基于采样的深度神经网络测试方法研究①
2020-10-29苏警
苏 警
(安徽电子信息职业技术学院 软件学院,安徽 蚌埠 233000)
0 引 言
随着人工智能应用的发展,深度神经网络模型称为很多软件系统的重要组成部分[1-2]。因此,在实际应用环境中对深度神经网络模型进行有效的测试,是确保模型能够正常运行的必要手段。但是,对实际环境数据集进行标记需要花费大量的人力物力,造成巨大的成本。针对该问题,利用深度神经网络学习得到的分布表征,缩减测试所需的输入空间,有效减少测试数据的标注代价。
1 实际环境的深度学习神经网络测试
深度神经网络(Deep Neural Network,DNN)是由输入层、输出层以及多层隐藏层组成是的人工神经网络。DNN将输入转换为相应的输出,能够描述线性和非线性关系。神经网络后一层的输入是其前一层输出的线性组合,其中的激活函数φ使神经网络具有强大的拟合能力。与其他机器学习模型类似,深度神经网络首先会使用训练数据集进行参数训练(即神经元之间的权重wi,j和偏置bi)。实际上,深度神经网络学习到的是后验概率分布,即p(y|x)。
将经过训练的深度神经网络模型部署在特定应用环境中时,该深度神经网络模型可能并不能达到预期的精度。造成深度神经网络模型精度下降的原因有多种,例如模型在特定的训练数据集下发生过拟合或者欠拟合,或者是训练数据集和应用场景的数据集之间存在数据分布差异。在实践中,数据分布差异的情况时常发生。因此,在深度神经网络模型在投入使用之前必须经过充分测试。深度神经网络实现了归纳推理,它与基于逻辑推理的软件程序不同,因此深度神经网络测试与传统的软件测试不同。对于经过训练的深度神经网络模型,不存在确定且通用的测试方法。深度神经网络测试的大概流程是,提供预先训练好的深度神经网络模型和特定的操作上下文,以判断该模型在此上下文中的性能,判断的依据是深度神经网络模型的预测准确性。如果能够获得足够多的标记数据,那么深度神经网络测试并不是一个困难的任务。实际上,尽管可以从操作环境中收集未标记的数据,但是对数据进行标记的成本非常昂贵。因此,深度神经网络测试的关键中心问题是如何使用少量的带标记数据样本准确测试深度神经网络在其操作环境中的性能。
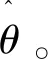
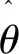
(1)
Var[H(X)]=E[Var[H(X|Z)]]+Var[E[H(X|Z)]]
(2)
式(2)中,总方差Var[H(X)]由两部分构成,第一部分是误差的均值E[Var[H(X|Z)]],第二部分是误差的方差Var[E[H(X|Z)]]。E[H(X|Z)]是关于Z的函数,而且有E[H(X)]=E[E[H(X|Z)]]。
可以利用Z的分布进行采样,并且由于E[H(X|Z)]的方差比H(X)小,可以估计E[H(X|Z)]而不是直接估计H(X)。如果可以制作一个完整的Z样本,即样本覆盖了Z的所有值zi,则估计的方差将会是估计E[H(X|zi)]所引入的方差。此外,如果H(X)的值完全由Z决定,则方差为零。但是,这两个条件难以被满足,尤其是在操作软件测试的复杂场景中。因此,要提高测试的效率,需要:(1)尽可能确定影响H(X)准确性的Z,以便使在每个zi条件下H(X)的方差最小;(2)尽可能选择Z中具有代表性的样本,以便可以很好地处理Z带来的不确定性。上述两点在实际实践的过程中互相矛盾的。直观地讲,H(X)的解释Z越“精确”,它的粒度就越细,而用小样本就越难代表它。因此需要小心地选择样本Z以在它们之间取得良好的平衡。用于提高测试效率的调节技术可以看作是常规白盒测试中结构化覆盖。然而,由于深度神经网络测试的黑盒性质,将这一想法应用于深度神经网络测试极具挑战性。而且深度神经网络模型的样本Z是一个高维向量,因此难以用小样本来表示。
2 基于采样的测试方法
给定训练过的深度神经网络模型M,从操作上下文中收集的N个未标记样本的集合S,从集合S中选择子集T并对T中的样本进行标记,子集T的大小为n=|T|≪N。使用T来测试模型M在样本S上的准确度,使估计误差尽量小。利用模型M和样本集合S的信息,试通过调节来实现有效的估计。首先讨论基于置信度的分层抽样调节,然后提出了一个解决方案,该方案通过模型M所学习的表示来进行调节,并通过交叉熵最小化来近似样本S的分布。
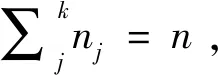
(3)
可以将最后一层隐藏层神经元的输出作为随机变量Z。该输出可以看成是训练数据的学习表征。操作上下文的数据不是独立同分布时,表征会比预测更稳定。对于经过训练的模型M,假设其最后一个隐藏层L由m个神经元ei组成。将每个神经元ei的输出Dei分成K个相等的部分,并定义函数fei(x)=j,表示输入x所对应的神经元ei的输出属于集合Dei,j。
令Sz1,…,zm={x∈S|fei(x)=zi}是S的子集,子集Sz1,…,zm中的元素与z=(z1,…,zm)一一对应。样本Z的概率分布PS(z)的定义为:
(4)
但是,由于样本Z具有较高的维数,要根据Z的分布从整个测试集S中获取样本T极具挑战性,更不用说实施分层采样了。对此,通过最小化PS(Z)和PT(Z)之间的交叉熵来选择样本集合T,即
(5)
其中,
(6)
在这种高维情况下,很难直接计算出最小值。由于深度神经网络通常会减少最后一个隐藏层中神经元之间的相关性[3],因此可以通过假设它们在计算最小化时彼此独立来进行近似。在这种情况下,可以通过最小化PS(Z)和PT(Z)之间的平均交叉熵来最小化CE(T),即
(7)
当PS(z)=PT(z)时,可以得到CE(T)的最优值。因此,模型准确度的估计可以表示为:
(8)
为了求解优化问题(7),提出了一种基于随机游走的输入选择算法(如算法1所示)。

表1 随机游走的输入选择算法
3 实验评估
使用Tensorfow和Keras框架实现了本文提出的方法。对于基于置信度的分层抽样,使用通过实验获得的最佳设置。样本分为三个层次,具有最高置信度前80%样本分配给第一层,将其后的10%分配给第二层,将最低的10%分配给第三层。为了获得大小为n的样本,分别从三个层次中选取0.2n、0.4n和0.4n个样本。对于实现基于表示的条件的基于交叉熵的采样,将每个神经元的切片数K设置为20。
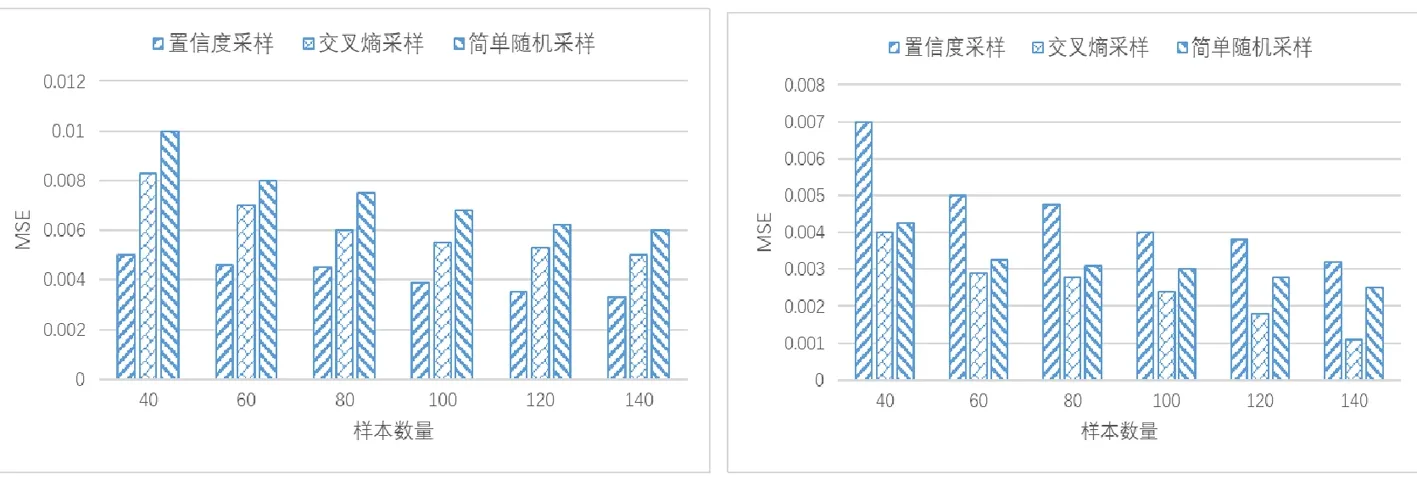
(a)训练数据集与操作环境数据集相同 (b)训练数据集与操作环境数据集不同
通常,可操作深度神经网络测试是在特定操作环境中检测深度神经网络模型的性能损失。假设深度神经网络模型已经使用训练集进行了很好的训练。实验采用的深度神经网络模型为LeNet-5[4],操作环境的数据集为MNIST[5]。训练数据集有两个,一个是原始的MNIST数据集,另一个是经过篡改标注的MNIST数据集。估计器的性能指标是平均平方误差(MSE)。实验是在PC上进行的,使用Liunx操作系统,CPU为i7-9700K,内存为64GB,GPU为英伟达GTX 1060Ti。实验结果如图1所示。图1(a)是训练数据集和操作环境数据集均为MNIST的MSE结果,图(b)是训练数据集为经过篡改的MNIST的MSE结果。由图1(a)可知,基于置信度的分层采样方法表现最好,其MSE最低。但是,如图1(b)所示,当训练数据集和操作环境数据集不一致时,基于置信度的分层采样方法具有最高的MSE。这说明基于置信度的采样具有较低的鲁棒性。对比图1(a)和(b)可知,基于交叉熵的采样方法表现最为稳定,其MSE均低于随机采样方法,具有较高的鲁棒性。
4 结 论
利用深度神经网络模型学习到的表征来提高操作环境中深度神经网络测试的效率,通过实验评估了提出的基于表征条件的采样方法的有效性。在后续的工作中,将对实验进行扩展。使用更多目前常见的深度学习模型(例如VGG-19,ResNet-50,Dave-drop)和数据集(例如ImageNet,MS-COCO,VisualQA,CIFAR-10)进一步验证本方法的有效性。
