基于标记语言的跨平台并行编程框架设计①
2020-11-13唐佩佳钟旭阳
唐佩佳,徐 云,钟旭阳
1(中国科学技术大学 计算机科学与技术学院,合肥 230027)
2(安徽省高性能计算重点实验室,合肥 230026)
并行计算是目前主流的提高计算机系统计算速度和处理能力的一种有效手段,可将原有的串行程序改造为并行程序来解决性能问题,充分利用并行计算技术提高数据处理能力.而串行程序并行化的过程需要专业的并行编程能力,需要大量的工程成本.同时,随着各种并行计算平台数量的增加,并呈现出多样化,需要保证并行程序有一定的跨平台性,使得并行程序可在多个并行平台上跨平台运行.然而,不同的并行计算平台的硬件、所适用的并行模型和运行时环境都各不相同,这对程序的可移植性提出了严峻的挑战.
串行程序并行化的工具或系统可以分为两类:一类是采用专用编译器等自动并行化工具直接将串行程序自动并行化,编译器开发成本较高,而并行效率不高.比如斯坦福大学的SUIF 编译器[1]和Mathews 的ACP编译器[2],为了保持原有串行程序语义,导致编译器的策略非常保守,实际效果不太理想.其他工具例如Cetus[3]、Par4all[4]、Pluto[5]仅可实现循环级别的并行,不支持任务并行.S2P[6]虽然提供了任务级并行,但其并行粒度没有优化.现有自动并行化工具支持的并行平台较少,仅仅包括共享存储平台的少数系统和少量异构平台.另一类是采用加编译制导的编译器或并行编程框架,对串行程序进行辅助标记来实现并行化.
常见的并行编程平台主要有共享存储和分布式存储两类.共享存储平台下,OpenMP 采用在串行程序中添加并行标记语句的方法来实现并行化,这种方法会产生较好的并行效果但需要一定的标记工作量,系统好坏取决标记方法和工作量的大小.Blumofe 提出的Cilk/Cilk++[7,8]是一种基于C/C++的多线程并行编程模型,是在原有C/C++的基础上提供和并行相关的制导标记,实现任务分解和并行.Habel 等[9]实现了一种基于标记的分布式并行编程框架的设计,该框架提供了数据来源和分布的标记,通过源到源编译器将标记解析为并行程序,但该框架仅支持矩阵密集型的科学计算.分布式存储平台下,MPI 并行编程模型采用消息传递机制完成并行计算和同步通信;以FORTRAN90 为基础的HPF[10]并行编程模型,通过制导语句实现数据并行制导和数据映射制导.Sourouri 提出的Panda[11]异构并行编程框架可将带标记的串行代码转化为MPI或MPI+CUDA 并行代码,但该框架缺少运行时系统.
同时支持共享存储和分布式存储的并行编程框架不多见,这些系统和框架往往与应用任务特性相关或一些特定并行编程模型相关,实现或生成的并行程序效率也是一个问题.Liu 等[12,13]提出了一个基于任务和管道(TNC)模型的并行编程框架.应用程序分为主程序层和任务实现层.主程序层与平台无关,框架提供定义和启动任务和管道的接口;任务实现层与平台相关,具体各类型任务和管道由平台相关编程方法实现,框架再将任务和管道封装,管道负责各任务间的通信.应用程序主程序层可以保持不变,任务实现层根据不同目标平台调整,从而提高并行程序的维护和可移植性,但该方法在分布式环境下通信开销较大.Kutil[14]提出了基于面向对象的C++的编程框架,支持共享存储平台和分布式存储平台.该方法将矩阵运算分解为无通信的子运算,由框架负责具体的数据通信,但该方法的并行化设计仅针对矩阵运算领域,无法扩展到其他计算任务.
为了解决上述问题,本文提出了一种基于标记语言的三层并行编程框架.我们对共享和分布式存储编程平台的基本并行特性进行抽象,提取各并行编程平台并行程序的基本结构和共同点形成跨平台的标记语言.实现了二个层间转换过程,一个是串行程序层到并行中间代码层转换,采用对串行程序进行并行标记得到有并行语义的程序代码;另一个是并行中间代码层到目标并行编程语言程序层转换,采用对并行中间代码进行解析映射的方法,辅助并行编程框架实现目标并行平台的并行程序转换.
1 框架总体结构
1.1 框架的层次模型
为了使框架结构清晰,设计了一个跨平台的分层并行编程模型,共有3 层,分别是:上层、中层、和下层.如图1所示.

图1 编程框架的层次模型
上层是用户的串行程序层,是平台无关的.中层是与串行程序对应的、带有制导标记的中间代码,有并行语义但与平台无关.下层是目标并行编程语言程序层,可在并行计算执行模型上运行,与平台相关.
并行计算执行模型主要包括:成熟的通用并行计算执行模型,例如Pthread、OpenMP、MPI 和CUDA、OpenACC 等;特殊应用并行编程模型,例如Vxworks下多任务并行编程模型.
底层硬件平台主要包括共享存储多核CPU 平台、分布式存储Cluster、异构GPU 三种类型.
1.2 框架处理流程
利用框架将一个串行程序实现并行化的流程如图2所示.首先输入选择待转化的串行程序文件,进入第一个层间转换阶段:在串行程序定义的位置添加并行标记或者在需要并行参数寻优和同步控制等功能的位置添加相应的标记,得到有并行语义的程序代码.然后进入第二个层间转换阶段:并行编程框架将逐一解析各并行标记,结合用户界面输入的目标平台参数,经过一系列映射过程后得到目标并行编程语言程序.

图2 编程框架的处理流程模型
2 跨平台并行化实现
对串行程序进行简单标记,再经过解析映射得到能够并行地在共享存储平台、分布存储平台和GPU平台等多种平台上正常运行的目标并行编程语言程序.主要研究基于标记的串行API 跨平台并行化方法,包括两个层间转换过程:(1)并行中间代码生成;(2)基于标记信息的解析映射.
2.1 并行中间代码生成
标记语言用于辅助并行编程框架实现目标并行平台的并行程序转换,是并行编程框架的重要组成部分.我们对多种并行平台语言的基本并行特性进行抽象,因此标记语言是一种可表示并行语义的跨平台标记语言,命名为Sigma 标记语言(以下简称标记语言).以简洁易用、功能齐备的指导原则,设计了类似OpenMP的三段式标记语言.标记语言的指令结构如图3所示.

图3 标记语言结构
标记语言共有5 类19 条,包括并行、辅助并行、性能、平台等类型的标记,标记语言与平台无关.
本文研究的工程背景是雷达数据处理.以雷达数据为代表的此类工业数据有以下几个特点:
(1)数据规整.每个数据包都有固定的大小,包含多批固定长度和类型的数据.
(2)数据独立性.各个数据包彼此独立不相关,可以单独处理,对有的处理过程,数据包的各批次数据可以被单独处理.
(3)周期性.每个数据包按固定周期到达.
针对上述数据特点,并行方式采用数据并行.并行标记设计为#sigma parallel_task [标记子句].
并行标记提供了数据并行所需要的信息,有4 个标记子句:
(1)src_data:提供串行API 输入数据源、数据类型和数据长度;
(2)dst_data:提供串行API 输出数据源、数据类型和数据长度;
(3)group:提供分组(批)数,即数据源可以划分为若干批或组来相对独立的处理;
(4)varlist:串行API 的其他参数.
采用对串行程序进行并行标记得到有并行语义的程序代码,即第一层间转换阶段.
在一个需要并行化的数据处理串行API 的定义位置添加并行标记得到并行中间代码,如图4所示.

图4 并行中间代码
2.2 基于标记信息的解析映射
采用对并行中间代码进行解析映射得到目标并行编程语言程序,即第二层间转换阶段.
用户在并行编程框架界面选择目标平台参数(硬件平台、操作系统和并行计算执行模型等)后,框架将2.1 中的并行中间代码进行解析映射可以得到目标平台并行语言编程程序.具体步骤如下:
(1)标记解析.并行编程框架将并行中间代码进行解析,得到标记提供的数据并行参数,如输入数据源srcname、输入数据源大小srcsize、输出数据源dstname、输出数据源大小dstsize、分批数num 和其他参数;
(2)标记映射.并行编程框架将并行中间代码映射为基于数据并行的目标平台并行语言编程程序,
框架对多种并行平台语言的基本并行特性进行抽象.以Pthread 多线程线程池并行编程模型和MPI 并行编程模型为例,展示共享存储平台和分布式平台的并行程序架构对比如表1所示.

表1 共享存储平台和分布存储平台并行程序结构对比
由表1可知,并行程序的主要结构包括数据划分和分发、调用原串行API、数据收集等部分.其他可用于数据并行的OpenMP 模型和Vxworks 系统并行模型等并行编程也满足类似结构.
因此,并行编程框架根据这个主体结构封装了多个目标平台下的基础并行代码段,主要用于并行初始化、数据分发和收集、并行计算执行等.这些代码段将使用上述(1)标记解析得到的并行参数.标记映射过程,即目标并行平台代码生成过程如算法1 所示.

算法1.并行标记映射算法输入:数据并行参数srcname、srcsize、dstname、dstsize、num 等,串行API 名称,numprocs 为并行处理单元数(共享存储平台的计算单元是线程,分布式存储平台的计算单元是节点进程);目标平台参数(硬件平台、操作系统和并行计算执行模型等).输出:并行代码.1)写初始化部分代码.主要实现并行初始化和临时变量定义,变量空间申请,框架根据不同的目标平台使用不同的并行初始化代码段.2)写数据划分部分代码.主要实现将num 批数据划分为numprocs份;划分方式有静态和动态划分两种,框架根据用户选择的划分方式调用不同的函数实现,函数参数将使用num 和numprocs.3)写数据分发部分代码.主要实现将数据分发到每个并行处理单元.共享存储平台使用自定义函数Data_trans,以传递存储地址实现,分布式存储平台的数据分发使用MPI 自带消息传递函数,以传消息实现.框架根据不同的目标平台调用不同的数据分发代码段,代码段将使用srcname 和srcsize 参数.

4)写数据处理部分代码.主要实现数据的并行处理.共享存储平台以线程方式调用串行API,分布式存储平台以进程方式调用串行API.框架根据不同的目标平台调用不同的并行计算执行代码段.5)写数据收集部分代码.方法与3)类似,主要实现收集各并行计算单元结果.框架提供的代码段将使用dstname 和dstsize 参数.6)写结束收尾部分代码.主要实现变量空间回收和并行环境结束工作.
算法1 的第2)步中的数据划分方式有静态划分和动态划分.静态划分是均匀划分,数据划分的块数与并行处理单元数相等.动态划分指的是根据并行参数自动寻优的结果来进行划分,并行参数寻优的方法见3.2.假设有4 个并行处理单元(共享存储平台的计算单元是线程,分布式存储平台的计算单元是节点进程)来处理一个数据集,两种划分方式如图5所示.

图5 数据划分方式示意图
划分后的数据是相对独立的,在数据处理过程中各并行处理单元之间没有数据交换和同步,不会出现数据竞争.对于某些有数据交换和同步需求的程序,参考fork/join 模型,将源程序中数据交换和同步部分保持不变,仍然采用串行执行,将剩余部分封装为一个或多个新的API,再对新API 进行并行化.原串行程序的可并行部分通过并行化提高了运行效率,不可并行部分实现了数据交换和同步功能,在保证原程序的总体功能实现的前提下实现了原串行API 的并行化.第4节中的副瓣对消计算实例即按此方法实现.
算法1 的第4)步中共享存储平台的多线程实现所涉及的并行计算执行代码段包括:Pthread 模型、OpenMP模型和VxWorks 系统并行模型,分别使用Pthread 线程池、OpenMP 多线程制导和VxWorks 多任务实现.
算法1 的第1)和6)步在全部并行计算完成前仅需执行一次,为了提高易用性,将算法1 的2)到5)封装为并行API 以供多次调用,同时保持并行API 和串行API保持参数列表的一致,增加了可读性.
针对GPU 平台并行程序的特殊程序结构,即host/device 混合编程模型,并行框架增加了面向GPU 平台的kernel 标记手段,可将kernel 标记解析映射为CUDA API 并行实现.
3 并行参数自动寻优
并行参数自动寻优的目的是帮助用户选择最优的并行参数,优化并行效果.并行参数包括线程数、节点数和数据划分比例等,综合影响因素和优化效果,共享存储平台和分布式存储平台分别挑选线程数和数据划分比例作为优化对象.使用并行参数自动寻优标记后,框架将会生成目标并行平台下的并行参数自动寻优程序.
(1)共享存储平台
框架可自动计算不同的线程数下程序的耗时,并择优确定最佳线程数.具体过程见算法2.

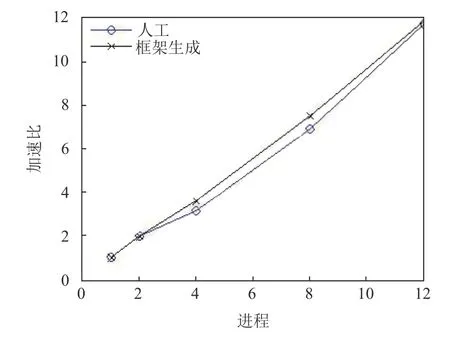
算法2.共享存储平台并行参数自动选优算法输入:线程数集合P=2:N,N 为物理核数,最小耗时初始值Tmin 初始化为最大值;输出:最佳线程数Popt;1)for each 线程p 属于P 2)统计多次并行函数运行平均耗时t;3)if t 标记使用方法:将标记#sigma auto_optization_SM_start 和#sigma auto_optization_SM_end 分别加在并行域的开始和结束位置即可. (2)分布式存储平台: 框架可自动收集同一个算例在不同的节点运行耗时后确定最佳数据分配比例,实现负载均衡.具体过程见算法3. 由节点耗时计算任务分配比例的公式如下所示: 其中,Ti是多次标准算例运行平均耗时,N是分布式存储平台的节点数,Li是节点i的任务分配比例. 由任务分配比例计算任务量的公式如下所示: 其中,W是待分配的任务总量,Wi是节点i所分配得到的任务量. 算法3.分布式存储平台并行参数自动选优算法输入:分布式存储集群有N 个节点,待分配的任务总量W,标准算例;输出:各节点的任务量w;1)for each node i 2)统计多次标准算例运行平均耗时Ti;3)收集其他节点的耗时Tj,j∈{1:N }但j≠i;4)通过式(1)计算节点i 的任务分配比例;5)通过式(2)计算节点i 的任务量;6)end for 7)return 各节点的任务量w; 标记使用方法:将标记#sigma auto_optization_DM 加在并行域的开始位置即可. 雷达信号处理是典型的工程应用,涉及大量的数学变换和矩阵运算,我们选取脉冲压缩、副瓣对消、雷达图像处理3 个处理过程来测试我们的并行框架. 首先,对并行框架的功能性进行测试,即考察并行框架是否能正确实现跨平台并行化. 以副瓣对消串行API 程序并行化为例.首先,对副瓣对消串行API 程序添加并行标记,选择目标并行平台为“共享存储多核平台-Linux-Pthread”和“分布式存储平台-Linux-MPI”后,并行框架对标记进行解析映射后,可以生成共享存储多核平台(Linux)上的线程池的并行程序和分布式存储平台(Linux)上的基于MPI 的并行程序.两个并行程序的运行结果和原串行程序一致,证明本文的并行框架具备跨平台并行能力. 其次,对框架生成的并行编程语言程序的性能也进行了测试. (1)共享存储平台 以脉冲压缩串行程序为例,对于框架产生的Pthread脉冲压缩并行程序,将并行度分别取2、4、8、12 时,即线程数分别取为上述值时,统计程序运行耗时.并行程序运行的硬件条件为:共享存储平台Intel(R)Core(TM)i7-8700K CPU @ 3.40 GHz,CPU 6 核12 线程,Linux. 由程序运行耗时计算的加速比如图6所示,由图可知,两种方式产生的并行程序均取得了较好的加速比,由于框架自动生成的并行程序的冗余代码较少,代码规范且执行高效,其加速比要略优于人工实现的并行程序. 图6 脉冲压缩并行程序取不同并行度时并行化加速比 (2)分布式存储平台 以雷达图像处理串行程序的并行化为例,对于框架产生的分布式图像处理并行程序,将并行度分别取1、8、16、24 时,即进程数分别取为上述值时,统计程序运行耗时.并行程序运行的硬件条件为:双AMD(R)Opteron 6168 处理器,每个处理器有12 个计算核心,Linux 操作系统. 由程序运行耗时计算的加速比如图7所示,由图可知,由并行框架生成的并行程序的加速比与人工实现的并行程序相当. 图7 图像处理并行程序取不同并行度时并行化加速比 我们设计了一种基于标记语言的上层(串行程序层)、中层(并行中间代码层)和下层(目标并行编程语言程序层)的三层并行编程框架.我们对多种并行平台语言的基本并行特性进行抽象,形成了一种可表示并行语义的跨平台标记语言.标记语言辅助并行编程框架完成了二个层间转换过程,实现了目标并行平台的并行程序转换,解决了串行代码自动跨平台并行化的问题,仅需一次标记,即可得到多个平台的并行程序.将框架应用于雷达数据处理程序并行化改造,实验结果表明,该框架可以生成目标并行编程平台的并行代码,且经过系统参数优化的并行代码加速比相当或优于人工实现的并行代码.


4 实验分析

5 结论与展望
