军用无人机机载AI计算平台最新发展
2020-11-06汤一峰
汤一峰
中国航空无线电电子研究所
基于忆阻器、脉冲神经网络等新器件、新算法的仿生神经网络AI计算技术正蓬勃发展,目前看它也许像量子计算技术一样,具有实现前所未有算力突破的潜力。本文从“敏捷秃鹰”、“蓝鸦”超级计算机入手,概述美军无人机机载AI计算平台最新发展。结合工业界、学术界的最新研究成果,分析相关技术将如何颠覆性改变军用机载AI计算的硬件结构和应用领域。
2018年美国国防预研局(DARPA)提出“马赛克战”新型作战样式,其中反复提及军用人工智能(AI),认为军用AI是实现决策中心和决策优势的关键技术。AI是一种能够感知和理解周围环境,并采取相应适当行动以最大限度实现目标的物理或虚拟实体。在美军空中作战领域,人工智能正发挥越来越强的赋能效应。美国空军“天空堡”(Skyborg)、DARPA“分布式杀伤网”(ACK)等项目均将AI作为项目成功的重要保证。
军用AI由软件和硬件两部分组成,本文重点介绍适应未来军用机载环境下AI计算硬件平台的发展现状和未来趋势。
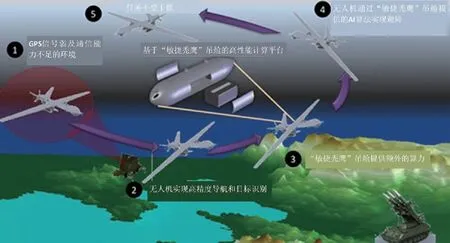
图1 “敏捷秃鹰”有望实现无人机机载边缘计算。
“敏捷秃鹰”计划
美空军研究实验室(AFRL)在2014年前后开始进行一种机载AI计算平台研究,即“敏捷秃鹰”(Agile Condor)研究计划。
“敏捷秃鹰”采用AI计算技术,能够在远程无人机上进行机载高性能嵌入式计算,实时对数据进行处理和传输,从而增强机载平台情报数据获取效率以及态势感知能力,具有数据处理高效、目标识别迅速以及带宽需求降低的优点。
AFRL采用MQ-9无人机搭载“敏捷秃鹰”吊舱开展原型机测试,2019年进行了集成与演示验证。测试中,MQ-9“死神”无人机机载X波段雷达和光电系统向“敏捷秃鹰”吊舱AI计算平台发送合成孔径雷达图像、红外热成像及可见光图像,通过在线目标识别测试,“敏捷秃鹰”取得了不错的成果。
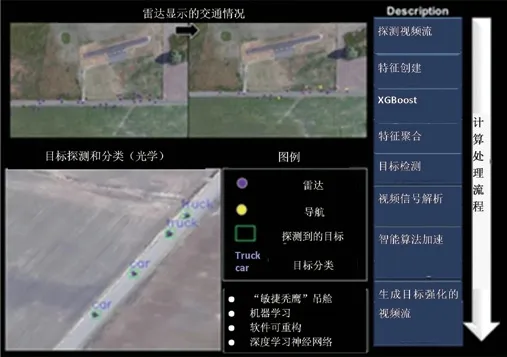
图2 AI图像处理效果。
“敏捷秃鹰”的计算板卡使用定制的OpenVPX主板,具备运行异构计算分布式软件的能力。根据现有研究结论,对大规模神经网络而言,图形处理芯片(GPU)的卷积计算能力优于中央处理芯片(CPU)。而CPU和GPU联合处理又要比单CPU处理效率更高。“敏捷秃鹰”吊舱内置的计算板卡带有3个插槽,每个插槽各搭载1个i7CPU和2个NVIDIA Maxwell GM107 GPU,1个i7 CPU控制2个GPU,可以提供2.5万亿次/秒的浮点运算能力,3个插槽一共可以提供7.5万亿次/秒的浮点异构计算处理能力,而计算板卡总重才27kg。
研究还表明,与CPU+GPU配置方式相比,在某些情况下可编程或可定制的加速器硬件平台如FPGA、ASIC、DSP能实现更优化的神经网络算法。因此,“敏捷秃鹰”还有额外的插槽用于添加FPGA和DSP。
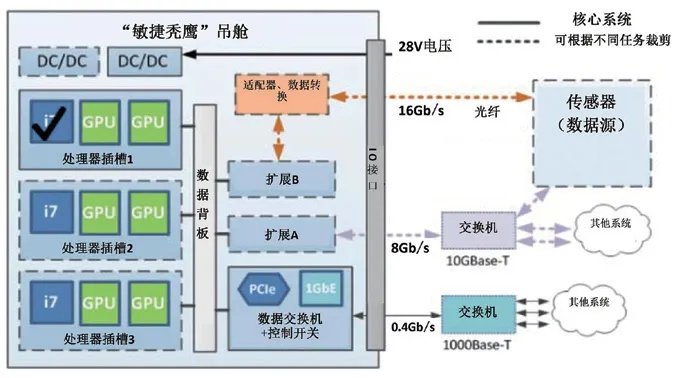
图3 “敏捷秃鹰”系统框架图。
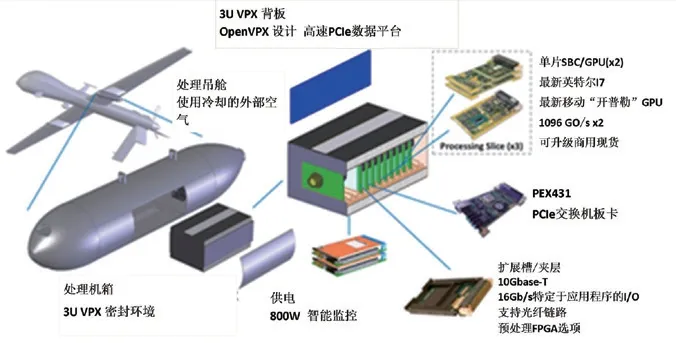
图4 “敏捷秃鹰”吊舱系统配置图。
整套吊舱内部使用万兆以太网端口进行数据传输,同时另配有速率16GB/s的光纤通道。信息数据被传输至“敏捷秃鹰”吊舱后,先传送到数据背板,然后使用PCIe总线和以太网通过PCIe中间件在各个计算插槽内传输数据。
在算法实现上,“敏捷秃鹰”的目标识别算法包括深度神经网络、深度卷积神经网络、递归神经网络,这些算法使用Caffe框架进行训练。图像异常检测使用了XGBoost等技术。
“蓝鸦”超级计算机
“敏捷秃鹰”升级计划将继续提高平台计算水平,引入仿生神经网络计算技术,并降低功耗和减轻重量,未来有望集成到像“影子”(Shadow)等那样的小型无人机。
由于GPU、FPGA运行人工神经网络学习算法时,机载计算平台的功耗和体积均比较大,无法满足像“扫描鹰”(ScanEagle)、“影子”这样的小型无人机,而新兴仿生神经网络计算技术具有优势,可满足小型无人机任务载荷对功耗、体积、重量的要求。
仿生神经网络计算机不同于冯·诺依曼体系结构,神经形态计算试图从硬件架构实现对人脑的模拟,即一个神经元可以对来自邻近神经元的多个刺激做出反应,整个网络可以根据来自环境的不同输入改变其状态。这样的硬件架构十分接近神经网络学习算法,因此适合执行人工神经网络或脉冲神经网络算法。同时,通过在“内存中计算”,可以突破冯·诺依曼瓶颈,即处理大型问题时,打破内存与处理器之间的数据传输受总线能力的限制。
图6是一个最简单的仿生神经网络处理核,该处理核以轴突作为输入通道,神经元作为输出通道,输入和输出之间通过可编程的突触进行通信。神经元作为主要运算单元接收并整合“1”或“0”的脉冲信号,并依据这一信号做出指令,再将此指令通过各神经元连接处的突触输出给其它神经元。
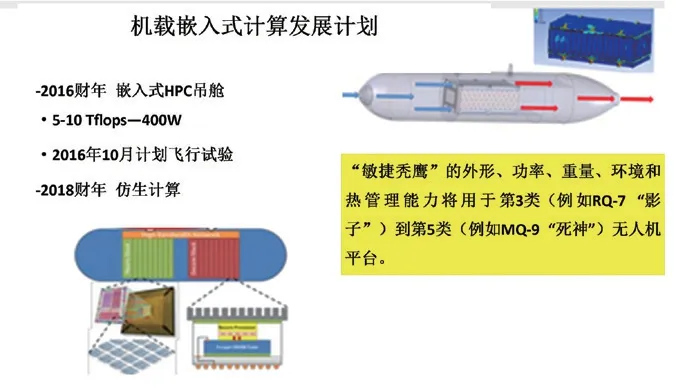
图5 美空军实验室规划的机载嵌入式计算发展。
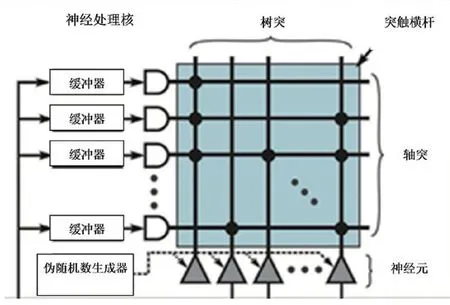
图6 神经处理核的逻辑图和互联方式。
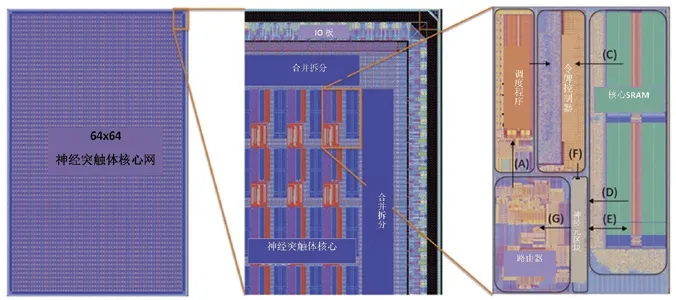
图7 从左至右是对TrueNorth逐层芯片结构的分解。

图8 NS1e(左)及NS1e-16(右)仿生神经网络计算机芯片。
早在2008年,DARPA就资助了“神经形态自适应可塑可扩展电子系统”(SyNAPSE)计划,开展神经形态计算技术相关研究。
首个基于SyNAPSE的研究成果即由IBM研制的芯片,被命名为TrueNorth。该芯片内置100万个模拟神经元和2.56亿个模拟神经突触,芯片内的神经元和突触配备了2个ARM Cortex-A9和一块1GBDDR内存进行读取计算控制,以模块化方式构建成一个基于晶体管的神经网络。晶体管采用三星28nm制程工艺,5.4亿个晶体管仅占面积4.3cm2。
每颗TrueNorth芯片所包含的神经网络通过阵列方式互联,轴突作为输入,神经元作为输出,突触作为轴突和神经元间的直接联系,通过点对点的联系方式,将任何一个核的神经元连接到任何一个核的轴突,以完成本地或远程通信。这样多个TrueNorth芯片互联就可以搭建出一个仿生神经网络计算机。截至2018年,IBM已开发出NS1e、NS1e-16、NS16e等多个型号仿生神经网络芯片验证机。
在功耗方面,一颗含54亿个晶体管的TrueNorth芯片,所需功耗仅70mW,而一颗包含14亿个晶体管的英特尔芯片,所需功耗则通常达到35W甚至140W。
在运算速度方面,CPU等常规芯片的运算速度利用每秒浮点运算数(FLOPS)来计量,TrueNorth以每秒突触运算值(SOPS)来计量。对于一个典型网络,TrueNorth每瓦发送460亿SOPS,对于高脉冲率和多活跃突触数量的网络,TrueNorth每瓦可发送4000亿SOPS。而目前最高效的超级计算机,每瓦仅发送45亿FLOPS。
2019年美国空军研究实验室联合IBM公司,以TrueNorth芯片生态系统为基础,共同开发出“蓝鸦”(Blue Raven)超级计算机,被称为世界技术领先的神经形态数字突触超级计算机。“蓝鸦”计算机包含64块TrueNorth芯片,每个芯片含100万个神经元节点。因此,“蓝鸦”可模拟大脑中6400万个神经元和160亿个突触进行数据处理。“蓝鸦”使用IBM专为TrueNorth开发的Eedn卷积神经网络学习框架进行训练。目前“蓝鸦”的功率仅70W,相当于一枚家用灯泡。
AFRL表示,“蓝鸦”可大幅提高空中平台数据处理能力,直接在机载端实现图像识别、毁伤评估、导航等功能。从而无需将传感器数据回传至地面控制站数据中心,加快作战人员的战时决策速度。AFRL内部已将“敏捷秃鹰”和“蓝鸦”作为同一个项目进行管理,后期目标是在4~5年内将“蓝鸦”处理速度提升至现有速度的4倍。

图9 “蓝鸦”由美国空军研究实验室和IBM公司联合开发。

图10 “敏捷秃鹰”和“蓝鸦”已被AFRL 列为同一项目。

图11 英特尔研发的Intel Loihi芯片。
未来发展
在仿生神经网络计算领域,除AFRL与IBM之外,英特尔(Intel)也取得了巨大突破,该公司研发的Loihi芯片在2017年首次亮相,包含128个内核、13万神经元、1.3亿突触,每个内核模拟多个逻辑神经元,具有支持多种学习模式的可扩展片上学习能力。2020年3月,英特尔将768颗Loihi芯片组装成拥有1亿个神经元的超级仿生神经计算系统,超过了仓鼠大脑的神经元总数。
未来进一步发展仿生神经网络计算平台,还应考虑使用忆阻器等新材料替换目前基于互补金属氧化物半导体(CMOS)的元器件。
忆阻器密度高、功耗低,作为一种具有记忆功能的元器件,适合用于突触结构,是硬件实现人工神经网络突触的最好方式。
马萨诸塞大学阿默斯特分校研制的基于忆阻器的三维卷积神经网络处理芯片达到了8层,而总厚度仅为300nm。
从今日芯片巨头英特尔、ARM等公司成长历程可知,发展壮大不仅仅依靠芯片本身的先进性,更重要的是联合商业伙伴,搭建应用、操作系统、语言开发、商业模式等一系列生态系统。仿生神经网络AI计算平台的关键要素如基于新材料的忆阻器、基于新算法的脉冲神经网络(SNN)、仿真平台、训练框架等正在蓬勃发展。相信未来仿生神经网络计算和量子计算技术,将实现前所未有的巨大算力突破,颠覆性改变军用机载AI计算的硬件结构和应用领域。

图12 马萨诸塞大学阿默斯特分校研制的8层芯片。
