数据处理技术在互联网推荐场景中的应用
2020-11-05董雪鹏
董雪鹏
(南京电子器件研究所,江苏 南京210016)
在互联网社会,每个人的线上生活都在不断产生相应的数据,这些数据就是互联网社会最宝贵的资源。当前互联网公司的许多商业模式都是基于这些数据实现的。通过对互联网用户行为数据的处理,可以分析用户的使用习惯,不同类别用户的兴趣特征,从而为不同用户推送不同的内容,提升用户使用体验,提升应用日活用户数量,进而提升应用商业化指标。数据处理技术在内容推荐场景的应用随着业务场景的需求,处理技术的发展以及沉淀数据质量的提升可以分为三个方面:离线批处理,分布式流计算和深度数据挖掘。
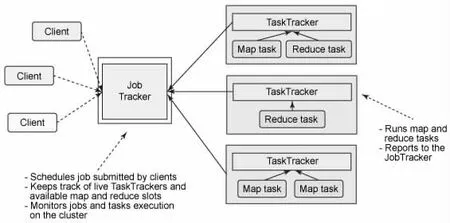
图1 MapReduce 结构图

图2 流式计算过程示意图
1 离线批处理技术
互联网上每天都在产生很多的数据,为了将最新的数据及时准确地送到每个用户的眼前,需要每天对这些数据进行分析计算。比如某个线上商店新上架了一批新的热门商品,那么电商平台需要及时将这批商品推荐到潜在客户的应用程序上。这里就需要进行推荐算法的计算,而且需要定期根据最新的数据进行推荐结果更新。这里存着一个核心计算问题,计算成本。
在数据量达到一定规模后,所有的计算成本都会呈指数级增长,包括内存、CPU 和时间。为了在有限的时间内尽可能快地完成计算任务(保证上架商品尽可能快地呈现到用户面前),需要将更多的算力联合成集群使用。同样是由谷歌公司发表的论文“MapReduce”提供了一种解决分布式计算问题的思路,对应的开源解决方案是Hadoop 中的MapReduce 模块(见图1)。
MapReduce 帮助数据分析人员将存储在分布式存储上的海量数据分散到不同的服务器上进行并行计算,最终再将分散的计算结果进行合并得到最新的数据分析结果[1]。因为这种计算往往是面向一定规模的存量数据的,即先将数据存储到硬盘上,当数据累积到一定的规模后再进行批量分析,因此也称为离线批处理计算。
但是有些场景下这种计算模式是不能够满足我们的业务需求的。比如在导航地图中,用户痛点是希望知道当前道路的实时路况,如果间隔一段时间才能得到分析结果,这种体验将会是非常糟糕的。此时数据分析的主要矛盾是计算的实效性问题,需要有一种快速的数据分析技术来支撑这种业务场景[2]。
2 分布式流计算
为了能够提高数据分析的效率,降低数据分析时延,发展出了流计算模式[3]。流计算相比较批处理技术的核心优化点有两个:
(1)纯内存操作,节约了数据存入磁盘再进行读取的成本。
(2)将计算分为很多小的链式操作,充分利用计算的流水线效应提高了计算吞吐能力。
流式计算开源的解决方案有很多,当前业界最流行的解决方案是Apache 基金会开源的Flink 实现(如图2)。
流计算过程中,数据像流水线一样闯过由Operator 组成的处理链条,整个数据集的平均吞吐延时约等于Operator 中耗时最长节点的延时[4]。
3 深度数据挖掘
随着批处理和流处理场景的落地,这些大数据处理技术满足了各种用户最基本的需求,但是互联网沉淀的数据资源的价值还远远没有被挖掘出来。为了满足不同用户个性化的需求,实现千人千面的业务价值,需要引入一些更高阶的计算模式,这就是深度学习技术[5]。
深度学习技术的应用是工程、算法和商业模式在一个合适的时间点发生碰撞的结果,通过前面的工程积累,生产上基本解决了大规模复杂计算的问题。此外,2010 年之后深度学习算法的飞速发展也为商业应用提供了强有力的理论支撑,还有多年来各个应用场景沉淀下来的海量的优质标定数据,也为技术的商业化应用提供了保障。在这样一个特定的时间点,数据,算法和工程碰撞在一起成就了数据挖掘的成功应用。
4 结论
大数据技术在互联网领域的成功应用有着清晰的发展脉络。本质上由于互联网的普及造成了海量数据喷发,而实际生产的需要推动了工程和算法各个方面协同发展,最终达到完美的融合,实现了商业上的成功。这一发展过程,在其他行业引入大数据技术进行生产时,值得充分借鉴。
