结合Skip-gram和加权损失函数的神经网络推荐模型
2020-10-10李淑芝余乐陶邓小鸿李志军
李淑芝,余乐陶,邓小鸿,李志军
1.江西理工大学 信息工程学院,江西 赣州341000
2.江西理工大学 应用科学学院,江西 赣州341000
1 引言
随着电子商务的快速发展,关于产品和服务的信息过载无处不在。在淘宝、亚马逊等在线购物平台上,不断有大量的产品和服务来满足潜在的多样化需求。与此同时,对于购物者来说,在线应用商店中有成千上万的应用可供用户下载和使用,因此从中检索到满意的产品和服务是非常耗时的。如何更好地推广产品,并减少用户花费在检索上的时间,得到一个性能良好的推荐系统是当前亟待解决的问题[1-2]。
一般情况下使用历史数据中用户对项目的评分信息来进行推荐,如协同过滤技术[3-5],但其具有一些缺陷,如评分信息稀疏、推荐项目单一等。因此,研究人员提出了一系列使用比历史评分数据更多的数据来进行推荐,如基于内容的技术[6]、基于知识的技术[7-8]和基于社交网络的技术[9],这些技术都使用了其他附加信息,如隐式反馈信息、实体的属性和关系、社交网络数据、标签及多元信息[10]等,使用附加信息可以降低数据稀疏性,但也会导致计算量大,算法变复杂。而且随着用户或项目规模的急剧扩大,数据变得越来越稀疏[11]。数据稀疏给推荐算法带来的困难主要有以下3 点:(1)传统的协同过滤算法无法进行精确推荐,且用户-项目矩阵为稀疏矩阵[12];(2)用户-项目矩阵零元素较多,机器学习中参数更新计算量较大;(3)推荐系统仅为用户推荐经常出现在用户的评分列表中受欢迎的项目,因此不会推荐新的项目。针对以上问题,许多研究者从不同角度对推荐模型进行了相应的改进和完善。Covington等人[13]提出深度协同过滤模型,首先利用深度候选视频生成模型检索出候选集,然后利用深度排序模型对候选视频排序,模型根据用户历史活动、上下文以及人口学信息,利用多层全连接神经网络学习用户特征向量,但是该模型使用了许多附加信息,导致计算量大且精度较低。与文献[13]类似,Zanotti等人[14]利用神经网络语言模型CBOW和Skip-gram[15]学习电影多个来源的特征,发现隐含的语义关系,提取用户和物品更丰富的分布式特征表示,并根据学习的用户(物品)特征使用传统的基于用户(物品)近邻的协同过滤进行评分预测,但未考虑项目冷启动问题。为处理冷启动问题,Wang 等人[16]提出了一种通用的协同深度学习模型,通过降噪自动编码器[17]从用户评论中学习物品的深度特征表示,同时利用协同主题回归[18]将学习的物品语义特征与标准的概率矩阵分解模型相结合进行预测。类似的,Wei 等人[19]将物品内容信息用词袋模型转换成向量表示,然后使用堆栈降噪自动编码器学习内容特征,最后融合兼顾时间信息的矩阵分解模型timeSVD++[20]进行评分预测,但都没有解决参数过多、训练过程复杂、模型训练时间较长的问题。于是,Zhang 等人[21]提出了一种将协同过滤推荐算法与深度学习技术相结合的模型,该模型采用基于二次多项式回归模型的特征表示方法,对传统的矩阵分解算法进行改进,使其能更准确地获得潜在特征。然后,将这些潜在特征作为深度神经网络模型的输入数据,作为模型的第二部分,用来预测评分。但是文献[21]并没有平衡受欢迎项目和不受欢迎项目的新颖性,导致该模型一直推荐流行的项目。
为解决上述方法存在的推荐精度低及推荐项目单一性的问题,本文提出了一种基于Skip-gram 项目嵌入和加权损失函数的深度神经网络的推荐模型DSM,首先采用3 层ReLU 层来对输出向量进行回归,在没有使用其他附加信息的前提下提高了推荐精度;其次,将Skip-gram 项目嵌入加入到推荐模型中,每个项目表示为一个稠密的向量,解决了计算量大的问题,并且采用加权损失函数,平衡了历史评分数据集中项目的受欢迎程度,保证了推荐项目的新颖性;最后,在APP数据集和Last.fm数据集上的对DSM模型进行验证。
2 算法描述
2.1 问题描述

2.2 模型的架构
DSM模型的基本思想是将推荐问题看作预测回归问题,利用用户的历史项目评分列表,对用户将来喜欢的项目进行回归分析。模型的结构如图1所示,模型的输入是用户的历史评分项目列表,输出是用户的首选项目。

图1 DSM模型的体系结构
参考文献[13]中隐层深度效果的对比,拥有3 层ReLU 层(宽分别为1 024、512、256)的模型能够得到最优的结果,并且计算量也不会太大。此基础上再增加一个ReLU层可提高模型的命中率,但随之时间复杂度将会增加,总体来说对模型没有太大的影响。使用ReLU层作为隐藏层的原因是它可以调整线性单元,且该激活函数不会在浅梯度上饱和。因此,本文采用包含3 层ReLU 层的结构来构造深度神经网络模型,其第一层是输入层Lin,用于向量的输入;第二层到第四层是3 个ReLU 层(L2到L4),学习从输入向量到输出向量的映射关系;第五层是输出层Lout,利用回归分析预测用户首选项目。
2.3 Skip-gram项目嵌入
项目嵌入最早由Barken 等人2016 年在文献[22]中提出,其主要思想是假设在一个静态的环境,将用户的项目列表视为文本中的一个单词,其中所有的项目都由用户在相同的上下文中进行评分,不考虑用户对项目进行评分的顺序和时间,虽然这样会丢失项目的空间和时间信息,但仍然可以产生比传统方法更好的性能,因此,本文将项目嵌入引入到深度神经网络中。考虑到用户对项目评分的随机性以及偏好程度的不同,用户对项目评分是任意顺序的,对此为了更好地对项目进行描述,本文模型按字母顺序对用户项目列表中的项目进行排序。项目嵌入是将高维稀疏的原始数据表示为更密集的低维向量,假设一共有m个唯一且不重复的项目,使用One-hot 进行编码之后得到的向量表示为ℝm,该向量每个维度的值是0 或者1(ℝm=[0,0,0,1,…,0]),但此时得到的向量维度等于项目数m,并且非常稀疏。通过项目嵌入方法将项目嵌入到一个低维空间ℝn(n≪m),再构造一个从ℝm到ℝn的线性映射,每一个ℝm的矩阵M都定义了ℝm到ℝn的一个线性映射。嵌入向量的维度数一般是项目总数的4次方根,即n= m4 ,大大降低了维度,因此可以减少计算量,得到的密集向量用v(i,j)表示。
本文采用Skip-gram 模型[15]进行项目嵌入,按照字母顺序对每个用户的项目进行排序,使用当前词作为输入,经过连续映射层到Log-linear分类器,来预测指定窗口内位于该词前后的词。增加窗口的大小可以改善学习到的词向量的质量,但是也增加了计算复杂度。由于离得最远的词通常与当前词的关系要远远小于离得近的,所以给那些离得较远的词较小的权重,使得它们被采样到的概率要小。通过训练复杂度可确定窗口的大小,训练复杂度的公式为Q=C×(D+Dlb(V)),其中C为词的最大距离,D为词向量维度,V表示单词的大小。根据训练复杂度公式进行实验,以训练时间量化复杂度,实验结果如图2 所示,发现具有23 个最大距离项目性能最好,故本文使用项目ij预测其23 个最大距离项目。这些项目都是连续的向量,映射可以看作是含有一层隐藏单元的神经网络,用于项目嵌入的Skip-gram模型如图3所示。

图2 训练时间与最大距离数的关系

图3 Skip-gram模型
Skip-gram 模型训练的目标是调整项目向量,这些向量用于预测用户评分历史中的相似项目。给定一个训练项目的序列,Skip-gram采用最大似然估计,模型中涉及的训练实例越多,模型的精度越高,但是计算量也就越大。Skip-gram 模型使用SOFTMAX 函数定义,由于项目集数目可能很大,可采用负采样计算,如公式(1)所示,对于每个,通过Unigram 分布得到k个负样本。 是项目的输出词向量项,in是k个负样本的其中一个样本,对于大的数据集,k取值为2~5,而对于小数据集,k一般取值5~20。
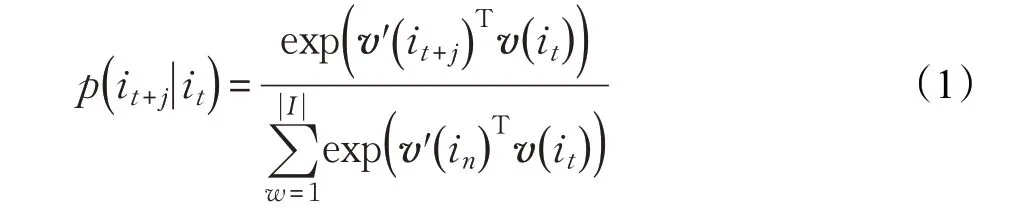
项目嵌入处理后,每个项目由一个长度为e密集的数值向量表示,其中参数e是用于表示Skip-gram 模型中一个项目的特征数。

2.4 加权损失函数及网络训练


图4 APP数据集项目的权重
图5 Last.fm-1k数据集项目的权重


算法1DSM模型的训练算法

2.整个数据集中随机抽样用户U()PE的百分比,按统一分布从每个用户的排名历史I(uk)中提取Q 个项目;
3.使用Q 个项目和项目嵌入中的每一项组成in-out对
4.前向传播:
(2)对于所有用户使用公式(3)计算当前迭代的损失函数Losssum;

3 实验结果与分析
3.1 数据集
在实验中,本文使用以下两个数据集来评估DSM模型的性能。第一个数据集是TalkingData 提供的移动应用程序安装数据集APP dataset[25]。APP 数据集经过预处理,本文实际实验的数据集包含221 个应用程序,177 名用户,即历史评分矩阵的用户数 ||U 为177,项目数 ||I 为221,大多数用户经常在移动设备上使用21 到30 个应用程序。另一个数据集是Last.fm-1k 数据集,经过预处理,本文实际实验的数据集包含983 个用户和148 725 首歌曲作为音乐推荐,即历史评分矩阵R||U×||I的用户数为983,项目数为148 725。图4和图5是使用公式(4)中线性插值函数对应用程序及歌曲分配权重,所有的权重都在0.5到0.6范围之间。
3.2 实验的设置
本文使用以下模型作为基准方法进行比较,分别为基于项目的协同过滤方法(Item-CF)[3]、RBM[26]、NADE[27]、Deep Belief Network(DBN)[28]以及基于神经网络结构的矩阵分解模型(MF by NM)[29]。Skip-gram 模型使用了DeepLearning4J开源平台来实现,从而构建了DSM模型。
本文所述方法的参数如表1所示。对于所有方法,其参数都是通过反复试验来调整的。对于Item-CF,APP数据集中参数设置为100,Last.fm数据集设置为1 000;对于RBM方法,APP数据集参数 ||L 设置为150,Last.fm数据集设置为2 000;对于NADE方法,本文设置了与RBM方法相同的参数;对于MF by NM,APP数据集中参数c 设置为50,Last.fm数据集中设置为1 500;对于DSM 模型,本文将L2设为4e,L3设为3e,L4设为2e 是实验中需要调优的参数),因为在推荐Youtube 视频也是这样设置的[13],在所有被研究的具有不同数量的隐藏层和单元的体系结构中,该设置的性能最好;本文对DBN 训练中不同的RBM 层数进行了评估,发现当RBM 层数设为5 层时,对于每层隐藏单元数,APP 数据集设为150,Last.fm数据集设为2 000,所采用的DBN结构在推荐下达到了最佳性能。Srivastava 等人[26]指出在深度神经网络中添加更多的层并不是最好的,添加层数过多会导致严重的过拟合,即在DSM模型和DBN中添加更多的层和神经元单元并不能提高推荐性能。

表1 实验中比较方法的参数
每个推荐方法在实验中还涉及另外两个参数来检验其性能。第一个参数是所考虑的推荐项目Q的数量,第二个参数是训练数据占所有数据样本的百分比PE。因此,本文在实验中相应地设置了两种方案:第一种方案是将PE设置为0.95,使用95%的数据集作为训练数据,其余5%的数据集作为测试数据。根据数据集中项目数量的大小,APP数据集中用户APP数量最小为10,推荐项目Q的数量依次设置为1、2、4、6、8;Last.fm数据集中用户歌曲数量最小为100首,推荐项目Q的数量设置为10、20、50、70 和90。第二种方案是预先定义推荐项目Q的数量,将训练数据的PE从0.75 调整为0.95,以0.05 为区间,对于APP 数据集,由于DSM 模型在第一个方案中产生了最好的性能(参见第3.3.2 小节),故本文将推荐项目Q设置为4,同样的,在Last.fm数据集中本文将推荐项目Q的数量更改为20 个(参见3.3.3小节)。

本文采用MAP(Mean Average Precision,平均精度)方法和多样性方法对模型的性能和其他方法进行评估。当查询有多个相关对象时,MAP 提供了信息检索质量的单图度量,本文将用户输入向量中的项目作为查询,将用户输出向量中的项目作为查询的相关对象,通过公式(7)计算出,它是第k个用户的平均精度值,j是排名,Q是推荐项目的数目,表示了排名j的对象是否是uk喜欢的项目。公式(8)中定义的为给定截断排名j处的精度。一组Q个测试数据样本的MAP值就是测试集中所有样本平均精度的平均值,MAP值越大,推荐性能越好。

3.3 实验结果
3.3.1 调优参数e
DSM 模型中项目嵌入的特征数e是推荐性能的一个决定性参数。如果参数e设置得很小,会导致项目嵌入到一个压缩空间中,导致深度学习中项目表示的信息丢失。如果参数e设置得很大,则会导致学习特征空间非常稀疏,导致计算量很大,并且性能没有任何提高。在实验前期准备阶段,本文通过反复试验对参数e进行了调优,得出在APP 数据集和Last.fm-1k 数据集中,随着e的增大,MAP的性能逐渐增加,多样性性能逐渐下降,直到e设置为100 时MAP 性能保持稳定,e设置为300时多样性性能保持稳定。因此在接下来的实验中,对于项目嵌入e的特征数,本文将APP数据集中设置为100,Last.fm数据集设置为300。
3.3.2 第一种方案的结果
图6、7 是3.2 节中设计的第一个方案的实验结果。当PE值增加时,所有方法的MAP 测量精度也在稳步增加,而所有比较方法的多样性所测量的新颖性也在逐渐减小。表2、3中的数据为调整百分比PE时得到的标准差。
图6、表2可以看出在APP数据集中Pro-Ave方法在精度上比其他方法提高了10%~20%左右,Ran-Max 方法在新颖性方面比其他方法提高了3%~10%左右,因此从本文提出的模型派生的方法的性能均优于其他方法。
图7、表3 的Last.fm数据集的数据可以看出类似的实验结果。对于这两个数据集,无论是准确性还是新颖性,PE值设为0.90时,所有方法的性能都趋于稳定。

图6 APP数据集中各类模型的MAP值、Diversity值(1)

图7 Last.fm数据集中各类模型的MAP值、Diversity值(1)
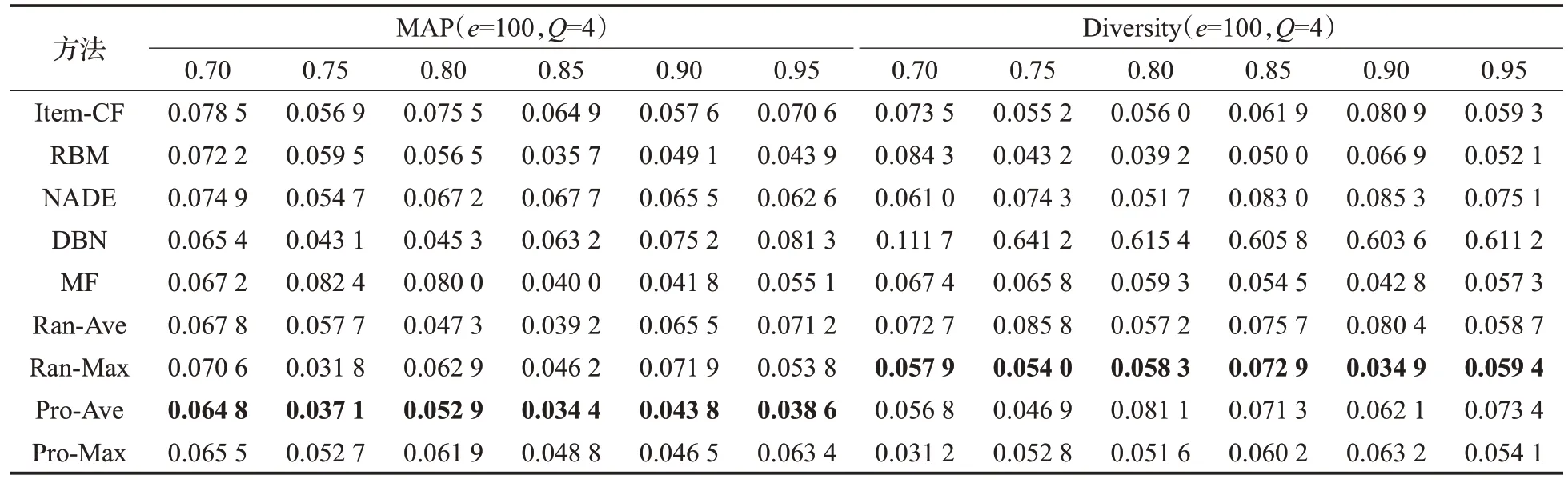
表2 模型在APP数据集上的标准差(1)

表3 模型在Last.fm数据集上的标准差(1)
当增加更多的数据来训练这些方法时,由于用户之间的关系、项目之间的关系和用户、项目之间的关系被更加细致地描述,因此它们的性能得到了提高。例如,Item-CF方法的性能取决于项目在历史数据中的相似性度量,而DSM 模型的性能很大程度上取决于项目在嵌入空间中的相对位置。但是,当PE大于0.90 时,所有方法的性能都是稳定的,这可以解释为当使用足够的数据来训练方法时,过多的数据会导致过度拟合而抵消了增加更多训练数据所带来的积极影响。
在推荐准确度方面,对于所有PE值,DSM 模型的性能都优于其他方法。该模型通过深度学习用户的历史评分项目,更准确地描述用户的偏好,并且可以将传统的Item-CF用于学习用户和项目之间的显式关系。然而,在深度学习方面,它可以用来学习用户和项目之间的内在关系。其中采用5 层深度神经网络来学习项目之间的内在关系,即通过输入向的神经网络来组合表示输出向量。此外,从实验可以看出Pro-Ave 方法的性能优于Pro-Max 方法,而Ran-Ave 方法的性能优于Ran-Max 方法。Covington 等人[13]也验证了平均池化方法在生成推荐深度学习的输入向量方面优于最大池化方法。池化使得特征参数减少,其中平均池化对领域内特征参数求平均,保留了更多的项目之间的内在关系,而最大池化只是提取特征中的最大值,会使估计值方差增大,并且丢失许多信息,因此在输入向量方面平均池化优于最大池化。
在推荐新颖性方面,可以看出DSM 模型推荐的项目比其他方法推荐的项目更加多样化。Item-CF生成的项目之间是相似的,因为给定项目的相邻项目比非相邻项目相似性更高。此外,对于给定的项目,受欢迎的项目通常比邻近项目列表中不受欢迎的项目出现得更频繁。因此,在其他方法的推荐列表有大量的受欢迎的项目,导致了推荐的项目新颖性较低。然而,使用公式(4)所述的加权损失函数,那些不受欢迎的项目也被给予了与那些受欢迎项目近似的权重。虽然不太受欢迎的项目的权重相对小于比受欢迎的项目的权重,而不受欢迎的项目的数量远远大于受欢迎的物品的数量,因此,不受欢迎的项目的权重的总和要大于流行的项目权重,在该模型中不受欢迎的项目比其他方法更有可能被推荐。
3.3.3 第二种方案的结果
图8、9 是设计的第二种方案的实验结果(本文3.2节介绍)。从图中可以看出,在精确度上,在APP 数据集上所有方法的性能都比Last.fm-1k数据集好,然而在新颖性方面是相反的情况。在图8中,本文对APP数据集的Q值从1 到8 进行递增;在图9 中,Q值从10 变化到90。表4、5 中的数据为调整推荐项目Q的数量时得到的标准差。
当推荐的准确性提高时,推荐的新颖性就会降低,因为此时推荐的项目与输出向量的正确项目更加相似。本质上,项目的相似性是根据它们在用户评分列表中之间的联系来定义的,更精确的推荐意味着在相同的列表中推荐更多的项目,这也会导致新颖性的降低。
当推荐项目Q的数量设置很小的时候,正确项目被列为最重要的项目的可能性更小。但是当推荐项目Q的数量变大时,所有方法都会推荐不相关和相关的项目,导致准确性降低。从图8、9 可以看出当APP 数据集的Q设为4,Last.fm-1k 数据集的Q设为20 时,所有方法的精度达到其最大值。在精度上,Pro-Ave 方法比其他方法有更好的性能,而在新颖性上,Ran-Max 方法比其他方法有更好的性能。所以在准确性和新颖性方面,从DSM 模型派生出来的方法比其他方法产生了更好的性能。从Ran-Max 方法得到的实验结果可以看出,可以使用随机抽样和最大池化来保证深度学习推荐的新颖性。因此,本文使用深度神经网络学习项目的内在关系,可确保项目关系可以在网络中被“记住”从而提高推荐精度,使用加权损失函数可确保用户的历史评分中项目可以频繁被推荐,从而改进推荐的多样性。

图8 APP数据集中各类模型的MAP值、Diversity值(2)

表4 模型在APP数据集上的标准差(2)

表5 模型在Last.fm数据集上的标准差(2)
3.4 DSM模型的复杂度


4 总结与展望
针对传统的协同过滤算法中存在数据稀疏性问题,本文提出了一种新颖的模型DSM:首先,对于每一个项目,都使用一个密集的数字向量来表示;然后,提出一种深度神经网络来预测用户对项目的偏好,并采用加权损失函数与线性插值函数相结合的方法来平衡推荐的准确性和新颖性;最后,使用平均池化和最大池化将用户的历史项目聚合到深度神经网络的输入向量中,采用随机抽样和分布抽样相结合作为样本项目的输出向量来训练深度神经网络。在APP和Last.fm数据集中的实验结果表明,DSM 模型在准确性和新颖性方面优于现有的模型。未来的工作考虑将项目嵌入以及预测进行整合,形成一个端到端的递归神经网络,即本文的问题可表述为短序列推荐问题,并在DSM 模型中建立一个递归神经网络来解决有关时间序列的问题,进一步提高其性能。
