->St;如果基本块BB的类型属性Attr为I,即BB->Attr==I,则通过rand()随机函数计算生成1或0的随机数。当随机数r等于0时,将基本块BB的分支变量值 (BB→St) 赋给d,表示将执行不相关基本块I。当随机数r等于1时,则继续调用GetSt算法将BB的下一个基本块分支变量值 (GetSt(BB->St,b)) 赋给d,表示将不执行不相关基本块I。最后,返回d并执行d对应的分支路径。
3 测试与分析
本节根据Collberg提出的评价指标[17]分别对本文算法混淆前后的强度和性能进行实验测试与分析。其中,强度是指混淆后对代码理解的困难程度。性能是指混淆后由代码转换所带来的软硬件资源额外开销。
3.1 强度测试
首先,对本文算法的混淆强度进行测试,构造如下函数作为测试用例。
int Test(inta,intb,intc) {
intresult=0;
intmod=a % 4;
if (mod==0) {
result=(a|0xFFEE)*(b-2);
} else if (mod==1) {
result=(a|0xEEFF)*(c-2);
} else {
result=(c&0xBBAAFFEE)*(a+b);
}
result=result+mod;
returnresult;
}
按照第2.1小节描述的步骤对以上测试用例代码作混淆。首先,在 “result=(a|0xFFEE)*(b-2);” 之后添加非透明谓词,使用 “7*y2-1==x2” 作为非透明谓词表达式,该表达式永远为假,然后插入 “result+=(a&0xFFEEDDCC);” 作为不相关块。接着,在 “result=(c&0xBBAAFFEE)*(a+b);” 之后插入第2处非透明谓词表达式,使用 “prime1*((x|any1)2)==prime2*((y|any2)2)” 作为非透明谓词表达式,该表达式永远为假。其中,prime1和prime2为任意两个不相等的质数,any1和any2为两个不相等的随机正数,x和y可以是程序给的数,基于此构造 “(11*((a|5)*(a|5)))==(29*((c|9)*(c|9)))” 表达式,最后插入 “result+=(a&0xFFEEDDCC);” 作为第2处不相关块。经过上述混淆之后的代码如下所示。
int Test_OpaPred_Obf(inta,intb,intc) {
intresult=0;
intmod=a% 4;
if (mod==0) {
result=(a|0xFFEE)*(b-2);
if (7*a*a-1==b*b) {
result+=(a&0xFFEEDDCC);
}
}
else if (mod==1) {
result=(a|0xEEFF)*(c-2);
} else {
result=(c&0xBBAAFFEE)*(a+b);
if ((11*((a|5)*(a|5)))==(29*((c|9)*(c|9)))) {
result+=(a&0xFFEEDDCC);
}
}
result=result+mod;
returnresult;
}
接着,把以上代码使用2.3小节描述的算法作控制流平展混淆Test_OpaPred_Flat_Obf,并利用IDA控制流图生成模块构建控制流图,对比分析其混淆前后的控制流复杂度,分别如图8和图9所示。
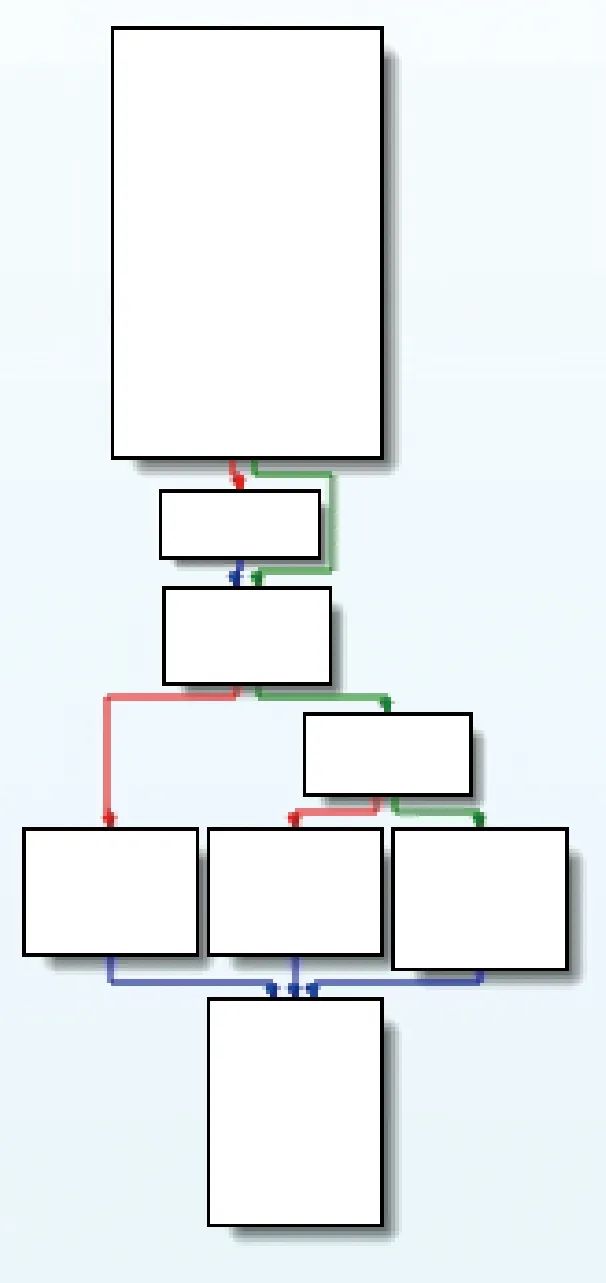
图8 测试用例原始控制流

图9 测试用例OpaPred_Flat混淆控制流
从图8和图9混淆前后的控制流图看,控制流被明显地展平化,达到了预期的效果。把测试用例Test()代码使用Obfuscator-LLVM混淆器使用“-mllvm-fla”选项做控制流平展混淆。混淆后的控制流如图10所示。
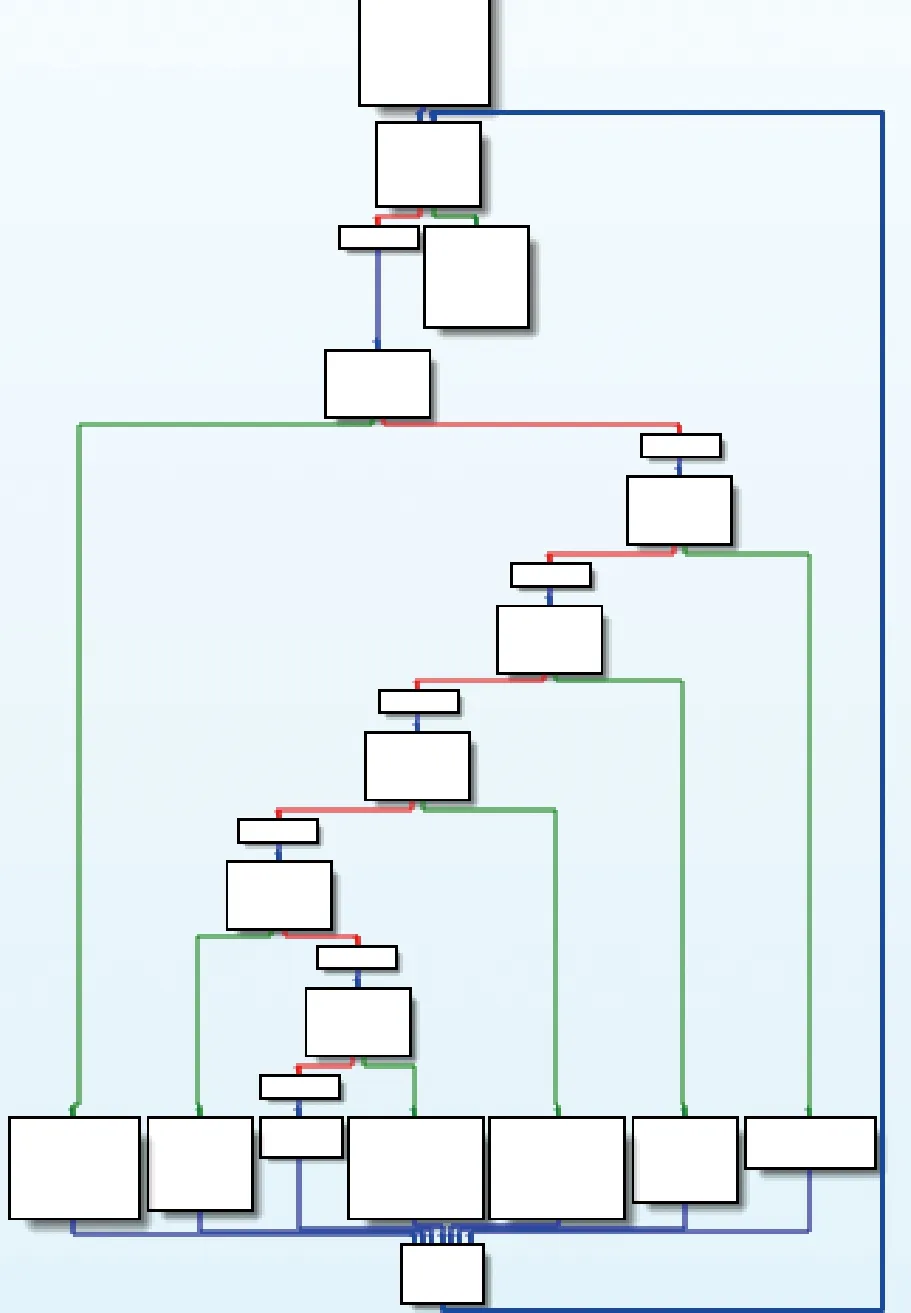
图10 测试用例Obfuscator-LLVM混淆控制流
从图9和图10的比较可知,本文控制流平展化方法较之于现有的OLLVM控制流平展化混淆效果有了较大的提高,能够对抗反混淆技术并给程序提供更高的强度保护。进一步使用IDA插件分析图8~图10的控制流复杂度,测试结果见表1。其中,e表示每个控制流图中边的数量,n表示每个控制流图中节点的数量,V(G)表示每个控制流图的循环复杂度(cyclomatic complexity)[18]。

表1 程序的控制流复杂度测试结果
从表1可以看到,混淆前Test的控制流循环复杂度是4,混淆后Test_OpaPred_Flat_Obf控制流循环复杂度大大增加达到16,相比混淆前其控制流循环复杂度增加了4倍。但是,对比Obfuscator-LLVM同样使用控制流平展算法混淆的结果,其循环复杂度只增加了1倍,达到优于Obfuscator-LLVM复杂度的效果。因此,通过控制流循环复杂度测试说明本文算法可以有效提升程序的混淆复杂度。
为了进一步测试程序的混淆强度,下面将对混淆前后测试用例的最大嵌套深度、语句数量和外部调用3个指标进行测试和分析[19],其中最大嵌套深度是根据测试用例中分支嵌套的层数进行计算,语句数量是指测试用例中语句数量,外部调用则根据测试用例中存在的外部函数调用个数进行计算。测试工具采用SourceMonitor,表2显示了测试结果。

表2 程序的强度指标测试结果
在表2中,混淆前Test的语句数量是10,而混淆后Test_OpaPred_Flat_Obf的语句数量增加到47,是混淆前的4.7倍。而混淆前后测试用例的外部调用数量分别为0和22,有显著的增加。此外,最大嵌套深度有从混淆前的2变为混淆后的5,也一定增加。以上SourceMonitor不同测试指标的测试结果说明,攻击者更难理解本文算法混淆后的程序,其强度比混淆前的程序更为复杂。
3.2 性能测试
本小节将测试分析程序混淆前后的性能,测试环境包括:CPU:Inter®CoreTMi5-4590 @ 3.30 GHz;RAM:8 G;SSD:256 G;OS:Windows 7旗舰版。首先,测试混淆前后的程序及内存使用大小,结果见表3。

表3 混淆前后程序及内存使用大小比较
从表3可以看出,混淆前Test的程序大小为11 k,混淆后Test_OpaPred_Flat_Obf的程序大小为19 k,混淆之后的程序大小相比混淆前增加72.7%,其增加的原因主要是混淆后增加了混淆代码逻辑和基本块的关系表。此外,混淆前后内存的使用从2704 k增加到2932 k,只有8.4%的增长率,这部分增量主要来自于混淆后调度函数动态赋值算法中所用到的基本块的关系表,平展后的基本块越多该表就越大,但相比于原程序的整体内存消耗,其所占的比例并不大。因此,采用本文方法混淆后的内存消耗对程序运行内存的性能影响仍然非常小。
其次,测试程序的运行时间性能,分别以1 000 000、10 000 000和100 000 000次计算混淆前后Test和Test_OpaPred_Flat_Obf的运行时间,并通过多次测试求得其平均单次运行时间,测试数据见表4。
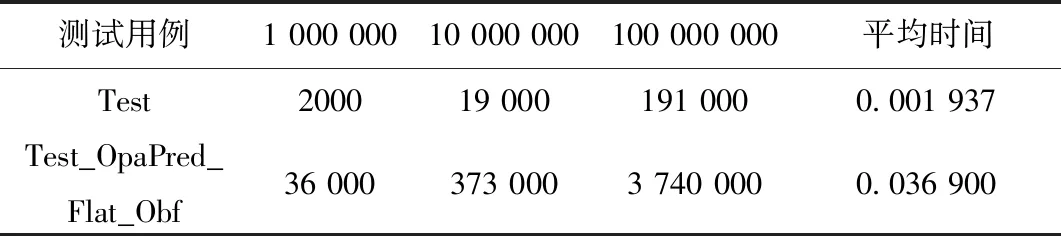
表4 混淆前后程序运行时间比较/μs
从表4可以看出,程序算法在混淆前的运行时间随着运算次数增加而线性增大,同时混淆后的时间增长仍然保持基本成正比的特性,并且两个测试用例随测试次数变化的增长率相近。从平均运行时间来看,其混淆前后的绝对运行时间依旧在很低的水平。
4 结束语
抵御控制流分析的程序保护已经成为了当今国内外软件安全研究的热点,其中如何提升程序的混淆强度也成为安全研究人员的重点研究课题。本文分析了程序所面临的控制流分析与利用,对程序在解析控制流图时容易被逆向编译和算法重构等安全问题,提出一种针对控制流图进行非透明谓词插入和平展化相结合的抵御控制流分析的程序混淆保护算法,并通过对混淆前后的测试用例进行控制流循环复杂度、最大嵌套深度、语句数量和外部调用的比较测试和分析。测试结果表明了本文算法在混淆强度方面的有效性。在性能测试中,当运行数据达到一定量时,对混淆程序的大小和运行时间性能会产生一定的影响,如何在提高安全性的同时,降低对大小和时间性能的影响将是在今后工作中进一步研究的内容,包括优化调度函数动态赋值算法的内部实现,提高其执行效率。
