基于超网络和投影降维的高维数据流在线分类算法
2020-10-15茹蓓
茹 蓓
(新乡学院计算机与信息工程学院 河南 新乡 453003)
0 引 言
近年来出现了许多数据流的实时分类应用,例如:金融市场通过对证券股指、期货数据进行实时分类和预测,能够快速察觉市场行情的变化,有助于提高投资收益和降低风险[1];社交媒体用户每天需要发布大量的图像数据流,通过对图像进行实时分类和预测,能够快速检测出非法图像[2]。对数据流的实时分类和预测存在巨大的应用价值[3],而图像、文档等高维数据是数据流的一个重要组成部分,其高维特性严重影响了分类器的计算效率和分类性能,成为实时数据流分类的一个难点[4]。
增量学习思想是当前数据流实时分类的一个重要手段,文献[5]提出了噪声消除的增量学习分类器,使用互信息近邻来检测噪声样本,通过增量学习检测数据流的类标签。文献[6]提出基于样本不确定性选择策略的增量数据流分类模型,从相邻训练集中按照样本不确定性值选出“富信息”样本代表新概念样本集。增量学习主要通过一些评价指标检测出某些判别能力强的新到达样本,然后结合这些样本对分类器进行更新,此类方法主要以上一个时间窗口的模型为基础,导致变化剧烈窗口的训练集存在明显的偏差,难以实现理想的分类准确率。文献[7]将回归系统应用于时变环境,实现了回归神经网络,该方法通过回归模型主动学习神经网络的模型参数,实现了较为理想的性能,虽然采用了简单的神经网络结构,但该模型的回归模型依然存在训练时间长的问题。
基于神经网络的数据流分类器一般通过增量学习机制动态地更新神经网络的参数,采用多层神经网络处理高维数据流才能获得更好的效果,但多层神经网络的参数量较多,实时学习的难度较大[8]。本文从一个新的角度出发,对高维数据流进行分析和分类处理。采用超网络建模高维数据流的数据空间,利用基于高斯核的投影技术将高维数据投影到低维空间。利用贝叶斯模型的先验分布、后验分布和似然信息拟合数据流的动态特性,设计了贝叶斯模型的实时更新方法,实现了对高维数据流的实时分类处理。
1 高阶模型的超网络
超图[9]是离散数学中有限集合的子系统结构,超图的边为高阶边,称为超边,超边连接两个以上的顶点。将超图表示为G=(V,E),其中V和E分别是顶点集和超边集。一条超边是V的一个子集,超边的权重满足w(e)≥0。顶点的度和超边的度d(v)和δ(e)分别定义为:
(1)
δ(e)=|e|
(2)
式中:|e|为边e的基数,将度等于k的超边简称为k-超边。超边的度值越高,则该超边的模式判别能力越强。如果一个超图的超边均为k-超边,则称其为k-均匀超图,所以2-均匀超图即为传统意义的图,3-均匀超图即为三元组的集合,以此类推。
超网络[10]是超图结构的高阶表示,超网络的顶点定义为一个变量及其取值,超边定义为顶点间的高阶连接,超边的权重表示连接的强度。超网络是大量超边的集合,可表征高维数据特征之间的高阶关系。
将超网络定义为一个三元组形式H=(V,E,W),其中W表示超边的权重集。超边是两个以上顶点的集合,表示为:
ei={vi1,vi2,vi3,…,vi|ei|,yi}
(3)
式中:yi表示第i个超边ei的类标签。超边的权重反映了超边对于类标签的判别能力,所以可将超边考虑为一个弱学习机,学习分类器所需的特征子集。图1为一个超网络及超图结构的示意图。

(a)超网络实例
给定一个数据点集x(n)、一个类标签集Y和一个超网络H,选择x(n)超边加权调和值最大的标签,将该极大值标签作为x(n)的类标签。超网络模型的分类步骤如下:
步骤1计算超边集E中所有y∈Y超边的权重之和:
(4)
式中:w(ei)表示ei的权重。
步骤2选择总权重最大的标签作为x(n)的标签:
(5)
定义两个指示函数f(x(n),ei)和φ(y(n),yi),如果ei匹配x(n),则f(x(n),ei)=1;如果y(n)=yi,则φ(y(n),yi)=1,即:
(6)
(7)
式中:c(x(n),ei)表示匹配的数量;θ为匹配的阈值,用于增强对噪声数据的鲁棒性。
超网络的模型结构对分类算法的性能具有极大的影响,学习程序的目标是寻找最优的超边集,即从一个特征集选出特征子集。该问题主要分为3个子问题:(1)选择构建超边的变量子集;(2)确定超边的度;(3)确定模型的超边数量。子问题(1)和(2)影响分类器的分类性能,子问题(2)和(3)影响模型的计算复杂度。如果特征为二进制值,那么特征集的规模为22|x|,|x|为数据的维度,超网络模型对于高维数据的计算复杂度较高,因此为超网络设计一个高效的模型学习方法,即基于贝叶斯模型的超网络更新机制。
2 基于贝叶斯模型更新超网络
图2为超网络数据流分类算法的结构框图,使用贝叶斯更新方法学习超网络的结构,学习的内容包括生成超边、更新超边权重和评估超网络模型。首先,从训练数据集提取超边,构建初始化超网络,将超边和训练数据匹配计算超边的权重。然后,将训练集分类估算模型的适应度,将低权重超边替换为新生成的超边,动态地修改模型。

图2 超网络高维分类算法的结构框图
2.1 贝叶斯模型的学习方法
引入贝叶斯模型学习超网络,贝叶斯模型假设后验分布和先验分布分别为当前种群(当前超网络)和上一代种群(上一代超网络)。模型的适应度定义为后验概率,适应度同时反映了数据的判别能力和模型的复杂度。

(8)
式中:p(Y|X,Ht)和p(Ht|X)分别为似然信息和先验分布;p(Y|X)是一个正则常量。后验分布关于似然信息和先验分布的乘积成正比例关系:
p(Ht|X,Y)∝p(Y|X,Ht)p(Ht|X)
(9)
定义Ht的适应度函数Ft为后验分布的对数,目标函数变为最大化式(10):
Ft=logp(Y|X,Ht)+logp(Ht|X)
(10)
即
(11)
2.2 采用贝叶斯模型学习超网络结构
计算超网络的适应度需要定义模型的先验信息和似然信息,将经验先验分布p(Ht|X)定义为目标问题的先验知识。超网络的先验信息包括两点:(1)变量和类标签之间的相似性矩阵,采用基于投影的相似性矩阵选择数据,产生初始化超边;(2)缩小模型的规模,从上一次的后验分布p(Ht-1|Y,X)计算当前迭代的经验先验分布:
p(Ht|X)∝p(Ht-1|Y,X)
(12)
(13)
式中:Et为Ht的超边集;P(e)表示超边e的产生概率;PI(xi)表示选择变量xi的概率;PI(xi)关于xi和类标签之间的相似性成正比例关系。仅需要对每个新到达时间窗口计算一次PI(xi),在更新过程中无需改变该概率值。通过上述方法可确定超网络模型的3个主要参数:超边包含的变量、超边的度和超边数量。
似然定义为从Ht正确分类Y的条件概率,X表示了Ht的判别能力。统计模型对训练数据正确匹配和错误匹配的数量,再计算每个超边的加权调和值,通过评估超边的判别能力估算似然信息。如果超边和一个数据实例的标签匹配,则认为该超边正确匹配,否则匹配失败。总似然计算为各个数据实例似然的乘积:
(14)
将经验似然定义为:
p(y(n)|x(n),Ht)≡
(15)
式中:w(ei)为第i个超边的权重;Et为Ht的超边集合。如果经验似然小于0,则将其设为一个小的正数来防止出现负似然的情况。可获得:
(16)
在训练程序中,如果正确匹配一条超边,那么fi(n)·φi(n)和fi(n)(1-φi(n))分别等于1和0;如果错误匹配,则分别为0和1;如果匹配失败,则两个值都为0。
超边的权重是关于正确匹配情况和错误匹配情况的函数:
(17)
式中:α是小于1的常量,用来增加正确预测的概率;β是一个小的正常量。因为度小的超边匹配率更高,所以如果两个超边的度接近,则选择度小的超边,β不仅减少了模型的复杂度,而且增加了模型的泛化效果。如果w(e)小于0,则设为0,防止出现负权重。
结合式(13)的经验先验和式(16)估算的似然,将超网络的适应度修改为:
Ft=logp(Y|X,Ht)+logp(Ht|X)≈
(18)
式中:λ和ζ均为正常量,λ负责调节模型的大小,ζ负责调节先验信息的变量选择能力。
综上所述,提高适应度的措施有三点:(1)每次迭代保留权值高的超边;(2)选择PI(x)概率大的变量生成超边;(3)在保持模型判别能力的情况下,尽量减少超边的数量。超网络更新的结束条件是在连续几次迭代后,Ft均不大于Fmax,或者达到最大迭代次数Imax。
2.3 基于高斯核投影的相似性度量
直接度量高维数据的相似性不仅准确率低而且计算复杂度也较高,因此本文采用高斯核的投影技术计算高维数据之间的相似性矩阵。设S(xi,xj)为数据xi和xj间的相似性,其投影矩阵定义为[P]i,j=S(fDR(xi),fDR(xj)),其中:i和j是矩阵的行和列,fDR为投影函数。本文的目标是将高维空间的数据点投影到低维空间,设目标相似性矩阵是一个方阵T,则需要优化以下的目标函数:
(19)

表示矩阵M的l1范数。如果每对数据点超过了目标相似性,此时的目标函数则是最小值。


(20)
设c(x)为低维空间的相似性度量(例如:欧氏距离),可将目标矩阵T中的元素定义为:
(21)
式中:σc为缩放因子。
采用核方法实现投影处理,设Φ=φ(X)为Hilbert高维空间[12]的数据矩阵,φ(X)为高维空间的投影函数,然后学习从高维空间到低维空间的线性映射。将矩阵W重新定义为:
W=φ(X)TA=ΦTA
(22)
式中:A∈Rn×m为系数矩阵。将投影定义为数据点的线性组合,可获得以下的投影方法:
YT=WTΦT=ATΦΦT=ATK
(23)
式中:K=ΦΦT∈Rn×n是数据的核矩阵,表示Hilbert空间数据点的内积,即Kij=φ(xi)Tφ(xj)T。
核方法学习系数矩阵A,采用梯度下降法优化目标:
(24)
(25)
2.4 学习超网络的方法设计
贝叶斯更新模型包括:生成超边、选择超边和更新超边。生成超边需要确定两个属性:(1)超边的数据变量;(2)超边的度。图3为生成超边的示意图。

图3 生成超边的示意图
根据变量之间的投影相似性矩阵选择相似的变量,相似的变量组成一条超边。式(13)的PI(xi)计算为:
(26)
式中:I(xi;y)表示变量xi和类y间的相似性(基于投影计算高维数据的相似性);η为一个非负常量,该常量防止相似性过小。将η和式(18)的ζ设为反比例关系。
根据Ht-1超边度的概率决定Ht超边的度:
(27)

算法1生成超边的程序
输入:数据集S={S1,S2,…,SN}。
输出:超边e。
/*初始化程序*/
n←从|D|随机选择数据样本;
d←D[n];
K←通过式(27)计算边的度;
For eachkfrom 1 toKdo
idx←式(26)选择变量;
val←d数据的xidx;
v←(idx,val);
e←e∪{y(n)};
end for
e←e∪{y(n)};
w(e)←0;
在迭代过程中删除低权重的超边,增加新的超边,但可能存在相似的冗余超边,导致计算复杂度升高。因此式(18)的适应度有效维护了超网络的大小,如果Ft大于Ft-1,则缩小超网络,否则扩大超网络。
设Rt和Gt分别表示在第t次迭代删除的超边数量和新产生的超边数量。将Rt定义为一个关于t的函数,Gt定义为一个关于Rt的函数,Rt和Gt分别定义为:
(28)
Gt=γt·Rt
(29)
式中:Rmax和Rmin分别表示Rt值的上界和下界;κ为一个常量,控制Rmax到Rmin的变化速率;γt为泛化模型的比例系数,定义为:
(30)
式中:ΔFt=Ft-Ft-1;τ控制种群缩小的速度,如果τ=0,那么种群规模保持不变。
图4为基于贝叶斯的超边更新算法流程图,根据数据集的先验知识生成初始化超网络,将超标权重和特征的判别能力作为贝叶斯的似然信息,将超网络的复杂度和适应度作为贝叶斯的后验分布,贝叶斯迭代地学习最优的超网络结构。基于贝叶斯的超边更新算法伪代码如算法2所示。

图4 基于贝叶斯的超边更新算法流程示意图
算法2基于贝叶斯的超边更新程序
输入:训练集D,所有变量的相似性矩阵SM,第t次迭代删除的超边数量Rt,第t次迭代新生成的超边数量Gt,第t次迭代的超边集Et,第t次迭代的超网络Ht,最大迭代次数Imax,H0的初始化超边数量Hinit。
1.E0←NULL,H0←NULL;
//初始化
2.计算SM(D,SM);
//式(26)
3.for eachifrom 1 toHinitdo
//建立初始化模型
4.ei←生成超边;
//式(27)
5.wi←评价权重;
//式(17)
6.E0←E0∪ei;
7.end for
8.利用式(18)评估当前模型的适应度;
9.E1←利用式(22)删除低权重超边;
10.for eachtfrom 1 toTdo
//超边迭代更新模块
11. forifrom 1 toGtdo
12.ei←生成超边;
//式(27)
13.wi←评价权重;
//式(17)
14.E0←E0∪ei;
15. end for
16. 以式(18)评估当前模型的适应度;
17. if未满足结束条件then
18.H←H×Ht;
19. eles
20. break;
21. end if
22.Et+1←删除低权重超边;
//式(28)
23.数据流分类
3 实 验
3.1 实验环境和实验方法
实验环境为PC机,处理器为Intel Core i5-4570,内存为16 GB,操作系统为Ubuntu 14.04 LTS,软件的编译环境为MATLAB R2017a。
将数据集排列成序列形式,每个到达数据首先用来测试在线分类器的分类性能,再用来更新分类器的模型。每组实验将每个数据集做10次置乱处理,置乱数据集作为输入数据,独立完成10次实验,统计10次实验的平均误差率和标准偏差值。
3.2 实验数据集
采用10个UCI高维数据集作为实验的benchmark数据集,表1为benchmark数据集的基本属性。数据集排列成序列形式来模拟数据流。

表1 10个高维benchmark数据集的基本属性
3.3 对比实验方法
选择4个近期的数据流在线分类器作为对比方法:
(1)基于演化的在线贝叶斯分类器[13],简称为OnlineBayes,该方法与本算法同属于采用贝叶斯分类器的在线分类方案。
(2)基于元神经元的脉冲神经网络分类器[14],简称为OnlineSpikingNeural,该方法是基于神经网络的在线分类器。
(3)基于混合分类回归树和模糊自适应谐振网络的在线分类器[15],简称为FAM-CART,该方法较为新颖,且性能较为突出。
(4)在线的广义分类器[16],简称为onlineuniversal,该分类器支持多种类型的数据流。
本文算法简称为HypernetworksBayes。
3.4 分类器性能实验结果
1)高维数据流的分类错误率。首先评估5个分类器对于10个高维数据流的分类准确率,采用分类误差率作为度量指标,图5为总体的统计结果。可以看出,HypernetworksBayes对于Biodeg和Spambase 2个数据集的分类错误率高于FAM-CART,HypernetworksBayes对于Ring数据集的分类错误率也高于onlineuniversal算法,但结果也较为接近。对于数据流的二分类问题,本文算法与其他优秀的分类器较为接近,但对于其他高维数据的多分类问题,本文算法的优势则较为明显。FAM-CART对于10个高维数据流均表现出较低的分类错误率,FAM-CART采用分类回归树和模糊自适应谐振网络2项技术,模糊自适应谐振网络具有较强的自适应和自调节能力,而分类回归树对于连续性数据流具有较强的处理能力,因此实现了较好的效果。比较OnlineBayes和HypernetworksBayes可见,HypernetworksBayes的分类错误率远低于OnlineBayes分类器,即本文的超图理论和基于高斯核投影的降维处理有效地提高了分类器的性能。总体而言,本文算法的分类错误率低于其他4种算法。

图5 5个分类器对高维数据流的分类错误率的比较
2)分类器统计检验。通过Friedman检验[17]测试分类器对于10个数据集分类结果的差异,Friedman检验的显著性设为0.05。Friedman检验获得的排名如图6所示。本文算法排名第一,且远高于第二名,再次验证了HypernetworksBayes分类器的性能优势。

图6 分类器的Friedman检验结果
Friedman检验能够比较多个分类器之间的性能,而验后比较检验(post-hoc test)能够详细比较多个分类器和单一分类器的性能。通过验后比较检验进一步分析分类器的性能,根据文献[18-19]的讨论,Hommel检验适合评估数据流的在线分类器的性能,所以采用hommel post-hoc对分类器进行验后比较检验分析,结果如表2所示。观察表中各个分类器的p-value值,HypernetworksBayes明显优于其他4个分类器,而对比方案中OnlineSpikingNeural和FAM-CART的性能也较为理想。
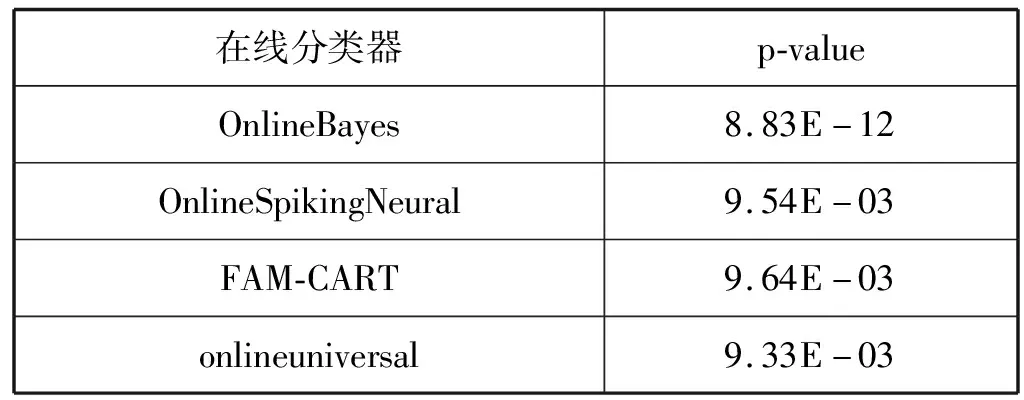
表2 分类器的hommel post-hoc检验
3.5 分类器的时间效率
时间效率是数据流在线分类器的一个重要性能指标,直接决定了分类器的应用价值。为了评估在线分类器的时间效率,统计了5个分类器每组实验分类程序的平均时间,结果如图7所示。可以看出,OnlineSpikingNeural和FAM-CART的处理时间远高于其他3个算法,这2个算法均为基于神经网络的分类器,在训练神经网络的过程中难以同时在网络性能和时间效率两方面均取得理想的平衡。受益于贝叶斯模型的高计算效率,OnlineBayes的时间效率最高。Onlineuniversal分类器不包含复杂的计算和模型,也实现了极高的时间效率。HypernetworksBayes的时间效率略低于OnlineBayes分类器和Onlineuniversal分类器,但是也足以满足处理实时数据流的时间需求。

图7 5个在线分类器的平均处理时间的比较
3.6 噪声数据流的分类实验结果
在实际的数据流应用中,数据流均伴随着不可忽略的噪声数据,因此测试了在线分类器对于噪声数据流的性能。随机选择一个错误类标签,替换训练数据集的正确标签,训练集的噪声数据比例分别设为10%、20%和30%。训练集为噪声数据集,测试数据集为无噪声数据集,使用10折交叉验证完成每组数据集的实验,计算10次独立实验分类错误率的平均值。因为Optdigits和Penbased两个高维数据集的分类错误率较低,所以重点测试并统计了噪声数据对于Optdigits和Penbased两个高维数据集的影响。
图8为Optdigits和Penbased两个高维数据集的实验结果。可以看出,随着噪声比例的增加,本文算法分类错误率略有升高,但上升幅度较小。OnlineBayes和onlineuniversal两个分类器受噪声的影响较大,几乎不具备噪声鲁棒性,因此可得结论:本文的改进措施有效地增强了分类器的鲁棒性。

(a)Optdigits数据集
4 结 语
本文设计了基于超网络和投影降维的高维数据流在线分类算法,利用贝叶斯模型的先验分布、后验分布和似然信息拟合数据流的动态特性,设计了贝叶斯模型的实时更新方法,实现了对高维数据流的实时分类处理。本文算法利用高斯核将高维空间的数据点投影到低维空间,实现了较高的高维数据流分类准确率,并且对于噪声也具有较好的鲁棒性。
本文模型依然存在一些限制:无法处理不平衡数据流,而不平衡数据流也是实时数据流领域的一个细分领域;仅支持数据维度权重相等的情况。未来将尝试引入分级的超网络模型,解决特征维度权重不相等的问题,从而可将本方案运用到推荐系统等多属性度量的应用中。
