基于广播信道的分布式事务处理方法
2020-10-09温宇强邵孟良
温宇强 邵孟良

摘要:本文提出的基于广播信道的分布式事务处理方法,该方法在广域网环境下仍然适用且高效。相比于基于消息传递的分布式事务处理的算法,针对某类分布式问题,在满足ACID( Atomicity.Consistency.lsolation,Durability)条件下,本文通过实例展示基于广播信道的分布式事务处理方法在处理某类分布式问题时的优势:计算量通信量减少,系統扩展性增强,算法调试简单。
关键词:分布式计算;事务处理;广播信道
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2020)18-0001-04
开放科学(资源服务)标识码(OSID):
1 引言
在分布式系统中,为了提高数据的可用性,增强系统的扩展性,数据经通过存储多份的方式来实现系统能力的扩展。然而,一些异常情况将导致数据出现不一致性,因此高可用事务处理系统的并发控制在可扩展性、副本恢复和单点性能等方面面临着诸多挑战。基于消息传递的共识协议算法,对消息传递的质量和延时是非常敏感的。在一个数据中心的环境下,节点之间的网络通信质量和带宽是有保证的。所以这些算法多用于一个数据中心内,或仅用于通过广域网连接的少数节点。
在Internet应用情况下,我们需要处理的分布式计算任务往往是地理上非常分散的节点参与的。由于网络环境的不稳定性和复杂性,如果使用现有的基于消息的共识算法,在执行效率和系统可用性等方面会遇到极大挑战。
本文提出的基于广播信道的分布式事务处理方法,是在广域网环境下仍然适用且高效。在同一个数据中心的这种环境下,找到合适的广播媒介(比如:基于DTMB技术的广播信道),相比于基于消息传递的分布式事务处理的算法,仍有系统处理简单高效的优势。
2 基于广播信道的系统模型
针对分布式事务处理,学者们提出了多种解决分布式事务处理问题的算法,即共识协议算法。比如:两阶段提交(2PC)[1],三阶段提交(3PC)[2],Paxos算法[3],Raft算法[4]或ZAB算法[5]。这类算法以应用于数据中心环境下,而Internet的网络环境,比数据中心的网络环境要更不可控。尽管现有业界提出了一些web服务环境下的事务组合及控制,例如google的chubbv[6]以及Apache的ZooKepper[7],他们都使用复制状态机来为少量配置数据提供键值(Key-Value)存储。这类复制状态机系统通常只由3个或5个服务器组成。但Web环境下的分布式计算问题需要更大的规模,目前仍存在多方面的挑战。
面对Internet环境,若采用分而治之的方案,比如:
在这些系统中,需要在待处理的问题中有可以进行分层或分块到较小的系统中数据。但如果系统中某些数据就是全系统唯一的,所有子系统都会用到的数据,系统分层或分块处理都会导致这类数据的一致性(ACID)受到破坏。所以可能不得不在广域网下使用基于消息的共识协议算法。而广域网环境下,共识协议算法还不能在大规模系统上应用。
然而利用作者提出的信道异构CDN( CHCND)系统架构[8],针对分布式事务处理中,共享数据可累计的更新,且只有总量变化会对业务逻辑产生影响,而操作顺序并无要求的操作。例如:电子购物系统,电子订票系统等的某些类型数据更新。本文提出了一种分布式事务处理方法,可以有效解决数据副本更新问题,使得这类系统的事务更有效率。系统结构如图1。
本文利用CHCDN系统的传输效率高的特性,将共享数据通过中心节点进行事务更新,再通过广播信道进行副本更新。分布处理节点在数据需要更新时,将逐级汇总,最后在中心节点完成数据更新,我们称此方案为信道异构共识协议。针对某些类型的分布式事务处理,异构共识协议可以更加有效率。
3 信道异构共识协议
结合广播信道通信的优势,我们提出的信道异构共识协议如下:
算法所有参与方都是节点Ni,i∈[0,n],运行算法之初,对Ni.产生一个节点的偏序集Pi,i∈[0,n]。Pi的选择都是根据具体应用来定义的。其中的第一个服务器PO便是主服务器,其他服务器成为从服务器。中心节点为C,C可以把数据发送到广播信道传输。偏序集合的依据有很多种,比如:以节点P2到中心节点C的双向点对点网络(可以是WAN网络)的延迟,作为产生偏序集合的依据。P0对只提供服务,最终客户通过P2获取服务器,其中Pi,i∈[0,n]。另外,c可以是只中的一员,也可以是一个独立的节点。只都可以与P0通过点对点网络通信。Po可以通过点对点网络与C通信。系统初始化时统计出
对于要通过分布式系统更新的数据项,算法引入广播变量类型,其状态有:fboardcast-read.boardcast-lock),同时还有更新版本号boardcast_revision,数据项的更新版本号会随着数据更新提交的次数变化,为叙述方便,我们假设变量更新版本号从0开始递增。广播变量类型的属性,都存储在主服务器PO上。其他节点会通过广播信道得到对应数据项的更新状态。则在只系统中,要更新的数据便有了广播变量类型。其值在Pi系统中,对Pi中的应用程序为只读的属性。通过广播信道,可以实现所有节点的系统时间统一,并且这个时间精度可以足够用于分布式事务的先后区分。如果有相同的两个更新请求的时间戳一样,则再利用节点的排序,人为定义相同时间戳的更新请求先后次序。
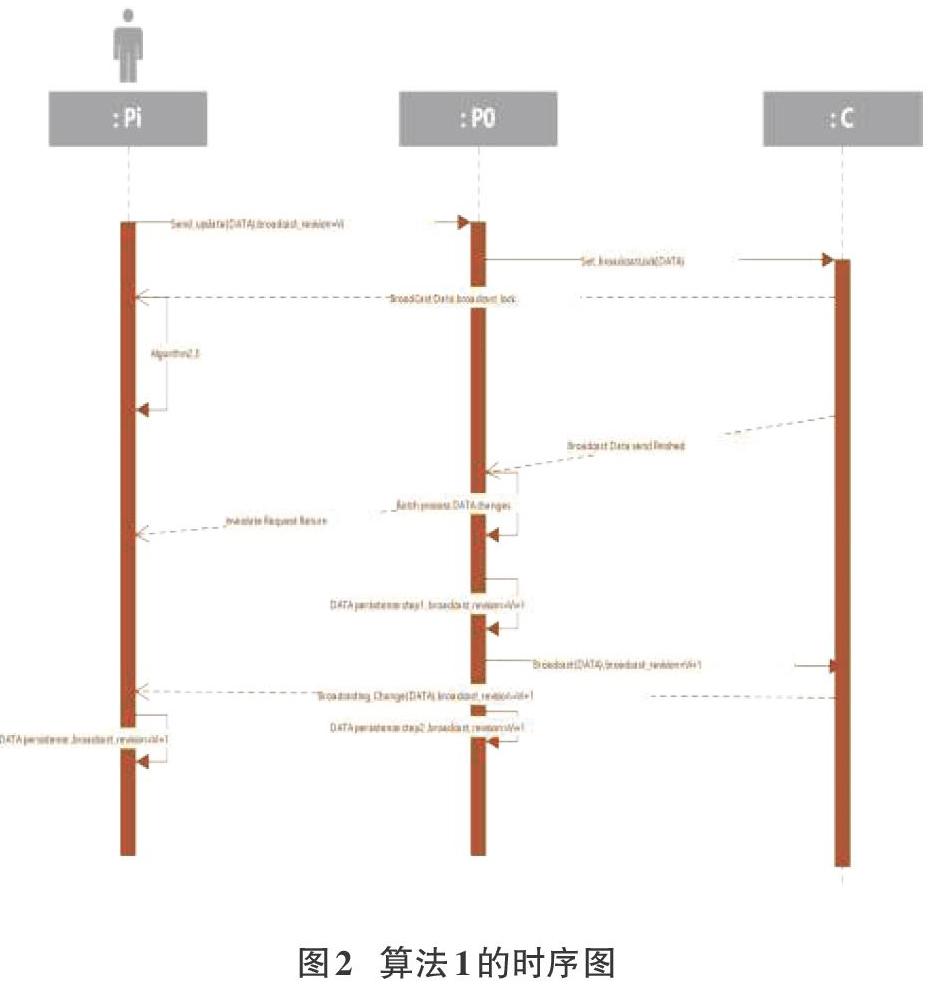
系统事务处理具体处理流程如下,算法1:
Stepl节点Pi发出数据的修改请求,通过点对点网络,请求送达PO。
PI中对于状态为boardcast-read的数据项,只若要执行数据更新的操作,则节点Pi需通过点对点网络提交该数据项的更新请求给P0,请求信息带有时间戳,以及当前数据项的更新版本号boardcast_revision=Vi。
Step2 Po在接到对某广播类型变量boardcasLrevision=Vi的第一个更新请求后,通知C,C通过广播信道把对应数据项的状态变为boardcast-lock的消息发送出去.广播信道发送出去该消息的当前时间戳为to.
to+ TB时间过后,所有的节点都应收到这个消息,并把系统内对应的数据项的状态由boardcast-read变为boardcast-lock。则此时以后的对此数据的修改请求将会视为无效。这些有效的boardcast_revision=Vi更改请求中,最迟会到达PO的时间为Tmax;io,如果超过了这个时间到达,也视为无效数据,并且会根据到达时间修订Tmax:i-0,具体修订算法不属于本文讨论的内容。
所以,Po对boardcast_revision=K时间标签为to+ TB+ Tmax:io以后的数据提交请求,以及,boardcast_revi-sion=Vi但是在t0+TB+Tmax:i-0以后才到达的数据更新请求都会忽略。
PO收到有效的的更新请求,顺序进行处理。其他的处理可以并行:返回结果给对应的节点;对无效的数据请求,直接给节点返回对应的错代码;发送结果的反馈,使用的是点对点网络。
假设顺序处理完当前时间窗内的有效更改需求后,分两步提交这个数据项的持久化存储:
Step2.1,PO将结果在持久化系统中(数据库)更新,并设置新的boardcast_revision=Vi+i,并发送更改后的数据项给C,C通过广播信道发送对应数据项的更新信息。从t0+TB+Tmax:i-0开始处理更新请求到C收到更改后的数据值并把值更新消息发送到广播信道,耗时为g;
Step2.2,當PO收到广播信道中的数据更改信息,时刻为to+ 2TB+Tmax:i-0 +9,执行持久化系统的更新确认。
由于数据更新的请求多数是值更新类的请求,所以批量处理在一定时间间隔内的更新请求,有合并对同一变量的操作的可能,而减轻数据库持久化的1/0压力。提高系统的响应速度。
同理只节点也会在tc)+ '2TB+Tmax:t一0+g时刻收到广播更新信息,数据项状态则由boardcast-lock转化为boardcast-read,boardcasLrevision也做相应的更新,所以白t0+2TB+ Tmaxi-0+g开始的数据请求将会是有效的,对应的数据项更新请求将是boardcasLrevision=Vi+1
Step3只节点通过广播信道接收数据库的更新,对比自己的数据库中的条目,进行更新。某些条目也许不在本节点的数据库中,则不用管。某些更新失败的节点,需要重新检查广播数据项的状态,再提交新的更新请求。
Step4提交新的请求即重复上面的1-3的过程。
本系统数据更新最小间隔Tsp,也就是响应速度为。Trsp与分布式系统的规模无关,有下列关系:TB是基于系统所选择的广播信道而决定的,其值为:TB=电磁信号在空中传播时间+调制解调时间
如果选择同步卫星,则TB大概是0.27秒;如果选择低轨道卫星,TB则很小大概是同步卫星的1/36-1/6;若采用高空气球或高空无人机作为信号中继,则B的值更小。( )与( )的值有赖于分布式系统节点间的网络环境,系统在运行过程中可以动态监控这些值;g是PO处理时间窗内请求需要的时间。所以,本算法的系统的可用性是有保证的。
对应上面的系统事务处理流程流程,Pi节点内的处理流程描述如下:
假设Data为我们感兴趣的全局一致的广播类型数据,Val-ueChange为本地应用对Data变化的期望,realchange为本地应用最终得到的Data变化。由于boardcast_revision更新主要是通过广播信道更新,所以下面算法主要叙述Data的状态和值的更新。 只节点广播信道更新数据的处理流程的伪代码片段如下,算法2:
1:
2:
if(Data.status==boardcast-read)(
//new value change command can be send now
3:Send_update(Data, ValueChange);// Asynic messagesend
4: ) else if(Data.status==boardcast-lock)(
5:Invalidate(Data);// local variables need to bechecked. Data value maybe changed
6: j
Pi节点收到P0返回的异步消息处理结果的处理流程为代码如下,算法3:
0:
1:
value=Get_CurrentValue(Data)
2: if(resuh.status==sucess){
3:realchange=ValueChange;
4: )else if(result.status==fail)(
5:
realchange=0;
6: 1
7
Pi节点的数据处理逻辑,应该基于ValueChange和real-change,而不是基于广播类型数据Data的value。
通过引入广播数据类型,分布式程序的设计上可以不需要为分布式变量操作的同步而消耗时间等待。广播数据类型的修改采用异步的方式,不会影响本地的应用效率。只是在应用设计上,要正确灵活地使用广播数据类型。这大大简化了分布式系统的设计。分布节点Pi对应用逻辑的处理中,不需要执行对数据库的持久化操作,所有的持久化操作集中在Po做。这会让应用程序负担小,跑得更快。在Po中,对值更新类型的数据操作,可以在Trsp时间内合并对相同数据操作,最后只需一次数据库的持久化写入,这种合并处理对PO的数据库10操作的减少也是有很大帮助的,此部分的处理可以在Po系统中划分一个中间件子系统来处理;另外在每次提交的操作间隔中,已经包括了p0数据库的提交,所以Po的处理速度会因为数据量的增大有所减慢(g增加),从而增加系统最小更新时间间隔Trsp。但目前有很多比较成熟的技术可以提高这部分的执行效率[1][2]。
对数据项的操作尽量多使用更新类型的数据操作,而不是设置类型的数据操作。这是分布式系统数据处理中常见的情况,比如:对金额,计数等的操作,主要是更新类型操作。
4 模拟仿真
例如:全国铁路售票系统使用本算法实现全国范围内的列车剩余车票数据的更新事务处理。全国所有的铁路售票系统通过网站为全国人民服务,全国人民可以访问网站来订票,订票的规则是先到先得。
现此系统准备使用本算法,实施如下。
1.对全国所有的铁路售票系统通过网站,按CHCDN的方式,在全国建立多个镜像服务器。假设全国每个小区都有一个边缘计算中心,则可以在每个小区的边缘计算中心中,利用CHCDN系统部署镜像站点,为小区中的居民服務。
2.每个镜像站点初始时有一致的数据库,里面保存了全国各列车的售票情况数据。
3.通过本算法,系统初始化后,选择了一个在北京交通部的服务节点作为Po,同时在交通部内有一个服务器C可以把数据传到中星9号上的某个数据频点。系统中的所有节点,都安装有广播接收子系统可以获取中星9号上的这个数据频点中的数据。系统经过初始化后,确认的系统响应间隔Trsp为0.8秒。
4.通过广播信道,可以直接更新系统中各节点的全国各列车的售票情况数据。
5.这样,各节点中的网站设计,大部分没有什么区别,只是把用户部分的用户信息,作为各节点自己管理的数据。用户信息的数据,在全网也保持一致,此部分信息可以不用存在一个单一的节点内,而是分布式的存于客户登录过的节点中,不同节点之间的用户信息之间是可以确保一致的。(这不是本算法要讨论的内容,所以不详细展开)
6.系统中某小区a有用户Ua登录到该小区内的全国所有的铁路售票系统网站镜像,这个网站镜像运行在节点Pa,Ua在网站上浏览L列车的剩余车票时,还有100张,在时刻to,Ua在镜像网站上订了一张L列车的车票,这时网站显示“车票订票执行中…”。由于镜像网站运行在Pa,Pa中有足够的资源保证Ua的体验,用户体验到的就是分布式系统处理的速度。
8.ta到tz的时间中,假设tz最大,tz
9.PO在to +0.5前的时间内(t。+0.5对应于算法1中的to+ TB+Tmax:i_o)接收Pa到Pz发来的boardcast_revision=0的更新请求,其中只有Pa到Pj的请求是有效的,假设他们都在ta+0.5之前到达PO。Po处理了这些请求后,L列车的余票为9张。Po把这个结果提交本地数据库,数据版本更新为board-cast_revision=1,把结果通过C传到中星9的广播信道中。同时,Po通过点对点的网络对Pa到Pz的请求进行应答。
10.在to +0.8时刻(to +0.8对应于算法1中t0+2TB+Tmax:i-0 +9),所有节点收到广播信道更新。Uk到Uz的用户界面上可以浏览新的余票信息,只有9张了,重新调整订票数为每人1张。
11.假设Uk到Uz在重新提交订票请求的时候,又同时进行了提交(这在实际系统中几乎不可能,但是为了说明系统对这种极端情况的处理,我们假设同时条件成立)。由于Uk到Uz提交的请求需要16张票,但是现在系统只有9张票,所以只能满足部分用户的请求。最)收到这些更新请求后,会根据Pk到Pz在系统中的排序,定义这些请求的执行顺序;假设就按照k-z的顺序,则Uk到Us可以每个人得到1张票,Ut到Uz还是没有抢到票。这时系统中L列车的余票为0张。
同样的方式,在处理更多的列车数据和更多的用户的时候方法类似。
这个例子体现了利用本算法后的系统的分布式系统的可扩展性和在事务处理中的高效和公平。
5 结论
基于广播信道的分布式事务处理模型的提出,虽然不能把所有的事务处理问题都解决。但是针对大量存在的公共变量更新问题,该模型提出了十分有效方法,在计算量、通信量、算法调试复杂度等方面都大大改善。基于广播信道的分布式事务处理在这类问题的应用,将会推动分布式事务处理方式的改变。
参考文献:
[1] Lechtenborger J.Two-Phase Commit Protocol. In: Liu L.,Ozsu M. (eds) Encyclopedia of Database Systems[M]. Springer,New York, NY, 2016
[2]Al-Houmaily Y.J., Samaras G.Three-Phase Commit. In: LiuL., Ozsu M.T. (eds) Encyclopedia of Database Systems[M].Springer, Boston, MA. 2009
[3]Lamport Leslie,Ceneralized Consensus and Paxos,Microsoft Re-search Technical Report MSR-TR-2005-33, 2005
[4]Ongaro D,Ousterhout J. In search of an understandable consen-sus algorithm[C]. usenix annual technical conference, 2014:305-320+
[5]Junqueira F,Reed B,Serafini M,et al.Zab: High-performancebroadcast for primary-backup systems[C]. dependable systemsand networks. 2011: 245-256.
[6]Burrows M. The Chubby lock service for loosely-coupled dis-tributed systems[C]. operating systems design and implementa-tion。2006: 335-350.
[7]Hunt P D,Konar M, Junqueira F,et al.ZooKeeper: wait-freecoordination for internet-scale systems[C]. usenix annual tech-nical conference. 2010: 11-11.
[8]温宇强.CDN系统中数据请求、发送的方法、装置及系统结构:中国专利,ZL 2014 1 0271393.X [P].2014-08-27
【通联编辑:梁书】
基金项目:2018年广州市科技计划项目“实时大数据处理中间件关键技术研究与开发”(201804010402);2018年广州南洋理工职业学院创新强校工程项目“信息技术创新与应用基地”(NY-2018coPT-01);2019年广东省普通高校重点研究(自然)项目“实时大数据处理平台关键技术研究与开发”
专利:CDN系统中数据请求、发送的方法、装置及系统结构专利号:ZL 2014 1 0271393.X
作者简介:温宇强(1978-),男,硕士,主要研究方向为分布式计算、大数据等;邵孟良,副教授,硕士。
