HBM访存特点分析及性能测试∗
2020-09-28陈海燕王耀华杨晓辉
张 显 陈海燕 王耀华 杨晓辉
(1.空军航空兵第十三团 日喀则 857000)(2.国防科技大学计算机学院 长沙 410073)
1 引言
X-DSP是课题组自主研制的一款面向高性能计算的多核向量数字信号处理器。随着性能需求的增长,X-DSP采用了更多的内核和更高的时钟频率,而其采用的DDR3存储部件逐渐不能满足大规模应用程序的高带宽需求。JEDEC提出的HBM[4]作为一款通过3D堆栈技术实现的新型内存技术,在电压只有1.2V时钟频率1GHz情况下,其理论带宽可达265GB/s。可望有效缓解高性能多核微处理器的访存带宽瓶颈。
HBM存储颗粒由一个基本逻辑层和四个DRAM层通过3D堆栈构成,之间通过TSV互连[5~8],基本逻辑层包含I/O缓存模块和测试逻辑模块[9~12]。每个DRAM堆栈层包含2个内存通道,共集成8个通道,各通道之间相互独立。8个通道各自对应一个内存控制器,如图1,每个通道支持两个AXI从机接口,对应其中的两个虚通道。

图1 HBM功能模块图
HBM支持虚通道访存模式,每个虚通道对应一个128位数据位宽32位地址位宽的AXI4.0接口;支持不同读地址ID读请求乱序返回读数据,而相同读地址ID需按读请求顺序返回读数据;仅支持自增Burst类型。HBM单个虚通道支持交错地址映射方案,如图2,4~9位指向6位列地址,10~13位指向4位Bank地址,14~28位指向15位行地址,可访问的内存空间为512MB,则整个HBM共8GB寻址空间。

图2 HBM单个虚通道地址映射方案
2 HBM测试平台及性能测试
2.1 HBM测试平台
由于HBM 16个虚通道完全并行,对应不同地址空间,下面只需针对单个虚通道搭建测试平台进行基本的性能测试。单个虚通道从机接口遵循AXI4.0协议,包含读地址通道、读数据通道、写地址通道、写数据通道和写响应通道[13]。本文利用Ver⁃ilog HDL搭建了HBM测试平台,整个平台包括HBM主机模型、HBM、参考模型、比较器四个模块。主机模型通过相应读、写请求通道向AXI从接口发送请求激励。请求内容主要包括:访存类型、访存地址、Burst类型、Burst大小、Burst长度、选通信号、握手对信号VALID和READY等。参考模型为基于数组实现的存储器,用于和HBM的输出结果进行比较,判断读写数据的正确性。

图3 HBM测试平台
2.2 HBM读写性能
读写性能测试主要是计算HBM读写有效带宽和带宽利用率。HBM主机模型向HBM发送地址递增的连续读请求,读地址ID分为固定和不固定两种。结果表明,读ID号固定和不固定的情况下,HBM读数据带宽利用率分别最大为85.34%和91.11%,有效带宽分别最大为218.47GB/s和233.24GB/s。读地址ID固定时读数据需按读请求顺序返回,ID不固定时可乱序返回,导致读ID固定最大有效带宽利用率较ID号不固定情况下降5.8%,如图4所示。

图4 HBM读数据带宽利用率
写地址ID号固定和不固定的情况下,HBM写数据带宽利用率最大为74.50%,有效带宽最大为190.72GB/s。写ID号固定有效带宽利用率和写ID号不固定表现相同,是由于写数据到达HBM控制器时进入缓存,并同时返回写响应信号所致,如图5所示。

图5 HBM写数据带宽利用率
3 基于HBM和DDR3的X-DSP性能测试
3.1 X-DSP体系结构
X-DSP为自主研制的一款高性能多核数字信号处理芯片,包含6个DSP超节点,每个超节点包含2个同构的DPS内核,12个内核通过片上网络访存核外存储。单个DSP内核采用SIMD和VLIW技术,可一拍实现11条标向量指令派发;其主要包括指控单元、标量处理单元SPU、向量处理单元VPU、DMA、768KB的片上阵列存储器AM等,如图6所示。指控单元用于取指和将指令派发至SPU和VPU;SPU包括指令流控、标量运算单元SPE和标量存储器SM,指令流控用于程序流控制,SPE内部集成2个同构的乘加运算部件SMAC2、SMAC1,SM主要实现标量数据访存。VPU包含16个同构向量运算单元VPE,每个VPE集成3个运算部件VMAC1、VMAC2、VMAC3进行向量乘加。DMA可实现核内AM、核内SM与核外存储的数据传输。

图6 X-DSP体系结构
3.2 基于HBM和DDR3的X-DSP性能测试
为评估HBM高带宽性能,本文基于X-DSP体系结构,在X-DSP仿真模拟平台中分别将核外内存配置为HBM和DDR3,评估GEMM程序和典型深度学习程序 AlexNet[14]、VGG16[15]的程序执行时间并分析其性能。
GEMM(通用矩阵乘法)在深度学习中十分重要,全连接层和卷积层基本上都是通过GEMM来实现。我们通过图3.2示例说明矩阵 A12×9216·B9216×4032在X-DSP12个核内划分运算过程:将矩阵B9216×4032按列分成12份,对应到12核中,单核包含336(21×16)列。因AM大小为768KB,将矩阵B9216×336按行分成18份,这样每份大小为B’512×336=672KB(512×18×21×16×4B)依次存入AM。相应的将矩阵A12×9216按列划分为18份得A’12×512,则 A’12×512·B’512×336=C’12×336。矩阵B’各行可划分为21个宽度为16的向量B’0,0,B’0,1,。。。,B’0,20,。。。,B’511,0,B’511,1,。。。,B’511,20。取出存储在 SM 中的 A’中第一行元素 a’0,0,a’0,1,a’0,2,。。。,a’0,511,通过标向量广播操作扩展为宽度为 16 向量 A’0,0,A’0,1,A’0,2,。。。,A’0,511。A’0,0分别与B’0,0,B’0,1,。。。,B’0,20到VPE中进行向量乘后得中间结果 T0,T1,T2,。。。,T20,大小为 1.325KB,放入AM。然后取 A’0,1与 B’1,0,B’1,1,。。。,B’1,20到 VPE中进行向量乘后与之前中间结果累加为新的中间结果 T0,T1,T2,。。。,T20。依次进行 512次上述运算后得C’0,0,C’0,1,C’0,2,。。。,C’0,20。同理,矩阵A’12×512剩余11行与B’512×336进行上述同样运算后得到C’1,0,C’1,1,C’1,2,。。。,C’1,20,。。。,C’11,0,C’11,1,C’11,2,。。。,C’11,20,进而得到矩阵C’12×336。将矩阵B按行分成的18份分别从核外内存中取至AM与矩阵A按列分成的18份进行上述全部运算过程,每次累加更新得到的矩阵C’12×336。最后将12个核所有最终结果合并得到 A12×9216·B9216×4032的最终结果矩阵 C12×4032。
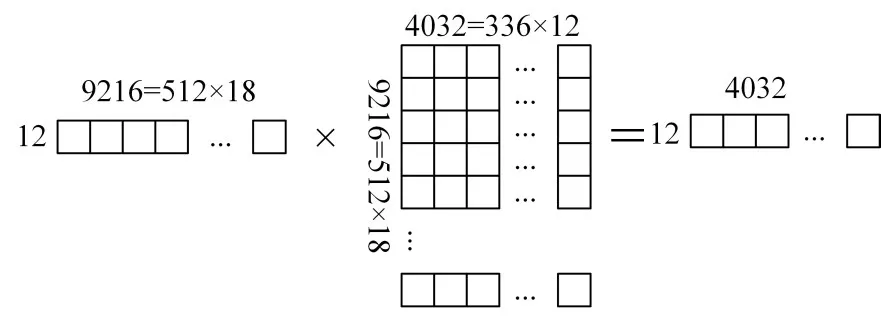
图7 GEMM分块计算示例
经过分析GEMM在12个核中的运算映射过程后,在X-DSP仿真模拟平台运行不同数据规模的GEMM程序。随着GEMM数据规模的不断增加,将数据从核外内存搬移至AM的过程中,HBM相比DDR3的高带宽优势大大缩短了数据搬移时间,从而缩短了程序执行时间,如图8所示。可以看到HBM最大计算资源利用率(计算时间/(计算时间+数据传输时间))达85%左右,而DDR3仅为48%左右。

图8 不同规模GEMM执行时间及计算资源利用率
AlexNet程序主要也是矩阵乘法,其共八层,前五层为卷积层conv1~conv5,后三层为全连接层fc6~fc8。五层卷积层中数据计算占主导,数据搬移量相对较少,对内存带宽要求不高,HBM和DDR3表现差异不大,如图9所示。而三层全连接层中数据搬移量大,DDR3带宽较低,导致VPE需要等待很长的时间才能获得数据进行运算,特别是fc6层;而HBM带宽非常高,可以很快将数据传输到VPE进行计算。总体上HBM相比DDR3将AlexNet程序的执行速度提升3.2倍左右。
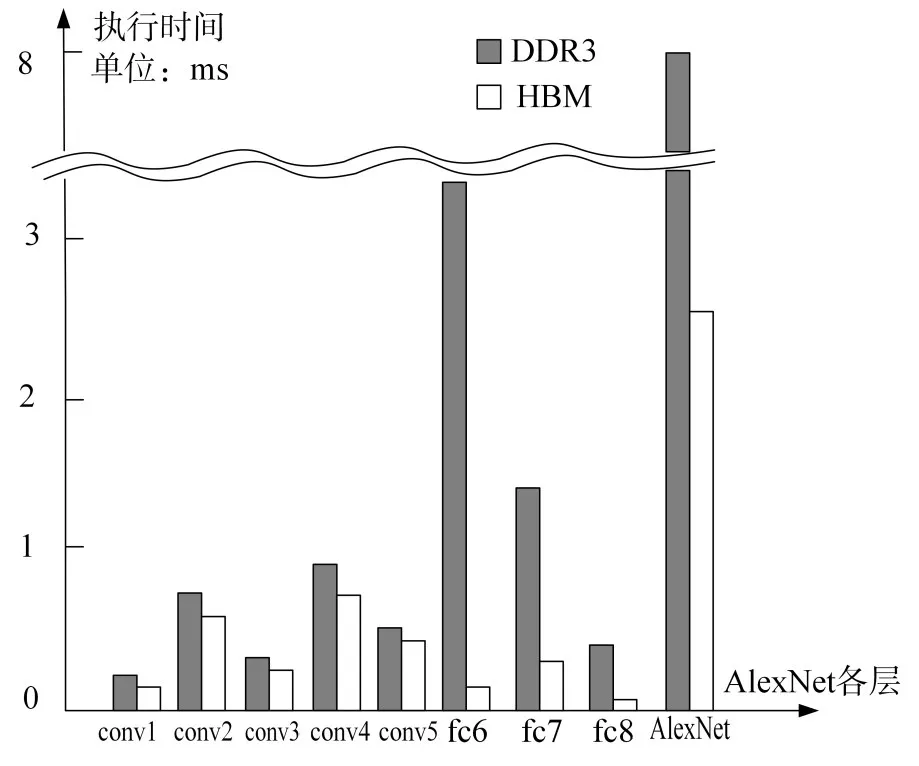
图9 AlexNet各层执行时间
VGG16共16层,前13层为卷积层如AlexNet,数据搬移相较数据计算不占主导,HBM比DDR3提升不大,而在后3个全连接层中HBM表现出更好的性能,大大缩减了全连接层执行时间,总体上比DDR3提升VGG16执行速度1.5倍左右。

图10 VGG16各层执行时间
4 结语
本文通过搭建HBM测试平台,对HBM读写性能进行基本测试,并在多核X-DSP仿真模拟平台中运行GEMM程序及典型深度学习程序AlexNet和VGG16,基于HBM和DDR3对DSP性能差异进行评估。实验结果表明,HBM拥有更高的访存带宽及利用率,可有效提升X-DSP面对大规模算法程序时的计算效率,为新一代多核X-DSP的性能扩展提供了方向。
