基于糖尿病防治的医学知识图谱构建的研究
2020-10-29刘勇齐梦霁
刘勇 齐梦霁


摘要:随着我国居民生活方式的变化,糖尿病已成为流行病,且逐渐呈年轻化趋势。作为一种长期慢性疾病,患者日常行为和自我管理能力对糖尿病的控制起到关键性的作用,为了促进糖尿病医学知识的共享、传播和利用,使得糖尿病患者拥有更积极的态度、科学的糖尿病知识和较好的糖尿病自我管理意识,本文提出了建立糖尿病的医学知识图谱,使用如医学实体抽取、医学实体关系抽取、医学实体属性抽取、医学知識融合等自然语言的相关技术,在语义层面对医学大数据进行了统一表达和组织,建立医学知识服务和应用,旨在促进患者掌握糖尿病管理所需的知识和技能,提高患者的生活质量。
关键词:糖尿病;医学知识图谱;关系抽取;自然语言处理
中图分类号:R319 文献标识码:B DOI:10.3969/j.issn.1006-1959.2020.18.004
文章编号:1006-1959(2020)18-0011-04
Research on the Construction of Medical Knowledge Graph Based
on Diabetes Prevention and Treatment
LIU Yong1,QI Meng-ji2
(Information Center1,Science and Education Department2,Nanjing Jiangbei People's Hospital,Nanjing 210048,Jiangsu,China)
Abstract:With the changes in the lifestyles of Chinese residents, diabetes has become an epidemic, and it is gradually showing a younger trend. As a long-term chronic disease, the daily behavior and self-management ability of patients play a key role in the control of diabetes. In order to promote the sharing, dissemination and utilization of diabetes medical knowledge, diabetic patients have a more positive attitude and scientific diabetes knowledge and better awareness of diabetes self-management, this article proposes to establish a diabetes medical knowledge map, using natural language related technologies such as medical entity extraction, medical entity relationship extraction, medical entity attribute extraction, medical knowledge fusion, etc. Big data is uniformly expressed and organized, and medical knowledge services and applications are established to promote patients to master the knowledge and skills required for diabetes management and improve the quality of life of patients.
Key words:Diabetes;Medical knowledge graph;Relation extraction;Natural language processing
知识图谱(knowledge graph)是若干实体相互连接而成的语义网络,是由Google在2012年正式提出的,目前比较流行的大规模知识库有DBpedia、Freebase、Wikidata等。随着医疗大数据时代的到来,基于本体的知识表示模型成为知识表示的主流方法,本体可定义为概念模型的明确的规范说明[1],它强调概念间的逻辑推理关系,基于语义网的本体描述语言成为研究和应用的热点,包括资源描述框架(Resource Description Framework,RDF)。RDF定义了资源、属性、值三种基本实体,作为一种基于资源标识符的三元组来描述语义实体间关系的知识组织的概念模型和逻辑模型,能够表达医学知识实体间的复杂关系。国内的知识谱图研究起步相对较晚,主要集中于几个大型的互联网公司,如搜狗、百度等。知识图谱在医疗行业的研究目前也在积极地探索中,北京大学,计算语言教育部重点实验室,利用自然语言处理技术,以人机结合的方式研发了中文医学知识图谱第一版CMeKG1.0,为医学知识图谱的构建提供了很有意义的参考[2]。为了解决医学知识图谱中知识重复、知识质量和知识融合的问题,提出了在大数据驱动下的医学知识图谱构建方法[3]。针对医学数据专业性强、结构复杂等特点,结合当前我国医学知识图谱构建在数据和技术层面临的问题和挑战,提出了相应的对策和建议[4]。本研究以《中国2型糖尿病防治指南(2017年版)》内容为核心,结合医学词典、电子病历、各种医学指南、专家共识等基础数据,使用自然语言处理的相关技术,从糖尿病的教育与管理的角度出发,建立一套完整的糖尿病知识图谱的构建方法,目标是提供一个深入了解糖尿病的全新视角,帮助患者不断掌握疾病管理所需的知识和技能,最终实现糖尿病的被动救治向主动防治的转变,降低人群中糖尿病发病风险,维护和促进全民健康。
1糖尿病知识图谱构建
糖尿病知识图谱的构建步骤见图1,分为医学知识表示、医学知识抽取、医学知识融合和知识图谱存储四个部分。
1.1医学知识表示 医疗大数据的来源非常繁杂,各个医学实体之间的关系也比较复杂,为了把相关信息表示成可理解的方式,需要相应的知识表示模型。①医学术语规范化唯一概念标识:为了解决医学术语在不同词汇表中的差异,参照统一医学语言系统(UMLS)、国际疾病分类(ICD-10)等,使用唯一概念标识对来自不同词汇表源但相同的词汇的概念进行编码。如:参照ICD-10,疾病“2型糖尿病”对应的标准编码是“E11.901”、疾病“糖尿病性下肢溃疡”对应的标准编码是“E14.6913”。有了唯一概念标识就可以把不同数据来源但具有相同概念的词汇进行统一的编码管理,使得医学知识表示具有规范的数据表达方式。②基于语义的本体描述:RDF三元组RDF因其结构简单、表述清晰,且具有于语义与关联表达的灵活性优势,可用于构建知识图谱。RDF可表达实体以及实体之间的关系,具体形式为<实体,关系,实体>或者<实体,属性,属性值>,如<糖尿病,分型,2型糖尿病>,其中“糖尿病”和“2型糖尿病”是实体,“分型”是这两个实体之间的关系。此外,RDF也可以用节点和关系组成的图模型来表示,其中节点表示实体和属性值,连线表示节点之间的关系。
1.2医学知识抽取 医学数据的知识信息抽取包括实体抽取、关系抽取和属性抽取三个步骤。在糖尿病指南中,主要分为半结构和非结构化文本两种类型。半结构化文本即文本中存在部分结构化的数据,兼顾了格式性和自由性,在抽取信息时,相对非结构化文本更为方便,见图2。非结构化文本也被称为自由化文本,一般没有固定格式,经常是连续的字符串来描述相关内容,需要经过如分词、实体识别等步骤才能获取相关信息,如一段有关糖尿病诊断与分型的介绍,见图3。
1.2.1医学实体抽取[5] 采用基于Lattice LSTM模型抽取实体[6],该模型对输入字符序列和所有匹配词典的潜在词汇进行编码,抽取如医学文本中的药物名称、症状名、疾病名等。
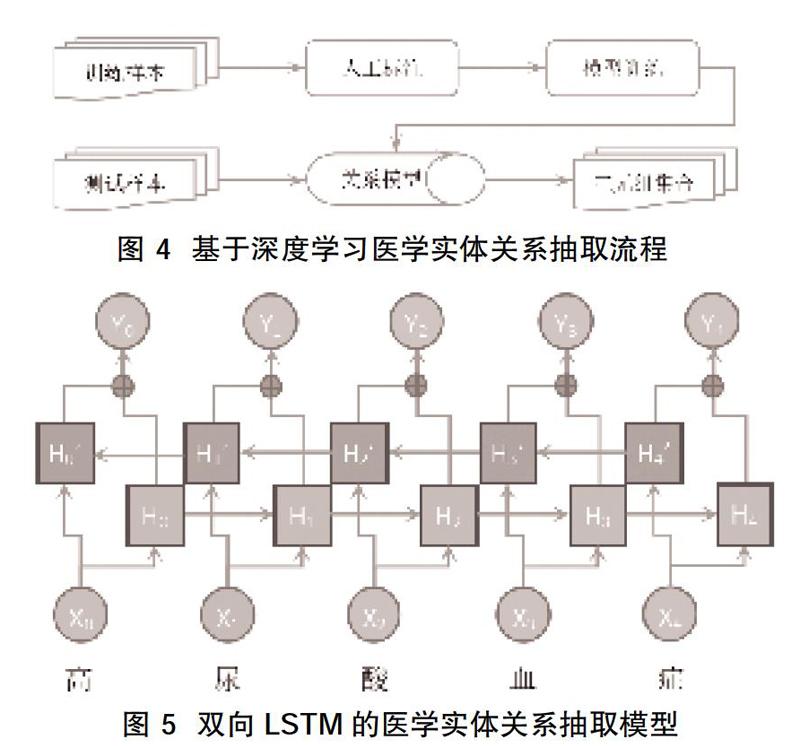
1.2.2医学实体关系抽取 为实现推理,还需要抽取医学实体之间的关系[7],以形成知识图谱。近年来,利用深度学习的方法抽取医学实体语义的关系取得了长足发展,如模型中引入位置特征、依赖关系、先验知识和注意力机制等附加特征,进一步提高了模型性能,见图4。基于大规模的人工标注语料可进一步提高模型的性能。此外,将各模型混合在一起用于医学语义关系抽取,可很好地利用各模型的优势,提高医学语义关系抽取的性能,如将基于深度学习和基于规则匹配的方法结合在一起,利用句法卷积神经网络模型抽取存在某种关系的蛋白质实体对,最后基于句法模板和词典匹配的方法抽取当前两个蛋白质实体间的关系[8]。在实体关系抽取中,最重要的是关系指示词的确认,有些是显性的指示词,如“症状是”“表现为”“可分为”等;有些是隐性的指示词,如“对于儿童和青少年的糖尿病高危人群,宜从10岁开始,但青春期提前的个体则推荐从青春期开始”,此句中暗藏了关系指示词“年龄”,即儿童糖尿病高危人群,年龄,10岁/青春期起。我们使用{B,I,O,E,S}三类标签标注候选关系指示词,B代表这个词语是关系指示词序列的开始,I代表这个词语在关系指示词的中间位置,O代表这个词语不是关系指示词的一部分,E代表这个词语是关系指示词的结束,S 代表这个词语是一个完整的关系指示词。图5是一个标注样例,是基于LSTM的双向LSTM医学实体关系抽取模型,表明高尿酸血症与糖尿病之间具有[疾病症状]的关系,此种关系属于隐含的关系,只有通过人工标注的方式才能完成。
1.2.3医学实体属性抽取 例如药品的属性包括不良反应、禁忌等,以实现对医学实体的完整描述。
1.3 医学知识融合 由于医学大数据来源多样的特点,且存在不规范术语、一词多义或多词同义的情况,因此需要根据知识表示模型合并已有结构化数据,以保证获取医学知识的质量。例如使用基于语料库分析的知识获取方法,结合现有的分类,对本体进行扩展[9]。在进行医学知识融合的过程中,可以使用一个混合匹配模型的融合方法,见图6。该融合过程中使用了字符匹配、语义匹配以及本体匹配的混合匹配模型,根据标准术语集,对输入的医学术语计算相应的匹配值,最后將匹配分值汇总,通过阈值判别来判定指定的医学术语与标准术语中某医学实体的匹配程度,从而达到医学知识融合的目的。
2糖尿病知识图谱的存储与展示
Nero4j是一个图形数据库,基本要素包括:节点、属性、关系,用来存储由无数个节点相连构成的属性图[10]。图7展示了每个医学实体是如何与其他医学实体连接或相互关联的,它既具有高效的查询功能,还具备可视化的能力。允许在不依赖于数据集总大小的情况下每秒快速遍历数百万个连接,擅长于管理高度连接的数据和复合查询。Cypher是Neo4j的图形查询语言,它允许用户从图形数据库中存储和检索数据[11]。Neo4j让查询图形数据变得易于学习、理解和使用,但同时也融入了其他标准数据访问语言的强大功能。
3总结
医疗大数据的分析与决策研究核心在于医学知识的表示,与其相关的医学信息的抽取、融合和分析显得尤为重要。本文阐述了从多源异构的大数据中,如电子病历、各种医学指南、专家共识等数据源中获取数据,通过自然语言的相关技术,如医学实体抽取、医学实体关系抽取、医学实体属性抽取、医学知识融合等,在语义层面对医学大数据进行了统一组织和表达,并构建了糖尿病医学知识图谱。最终促进患者不断掌握糖尿病管理所需的知识和技能,提高糖尿病患者的自我管理能力,对糖尿病的防控起到了积极的作用。
参考文献:
[1]Gruber TR.Toward principles for the design of ontologies used for knowledge sharing[J].International journal of human-computer studies,1995,43(5-6):907-928.
[2]奥德玛,杨云飞,穗志方,等.中文医学知识图谱CMeKG构建初探[J].中文信息学报,2019,33(10):1-9.
[3]孙郑煜,鄂海红,宋美娜,等.基于大数据技术的医学知识图谱构建方法[J].软件,2020,41(1):13-17.
[4]修晓蕾,吴思竹,崔佳伟,等.医学知识图谱构建研究进展[J].中华医学图书情报杂志,2018,27(10):33-39.
[5]Xu K,Zhou Z,Hao T,et al.A bidirectional LSTM and conditional random fields approach to medical named entity recognition[C]//International Conference on Advanced Intelligent Systems and Informatics.2017:355-365.
[6]Zhang Y,Yang J.Chinese ner using lattice lstm[J].arXiv,2018(v1):02023.
[7]Zeng D,Liu K,Chen Y,et al.Distant supervision for relation extraction via piecewise convolutional neural networks[C]//Proceedings of the 2015 conference on empirical methods in natural language processing.2015:1753-1762.
[8]赵哲焕,杨志豪,孙聪,等.生物医学文献中的蛋白质关系抽取研究[J].中文信息学报,2018,32(7):82-90.
[9]Dieng-Kuntz R,Minier D,R??i?ka M,et al.Building and using a medical ontology for knowledge management and cooperative work in a health care network[J].Computers in Biology and Medicine,2006,36(7-8):871-892.
[10]任玉琪.基于CNKI的中文醫学知识图谱构建与应用[D].大连理工大学,2019.
[11]王鑫,邹磊,王朝坤,等.知识图谱数据管理研究综述[J].软件学报,2019,30(7):2139-2174.
收稿日期:2020-06-03;修回日期:2020-06-13
编辑/钱洪飞
