以编译为导向的Matrix-DSP程序分析与优化
2020-11-05荀长庆陈照云孙海燕马奕民
荀长庆,陈照云,文 梅,孙海燕,马奕民
(国防科技大学计算机学院,湖南 长沙 410073)
1 引言
数字信号处理器DSP(Digital Signal Processor)在图形图像处理、视频编解码、工业自动化控制、无人驾驶、雷达信号处理和电子对抗等领域中具有广泛应用[1]。随着应用领域更加密集的数据处理需求,新一代DSP的架构设计和计算能力面临着更高的挑战。目前主流的DSP芯片大多以单指令多数据SIMD(Single Instruction Multiple Data)+超长指令字VLIW(Very Long Instruction Word)的向量化架构为发展方向,VLIW构架可以大大加强DSP处理器的指令并行能力,而SIMD指令集能够大幅度提高数据并行处理能力[2]。DSP计算处理能力的不断提升带来的重要挑战就是如何能够完成应用算法的向量化高效设计与实现。
离开特定的体系结构谈程序性能优化往往没有意义。面向向量化架构DSP的算法设计与优化需要基于向量结构特点和程序特征分析,实现算法的合理划分映射,并采用多种优化手段,充分挖掘程序中可利用的并行性,提高对存储层次的利用效率,从而大幅提高程序的执行性能[3]。大型科学计算应用往往包含若干热点内核程序,其性能优化对整个应用具有巨大提升效果。此外,程序的性能也和编译器息息相关,要想获得高效的程序性能,需要对编译器的优化能力(冗余删除、计算强度削弱、指令合并与调度、优化范围扩大等)有一个大致的分析,程序员需要结合编译器特点来调整向量编程方式,从而最大程度地使编译器理解程序员的并行优化意图,使程序员为编译器提供更多的优化机会[4]。因此,面向DSP的向量化程序设计与优化,与设计高性能DSP具有同等重要的地位,同时也具备相当大的难度和挑战性。
Matrix是自主研制的高性能数字信号处理器,具有向量处理、SIMD支持和超长指令字的特征。该DSP同时具有标量与向量功能部件,支持定点与浮点计算,在无线通信、科学计算、图像处理等多个领域具有广泛应用。本文基于Matrix DSP的体系结构特点,以编译器特性为导向,梳理内核级程序向量化设计分析与优化的一般步骤,并结合通用矩阵乘GEMM(GEneral Matrix Multiplication)例子进行具体展示,最后对未来优化方向提出思考与讨论。
2 Matrix DSP结构特点及向量化编程
作为自主研发的一款高性能DSP,Matrix具有典型的SIMD+VLIW的特征,其内核部分的主要结构如图1所示。该处理器主要包括标量部件和向量部件,由指令派发部件同时为标量和向量提供指令。标量部件中的标量处理单元SPU(Scalar Processing Unit)主要负责执行串行任务,同时负责对向量部件的控制。而向量部件中的向量处理单元VPU(Vector Processing Engine)主要负责执行计算密集的并行任务。其中向量处理单元采用一种可扩展的运算簇结构,由16个同构向量计算引擎VPE(Vector Processing Engine)构成,每个VPE中包含了3个浮点乘加器MAC,同时支持2个向量的访存操作(Load/Store)。核内的阵列存储器AM(Array Memory)可实现16路SIMD宽度的向量数据访问,为VPU提供较高的访存带宽。核内的存储器直接访问部件DMA可支持标量和向量的高效数据搬移与供给。整个Matrix采用可变长的VLIW架构,最大可支持11发射(包括标量指令和向量指令),从而最大程度上开发指令级并行与向量部分的数据级并行。
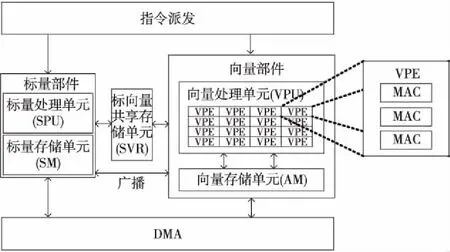
Figure 1 Kernel structure of Matrix DSP图1 Matrix DSP内核结构
对用户而言,向量化编程大体上可以分为3种,即自动向量化、手写汇编和基于向量扩展的高级语言编程。尽管自动向量化技术已经在学术界和工业界经历了多年的研究与探索,但是其性能还是不甚理想[5]。虽然手写汇编一定程度上能够完成高效的算法设计,但是其所需的技术积累、人力成本和开发周期都是极高的。Matrix DSP采用基于向量扩展的C语言方式,在实现整套基于GCC编译器工具链移植的基础上,提供一系列用于向量操作的内联函数接口,程序员可以调用向量函数接口,编译时可以直接将内联函数映射成向量指令[6]。该方式旨在通过程序员挖掘应用中存在的大量细粒度、同质、独立的数据操作,并基于向量化架构中的多个浮点运算单元,将上述数据操作通过向量指令实现并发执行,从而显著提高应用性能。
然而,面向这种基于向量扩展的高级语言若要实现高效编程,需要依赖程序员结合硬件结构的特点完成并行算法映射,同时熟悉编译器的编译能力和特性,完成特定高效的编程,来实现应用性能的优化加速。向量化编程对程序员提出了巨大的挑战,具体包括:
(1)程序员开发时需要显式接触硬件体系结构和硬件资源,包括浮点计算单元和数据通路等;
(2)程序员需要进行数据对齐和数据连续排布;
(3)程序员需要完成对应用中并行性的挖掘与探索,并完成面向特定体系结构的映射;
(4)控制流引入的开销问题;
(5)熟悉编译器自身的编译特性与编译优化能力,采用特定的编程方式为编译器提供更多优化机会。
结合Matrix DSP体系结构特点,以基于GCC移植的编译器工具链特性为导向,本文将以一个内核级代码(通用矩阵乘)为示例,对面向Matrix DSP的向量化算法设计分析与优化进行探索,并总结相关经验和思考。
3 以编译为导向的程序分析与优化
要实现高效的程序设计与优化往往需要程序员和编译器两方面共同配合,一个优秀的程序员可以尽可能降低对编译器的依赖,而一个高效的编译器对于程序员编程可提供极大的方便。本文着重基于Matrix DSP体系结构,结合编译器特性来进行程序分析与优化探索,以通用矩阵乘为示例进行展示,并总结梳理程序向量化设计优化的经验。
3.1 通用矩阵乘算法并行性分析和基本算法映射
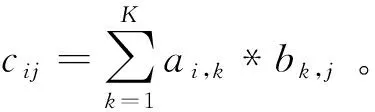
矩阵乘的并行算法有很多选择,结合Matrix DSP的向量处理单元包含16个VPE的结构特点,可以考虑最朴素的向量化映射方法,即将矩阵B按列划分,每个VPE处理不同的列数据,从而对应计算出矩阵C不同列的结果。同时,每个VPE中包含3个MAC单元,为了最大化数据并行效率,每个MAC可以再按列进行细粒度的数据划分,这样理论上每拍最多同时执行48个浮点乘加运算,将整个核内48个MAC部件全部充分利用。而矩阵A的数据需要16个VPE共享,因此为了提高片上存储效率,本文将矩阵A的数据存储在标量处理单元的数据存储部件SM(Scalar Memory)内,并通过全局共享寄存器广播给所有的VPE。矩阵B和矩阵C将存放在阵列存储器(AM)内。
整个Matmult向量化算法映射如图2所示,具体流程如下:
(1)矩阵A存放在标量数据存储部件(SM)中,矩阵B和矩阵C保存在阵列存储器(AM)内;
(2)标量单元将矩阵A元素按行访存并广播到16个VPE的向量寄存器;
(3)每个VPE根据按列划分的矩阵B和矩阵C进行访存,并与矩阵A广播的数据进行乘加计算,其中每次乘加计算利用3个MAC同时处理3列数据,16个VPE同时计算48列数据;
(4)将计算结果保存到矩阵C;
(5)循环直至所有结果计算完毕。
图2只展示了一个VPE内的计算过程,其他VPE内计算过程与之相同。

Figure 2 A basic vectorization algorithm of Matmult图2 Matmult基本向量化算法
为了最大化内核级代码计算效率同时避免冗余计算,内核级代码所计算的数据块大小同样需要精心考虑设计。矩阵C的列数N可以设置为48(16 VPE*3 MAC);同时保证数据对齐提高DMA传输效率,矩阵A的列数K可以设置为8的倍数(256 bit对齐),而矩阵A的行数M可以参考设置为6(具体原因参见3.2节)。
由于本文聚焦于内核级代码的程序优化,为了方便后续优化讨论,因此假设当前通用矩阵乘内核代码的规模为:矩阵A为6*512,矩阵B为512*48,矩阵C为6*48,同时所需的数据已经通过DMA搬移到片上,该数据规模不会超过片上存储容量。整个内核级向量C代码和部分汇编代码(即v1版本的Matmult代码)如图3所示,汇编代码共96行,其中最内层循环代码51行,单次内循环执行周期为64拍,在M7002芯片(Matrix DSP系列的一个芯片产品)上测试其执行时间为198.36 μs,编译选项统一采用-o2-funroll-loops。

Figure 3 Vectorization code and partial assembly code of Matmult v1图3 Matmult v1向量化和汇编代码片段
3.2 代码重构
通过对图3中代码分析可以看出,内循环中因为要完成一个完整的行向量和列向量的相乘累加计算,因此矩阵C在每次循环之间都存在着数据依赖(MatC),导致即使采用了循环展开的编译选项,仍然无法进行展开优化。从汇编代码上分析,内循环没有实现循环展开,循环体内仍然只有3个浮点乘加指令(灰色背景指令),同时VPE中3个MAC并没有充分并行,导致MAC资源的空闲浪费,整个内循环的指令效率有待提升。
从算法上分析,之所以会出现数据依赖是因为矩阵A按行广播,内循环需要完成累加计算,因此可以考虑将内外循环进行交换,即进行代码重构。调整后的算法将矩阵A按列广播,与矩阵B固定某一行进行对应乘法计算,并将结果累加到矩阵C中对应位置。当矩阵A完成1列数据的广播,矩阵B只需访问1行数据,而矩阵C需要完成所有位置的元素累加更新,这样调整可以最大程度上提高浮点乘加的并行性,具体过程如图4所示。鉴于指令集浮点乘加指令为6拍,同时为了保证寄存器使用时不溢出,矩阵A列数M可以参考设置为6。代码重构后内循环不再存在数据依赖,具体内核代码(即v2版本的Matmult代码)如图5所示,整个汇编代码长度351行,内循环完全展开,整个外循环代码占307行,单次循环内执行节拍数为309,芯片上测试其执行时间为159.40 μs。
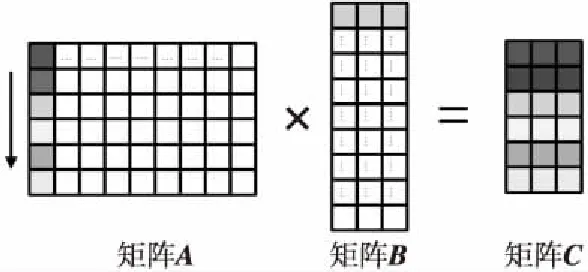
Figure 4 Optimized vectorization algorithm of Matmult图4 优化后的Matmult向量化算法
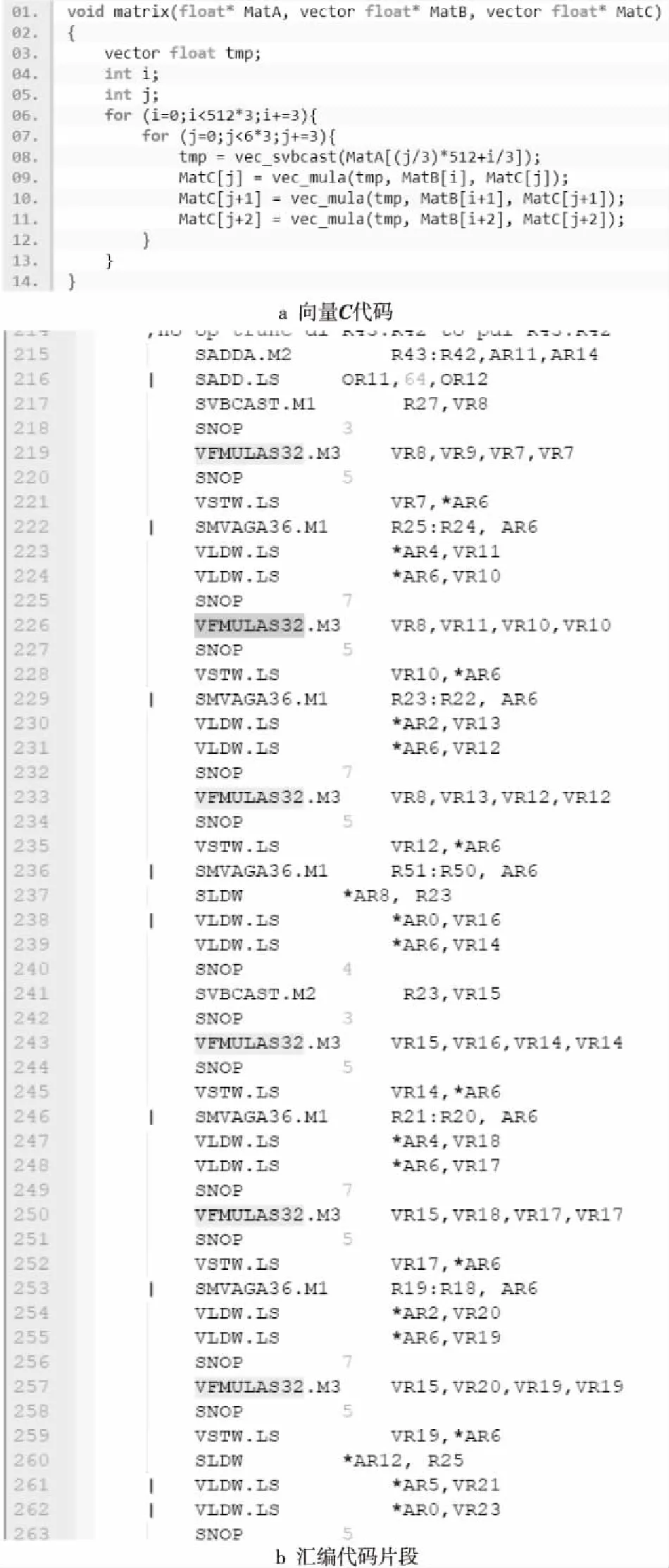
Figure 5 Vectorization code and partial assembly code of Matmult v2图5 Matmult v2向量化代码和汇编代码片段
3.3 计算访存解耦合
尽管进行了循环展开(从汇编代码上能看到同时存在多个浮点乘加指令),但在向量C代码第9~11行的计算过程中,由于单条语句包含了多个访存(矩阵B与矩阵C)操作,从汇编代码上看,浮点乘加指令中间存在着访存指令(VLDW/VSTW)。由于编译器中指令调度窗口大小有限,导致内循环多条指令的访存和计算串行执行,每个VPE中3个MAC的利用效率大大下降。大多数编译器能够从代码中提取的并行性信息有限,对一些复杂的处理过程,即使存在并行开发的可能,编译器也可能无法成功识别,因此需要程序员来辅助编译器完成并行性的挖掘与利用。
本文采用计算与访存解耦合的方式来对代码进行进一步优化,主要方法是将数组访存的部分从语句中分离出来,单独用中间变量来保存,并用中间变量替换计算语句中的输入。此外,本文发现在内循环中矩阵B的数据被反复访存,但事实上其数据仅依赖外循环,因此将矩阵B的访存移出内循环,从而进一步提高执行效率。优化后该部分代码(即v3版本的Matmult代码)如图6所示,整个汇编代码长度为296行,其中循环体占260行,单次循环执行周期为137拍,在芯片上测试其执行时间为70.33 μs。

Figure 6 Vectorization code and partial assembly code of Matmult in v3图6 Matmult v3向量化代码和汇编代码片段
3.4 合并访存与寄存器优化
通过计算访存的解耦合,可以发现在内循环中需要对结果矩阵C每个元素进行反复访存。从汇编代码上来看,尽管浮点乘加计算指令能够实现并发,但是整个内循环中访存指令数目(VLDW/VSTW)较多,而浮点乘加计算指令周期只占整个循环执行周期的13%左右,核心循环的计算效率并不高,访存的次数为外循环的次数(512次*2,读写各一次)。鉴于本文优化的代码中矩阵C规模较小(每个VPE处理6*3规模的子矩阵),可以考虑通过寄存器来降低访存的次数,从而实现程序效率进一步提升。
本文将矩阵C中每个元素都在整个循环外赋值给中间变量,并将内循环完全手动展开,在循环内采用中间变量参与乘加计算,在整个循环外再将所有中间变量赋值到矩阵C对应元素的位置上。优化后的代码只需要对矩阵C中每个元素进行一次读和一次写操作,大大降低了访存开销,提高了整个代码的执行效率。该部分代码(即v4版本的Matmult代码)如图7所示,整个汇编代码共253行,其中循环体占125行,单次循环执行共71拍,在芯片上测试其执行时间为36.12 μs。

Figure 7 Vectorization code and partial assembly code of Matmult v4图7 Matmult v4向量化代码和汇编代码片段
3.5 计算强度削弱:除乘法转换
为了提高MAC利用率,程序中存在连续3条乘加计算语句,导致图7a代码中MatA和MatB的数组下标访问中用到了整数除法。而除法所需要的执行周期比较长,降低了程序执行效率。如图8所示,核心循环的汇编代码中为了实现整数除法,需要进行多次迭代移位(SSHFLL/SSHFAR等移位指令)计算,大大增加了核心循环的指令条数,因此可以考虑用乘法来替换除法计算,削弱计算强度,从而降低冗余的指令数,提高执行效率。

Figure 8 Partial assembly code of Matmult v4图8 Matmult v4汇编代码片段
本文将代码中的循环变量和数组访问下标都进行调整,把除法计算调整为乘法计算,其过程如图9所示。编译器本身具有除乘法转换的优化功能,但是其主要针对除数为2的整数次幂,可以将除法转化为移位运算。而对于该优化代码中除数为3的情形,程序员可以手动调整编程方式,削弱计算强度。由于循环次数较多,循环内微小的优化能够对程序性能起到重要提升作用,优化后的代码(即v5版本的Matmult代码)如图10所示,整个汇编代码共230行,其中循环体占83行,单次循环执行共39拍,在芯片上的执行时间为20.27 μs。

Figure 9 Transforming division into multiplication图9 除法转换为乘法

Figure 10 Partial assembly code of Matmult v5图10 Matmult v5汇编代码片段
3.6 手动软件流水优化
从代码中可以发现,单次循环内的访存、广播与计算具有严格的数据依赖,无法进一步挖掘并行性。但是,每次循环迭代之间可以通过重叠执行来提高程序性能,充分利用处理器的所有资源。虽然循环展开之后一定程度上可以提高代码的并行执行效率,但是被展开循环之间的界限仍然为代码移动设置了障碍,同时大幅增加了整个代码的长度。因此,本文考虑采用软流水来充分释放循环间的并行性,同时生成高效紧凑的代码。
循环内的主要执行过程包括矩阵B的访存、矩阵A的广播和矩阵C的乘加计算。显然访存与广播之间没有数据依赖,可以并发执行,但计算则依赖于访存与广播的结果。同时不同循环间由于需要进行累加计算,因此第i+1次循环的访存与广播的数据写入不能早于第i次的乘加计算的数据读取。通过分析可以发现,不同循环间可能存在的并行性就是通过细粒度排布使得第i次乘加计算与第i+1次访存和广播部分重叠执行,同时还要严格保证数据读取和写入的顺序。调整后的代码还需要在循环外增加进入稳定循环态前后的额外部分。由于数据间的依赖约束比较严格,而高级语言编程无法完全细粒度地进行指令排布,只能将尽可能优化的空间展示给编译器,由编译器进一步完成。在进行手动软流水优化之后,整个汇编代码长度为274行,其中循环体占76行,单次循环执行周期为27拍,代码在芯片上的执行时间为14.09 μs。
3.7 优化手段总结与评测
结合程序自身并行性和编译器自身特性,本文采用了一系列程序优化手段不断提升其执行性能。具体包括:
(1)代码重构:即根据应用本身特性对算法进行合理的向量化映射调整,能够尽可能挖掘程序自身的并行性,充分利用硬件体系结构的计算资源。
(2)计算访存解耦合:为了提高代码中可并行性的挖掘与利用,尽可能将每一条语句功能简单化,将同一条语句中的计算和访存解耦合出来,为编译器优化提供尽可能充足的空间。
(3)合并访存与寄存器优化:降低访存次数或对访存进行隐藏是程序优化的重要手段。程序员在编程时需要利用数据可重用性来减少非必要的访存次数,同时多采用寄存器来提高对体系结构存储层次的利用。
(4)计算强度削弱:对于类似除法的计算,可以考虑将其手动或自动转换为等价且计算强度更低的运算来替代,从而提高程序执行效率。
(5)软件流水:除了挖掘单次循环内的程序并行性,还可以尝试分析不同循环迭代间的数据依赖,并通过软件流水来实现循环间的重叠执行,从而大幅提高程序性能。
上述优化手段并没有特定的使用约束,程序员可结合自身程序特性进行分析与调整。通过应用上述多种优化手段,本文以通用矩阵乘的内核级程序为例,将其执行性能从原始向量化版本的198.36 μs优化到14.09 μs,最高提升了1个数量级,其主要影响因素取决于单次循环体内的执行节拍数。各个优化版本的执行时间和性能提升如表1所示,数据均来自于实际M7002芯片级测试,采用的编译选项为-o2-funroll-loops。最终优化前后编译生成的汇编代码VLIW指令调度如图11所示,可以看出整个代码调度更加紧凑高效。

Figure 11 VLIW scheduling diagram for the kernel loop in Matmult v1 and Matmult v6图11 Matmult v1和Matmult v6版本核心循环代码的VLIW指令调度图

Table 1 Summary of optimization tips and results表1 各版本采用的优化手段与优化效果汇总
4 思考与讨论
面向特定体系结构实现高效的程序设计与优化本身就具有很大的挑战,而这其中需要程序员和编译器的共同协作,相辅相成。同样地,基于Matrix DSP开发高效的向量化应用或程序,除了上述总结的常用优化手段可以借鉴参考,本文也提出了对编译器未来优化方向和程序员的高效程序设计的一些思考和探索。
从编译器的角度来说,可以考虑从以下几个方面来进一步优化和提升,从而降低程序员编程的难度:
(1)自动向量化。Intel早在1996年就开始推出SIMD的向量指令扩展,并持续推进自动向量化的研究,即用户仍然采用串行思想进行编程,利用编译器中的自动向量分析器(auto-vectorizer)对代码进行分析并生成SIMD指令。自动向量化对用户编程极为友好,但是对编译器的挑战极大,目前自动向量化的效果不是特别理想,或者仍然需要程序员提供一些并行性提示来辅助编译器挖掘代码中的并行性。
(2)并行编程模型或编译制导。为了能够给编译器提供更多优化的可能,编译制导语句可以从开发者的角度提供给编译器更多编译期间无法提取的信息,提高编译器将代码向量化的概率。主流的并行编程框架OpenMP和OpenACC都是采用这种方式,只需要在程序中增加#pragma的语义提示,编译器就可以识别并对该部分代码进行并行优化[7 - 9]。另一种就是类似CUDA的编程模型,用户可以任意组织线程的层次结构和每个线程所执行的kernel计算,然后轻松映射到任意型号的GPU设备。
(3)软件流水,指令打包与调度。由于大部分应用领域代码的内核代码都是以循环为主,因此循环的优化对整个程序的性能起到重要作用。而软件流水功能是循环性能提升最关键因素之一,因此使编译器实现对循环的自动软流水,是一个重要的研究方向[10]。同样地,对于Matrix DSP的VLIW结构,指令调度和打包直接影响计算部件的利用率和程序的并行性,也同样是编译器自身性能的核心因素。
(4)大规模库函数开发。为了进一步拓展Matrix DSP的软件生态,尤其是拓展更多的应用领域,各类库函数是必不可少的。而库函数通常充分挖掘了指令集的特性,具有较高的计算效率。通过库函数的开发可以给用户提供高级语言接口调用,而将底层硬件信息隐藏,给用户更接近行为体验的语法,但是大规模库函数的开发需要极大的人力与时间代价。
从程序员的角度来说,要想设计高效的向量化代码,除了上述通用的优化手段和编译器的辅助,还需要从以下几点进一步挖掘与提升:
(1)用向量化的思想来完成程序算法分析和面向体系结构的映射。一方面要求程序员充分分析与挖掘应用算法的并行性,另一方面需要对体系结构的硬件资源具有清晰的把握。然后以特定的编程方式完成算法到体系结构的映射,尽可能提高硬件资源利用率和算法的并行性,这本身就是一项极难的挑战。
(2)尝试利用内存层次来提高数据访问效率。一般来说硬件体系结构会具有多个存储层次,例如寄存器、Cache、memory等。程序员需要考虑将不同的数据排布到不同的存储空间,尽可能利用数据重用来降低数据访存开销,或将长距离的访存延迟进行隐藏,例如常用的双缓冲机制。针对规模较大的数值算法,进行合理的数据块划分往往需要综合考虑数据供给的速率和计算部件消耗数据的速率,从而实现较优的计算资源利用率和程序执行性能。
5 结束语
本文面向Matrix DSP架构,以编译器性能为导向,对向量化内核程序的分析与优化进行了一系列的梳理与总结,包括代码重构、计算访存解耦合、合并访存与寄存器优化、计算强度削弱和软件流水等手段。通过运用上述优化手段,将一个通用矩阵乘的内核代码执行性能提升了1个数量级。在程序优化与总结的基础上,围绕Matrix DSP的高效编程,进一步从编译器优化和程序员算法设计2个角度,提出了一些思考和讨论。未来将沿着该方向持续开展面向Matrix DSP的程序高效分析与优化工作。
