基于改进在线序列极限学习机的AMI入侵检测算法
2020-09-18刘菲菲伍忠东丁龙斌
刘菲菲,伍忠东,丁龙斌,张 凯
(兰州交通大学 电子与信息工程学院,兰州 730070)
0 概述
随着电力工业和信息化技术的发展,智能电网成为未来电网的发展方向。智能电网是以电力和信息双向流动为特征的网络。高级量测体系(Advanced Metering Infrastructure,AMI)作为智能电网的核心组件通过与计算机网络互连,实现电力数据的双向通信。因为AMI系统存储资源有限,而传统入侵检测方法部署成本高,所以网络安全防护能力低,容易受到攻击。一旦AMI被攻击利用,用户用电、控制数据、电价等信息就会被窃取,干扰电网正常运行,因此AMI网络的安全研究具有重要的现实意义。
为保证AMI系统安全,NIST提出关于信息安全的研究报告[1]。目前,针对AMI的入侵检测方法多数基于协议规范、安全需求和安全策略。文献[2]针对AMI提出一种基于规则的入侵检测系统,但此系统需要部署传感器网络,成本较高。文献[3]提出基于数据挖掘的AMI入侵检测系统,但需要在智能电表和收集器等系统中进行安装。随着机器学习技术的发展,基于机器学习的入侵检测研究不断被提出。文献[4]利用支持向量机(Support Vector Machine,SVM)与人工免疫系统(Artificial Immune System,AIS)对恶意数据和可能的网络攻击进行检测与分类,解决了分布式拒绝服务(Distributed Denial of Service,DDoS)攻击AMI网络的问题。文献[5]在AMI网络中引入蜜罐作为诱饵系统来检测和收集攻击信息。文献[6]针对AMI提出一种基于数据流挖掘的入侵检测系统,并对其性能进行分析。文献[7]基于1/4超球体的单类支持向量机对AMI节点信任值的序列异常进行检测。文献[8]针对AMI异常用电检测,提出K-means算法与PSO-SVM相结合的无监督分类算法。但SVM仅针对小样本分类具有较好的分类效果,当面对AMI系统中存储资源有限、采集数据量大和数据实时更新的情况时,SVM的分类效果并不理想。文献[9]使用在线序列极限学习机(Online Sequential Extreme Learning Machine,OS-ELM)对AMI系统进行入侵检测,通过数据样本分批学习的方法,当新数据到达时删除旧数据,从而降低训练时间,减少AMI存储资源占用。OS-ELM为AMI入侵检测提供了一种新的解决方法。
可见,在OS-ELM算法中的学习参数需随机设定,且OS-ELM算法容易出现过拟合问题,影响检测准确率。另外,当OS-ELM算法面对海量数据时,由于数据特征过多,既无法保证重要特征的提取,又会增加训练时间,因此本文提出一种基于改进在线序列简化极核极限学习机(DBN-OS-RKELM)的AMI入侵检测算法。
1 DBN-OS-RKELM算法
本文提出的基于DBN-OS-RKELM的入侵检测算法整体框架如图1所示,主要包括3个步骤:
1)数据预处理。将NSL-KDD数据集中的符号特征数据转换为二进制数据,再归一化至[0,1]。
2)深度信念网络(Deep Belief Network,DBN)特征提取。无监督受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)对标准化数据集进行预训练,应用反向传播(Back Propagation,BP)算法进行全局微调,得到降维后的特征向量。
3)OS-RKELM分类器。建立训练网络,在添加数据的过程中实时更新输出权重并对攻击进行分类。

图1 DBN-OS-RKELM算法整体框架Fig.1 Overall framework of DBN-OS-RKELM algorithm
1.1 数据预处理
原始数据集NSL-KDD中存在多种类型的数据,因此在网络训练前需对数据进行预处理,将数据类型统一为网络可识别类型,从而降低网络训练复杂度并提高训练效果。
1.2 基于DBN的特征提取
DBN是由多层无监督RBM网络和一层有监督BP网络组成的深层神经网络[10]。DBN相较于传统神经网络,既提高了提取重要特征的能力,又解决了训练速度慢的问题,同时避免因随机初始化权值参数而陷入局部最优的问题。因此,本文采用DBN进行数据特征提取。整个DBN训练过程分为预训练和权值微调。DBN结构如图2所示,首先RBM逐层堆叠,将原始数据输入最底层RBM进行训练,将抽取的特征作为下一层RBM的输入进行训练,重复训练直至迭代到最大迭代次数,将底层特征向高层特征转化。在学习过程中,RBM降低至原始数据的维数,既保留了数据的主要特征,又降低了冗余特征。然后利用BP算法将错误信息自顶向下传播至每一层RBM,并对RBM进行微调降低误差。
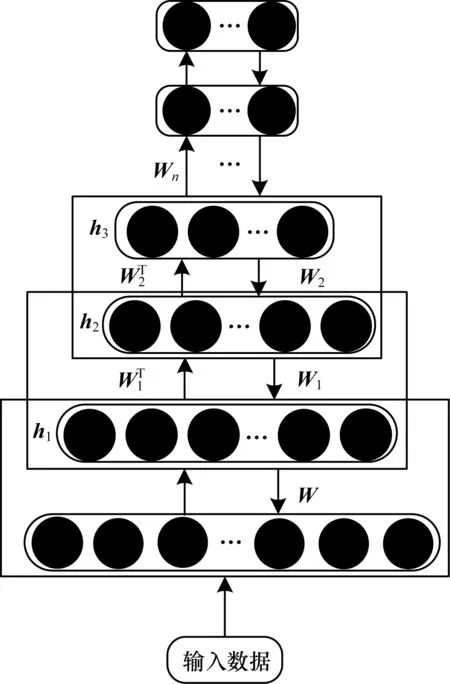
图2 DBN结构Fig.2 DBN structure
1.2.1 RBM网络预训练
RBM是一个两层神经网络,分别包括可视单元(v)和隐藏单元(h),可视单元表示输入数据特征。RBM每层之间为全连接,同层单元之间互不相连,RBM结构如图3所示。其中,vi代表第i个可视单元的状态,hj表示第j个隐藏层单元的状态,wij是可视单元i和隐藏层单元j之间的权重,ai为可视层单元i的偏置,bj为隐藏层单元j的偏置。在预训练过程中,使用贪婪无监督方法对RBM进行逐层训练,使用激活函数sigmoid计算可视层与隐藏层间的概率取值。RBM预训练过程的目标是求解出RBM模型中的参数θ,通常采用梯度下降法求解所有样本的梯度和,但由于本文采用数据集的特征向量过多且计算量大,因此使用基于Gibbs采样的对比散度方法求解更新后的参数θ。

图3 RBM结构Fig.3 RBM structure
RBM采用对比散度方法进行网络预训练的过程[11]具体如下:
输入可视层变量(v1,v2,…,vm)、学习率ε
输出RBM参数θ={W,a,b}
步骤1将输入的可视层变量(v1,v2,…,vm)赋值给v0。




1.2.2 BP权值微调过程
在RBM预训练过程中,每一层RBM网络只能保证权值对本层特征向量映射达到最优,并不能保证对整个DBN特征向量提取达到最优,因此本文基于BP算法利用少量带标签数据自顶向下有监督训练DBN模型[12]。BP算法在权值微调过程中,将错误信息自顶向下传递至每一层RBM,计算样本实际输出值与期望标签的误差值,并将最大似然函数作为目标函数,调整各层权重,避免DBN陷入局部最优,改善神经网络收敛时间长的问题,使DBN模型达到最优解,得到微调后的参数θ。BP权值微调过程具体如下:
输入训练样本(v1,v2,…,vm),预训练得到θ={W,a,b},学习率ε
输出微调后参数θ={W,a,b}
步骤1对于vi的所有输出单元οi,根据ξi=oi(1-oi)(ei-oi)求解其误差梯度ξi(ei为期望输出)。


1.2.3 网络深度确定

(1)
根据文献[13]可知,随着网络深度的增加,不相关部分被弱化,不同类样本间的相关系数不断减小,直至相关系数为-1.00时达到DBN最佳分类状态,既保证了检测效果,又减少了训练时间,如图4所示。本文从训练集随机抽取10 000条正常数据与攻击数据确定DBN网络深度,可以看出当隐含层层数为4时,互相关系数接近-1.00,之后一直趋于稳定,表明4层隐含层为最优深度,因此本文DBN的隐含层层数设置为4。

图4 互相关系数与隐含层层数的关系Fig.4 The relationship between the correlation coefficientand the number of hidden layers
1.3 OS-RKELM分类器
1.3.1 基于OS-ELM的在线学习
神经网络学习模型包括批量学习和在线学习两种模式,极限学习机(Extreme Learning Machine,ELM)作为批量学习模型[14],将所有训练数据一次性投入到模型中,这种模式需要的时间较多且效果不理想。因此,OS-ELM算法将训练数据以数据块的形式按时序分批次投入到网络中进行学习。在新数据到达时,删除已经学习过的数据,既减少了训练时间,又避免了重复训练。因此,OS-ELM算法符合AMI入侵检测的需求[15]。


(2)

(3)
(4)
由文献[14]可知:
(5)
按照这一规律不断更新,加入新数据并删除旧数据。当第K+1批数据到来时,得到此时的输出权重为:
(6)

1.3.2 基于OS-RKELM的在线学习
在训练过程中,OS-ELM算法只有当HHT为非奇异矩阵时,才可以求解隐含层权值矩阵,而在线学习过程中,添加的样本总会出现新旧样本过于相似的问题,导致HHT出现奇异现象,使训练结果过拟合,影响最终检测准确率。另外,OS-ELM算法的输入权值和偏置都为随机设定,泛化能力转弱,对入侵检测结果影响显著。OS-RKELM是一种基于核函数的快速在线分类算法,其能够以块-块的形式分批分类,通过正则化克服OS-ELM算法过拟合问题。与OS-ELM算法不同,OS-RKELM不限制初始训练数据集大小[17],在任何初始训练数据集下均可保持稳定的学习性能,同时加入核函数能够减少随机参数设定对检测准确率的影响。可见,OS-RKELM算法具有更快的学习速率和更少的参数,不仅能够解决OS-ELM算法存在的上述问题[18],而且满足AMI入侵检测的需求。
在OS-ELM算法的基础上加入正则化,正则化是对最小经验误差函数加上约束条件,对误差函数起到引导作用,减小解空间,使得参数达到最优解,具体计算公式如下:
其中,ε为实际输出与理想输出间的误差,C为惩罚系数。根据KKT条件,将约束优化式(7)转化为双重优化问题,即:
(8)

由于网络模型对学习参数进行随机赋值,使得分类结果的泛化能力不理想,因此本文利用核函数将学习样本映射到高维空间,提高分类准确性。定义核矩阵和输出函数如式(9)和式(10)所示:
ΩELM=HHT=h(xi)h(xi)=κ(xi,xi)
(9)

(10)
根据KKT条件对上述约束条件进行求解,得到:
(12)
与OS-ELM相同,OS-RKELM包括初始化与在线学习两个阶段。
1)初始化阶段
从原始输入数据Ω=(xi,ti),i=1,2,…,n中选定新训练数据Ω0=(xi,ti),i=1,2,…,M后进行训练。计算初始阶段的输出层权值β0:
(13)
2)在线学习阶段
在更新学习样本后得到新的权值为:
(14)
其中:
(15)
K1=κ(X1,XM)
(16)
求得:
(17)
当第k+1批数据Ω=(xi,ti),i=k+1,k+2,…,n到达时,可以得到:
(18)
(19)
Kk+1=κ(xk+1,xn)
(20)
(21)
OS-RKELM分类器训练流程如图5所示。

图5 OS-RKELM分类器训练流程Fig.5 Training procedure of OS-RKELM classifier
2 实验结果与分析
2.1 数据集预处理
本文针对AMI受到的攻击类型,采用NSL-KDD数据集进行实验。NSL-KDD数据集是目前得到广泛应用的入侵检测数据集。剔除KDD99数据集中的冗余部分得到新数据集,包含KDDtrain+训练集(125 793条)和KDDtest+测试集(18 794条)两部分[19]。数据集将攻击类型分为Normal、DOS、U2R、R2L和Probe 5类,攻击类型共有21种,各类攻击样本分布如表1所示。

表1 各类攻击样本分布Table 1 Distribution of various attack samples
数据集预处理过程具体如下:
1)数据集中包含41维特征,其中包括38个数字型特征与3个字符型特征。在数据训练前,将字符数据转换成二进制形式,例如将属性特征protocol_type的3种类型分别用二进制表示为tcp[1,0,0]、udp[0,1,0]、icmp[0,0,1],将其余字符型特征都以二进制形式表示。
2)在数据分析前,利用归一化方式将不同维度、性质的数据转换为0~1,转换公式如下:
(22)
其中,y为数据中某维度中的任意值,MAX为该维度中的最大值,MIN为该维度中的最小值。
3)将5种攻击类型分别以对应的编码映射表示为Normal[1,0,0,0,0]、DOS[0,1,0,0,0]、U2R[0,0,1,0,0]、R2L[0,0,0,1,0]和Probe[0,0,0,0,1]。
2.2 实验评价指标
实验采用准确率(AACC)、误报率(FFPR)和训练时间作为评价指标,具体计算公式如下:
(23)
其中,FFP为正常类预测样本数量,TTP为攻击类样本数量,TTN为正确预测正常类样本数量,FFN为攻击类预测为正常类样本数量。
2.3 实验参数设置
DBN-OS-RKELM算法的参数设置如表2所示,本文采用RBF作为OS-RKELM的核函数。

表2 实验参数设置Table 2 Setting of experimental parameters
本文实验过程中正则化系数(γ)、惩罚因子(C)、隐含层个数(L)和新样本数量(Batch)为随机设定,对入侵检测准确率结果有较大影响,如表3所示。通过多次实验,将γ、C、L、Batch 4个参数分别进行循环测试,得到检测准确率最高的参数作为本文最佳参数值。

表3 实验参数随机设置Table 3 Random setting of experimental parameters
2.4 结果分析
实验从检测准确率与训练时间两方面对DBN-OS-RKELM算法进行评价。为证明DBN-OS-RKELM算法的泛化能力和训练速率,与ELM、OS-ELM和基于DBN的在线序列极限学习机(DBN-based Online Sequential Extreme Learning Machine,DBN-OS-ELM)算法进行比较。
实验采用KDDtrain+训练集和KDDtest+测试集对算法性能进行评估。首先在相同实验平台和特征数目的条件下,优化ELM、OS-ELM、DBN-OS-ELM和DBN-OS-RKELM算法参数,使其达到最佳值。为保证实验准确性,每种算法运行20次,取平均值为最终结果。
实验1分别比较OS-ELM、DBN-OS-ELM和DBN-OS-RKELM这3种算法的隐含层对检测准确率的影响,如图6所示。DBN-OS-RKELM算法在隐含层节点为100时准确率最高。隐含层节点个数对OS-ELM算法准确率影响较明显,这是因为作为单隐层网络结构,隐含层个数对分类结果的影响很大。若隐含层节点个数过少,则网络达不到预期的学习能力与检测效果;若隐含层节点个数与特征维度过多,增加了训练时间和网络复杂度,导致泛化能力降低,则会造成过拟合现象。DBN-OS-ELM算法在隐含层节点个数达到70之后,准确率下降,并保持趋于稳定的状态,因此实验中选取的DBN-OS-RKELM和OS-ELM算法的隐含层个数为100,DBN-OS-ELM算法的隐含层个数为70。

图6 网络隐含层节点个数与检测准确率的关系Fig.6 Relationship between the number of hidden layernodes in the network and detection accuracy
实验2分别将ELM、OS-ELM、DBN-OS-ELM和DBN-OS-RKELM这4种算法在相同测试集与训练集上进行实验。如表4所示,OS-ELM算法与ELM算法相比,在减少训练时间的同时检测准确率有所降低;DBN-OS-RKELM与ELM算法相比,在检测准确率上提高了3.36%,而且其训练时间与OS-ELM算法相比变化不大,这是因为DBN特征提取降低了数据维度,并且在OS-RKELM中进行了数据分块和实时学习,进一步减少了训练时间。与OS-ELM、DBN-OS-ELM两种算法相比,DBN-OS-RKELM算法增加了数据特征提取和最优参数搜索过程,其检测准确率的提升表明算法整体性能优于传统极限学习机方法。

表4 4种算法的入侵检测性能对比Table 4 Comparison of intrusion detection performanceof four algorithms
实验3将攻击类型分为Normal、DOS、U2R、R2L和Probe 5类,对ELM、DBN-OS-RKELM、EDF和CNN算法在KDDtest+测试集下的性能进行对比,其中EDF和CNN实验数据来自文献[20]。由表5可以看出,DBN-OS-RKELM算法的检测准确率得到提升,同时大幅降低了训练时间。这是因为在通过特征提取和随机参数寻优后,数据维度降低,计算复杂度也随之降低。DBN-OS-RKELM算法与EDF和CNN算法对于Normal、DOS和Probe攻击类型的检测准确率十分接近,而对U2R和R2L攻击类型的检测效果更好,且训练时间也不会因为识别种类的增加而增加,依旧保持在线学习训练耗时短的优势。对于U2R和R2L攻击类型的检测准确率相对较低的原因为:U2R和R2L攻击类型训练集中的数据量过少,以及分类器在学习过程中得到特征向量的信息过少,因此在识别过程中容易被识别为其他攻击类型。

表5 5种攻击类型的入侵检测性能对比Table 5 Comparison of intrusion detection performance offive types of attacks
3 结束语
本文提出DBN-OS-RKELM算法,将AMI中采集到的日志信息利用DBN提取重要数据特征,应用OS-ELM对实时入侵数据以块的方式进行在线更新分类以缩短检测时间,并通过加入核函数与正则化提高极限学习机的泛化能力。实验结果表明,DBN-OS-RKELM算法解决了OS-ELM算法在检测过程中通过牺牲检测准确率降低训练时间的问题,相比ELM算法在保持准确率的同时大幅降低了训练时间,相比EDF和CNN算法入侵检测准确率更高,体现出其在海量样本情况下实时学习的性能优势,且更适用于智能电网AMI的实际应用。后续可将DBN-OS-RKELM算法应用于智能电网AMI入侵检测实验平台,以验证其正确性与高效性。
