基于DMFA 与深度学习的化工过程多工况异常识别
2020-09-15贾旭清田文德李传坤刘福胜罗忠军
贾旭清, 杨 霞, 田文德, 李传坤, 刘福胜, 罗忠军, 王 辉
(1. 青岛科技大学 化工学院, 山东 青岛 266042; 2. 中国石化安全工程研究院 化学品安全控制国家重点实验室, 山东 青岛 266071; 3. 山东齐旺达集团石油化工有限公司, 山东 临淄 255400)
1 前 言
化工生产是一种涉及复杂物理变化和苛刻化学反应的过程,存在人为误操作、设备异常等引起的多种可能异常状况。如果忽视异常状况发展,轻则导致系统瘫痪,重则发生火灾、爆炸等灾难性事故,所以针对化工过程进行异常检测与识别十分必要[1]。
近年来,异常检测与识别技术快速发展,已被广泛应用于化工生产过程监控。基于数据驱动的异常检测与识别技术受到学术界的广泛关注,例如主成分分析(principal component analysis, PCA)[2-3]和k 近邻算法[4]等,但是以上方法大多是基于浅层知识,难以学习到数据的深层次特征[5]。深度学习[6-7]由于基于深层次的抽象性而拥有更好的特征表示能力,其中卷积神经网络(convolutional neural network, CNN)[8]通过卷积操作学习工艺过程的特征进而构建高精度的异常识别模型,已被成功应用于化工过程异常检测与识别工作[9-10]。异常识别方法假设源域(训练数据)和目标域(测试数据)服从同一分布[11],因此不适用于时刻处于动态平衡的化工过程。YANG 等[12]最早提出了边缘分布自适应的方法,该方法缩短了不同域数据的边缘分布距离。SAITO 等[13]利用条件分布自适应的方法减少了不同域数据的条件分布距离。LONG等[14]提出了联合分布自适应(joint distribution adaptation, JDA)方法,同时考虑了边缘概率分布和条件概率分布。LI 等[15]提出多层域联合自适应的方法,应用于轴承故障诊断中准确度达到90%。后续相关工作均是在JDA 的基础上添加额外损失项,如平衡边缘分布和条件分布权重[16]、类内距和类间距[17]、结构不变性控制[18]、标签持久化[19]和流形对齐[20]等。但以上工作存在2 个问题:第1,直接对原始数据进行分布适配,未能有效构建过程的机理特征[21];第2,主要通过浅层网络学习数据特征,其有限的表示能力和低泛化能力,使其不能获得高度抽象和鲁棒的特征表示。
本文提出一种面向多工况的深层机理特征自适应与深度卷积神经网络(deep mechanism feature adaptation-deep convolutional neural network, DMFA-DCNN)的异常识别方法,并针对化工过程中常见的精馏单元进行了应用。首先,为弥补现有方法直接针对原始数据进行分布适配的缺陷,提出一种新的机理学习自适应模式。构建研究对象的机理模型,学习并自适应机理模型的特征分布,解决化工过程中源域和目标域机理特征分布不一致的问题,使异常识别过程中数据服从同一分布。其次,为解决浅层学习不能获得高度抽象和鲁棒的数据特征问题,采用卷积神经网络分层抽取化工机理模型深层次特征。最后,将本方法应用于脱丙烷精馏塔工业仿真案例。
2 基于DMFA 与深度学习的异常识别模型
化工过程是一个强非线性的动态过程,数学建模复杂度高,求解数学模型计算量大,故采用深度学习网络学习化工过程的输入和输出,实现知识自动获取、表示和推理[22]。化工过程系统的物料衡算方程和能量衡算方程代表了与系统有关的定量关系方程组,可用于构造工艺机理特征。根据所研究的实际化工过程,建立所研究过程的物料衡算方程和热量衡算方程,并定义物料衡算方程和热量衡算方程的各项可测变量值作为深度学习模型输入,网络输入层节点数设置为物料衡算方程和热量衡算方程参数项的个数。激活函数的非线性映射近似了衡算方程的求解过程,通过深卷积层、池化层和非线性激活函数层映射输入层变量值,以获取物料衡算方程和热量衡算方程的定量关系。这些定量关系以多元组标记的形式表示,如式(1)所示。
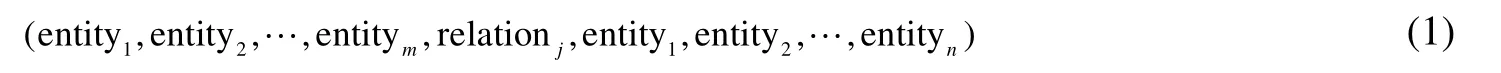
其中,实体表示物料衡算方程和热量衡算方程的各项可测变量值,关系表示各项变量值所建立的符合物料衡算和热量衡算守则的等式关系,m 表示等式左边项的个数,n 表示等式右边项的个数。
针对研究对象的各项实体,构建分层物料衡算方程和热量衡算方程特征提取模型。其中,卷积层通过a 个卷积核学习实体的a 个特征,各卷积层的输出形式如式(2)所示。

其中,f(x)代表激活函数,Wk代表连接第k 个特征图的核权重,bk代表该特征图的偏置。
假设输入实体的形式为1×m×1,在步长s、填充为p 的状态下,经过时域窗口n×1 的卷积核进行卷积特征提取,由CNN 输出式(3)得到特征图形式为1×z1×a,其中z1= (m-n+2p)/s+1。

然后,最大池化层通过池化窗口q×1、步长s 的参数依次滑过特征图1×z1×a,以滑过各个窗口的最大值组成新的特征图1×z2×a,其中z2的计算方法与z1相同。
最终,采用激活函数非线性映射新获取的特征图,以增加整个网络的表达能力。本文采用ReLU (rectified linear unit)激活函数,ReLU 本质上是一个分段函数,其定义如式(4)所示。
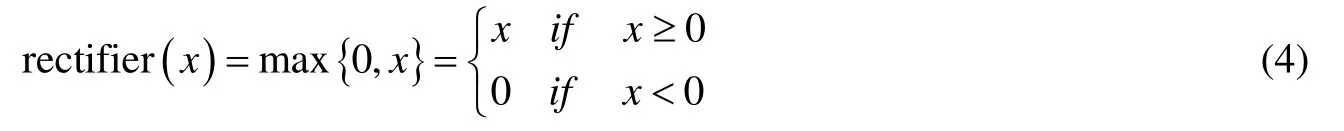
经过卷积、池化和非线性激活函数映射等一系列操作,逐层抽象机理模型实体的深层语义特征。针对多工况的化工过程,通过最大均值距离(maximum mean discrepancy, MMD)实现最小化源域和目标域的边缘概率分布P 和条件概率分布Q,最终设计了DMFA 方法。P 和Q 通过找到两个耦合投影矩阵As和At获得新数据表示,具体如式(5)和(6)所示。

其中,D(x)代表最大均值距离;ns代表源域样本数;Xs代表源域样本矩阵;mt代表目标域样本数;Xt代表目标域样本矩阵;C 代表类别数。
DMFA-DCNN 方法分为2 个阶段:离线训练阶段和在线识别阶段,如图1所示。

图1 基于DMFA-DCNN 的异常识别模型 Fig.1 Anomaly identification model based on DMFA-DCNN
第1 阶段是离线训练阶段,主要实现步骤如下:
(1) 根据历史运行数据建立研究对象的物料衡算方程和热量衡算方程,从而确定式(1)中各实体值;
(2) 通过卷积(式(2))、池化(式(3))和非线性激活函数映射(式(4))等操作层层抽取物料衡算方程和热量衡算方程各项实体值特征;
(3) 将抽取的特征划分为源域和目标域;
(4) 同时适配源域和目标域的P(式(5))和Q(式(6)),以获得最小化MMD 时的As和At;
(5) 通过As和At将源域和目标域变换为新源域和新目标域;
(6) 定义DCNN 的超参数。
(7) 为有效测试模型的泛化性,新目标域仅用于测试识别模型,新源域用于训练识别模型。若模型达到最佳性能则保存模型,否则重新调整模型超参数。
第2 阶段是在线识别阶段。该阶段实时获取化工过程的运行数据,采用建立的DMFA-DCNN 模型实时识别过程数据状态。
3 案例分析
3.1 脱丙烷精馏塔
将DMFA-DCNN 方法应用于某工业仿真脱丙烷精馏塔。脱丙烷塔作为气体分馏装置的一部分,主要用于分离催化裂化装置的液化石油气中的C2、C3 及C4 组分,工艺流程如图2 所示。

图2 脱丙烷精馏塔工艺流程图 Fig.2 Flow diagram of depropanization distillation process
根据脱丙烷塔的工艺流程建立了全塔的热量衡算(式(7))和物料衡算(式(8))。

其中F 为原料液流量,kmol·h-1;IF为进料焓,kJ·kmol-1;QF为进料加热器输入热量,kJ·h-1;QB为外界通过塔釜再沸器输入热量,kJ·h-1;D 代表塔顶采出流量,kmol·h-1;ID代表塔顶采出焓,kJ·kmol-1;W代表塔釜采出流量,kmol·h-1;IW代表塔釜液相焓,kJ·kmol-1;QC为由塔顶冷凝器输出热量,kJ·h-1。其中组分1 代表乙烷,组分2 代表丙烯,组分3 代表丙烷,组分4 代表异丁烯,组分5 代表异丁烷,组分6 代表丁烯-1,组分7 代表正丁烷,组分8 代表反丁烯-1,组分9 代表顺丁烯-1。
该案例包含40 个连续测量变量和6 种工况,涵盖正常工况和5 种异常工况(表1),各种工况的源域和目标域均采集2 000 个样本点。为消除不同变量之间量纲的影响,对样本进行了归一化处理。

表1 脱丙烷精馏塔工况表Table 1 Work conditions list of depropanization distillation process
3.2 构建分层卷积特征提取模型
YOSINSKI 等[23]证明了神经网络的前3 层特征是通用特征,故本文提出的分层卷积特征提取模型采用2 层卷积层,其参数如表2 所示。针对化工高维度数据,采用“t-SNE”可视化技术[24]更好地呈现卷积特征提取过程和效果。该技术可以有效映射原始多维特征空间变量至二维空间,从而实现高维数据的可视化[25]。其中原始机理特征分布和第1、2 层卷积层特征分布的映射效果如图3~5 所示。由图3 可见,多工况之间相互交错,各工况特征离散度高,工况可分性差。通过第1 层卷积层特征提取后(图4),工况特征的重叠部分大幅度减少,但部分特征的可分性仍然较差。通过第2 层卷积层特征提取后(图5),工况特征的可分性较高,但存在源域(S)和目标域(T)特征分布不一致的情况,容易导致模型识别错误,为此本文适配机理特征分布。

表2 分层卷积特征提取模型参数表Table 2 Parameters of layered convolution feature extracted model
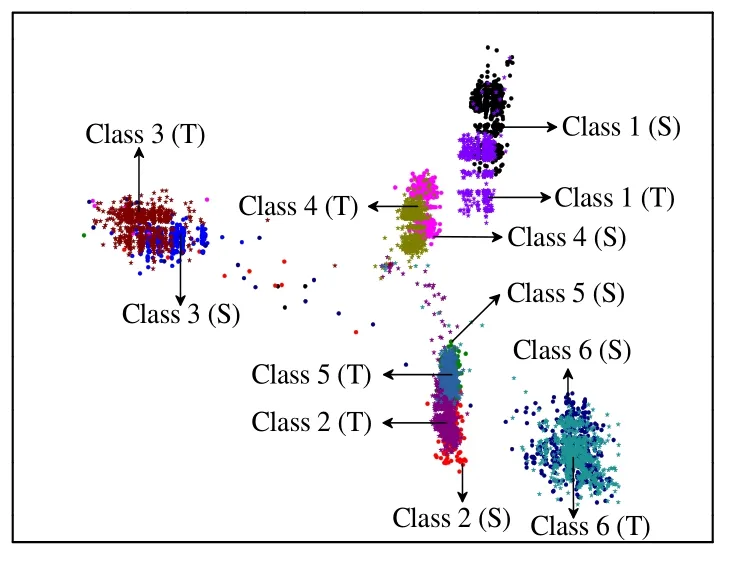
图3 原始机理特征分布可视化图 Fig.3 Visualization map of original mechanism feature distribution

图4 第1 层卷积特征分布可视化图 Fig.4 Visualization map of feature distribution from the first layer convolution

图5 第2 层卷积特征分布可视化图 Fig.5 Visualization map of feature distribution from the second layer convolution
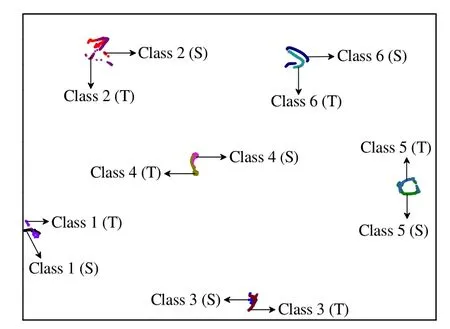
图6 第2 层卷积层机理特征自适应后的特征分布图 Fig.6 Characteristic distribution of mechanism after adaptation from the second layer convolution
3.3 机理特征分布自适应
图6 为适配了第2 层卷积层的输出特征。可以看出,各工况的源域特征和目标域特征分布情况基本一致,消除了化工过程中特征分布不一致对异常识别的影响。
3.4 异常识别
设计的DCNN 识别模型参数如表3 所示,采用经验的方法调整模型参数。第1 层卷积层采用宽卷积核[26],以有效过滤化工过程产生的噪声。第2、3 层采用窄卷积核[27],通过窄卷积核的多层叠加取得了与宽卷积核相同规模的感受野,加深纵向上的网络深度,提高模型识别能力。与相同深度的宽卷积核相比,窄卷积核使用的参数更少。卷积层和池化层均采用高效的ReLU 激活函数[28-29]。为识别多工况的化工过程,分类层激活函数采用softmax[30]。DCNN 参数学习采用小批量梯度下降中的Adam (adaptive moment estimation)方法,设置批次大小为 64,初始化函数设置为he_normal[31]。采用EarlyStopping 方法监测网络的损失函数,在损失函数不再下降时,停止迭代训练,以防止识别模型过拟合。
为了便于清晰地展示所提方法的性能,定义混合矩阵(表4)、F1 分数(式(9))、故障诊断率(fault diagnosis rate, FDR) (式(10))、误报率 (false positive rate, FPR) (式(11))、G-mean 指标(式(12))和准确率(式(13))。

表3 DCNN 异常识别模型参数表Table 3 DCNN model parameters used in anomaly identification

表4 混合矩阵 Table 4 Confusion matrix

将所提出的DMFA-DCNN 模型与单一DCNN 和深层机理特征(deep mechanism feature, DMF)-DCNN异常工况识别方法对比,应用于脱丙烷精馏过程。其中,DCNN 直接识别原始过程数据,DMF-DCNN模型识别经过卷积抽取了工艺机理特征但未经过自适应的特征数据。通过计算F1 分数、FPR、FDR、G-mean 和准确率指标来比较模型性能,进一步说明DMFA-DCNN 模型在工业仿真应用过程中的有效性。脱丙烷精馏塔6 种工况的识别结果见表5~8。在表5 中的6 种工况下,DMFA-DCNN 相较于DCNN 与DMF-DCNN 的识别性能整体较优。DMFA-DCNN 的平均F1 分数为99.87%,相较于DCNN 和DMF-DCNN的平均F1 分数提高了约2.40% 和0.27%。经分析发现DMFA-DCNN 的识别效果提升不明显,这是由于DMFA-DCNN 识别的精馏异常工况多为阶跃异常,其症状表现明显,异常本身容易被识别,加之DCNN 强大的学习能力,故所提出的DMFA-DCNN 方法的F1 分数提升不明显。
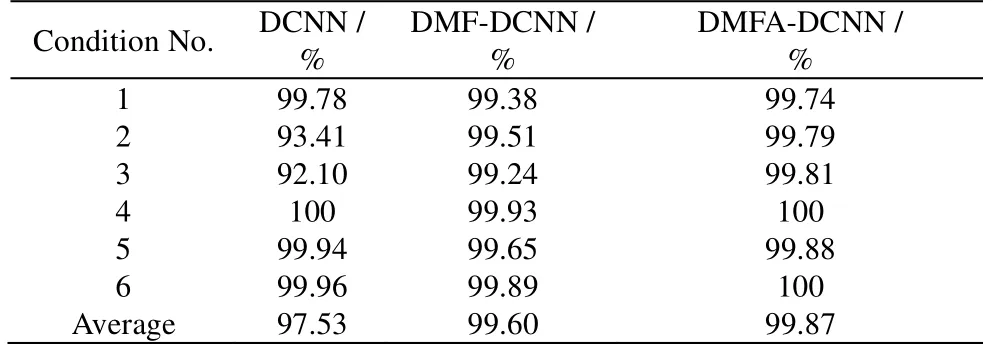
表5 DCNN、DMF-DCNN 和 DMFA-DCNN 模型的 F1 分数 Table 5 F1 scores of DCNN, DMF-DCNN and DMFA-DCNN models

表6 DCNN、DMF-DCNN 和 DMFA-DCNN 模型的 FPR Table 6 FPR of DCNN, DMF-DCNN and DMFA-DCNN models

表7 DCNN、DMF-DCNN 和 DMFA-DCNN 模型的 FDR Table 7 FDR of DCNN, DMF-DCNN and DMFA-DCNN models

表8 DCNN、DMF-DCNN 和 DMFA-DCNN 模型的 G-mean Table 8 G-mean of DCNN, DMF-DCNN and DMFA-DCNN models
FPR 对于工业生产应用有效性具有重要意义,故对FPR进行了对比分析,如表6所示。DMFA-DCNN 的平均FPR 仅为0.03%,与DCNN 和DMF-DCNN 相比降低了93.33% 和50.00%。由表6 可见,DCNN 模型对于异常2和异常3 表现出较高的误报率,分析认为异常2 (再沸器E-702 加热蒸汽暂时中断)和异常3 (系统仪表风暂时中断)均为仪表发生异常,导致了脱丙烷精馏过程表现出类似的症状进而区分困难。
表7 显示了DMFA-DCNN 模型的FDR 结果。由表7 可见,DMFA-DCNN 的平均FDR为99.90%,与DCNN 和DMF-DCNN 相比提高了2.48% 和0.27%。
为了全面比较分析模型性能,本文对比了G-mean 指标(表8)。当不同异常工况的训练数据不相同时,G-mean 指标具有较大参考价值。G-mean 指标是与F1 分数不同的另一种评价模型性能的指标,被定义为准确率和故障诊断率的几何平均数。由表8 可见,DMFA-DCNN 平均G-mean 为99.93%,与DCNN 和DMF-DCNN 相比提高了1.47% 和0.18%。
图7~9 显示了DCNN、DMF-DCNN 和DMFA-DCNN 模型的准确率。由图9 可见,DMFA-DCNN 在迭代261 次时到达停止训练条件,相较DCNN (图7)和DMF-DCNN (图8)识别模型具有更高的识别精度和收敛速度。同时由表9 的运行时间对比结果可见,DMFA-DCNN 运行时间仅为10.56 s (在Core i5, 8 GB内存电脑上测试),与DCNN 和DMF-DCNN 相比节省了72.25% 和67.11% 的运行时间。
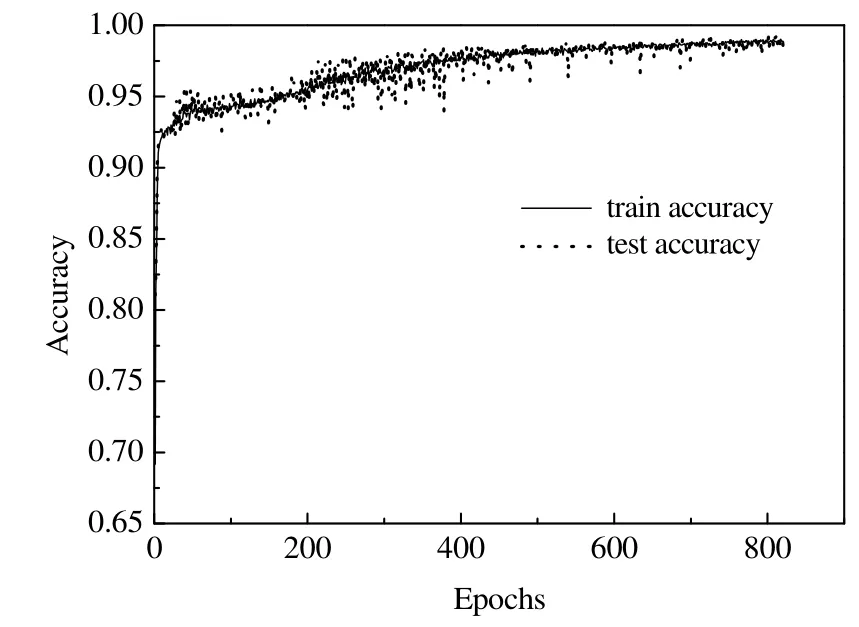
图7 DCNN 对于6 种工况的识别准确率 Fig.7 Identification accuracy of DCNN model for six conditions
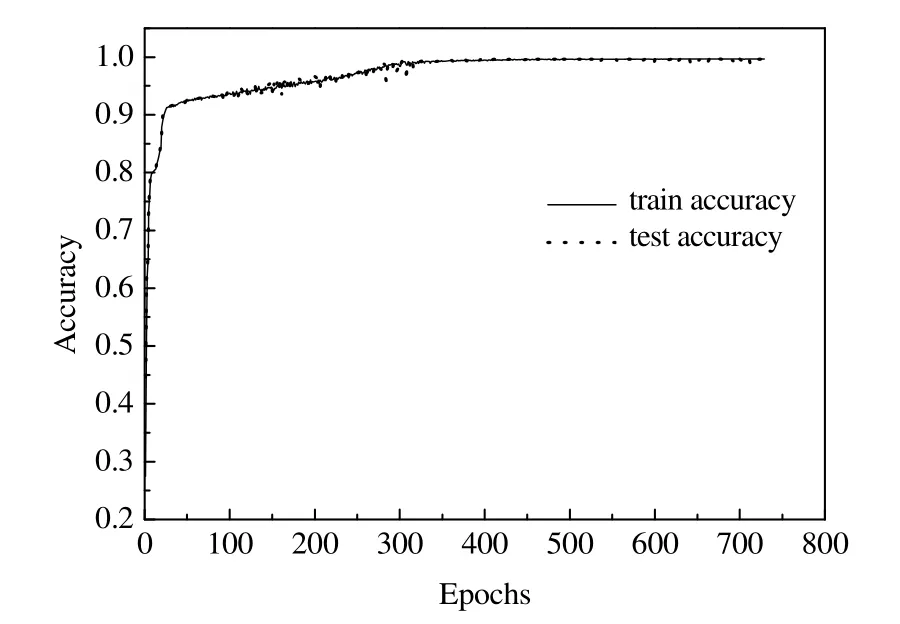
图8 DMF-DCNN 对于6 种工况的识别准确率 Fig.8 Identification accuracy of DMF-DCNN model for six conditions

图9 DMFA-DCNN 对于6 种工况的识别准确率 Fig.9 Identification accuracy of DMFA-DCNN model for six conditions

表9 DCNN, DMF-DCNN 和 DMFA-DCNN 模型的运行时间 Table 9 Running time of DCNN, DMF-DCNN and DMFA-DCNN models

表10 CNN-DAE 和 DMFA-DCNN 模型的准确率 Table 10 Accuracy of CNN-DAE and DMFA-DCNN models
为充分证明本文所提出方法的有效性,还与LI 等[10]提出的CNN-DAE 方法进行了对比,结果如表10 所示。可见,DMFA-DCNN 相较CNN-DAE 识别模型的平均准确率提升了8.37%。
4 结 论
本文提出了一种基于多工况深层机理特征自适应的异常识别方法DMFA-DCNN。F1 分数、FPR、FDR、G-mean 和准确率指标分析结果表明,DMFA-DCNN 识别模型平均F1 分数达到99.87%,平均FPR 为0.03%,平均FDR 达到99.90%,运行时间仅为10.56 s,较DCNN 和DMF-DCNN 识别模型具有更低的误报率、更高的故障诊断率和更短的运行时间。该方法对于异常前期的识别精度仍然较低,如何及时有效地识别微小异常将是以后研究的重点。
