基于频域稀疏自编码网络的音乐分离技术
2020-10-27吴修坤刘华平
曹 偲,吴修坤,刘华平
(网易云音乐 杭州网易云音乐科技有限公司技术中心,浙江 杭州 310052)
1 引言
Cherry 最先提出“鸡尾酒会效应”,即在嘈杂的环境中,人类可以轻易地将注意力集中于某一个说话者[1]。后来Bregman 试图研究人脑如何分析复杂的听觉信号,并提出了听觉场景分析框架。有别于“鸡尾酒会效应”的源分离,音乐分离的分离目标是组成歌曲的多个独立的信号源,如干声、伴奏成分。特别地,在SISEC 2018 音乐分离任务比赛中,独立的信号成分被细化为多个分轨信号,包括干声、鼓点、贝斯以及其他成分等[2]。近几十年来,由于很难对背景伴奏和干声进行有效建模,音乐分离一直是一个难题。直到近期,基于深度学习的方法在音乐分离中取得了较好进展。按照网络结构,这些优秀的音乐分离方法大致可以分为3 类,即基于CNN 网络的分离方法[3-6]、基于LSTM 的分离方法[7-8]以及RNN 和CNN 结合的分离方法[9-10]。LSTM 网络考虑了语音信号的时序相关性,但是由于时间依赖性无法进行并行运算,使得网络计算耗时较长。CNN 通过感受野获取信号局部特征,为了获取更大的感受野,需要更深层的CNN 网络,但深层网络意味着网络变大,且更加难训练。
此外,按照输入方式,这些方法可以分为两类:一类是输入时域波形特征(如Wav-U-Net[3]和Demucs[10]等),然后输出时域波形;另一类是输入时频域谱特征(如Spleeter[11]、MMDense-LSTM[9]和Open-Unmix[2]),然后输出时频域掩码,最后将时频掩码和时频点的点积求逆短时傅里叶变换获得时域波形信号。因此,通过时域或者时频域的信号特征,均可以取得较好的分离性能。然而,音乐分离问题依然存在很多问题,如分离的伴奏会丢失一些配器成分,导致听感上大打折扣。同时,分离引入的失真也是一个重要问题,如以时域波形作为输入特征的方法更容易引入新的频率分量,进而引入人工噪声。
本文试图提出一种稀疏自编码框架,在时频域特征上预先进行高维特征提取,然后结合CNN 网络用于音乐源分离。具体地,通过一个稀疏自编码器提取频域信号的高维特征,将自编码器的输出作为CNN 网络的输入,将CNN 网络的输出结果送入解码器,最后通过解码器将时频掩码恢复到和时频谱图相同的尺度。该方法很好地利用了频点之间的相关性来提高网络的拟合能力,增大了CNN网络的感受野。特别地,借鉴文献[5]采用两层叠加沙漏网络作为音乐分离网络。本文想法基于最初的创新想法,即将频域进行梅尔子带变换,并将子带域特征送入网络进行训练,最后输出时频域(Time-Frequency,TF)掩码。将梅尔频谱特征作为输入特征极大地提高了网络的拟合能力,并取得了较好的分离结果。因此,本文采用自编码器代替梅尔变换进行网络优化,并进一步验证了该方法的有效性。实验结果表明,基于稀疏数自编码的CNN网络获得了最优分离结果。
本文将在第2 节介绍相关分离工作,在第3 节分析稀疏编码网络,在第4 节详细描述基于稀疏编码的参数和网络训练环境,同时分析本文方法和其他先进分离算法的结果,最后总结全文。
2 相关工作
作为信息检索领域中一个重要的信号处理任务,音乐分离通常是将混合的歌曲信号分离为多个单独的源信号。目前,音乐源分离需要满足线性混合的假设,即一个混合信号xt∈RT是多个独立的信号源的线性组合:
经过短时傅里叶变换,式(1)中时域波形信号对应关系可以转换成时频域对应关系:
基于维纳滤波,估计的独立声源信号可以表示为:
其中,φ(x(f,t)) 表示混合信号源的相位,表示理想概率掩蔽(Ideal Ratio Mask,IRM)系数:
为了实现快速稳定的收敛结果,本文的目标代价函数为真实信号和估计信号幅度谱差值的L1范数:
3 音乐分离技术
本节描述稀疏编码网络结构,如图1 所示。稀疏编码网络主要是对频域信号进行编码压缩,用于CNN 网络进行音乐分离,并详细分析了编码网络对音乐分离的贡献。
3.1 频域稀疏自编码网络
稀疏自编码网络的思想是通过网络和传统方法预先提取一些高维特征,然后将高维特征融合并作为深度分离网络的输入。本文定义了稀疏矩阵编码模块,通过稀疏编码将频谱进行频谱维度的压缩,预先提取一些高维特征。具体地,先对STFT 幅度谱进行一维卷积,然后将卷积结果分别进行梅尔谱变换和稀疏编码处理。本文将梅尔谱和稀疏编码特征进行融合,获得稀疏编码的输出结果。由于频点特征存在信息冗余,会使深度CNN 网络难于训练,且加大了网络的计算复杂度。稀疏编码等效公式如下:
其中,Mel(b,f)表示Mel滤波系数,A(b,f)是稀疏编码权重矩阵,Bi(b)表示偏置向量,b表示编码变换维度(本文中傅里叶系数长度F为2 049,编码维度B为256,即将F维频域信号映射为B维特征)。获取的B维特征可以作为CNN 分离网络的输入特征,同时可通过解码矩阵将CNN 网络输出的B维结果进行解码获取F维Mask。
3.2 堆叠沙漏CNN 网络
通过分析选择2层堆叠沙漏网络作为分离网络。SH-4stack 方法[5]已经将堆叠沙漏网络用于音乐分离,并取得了良好效果,但只是简单将堆叠沙漏网络搬移到音乐分离任务中,没有将音乐信号中的物理意义和网络进行有机融合。此外,原始堆叠沙漏网络的网络结构庞大,计算复杂度高,因此SH-4stack 方法只实现了8 kHz 的音乐分离任务。本文将稀疏自编码网络应用于堆叠沙漏网络,极大地降低了沙漏网络的计算复杂度,提高了网络的拟合能力,实现了44.1 kHz 采样的音乐分离任务。特别地,对堆叠沙漏网络进行优化(如加入BN 层和Drop 层、调整下采样方式等)用来适应音乐分离任务,具体网络结构如图2 所示。
3.3 用于TF 掩码的解码模块
经过稀疏自编码模块和CNN 网络模块后,输出结果为b×t维的编码矩阵SASH(b,t)。本文采用解码矩阵得到TF 掩码:
其中,V(f,b)表示解码矩阵,为偏置向量。本文通过编码矩阵和解码矩阵实现了高维特征的提取和融合,提高了网络的拟合能力和计算时效性。特别地,本文采用稀疏编码模块将频点特征映射到一个高维空间,很好地利用了频点之间的相关性,同时扩大了CNN 网络的感受野。
4 实验结果与分析
4.1 实验设置
为了更加公平地验证本文方法的有效性,本文采用MUSDB18 数据集作为训练集合测试集。MUSDB18 数据集由SISEC2018 比赛提供,包含100首训练集和50 首测试集(总时长约10 h,采样率为44.1 kHz),且每首歌曲包含了混合信号和干声、伴奏成份。本文将100 首训练集中的94 首用于训练集,剩余6 首歌曲作为验证集,参数设置如表1 所示。
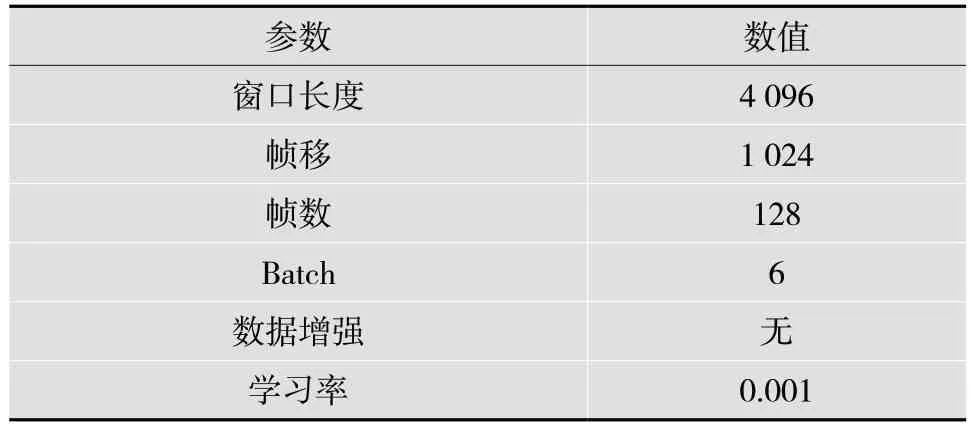
表1 基于稀疏自编码网络的训练参数设置
此外,本文采用tensorflow 框架建立和训练模型,训练工具为1 块NVIDIA 1080Ti GPU。网络的代价函数为误差的绝对均值,优化器为Adam。评价方式采用museval 包和BSSE-valv4 工具箱,评分标准为SDR。
4.2 分离结果分析
为了更好地验证和评价所提方法的效果,将所提方法与Demucs、Spleeter 等优秀分离方法进行对比。Spleeter 是优秀的分离方法,采用经典的U-Net网络作为分离网络,并加入空洞卷积提升网络的分离性能。Demucs 则是近期出现的先进的分离方法,采用Tas-net 对波形进行编码和解码,并采用LSTM网络作为分离网络。此外,采用SDR 指标进行评价。SDR 指标是目前主流的客观评价方式,值越高,说明音乐分离的性能越好。如表2 所示,本文方法在MUSDB18 数据集上获得了最优结果。
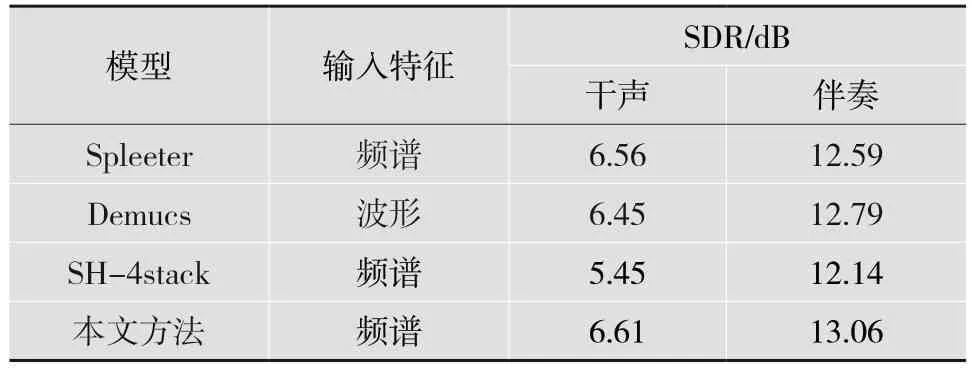
表2 本文方法和其他分离模型的SDR 分数结果(MUSDB18 数据集上)
其中,Demucs 给出了分轨模型,即分为干声、贝斯、鼓点以及其他。为了对比结果,本文将其中的贝斯、鼓点和其他成份合并为伴奏。与多个分离方法比较,基于本文获取的干声、伴奏均获得了最高分数。特别地,通过和SH-4stack 方法的对比结果可以得出,提出的稀疏编码网络结构提升了沙漏网络的分离能力。本文将梅尔频谱作为网络输入的特征之一,因为梅尔频谱模拟人耳听觉对实际频率的敏感程度,更好地突出了音高特性,使得网络提高了干声等分离成分的保真度,一定程度上解决了分离引入的失真问题。
此外,本文只用了MUSDB18 的100 首训练集作为训练集和验证集,而Spleeter 方法用了额外数据集(没有公开),Demucs 方法则用了额外的150首训练集,也从侧面说明了基于稀疏编码网络具有更强的拟合能力。
5 结语
本文提出了一种基于频域稀疏自编码网络的音乐分离神经网络,通过预提取一些高维维度来提高音乐分离的性能。特别地,本文很好地考虑了频点之间的相关性,并通过稀疏自编码网络将频点信息映射到高维空间,提高了网络的拟合能力和运行效率。实验结果表明,与现有的多个优秀分离算法相比,本文提出的稀疏自编码网络获得了最高的SDR 分数。本文目前只考虑了混合信号的频谱幅度谱,未来的工作是将相位特征进行建模,并应用于音乐分离任务。
