一种新的基于网络爬虫的证券数据采集方法
2020-11-14卫锦
◆卫锦
数据安全与云计算
一种新的基于网络爬虫的证券数据采集方法
◆卫锦
(山西太原科技大学 山西 030024)
本文通过图像序列化和宏录制技术的结合,提出了一种通用的证券数据采集方法。这种方法具有很强的适用性和普适性,有助于满足使用者个性化数据的采集需求,同时对使用者有较低的使用门槛。
数据采集;证券数据;序列化;宏录制
人工智能对当今时代的影响越来越大,各个领域也越来越多地将人工智能技术应用到本领域中。对于人工智能技术来说,重要的前提之一是拥有足够的数据量,所以数据采集就成了人工智能技术中的重要内容之一。但是各领域中关于数据采集方法的讨论比较少,大部分有关人工智能的文章是关于数据挖掘方法的讨论。对于普通研究者,手中没有足够的数据,就没有办法进行下一步数据挖掘工作。针对此种情况,本文将以数据采集方法为研究内容,提出一种新的数据采集方法,虽然该方法在本文中针对的是证券数据采集,但是也可扩展到其他领域,具有一定的普适性。
1 人工智能时代对数据采集的需求
随着大数据、人工智能和区块链等技术的不断出现,各行各业对数据的需求越来越大。尤其是在人工智能兴起的时代,对数据规模的要求也越来越大,而常用的数据采集方法大多依赖于共享数据网站的 API 接口(如toshare)以及他人的数据分享,来源由他人控制,不能满足一些有个性化数据采集需求的使用者。同时,大部分数据共享或者数据分享需要一定的资金支持,对于一些在校学生或者普通的研究者来说存在一定的壁垒。为了弥补这些不足,破除研究壁垒,本文提出了一种新的基于网络爬虫的证券数据采集方法,并以具体实践论证该网络爬虫技术在证券数据采集中的可行性与实用性。该方法基于图像序列化的技术与鼠标宏录制技术的结合,并将结合后的技术创新的应用在证券数据采集工作中,取得了良好效果。
2 常用的网络爬虫技术
网络爬虫(又称网络蜘蛛、网络机器人)是一种程序或脚本,根据一定的规则自动获取万维网的信息。网络爬虫可以自动查取 Web 的超链接结构,定位和检索信息。它从网站的某个页面开始,读取网页的内容,在网页中找到其他超链接,然后通过这些超链接找到下一个网页。不断前进,直到互联网上的所有网页都被抓取[1]。
通常意义上的网络爬虫是通过爬取html页面内的内容来采集数据的,而这种方法需要对网站结构,相应的爬取技术以及编写语言都有一定的了解才能够做到,需要大量的学习、测试,需要使用者花费大量的时间精力。而本文提出的爬取技术脱离于网站结构,从图像识别的角度出发,通过图像识别的方法爬取网页内容、数据,方法简单高效,具有一定的普适性和推广价值。
3 图像序列化的定义及步骤
图像序列化是指将图像数字化的过程,图像通过序列化能够将图像的真实特征提取出来,配合滤波技术可以完整提取出目标信息,进而可以获取图像中感兴趣的内容[2]。本文通过图像二值化来实现图像序列化,具体的步骤分为两步。
3.1 提取指定颜色
一般来说,图像中的很多信息是没有使用价值的,为了获取感兴趣的内容,需要将图像中除指定内容外的其他内容进行过滤。在本文中采用的方法是阈值分割法,通过阈值分割法将指定颜色之外的其他颜色过滤去除,并将剩余颜色二值化[3]。
具体二值化方法是将选定颜色的颜色值设置为基值 B,通过迭代阈值[4]的方法找到合适的阈值P,将[B-P,B+P]范围内的颜色设定为指定颜色,将其他范围内的颜色设定为非必要颜色。将过滤后图像中的指定颜色替换为白色(0),非必要颜色替换为黑色(255)。如图 1 所示。
对于本文所处理的彩色图片,颜色值的计算方法是将原图中的选定颜色的 RGB 三通道颜色分量相加。
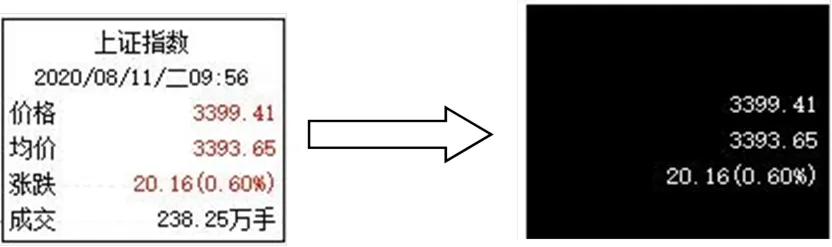
图1 提取指定颜色内容
3.2 将二值化后的图片序列化
网页制作时,显示的字体在同一个内容中一般是统一的,如图1 中的数字的字体。并且每个字符所占宽度、高度是相等的,所以可以用一个固定长宽的像素矩阵代表一个字符,故可用如下方法将二值化后的图片序列化。
如图2所示,图像为一个 4*6的像素矩阵,将其中二值化的像素矩阵序列化。序列化方法为,黑色取值为0,白色取值为1,图例中序列化结果为 011010011001100110010110。将序列化后的结果与图形库中已有的序列进行对比,如果图形库中存在则可判断出该字符的内容。如图2中所示示例,如果图形库中已经存在了 011010011001100110010110 序列,并且该序列代表的数字是0,则可判断出该二值化像素矩阵代表的字符为0。

图2 4*6二值化像素矩阵
图形库的更新依赖于使用者更新,需要使用者手动添加常用字符。对于证券数据采集的使用者来说,由于需要采集的数据大部分是一些数字,所以图形库添加的内容相对较少,方法复杂度也相对较低。
4 宏录制爬取网页数据
宏录制指的是将常用的操作存储下来,方便重复执行。宏录制的特点是可以通过录制一段宏来减少重复工作的工作量。大部分编程语言均可实现鼠标移动等功能,本文采用的方法是通过 python 语言中的pymouse模块中的 move 功能实现。
4.1 通过鼠标移动宏录制确定提取内容
证券数据采集的特点是经常需要采集一段时间内的数据,而网页数据特点之一就是可以通过鼠标移动来切换需要采集数据的时间。如图3所示,通过鼠标的移动,可完成不同时期证券数据的切换,从而实现采集数据的更新。大部分证券数据都有类似特征,都可以通过鼠标移动来更新数据内容。所以该特点在证券数据采集中具有一定的普遍性。
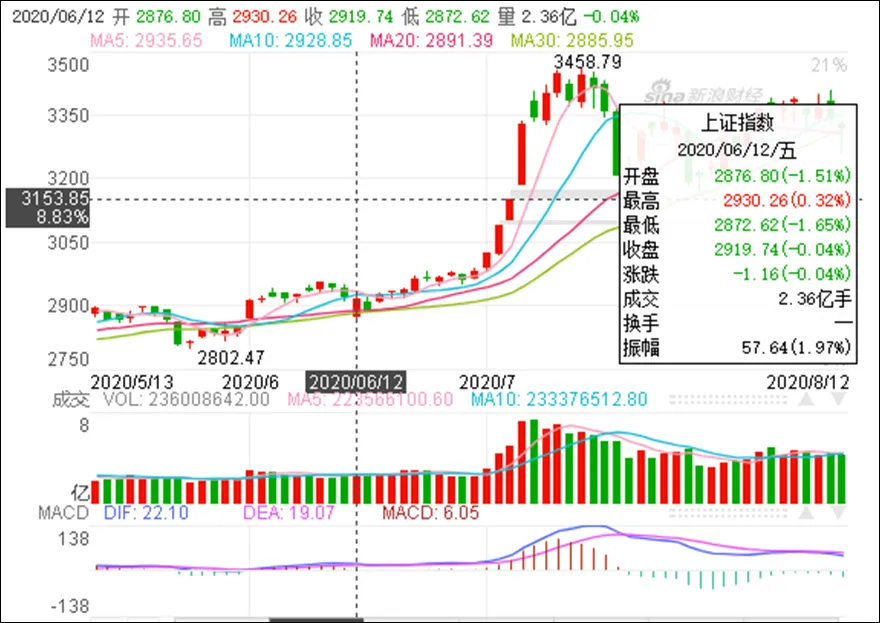
针对证券数据的特点,可根据采集数据的要求,通过录制鼠标移动的距离,结合图像序列化来提取相应一段时期内的证券数据。具体方法为,(1)测试并记录下能够实现数据更新的鼠标距离 d;(2)记录需要爬取的鼠标初始所在位置(x,y);(3)调用 move(x+d, y),实现鼠标的移动;(4)将更新后的图像通过图像序列化提取相应内容,将结果保留在对应的数据文件中。重复(3)(4)两步即可实现数据的连续采集,从而采集出使用者感兴趣的数据内容。
本文用上述提到的方法采集了为期1 年的证券数据,数据采集过程花费时间约为1小时,部分采集数据如图4所示。经验证,全部采集数据正确。通过实际测试,证明该方法简单、有效、准确,有良好的采集效果,能够满足证券数据采集需求。
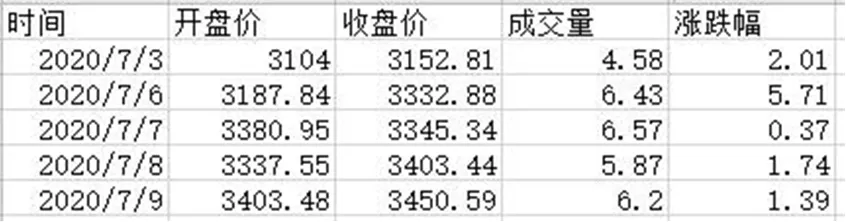
图4 爬取数据展示
5 总结
本文基于图像序列化以及鼠标移动的宏录制提出了一种新的证券数据采集方法,该方法与以往的网络爬虫方法不同,不依赖于网站提供的 API,也不依赖于 html 页面分析,而是从图像识别的角度出发,通过图像序列化后识别图像内容,从而采集数据。经测试,该方法简单、有效、准确,具有很强的适用性,有较低的使用门槛,有助于帮助研究者快速获取研究数据。同时,该方法具有一定的普适性,不仅适用于证券数据的采集,也可用于其他领域数据的采集。该方法的主要缺点是采集数据的速度较慢,需要花费一定的时间成本。另外图形库的添加有一定的复杂性,增加了该方法的操作量,对于需要采集大量文字性内容的使用者来说不适合使用。
[1]CHOJ.Crawlingtheweb:andmaintenanceof large-scaleweb data[J]. discovery,November,2001.
[2]贾锈闳.基于深度学习的低质量文档图像二值化算法研究[D].湖北工业大学,2020.
[3]党文静.图像区域分割算法的研究与应用[D].安徽理工大学,2018.
[3]杨培,陈沿锦,等.一种改进的快速迭代阈值选择算法[J].青海大学学报,2018,36(03):34-39.
