基于深度学习的视频多目标行人检测与追踪
2020-11-06徐耀建

摘 要:多目标检测与跟踪是当今计算机视觉领域中重要的子课题,因为当下摄像设备质量以及计算机科技水平的不断提高和使用成本的减少,相关技术的发展突飞猛进。文章通过对现有表现出色的目标检测算法YOLOv3进行调优,使其更适配于行人检测、目标跟踪算法Deep SORT以及Counting算法,以進行行人检测计数,实现一个基于图像处理的多目标行人检测与追踪的平台。
关键词:计算机视觉;多目标跟踪;YOLOv3;行人检测;Deep SORT
中图分类号:TP391.41;T18 文献标识码:A 文章编号:2096-4706(2020)12-0006-04
Abstract:Multi-target detection and tracking is an important sub-topic in the field of computer vision. With the continuous improvement of the quality of camera equipment and the level of computer science and technology and the reduction of the cost of use,the development of related technologies has made great progress. This paper optimizes the existing excellent target detection algorithm YOLOv3 to make it more suitable for pedestrian detection,target tracking algorithm Deep SORT and Counting algorithm,so as to count pedestrian detection and realize a multi-target pedestrian detection and tracking platform based on image processing.
Keywords:computer vision;multi-target tracking;YOLOv3;pedestrian detection;Deep SORT
0 引 言
随着人工智能产业的持续火热,计算机视觉逐渐成为较为活跃的研究领域,而多目标跟踪是其重要的子分支。其中的多目标行人检测追踪技术的主要目的是对视频内的行人目标进行分析以及轨迹追踪。本文针对本校“数字图像处理”课程进行深入研究,探讨目标跟踪性能的好坏受到所使用的检测算法、用于匹配区分的特征以及数据关联算法的影响,找到一种最适用于目标跟踪的算法,并在此基础上进行算法调优,使其能够在真实的场景中准确地进行行人检测和数量统计。
1 项目应用前景
如图1所示,多目标行人检测计数和追踪技术主要应用于交通网络实时监测(如行人流量估测等防线)、人机交互或视频监控设备、实时安防系统(安防系统早期依靠于传感装置进行,在引入目标检测和追踪技术后可以自动完成对行人的检测和轨迹追踪)和智能或无人车载系统(需要对车外的复杂行人环境及行人轨迹进行判断和行车规划,使车辆行驶脱离人为操作)等有益于人们社会生活的众多领域。目前其仍是计算机视觉中的研究热点,具有较好的发展和应用前景。
2 研究重难点综述
行人目标检测与追踪是计算机视觉领域的一个重要方向,由于其技术应用场景愈发复杂,如何优化算法性能来应对这样的复杂场景,是我们的重要研究目标。当前的复杂环境问题主要有以下几点。
(1)行人的遮挡问题,对于行人的遮挡可以大致的划分为行人的主动性和被动性遮挡,针对遮挡的情况可以划分为部分遮挡和完全遮挡,其中的完全遮挡可能会导致追踪目标和前期检测目标的不匹配并导致ID跳变,造成判断失误。
(2)行人的外观刚性形变问题,如果行人自身发生不确定的形变(动作或者行人重叠等变化),追踪行人的特征就会产生变化,导致低匹配的追踪失效。这个问题也可能由拍摄光线、摄像角度等因素引起。
(3)视频模糊/视频背景复杂问题,视频中行人的高速运动会导致行人的外观特征(如轮廓、纹理、边缘等)变得模糊,而造成追踪失效。同时,复杂的环境也对追踪算法的模型有着较高的要求。
3 概要设计
3.1 项目基本流程
行人目标检测与追踪的流程主要可以分为目标候选框提取模块、目标特征提取模块、分类器选取候选样本模块、下一帧目标位置的估测模块以及NMS处理模块,如图2所示。
其中目标候选框提取模块是针对输入的检测算法计算出的检测结果,确认目标样本候选框。
目标特征提取模块主要是选择合适的表达特征,并据此构建出特征模板用于后续的候选样本分析对比。
分类器选取候选样本模块是利用分类器对不确定的目标进行区分(因为行人移动较慢,所以仅在候选框有限距离内进行采样)。
目标估测模块是将之前的特征样本和候选样本进行比对,置信度高的即为目标的下一帧位置(NMS处理即为非极大值抑制,是为了去除置信度不高的多余候选框)。
NMS处理模块(Non-Maximum Suppression,非极大值抑制),对多个候选框,是为了去除置信度不高的多余候选框,得到最具代表性的结果,以加快目标检测的效率。
4 详细设计
4.1 目标检测算法选型思路
目标检测的主要目的是根据图像提取目标的位置以及类别,所以检测器的优劣也在一定程度上决定了目标跟踪技术的效率。目标检测一般分为以下三个部分。
(1)候选区域选定:这种方式主要是通过区域推荐(Region Proposal)的方式实现,这种方式的思路是利用滑窗遍历图像,结合分类器来判别滑过的区域是否存在目标。筛选后的区域即为候选区域,再结合特征进行进一步的檢测,但是这种方式无法自由缩放尺度,筛选任务较为繁重。
(2)候选区域特征提取:针对上一环节中的候选区域,我们需要结合上一章中所阐述的目标特征进行判别,利用深度学习算法对其进行回归分析。
(3)判定候选目标:根据特征的判别完成分类任务,结合类别分类器(例如SVM、Boosting等)识别和判定。
但是上述的流程中也存在着如下缺陷。
(1)通过滑窗确定的候选区域多为无效区域。
(2)目前的特征识别大多依赖于人工识别。
(3)人工识别的结果不能进行推广拓展。
为了能进一步优化这种方式,我们结合深度学习的方式对图像的深层特征进行提取以达到提高检测精度的效果,提出了基于区域的卷积神经网络(Region-based Convolutional Neural Network,R-CNN)的检测方式:其在候选区域的选择时使用的是选择性搜索策略(Selective Search,SS),切分图像时仅选择部分区域;再利用卷积网络(Darknet-53)提取深度特征,利用SVM分类器进行目标分类。同时为了进一步提高其处理效率,我们提出了Fast R-CNN(利用ROI池化层及Softmax分类器)来解决其执行效率的问题,但是仍旧不能够满足检测对实时性的要求。
YOLO系列算法将上述的流程统一到一个卷积网络中,这种方式放弃了传统的区域推荐网络(Region Proposal Network,RPN)策略,提高了执行效率。而YOLOv3则拥有目前YOLO系列的最高效率,其相较于之前版本主要有以下明显的改进。
(1)先验框(Prior Box)的数量从5个提升到9个,提升了IoU(平均交并比)。
(2)提高对小目标的检测力,YOLOv3的416版本应用了52个Feature Map(v2版本仅应用了13个),改进了其Detection策略,在整个Darknet-53中不同卷积层通道数均使用先减后增的方式。
(3)将Loss方式从Softmax转换为Logistic方式且每个Ground Truth只匹配一个先验框。
其相较于同属One-stage方法的SSD、DSSD方法依然具有很多优势,如下所述。
(1)不局限目标检测类别,只要大于设置的阈值均可检测。
(2)先验框设置的思想是均匀地将不同尺寸的Default Box分配到不同尺度的Feature Map上。
(3)Bounding Box的预测方法是对于位置偏移值再做一次Sigmoid激活,将其范围缩为0~1以保证预测有效。
4.2 目标跟踪算法选型思路
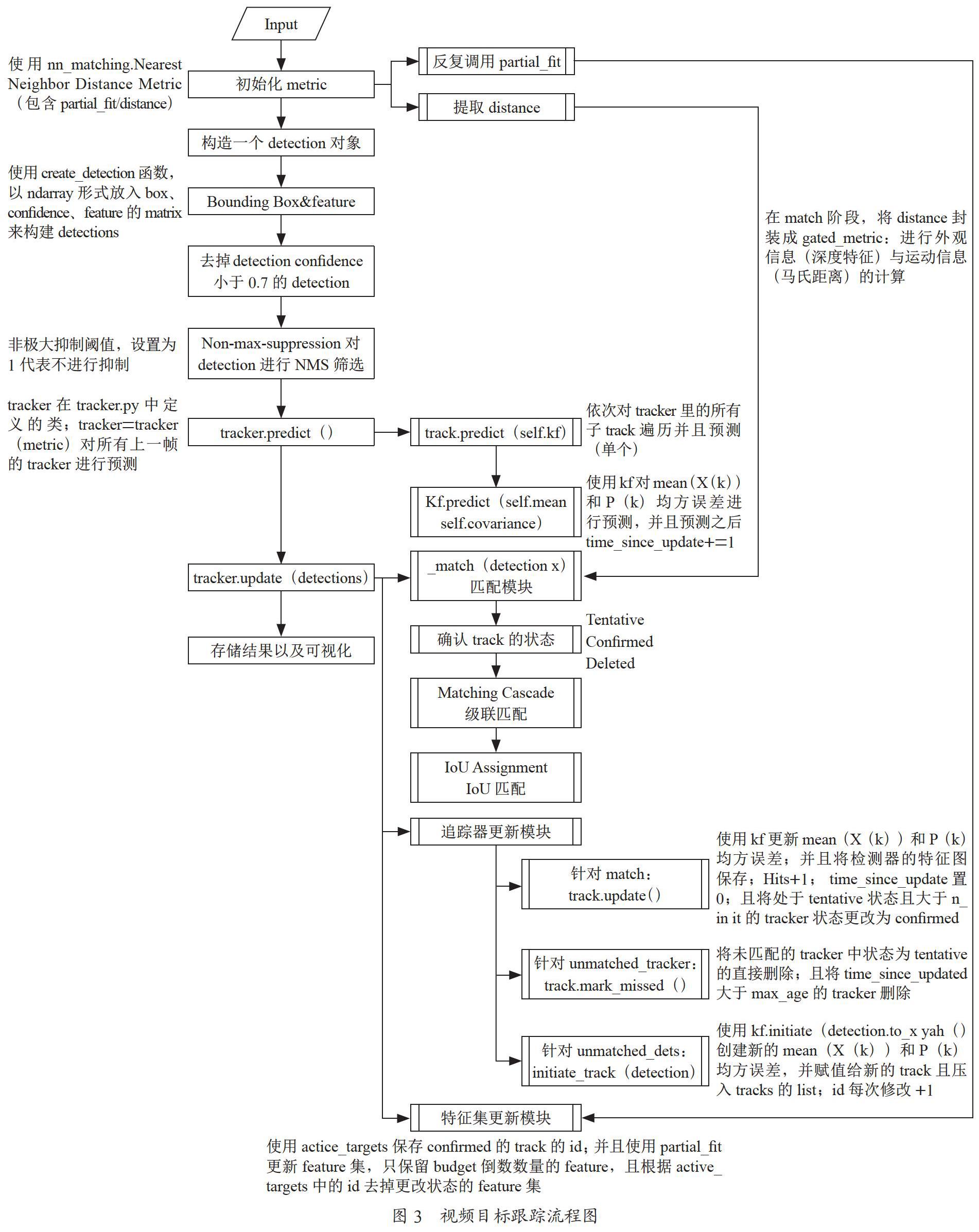
对于目标跟踪算法,我们仅针对多目标跟踪算法展开选型思路分析。本项目是针对视频中的行人目标的检测与跟踪,因为视频流是具有时间性和空间性的,如果对视频中的每一帧进行图像识别检测会造成计算的浪费,所以我们选择加入追踪使检测框更加稳定、输出内容更为平滑。视频目标跟踪主要可以划分为以下几个步骤,如图3所示。
目标追踪算法我们大致可以将其分为TBD和DFT两类,如果将其进一步地细致划分,可以划分为以下3类。
(1)基于多线程的单目标追踪器的多目标追踪算法,这种算法的代表性算法主要有KCF、LEDS等,这类算法的思路是对每一个目标分配一个追踪器,算法的追踪效果很好,但是算法对追踪目标的尺度变化要求较大且极耗CPU。
(2)以卡尔曼滤波器、匈牙利算法及KM匹配的后端多目标追踪算法,这种算法的代表性算法主要有SORT、Deep SORT等,这类算法依赖于检测的前期结果以及提取特征的区分程度,同时卡尔曼滤波和匈牙利算法可以极大程度地减少了ID跳变的次数。
(3)基于深度学习的端到端多目标追踪算法,这种算法的代表性算法主要有SST、MCSA等,能实现不错的跟踪效果,但是其目前还不够成熟。所以在本项目中我们选取了较为成熟的Deep SORT算法,并选取了较大型视频行人重识别数据集来训练特征提取网络模型。这种借助了深度特征和成熟追踪器的方式可以进一步提高追踪的效果,同时加上微调的行人目标检测算法,相信可以对整体模型有着一定的帮助。
4.3 实验结果分析
如图4所示,经过微调后的行人目标检测算法在针对行人的目标检测上已经可以实现不错的效果,如一般场景下的行人检测、多尺度的行人检测、密集行人检测。但是也确实存在着由于遮挡、模糊、过于密集等原因导致检漏的现象出现。
再结合特定的评价指标来对实验结果进行定量分析,我们选择Classification Accuracy作为正确性的评价标准,其评价类别有四种:目标为行人且检测为行人即为True Positive,目标为非行人但检测为行人即为False Positive,目标非行人且检测为非行人即为True Negative,目标为行人但检测为非行人即为False Negative。可以看出,YOLO系列算法作为One-stage类型的检测算法,其检测效果明显优于R-CNN与Fast R-CNN;同时针对行人进行微调的YOLOv3算法弥补了原本的YOLOv3算法类别概率的不足。同时,我们也可以结合对目标定位的精准度来对检测算法进行评估,通常我们采用IoU指标来判定检测的定位准确性。IoU是计算检测目标的真实区域与预测区域之间的重复面积,正常的YOLOv3算法的IoU可以达到68.12%,微调后的检测算法IoU指标有一定程度的提高,可达78.64%,表明其检测定位效果较为优良。这是因为我们选择了更加适配的先验框,同时在每一个网格上增加了候选框的数量,这样就可以更好地检测同网格的不同行人。
5 视频目标检测与追踪测试
多目标检测与跟踪算法的执行流程包括:给定原始视频帧、运行项目中的检测器、获取检测器得到的目标检测框、利用模型提取目标框中目标的表观特征/运动特征、进行前后两帧的目标匹配、进行数据关联并分配ID。其中检测器使用的是本项目的微调YOLOv3行人检测器、特征提取模型使用在行人重识别数据集上训练的128维特征、目标匹配使用卡尔曼滤波器进行预测和更新、数据关联部分使用加权匈牙利算法进行ID分配。
在测试视频中,我们监测了出现在当前画面的人数,统计了整个视频出现的人数,部分测试效果如图5所示。
6 结 论
在一个优良的检测器的基础上,为了更加平滑地输出视频的跟踪效果,我们选定了基于TBD的目标追踪算法Deep SORT,并融合深度外观特征模型提取目标特征,从而更好地解决之前SORT算法因为短暂重叠和长期遮挡所导致的ID跳变频繁的情况。
这种结合YOLOv3和Deep SORT算法的多目标行人检测和追踪算法可以在一定程度上提高对于行人的识别和跟踪准确度,但是其中也存在着一些待改善的问题。如视频检测的实时性还有待改善,可以选用更加快捷的检测器进行行人检测以节约更多的时间,也可以考虑尝试利用不同的特征提取模板进行训练以及考虑将特征提取部分和目标检测网络进行融合(例如无需匹配先验框匹配的CenterNet等),通过参数重用降低时耗。
参考文献:
[1] 王春艳,刘正熙.结合深度学习的多目标跟踪算法 [J].现代计算机(专业版),2019(6):55-59.
[2] 李牧子.基于图像识别的目标检测与跟踪系统的设计与实现 [D].北京:北京邮电大学,2019.
作者简介:徐耀建(1999.09—),男,汉族,江西上饶人,本科在读,研究方向:软件工程。
