基于Python爬虫的多语言社交媒体情感分析研究
2020-09-28薛涛
薛 涛
(运城师范高等专科学校 数计系,山西 运城 044000)
互联网的发展使人们进入了用户生成内容(User Generated Content,UGC)[1-2]的新时代,许多互联网技术的应用广泛地使用UGC提供服务。用户通过便携式设备(如手机)、Web等途径,轻松地发表评论、新闻、活动以及身边的其他信息。海量UGC(如文本、视频、音频)数据的出现,使人们面临着数据分析、数据抽取等难题。社交网络信息数据中包含了大量人们对新闻、时间、产品和服务等的评价和感受,研究这些数据信息对于舆情分析、互联网服务质量的提高等具有理论和实践意义。与国内的主流社交媒体(如新浪微博)相比,Twitter是一个用户遍及全球的社交媒体,具有更大的受众范围[3]。由于Twitter的信息数据包含了多种语言,拥有多样的用户社交圈,因此以Twitter作为研究对象,开展了多语言情感分析的研究。
本文的多语言社交媒体情感分析系统主要包括三个部分:预处理、模式提取和情感分类。该系统将使用三个不同的数据集作为输入。这三个不同的数据集分别是:评论推文(包含主观意见)、事实推文(包含客观描述)、已分类的推文。其中,事实推文用来提取情感模式,已分类推文用来构建分类模型。所有数据集中的数据都必须经过预处理阶段,将异常数据清除,使数据格式标准化。为了更好地表示这些集合的数据结构,将推文转换为图,即将评论推文转换为评论图,将事实推文转换为事实图。接下来,对图进行简化操作。进行简化操作后,事实图用来创建评论图中的权重,以生成情感图。然后针对情感图进行节点中心性和节点聚类分析,以提取用于构建模型的词汇-句法特征。在提取情感模式后,将情感模式列表和已分类推文相结合,以构造特定的情感模型。最后应用矢量建模技术,便能获得情感分类器。
1 基于Python爬虫的数据抓取和预处理
所使用的数据集是通过Python爬虫收集到的。因此,数据收集的时间越长,数据集就会越大。不同语言的语法、词汇基础和其他特征之间具有明显的差异,因此为了从不同的语言中获得情感模式,必须获取相应的语言数据集。评论推文数据集是普通用户的日常推文,其中包含一些与情感相关的单词、主题标签或表情符号。事实推文是官方媒体所发布的推文,主要包含已经发生的事件或报告事物的当前状态等客观事实。通过对官方媒体账户进行爬虫就可以获得事实推文数据集。已分类数据集包含了特定情绪相关的推文。采用Python爬虫,根据特定情感所对应的主题标签来获取含有该情感的推文。首先需要在Twitter开放应用程序的网站(https://dev.twitter.com/apps)上创建一个应用程序,以获取Twitter API的权限。接下来需要创建一个Token,从开放式授权验证(OAuth)中获取Key、Secret、Token和Access Token的信息,并将这些信息填入如表1所示的Python代码的相应位置中。采用Python提供的tweepy进行爬虫实现。

表1 获取应用Key
OAuth是一种开放式身份验证标准,Twitter已采用该标准来提供对受保护信息的访问。 OAuth使用三向握手为传统身份验证方法提供了一种更安全的替代方法。在实现爬虫功能之前,需要使用Python的import语句来引入相应的模块,如表2所示。

表2 Python爬虫所需要的部分模块
由于篇幅有限,此处仅展示根据用户ID搜索推文的部分实现Python代码,如表3所示。

表3 推文抓取的部分Python代码
社交网络应用允许用户自由地表达自己的情感,推文的内容具有多种形式、长度、符号用法甚至不同的语言。因此,需要对数据集进行预处理,避免噪音对后续处理产生影响。如果推文太短,将很难表达出具体的情感,因此需要将其删除。这是因为缺乏足够单词的文本可能会使句法模式更难识别。在关键字之前添加主题标签“#”有利于社交网络应用对推文进行分组。但是很多用户会在推文中滥用主题标签,最终使得该推文缺乏重要内容。因此,包含太多标签的推文也将被删除。另外,也需要删除转发的推文。转发的推文会造成内容重复,而且转发的推文不一定能反映当前用户的情感。最后,由于包含URL的推文一般不带有情感,因此需要将其删除。在预处理阶段之后,首先需要对每个推文进行分词操作,以获取多个独立的单词。然后,通过使用特殊标记替换推文中的用户名、URL、主题标签等来实现单词的规范化。规范化操作能够避免可能由于用户名、标签等而引起的偏差。
2 模式提取和情感分析
2.1 模式提取
模式提取是情感分析的一个重要过程。不同的语言在语法和句法上有所不同。句子由模式组成,它们提供了表达的结构。模式提取算法包括两个主要部分:基于图的单词提取和情感模式提取。基于图的单词提取组件是一种无监督的方法,可以提取两种类型的单词,即连接词和情感词,它们是模式的组成部分。情感模式提取组件使用提取的单词列表来识别语料库中的重复模式。根据评论推文和事实推文分别构建两个不同的加权图:Gu(Vu;Au)和Gn(Vn;An)。对于每个图,V是节点的集合,每个节点代表一个单词;A是一组弧线,用来表示两个单词之间的关系。为了保留推文的韵律和基础结构,根据推文中单词的顺序定义弧。用freq(ai)表示弧ai出现的频率,用w(ai)表示弧ai的权重,其定义如下:
(1)
因此,文本中单词之间的关系都可以由图中的弧表示,而且这些弧具有权重。为了更准确地对评论推文数据的结构进行建模,基于评论推文图Gu来构造情感图Ge,并根据事实推文图Gn的内容对情感图Ge进行调整。首先,通过包含Gu中的所有节点和弧来构造一个新图Ge,并根据以下的规则来调整Ge的权重。
(2)
新图Ge强调个人情感和个人观点,因此那些仅在评论推文中出现且不在事实推文中出现的推文的权重将保持不变。如果一条弧同时出现在评论图和事实图中,则该弧的权重会减少。在新图Ge中,弧的权重较高表示单词序列与评论推文更相关,而具有低权重的弧则与事实推文更相关。在后续的图分析过程中,权重较低的弧具有更低的重要性。因此,当弧权重低于阈值thw时,该弧将被删除。最后生成的图称为情感图。
接下来对情感图进行分析,以发现频繁且相关的单词以构建连接单词集,并查找与情感相关的单词。根据节点的统计信息可以对节点进行分类。以前的方法一般依赖于词性标签或基本的统计信息(如字数统计)。在多语言的情况下,这些方法并不适用。本研究所提出的方法是基于图中节点的中心性来识别连接词。在图分析中,节点的中心性衡量其在图中的相对重要性。最佳连接词不仅是频繁出现的词,而且还是图的中心。节点相关性也可以通过考虑其他因素来确定(如节点邻居的重要性)。为了达到这个目的,采用特征向量中心性对单词进行排序并选择连接词。当节点的邻居具有较高的特征向量中心性时,该节点也会拥有较高的中心性。节点vi的中心性ci的计算方式如下所示:
(3)
其中,λ是特征值。用矩阵M=(mi,j)表示情感图中节点之间的关系:当节点vi和节点vj在图Ge中相连接时,mi,j等于1;否则,mi,j等于0。
然后通过保留特征向量中心度高于阈值φeig的所有单词来形成连接词列表。在获得第一个单词列表后,下一步就是创建一个包含带有情感单词的第二个单词列表。由于仅基于频率来选择情感词并不可靠,而且一般来说情感词会通过相同的连接词相互连接,因此通过单词的平均簇系数来进行情感词的选择。节点vi的平均簇系数cli的计算方式如下所示:
(4)
然后通过保留平均聚类系数高于阈值φcl的所有单词来形成情感词列表。在获得两个单词列表之后,接下来通过查看连接词和情感词的组合来提取模式。考虑带有两个或三个单词的短模式,较长的模式可以通过组合短模式来表示。例如,四个单词序列可以由两个具有两个单词的模式组合来表示。每个模式必须包含来自连接词列表和情感词列表的单词。这是因为仅由连接词组成的表达式会缺少情感模式;而仅包含情感词的表达将缺乏足够的语法来描绘适当的含义。具有相同连接词、长度和顺序的样式会被归为一组。如此一来,能得到多个组,每个组都是一组模式实例。鉴于某些表达结构更为频繁,某些组将包含更多的实例。每个组中的实例将根据其语法结构定义候选模式,然后将每个组中的情感词替换为通配符以使该序列能够匹配其他具有相同模式的单词序列。这样一来,就能够得到表达不同情感的候选模式列表。
2.2 情感分析
使用情感度来反映模式p对特定情感e的重要性,其计算方式如下所示:
edp,e=pfp,e×iefp×divp
(5)
pfp,e是代表模式频率,定义为pfp,e=log(f(p,e)+1),其中f(p,e)是模式p在情感e中出现的频率。iefp是逆情感频率,其计算方式为iefp=|E|/|{e∈E∶f(p,e)>0}|。divp是指多样性,其计算方式为divp=log(Φ(p,E)),其中Φ(p,E)表示模式p能捕捉的情感数量。
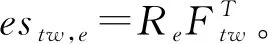
3 实验评估
所有实验中使用的数据均来自Twitter。为了提取模式,采用基于Python的爬虫技术抓取了含有情感的评论推文,其中包括英语、法语和西班牙语的推文各10 000条。而事实推文数据集则是通过抓取官方媒体在Twitter上发表的推文而获得的,每种语言各获得了约500条事实推文。考虑的情感分别为愤怒、恐惧、希望、喜悦、悲伤和惊奇。
将本方法与LSTMs(长短期记忆网络)[4]、Conv-Emb[5]和Conv-Char-S[6]进行了比较。表4展示了三种方法的准确度(accuracy)和F-度量(F-measure),表5展示了三种方法分别应用于不同语言下的分析结果。综合表4和表5的结果可知,本方法在多语言的情感分析中具有最好的性能。

表4 三种方法的准确度和F-度量对比

表5 三种方法在不同语言下准确度对比
4 结论
本研究探讨了多语言的社交媒体情感分析问题,首先设计并实现了基于Python爬虫的数据获取和预处理,然后提出了一种无监督的情感分析方法。最后利用真实数据集验证了本方法的有效性。未来的研究将通过进一步改进本方法,实现在线的社交媒体情感分析。
