基于Ceph的小文件预取缓存算法
2020-09-29陆小霞

摘要:为解决Ceph系统在处理小文件时,由于小文件被频繁访问时,集群需要在多个存储节点之间不断查找文件,导致系统读取性能较低的问题,本文提出了一种基于Ceph的文件预取缓存算法。该算法通过引入权重衰减因子来动态计算缓存文件的权重,当小文件长时间未被访问时,该文件的权重会随之降低。若权重小于阈值时,该文件会从缓存中移除,这样可以减少缓存空间的浪费,提高缓存文件的命中率。实验结果表明,该方法与现有方法相比能明显提高小文件的访问效率。
关键词:ceph;小文件;预读取;缓存;权重因子
中图分类号:TP302 文献标识码:A
文章编号:1009-3044(2020)17-0225-03
Abstract: In order to solve the problem that when CEPH system processes small files, because of the frequent access of small files, the cluster needs to constantly search for files among multiple storage nodes, resulting in low system read performance, this paper proposes a file prefetch caching algorithm based on CEPH. In this algorithm, the weight of the cache file is calculated dynamically by introducing the weight attenuation factor. When the small file is not accessed for a long time, the weight of the file will be reduced. If the weight is less than the threshold value, the file will be removed from the cache, which can reduce the waste of cache space and improve the hit rate of the cache file. Experimental results show that this method can significantly improve the access efficiency of small files compared with the existing methods.
Key words: ceph; small file; prepare reading; cache; weight factor
Ceph[1,2]是一種基于对象存储的无中心化的分布式文件系统,由于采用了对象存储的方式,其数据处理过程高度并行化,Ceph系统能够通过添加普通服务器来扩大集群,可轻松将存储规模扩展至PB级。而CRUSH[5,6]作为Ceph集群的核心算法可以动态的计算出各个文件的存储位置,实现了文件元数据的服务器功能,使之成了一个即使出现单节点故障也能正常使用的存储系统。但Ceph系统在频繁读取小文件时,由于集群需要在多个存储节点之间不断查找文件,导致系统读取性能较低的问题[8]。
在小文件访问时,目前有两种方法可以提高小文件的访问效率。Zou Zhenyu[3]等人采用文件预取机制将文件预取至缓存中,减少用户与集群的直接交互,从而提高文件的访问效率;Cheng Wenjuan[4]等人提出一种索引机制,在文件合并时生成相应的索引文件,减少小文件的查找时间,可以提高小文件的访问效率。本文在LRU算法的基础上给出一种改进的LRU_W算法。
1 LRU_W算法
分布式存储系统在处理海量小文件时,通过优化小文件处理算法所带来的效果远不如系统利用缓存带来的效果。因此,为了提高分布式存储系统的性能,针对不同应用场景设计实现的文件存储系统则会采用不同的缓存替换方法。
在确定分布式存储系统采用缓存机制可以提高系统的整体性能后,如何确定系统的缓存容量已经成为评估系统存储性能的重要问题。通过分析存储系统的数据特征,可以确定存储系统是读请求比较集中,还是写请求比较集中。若存储系统是写请求比较集中时,可以在系统文件写入时设置一个写缓存;若该系统是读请求比较集中时,可以在系统中设置一个读缓存。系统也可以通过再次访问缓存对象文件的大小,确定系统所需要的缓存容量大小,从而可以避免因缓存文件太小而浪费缓存空间。
1.1 LRU_W算法改进与实现
LRU算法是目前最常用的一种缓存替换算法,该算法是根据缓存文件的访问时间间隔原理设计实现的。当缓存容量不足时,将最不常被访问的文件替换出缓存。本文在设计缓存机制时,采用的是LRU算法来实现系统文件的预取及缓存。但在实验时发现,在面对海量文件读取及缓存时,随着文件存储数量及用户请求数量的不断增大,缓存中文件的数量也不断增长,这样将出现有些小文件长时间未被访问而浪费缓存空间的问题,导致缓存文件命中率降低。对此,论文给出一种基于访问频率及用户访问时间的LRU改进算法LRU_W。该算法在文件写入缓存时,首先利用公式(1)为该缓存文件计算出其权重因子Rw,并将其放置在缓存队列的头部。
1.2 LRU_W算法请求处理流程
LRU_W算法是基于LRU算法的改进,该算法充分考虑了文件的访问时间及访问频率因素,动态计算出每一个缓存文件的权重因子。通过公式(2)计算缓存文件的权重,并根据缓存文件的权重来确定缓存文件的优先级。当缓存容量不足时,将权重最小的文件从缓存中移除。
LRU_W缓存算法的请求处理流程如图1所示。
由图1可以看出,当用户发出访问请求时,系统需要首先缓存中是否有该文件,若存在缓存中,则从缓存中读出相应的文件内容并返回请求文件给用户,并重新计算缓存对象的权重,若其权重值低于给定阈值,则从缓存中移除该文件,否则就更新缓存信息。若该文件不在缓存中,就说明文件尚未被读取出来,然后系统向Ceph集群发出读请求,从Ceph集群中读取请求文件及与其相关的小文件至缓存中。当缓存容量不足时,优先将缓存中权重比较低的缓存对象从缓存中移除。
本文在LRU_W算法的基础上设计实现了一个二级缓存策略,该策略根据文件对应的权重因子不同,将缓存文件分别对应不同的优先级,其详细实现过程如图2所示。
如图2所示,Q,Q1分别代表二级缓存数据结构的一级缓存和二级缓存,其中二级缓存中的文件优先级相比一级缓存中的文件较高。该缓存策略的主要实现过程是:
1) 新加入缓存的数据放入Q中的首部,记录访问时间和访问次数,并给出相应的初始权重;
2) 随着时间的不断增加,文件权重的不断改变,当文件的权重大于给定的阈值时,就将优先级比较高的文件放入二级缓存Q1中。用户在访问文件时,首先从Q1中检查该文件是否存在,若不存在,再从Q中检查该文件是否存在。这样可以保证权重较高的文件优先级较高;
3) 随着海量小文件的读取,缓存容量不足时,首先从优先级较低的一级缓存Q中删除权重因子较低的文件;
4) 由于缓存文件的权重因子会随着时间的增长而衰减,当其权重降低到低于阈值时,该文件将会缓存中淘汰,避免文件长时间未被访问而浪费缓存空间。
2 实验与分析
实验对缓存优化机制的测试主要分为:LRU_W改进算法的相对命中率、绝对命中率及缓存优化机制应用到系统时文件的平均读取时间测试三部分。
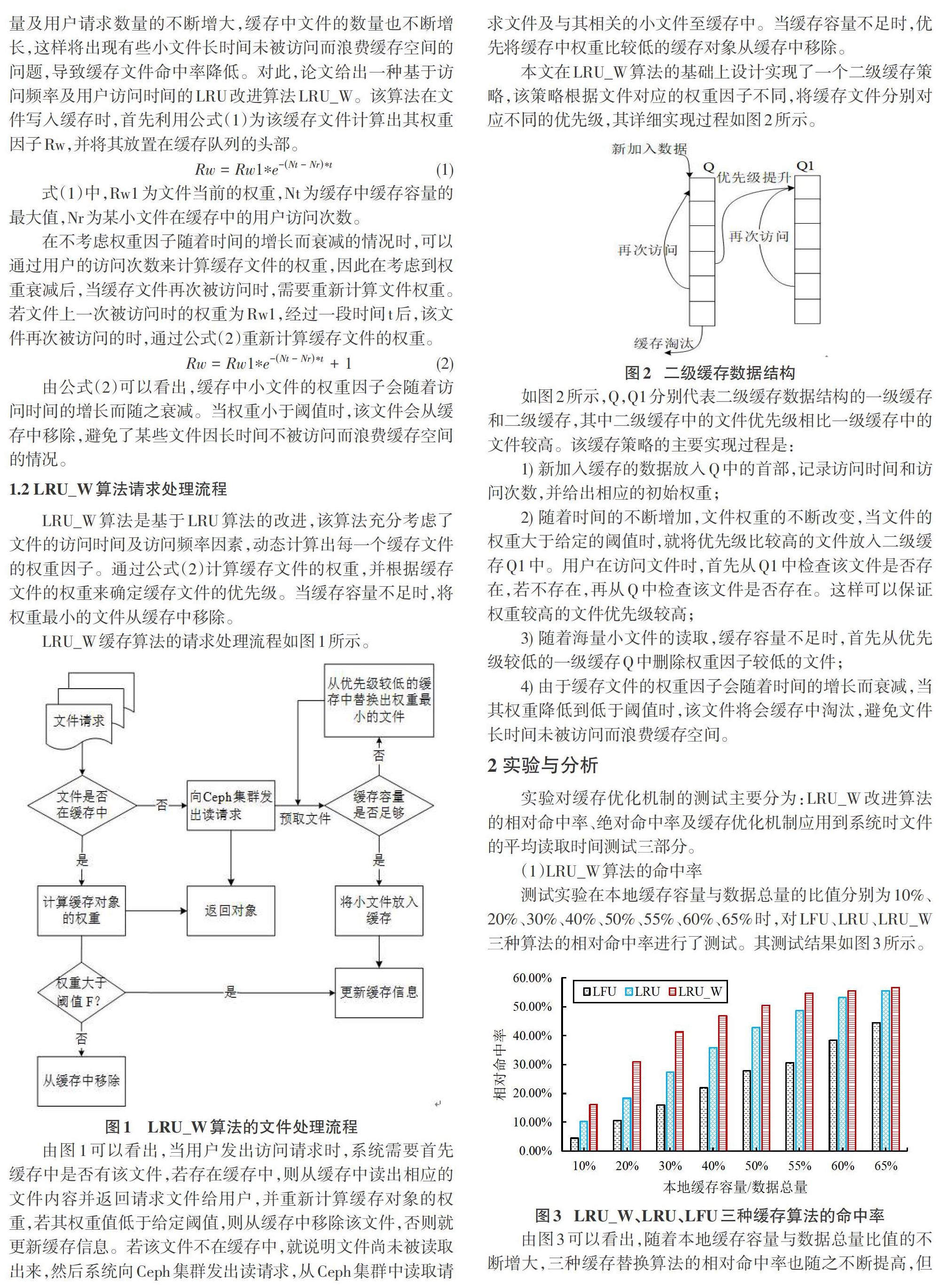
(1)LRU_W算法的命中率
测试实验在本地缓存容量与数据总量的比值分别为10%、20%、30%、40%、50%、55%、60%、65%时,对LFU、LRU、LRU_W三种算法的相对命中率进行了測试。其测试结果如图3所示。
由图3可以看出,随着本地缓存容量与数据总量比值的不断增大,三种缓存替换算法的相对命中率也随之不断提高,但本章节给出的缓存算法的相对命中率在本地缓存容量与数据总量比值较小时一直都是最优的。
(2) LRU_W算法的绝对命中率
该测试主要是通过不断改变本地缓存容量与数据总量的比值对缓存文件命中率的影响。具体实验过程是:本地缓存容量与数据总量的比值分别为10%、20%、30%、40%、50%、55%、60%、65%,对LFU、LRU、LRU_W三种算法的绝对命中率进行测试。其测试结果如图4所示。
由图4可以看出,随着本地缓存容量与数据总量比值的不断增大,LRU_W、LRU、LFU三种算法的绝对命中率也随之不断提高,但明显可以看出LRU_W算法相比其他两种算法的绝对命中率也是相对较优的。当比值达到55%时,可以看出三种缓存算法的绝对命中率几乎相同。
由图3和图4可以看出,LRU_W算法和LRU、LFU缓存算法想比较,LRU_W算法在本地缓存容量与数据总量的比值较小时性能较优。海量小文件存储系统中本地缓存容量是有限的,而系统数据是海量的, 因此本地缓存容量与数据总量的比值是较小的,而LRU_W算法在比值较小时,其缓存性能最优。
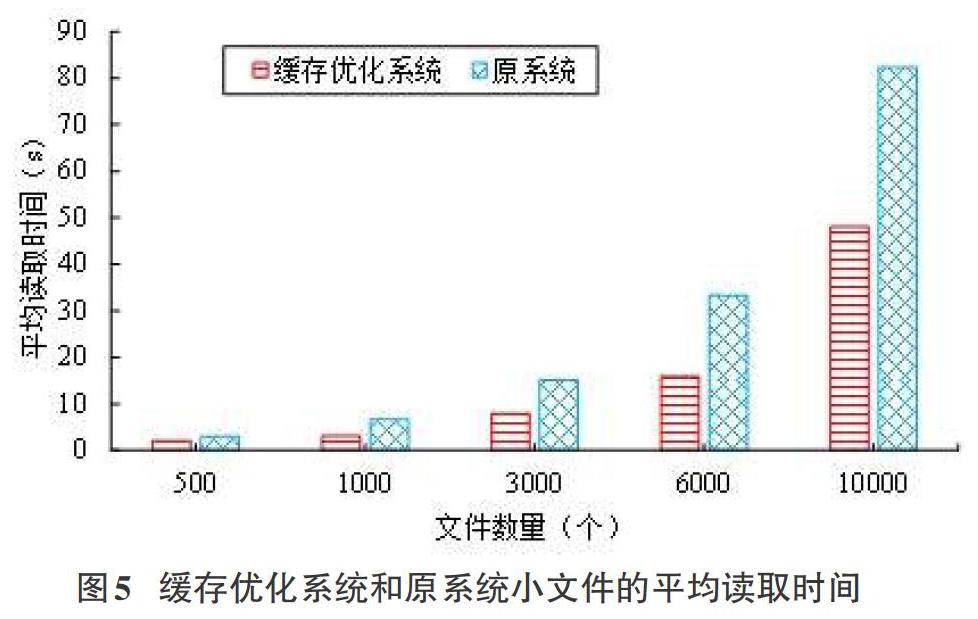
(3) 系统文件读取性能测试
该测试模块的主要作用是当系统中存在海量数据时,使用缓存优化机制的系统和无缓存优化系统对小文件查找效率的影响。具体实验过程如下:每一次测试都在上一次测试的基础上,增加相应的小文件请求。如首次测试读取500个小文件时的文件平均读取时间,其次是分别测试读取1000、3000、6000、10000个小文件时文件的平均读取时间。其中,缓存机制的缓存容量设置为2000,小文件的平均读取时间测试结果如图5所示。
由图5可以看出,在没有缓存优化机制的系统中,随着小文件读取数量的不断增加,其平均读取时间明显增加较快;在读取同样数量的小文件时,具有缓存优化机制系统的平均读取时间显然优于原存储系统。主要是因为系统使用了缓存优化机制,可以将小文件提前存储在缓存中,用户从缓存中读取文件,可以减少用户与集群的交互,从而减少用户的读取时间,提高了系统的读取效率。同时随着读取文件数量的增加,缓存优化机制根据缓存文件的访问时间和访问频率计算出其权重衰减因子,若文件长时间未被访问,该权重随之衰减。当权重小于阈值时,该文件会从缓存中移除,可以减少缓存空间的浪费,提高缓存文件的命中率及系统的整体性能。
3 结束语
针对Ceph系统读取性能较低的问题,本文在LRU算法的基础上给出一种改进的LRU_W算法。该算法通过引入权重衰减因子来动态计算缓存文件的权重,当小文件长时间未被访问时,该文件的权重会随之降低。若权重小于阈值时,该文件会从缓存中移除,这样可以减少缓存空间的浪费,提高缓存文件的命中率。实验结果表明,该方法与现有方法相比能明显提高小文件的访问效率。
参考文献:
[1] 陆小霞, 王勇, 雷晓春.系统中海量气象小文件存取性能优化方法[J]. 桂林电子科技大学学报, 2019, 39(1):61-66.
[2] Yang Chaowei, Huang Qunying, Li Zhenlong, et al. Big Data and cloud computing: innovation opportunities and challenges[J]. International Journal of Digital Earth, 2017, 10(1):13-53.
[3] Zou Zhenyu, Zheng Quan, Wang Song, et al. Optimiza-tion Scheme of Small File in Cloud Storage System Based on HDFS[J]. Computer Engineering, 2016, 42(3):34-40,46.
[4] Cheng Wenjuan, Zhou Miaomiao, Tong Bing, et al. Op-timizing small file storage process of the HDFS which based on the indexing mechanism[C]// IEEE, Internation-al Conference on Cloud Computing and Big Data Analy-sis. IEEE, 2017:44-48.
[5] Weil S A, Brandt S A, Miller E L, et al. CEPH: a scala-ble, high-performance distributed file system[C]//7th Symposium on Operating Systems Design and Imple-mentation (OSDI '06), November 6-8, Seattle, WA, USA. 2006:307-320.
[6] Weil S A. CEPH: reliable, scalable, and high perfor-mance-distributed storage[J]. Santa Cruz, 2007.
[7] Li Hongqi, Zhu Liping, Sun Guoyu, et al. Design and implementation of distributed mass small file storage system [J].Computer Engineering and Design, 2016,37(1):86-92.
[8] Wang Tao, Yao Shihong, Xu Zhengquan, et al. An Effec-tive Strategy for Improving Small File Problem in Dis-tributed File System[C]// International Conference on In-formation Science and Control Engineering. IEEE Com-puter Society, 2015:122-126.
【通聯编辑:梁书】
