TM5005GNR系统下行多载波聚合下系统时延优化设计
2020-09-10郑旸
郑旸


摘 要:该文围绕解决TM500测试终端载波聚合下行吞吐率和系统时延问题,提出了使用多核多线程并行处理来优化系统时延的方案。通过对比分析方案前后的数据,确定了基于多核多线程并行处理的优点,针对上述方案的具体实现进行详细论述。最后,通过测试仪表与基站联调,证明了该测试方案的有效性和可行性。
关键词:通信与信息系统;载波聚合;吞吐率测试;多核多线程
中图分类号: TN929.5 文献标志码:A
1 项目概况
5G NR基站测试仪表被用在5G NR基站的研发、生产、入网认证、维修等多个环节,测试仪表的成熟度和高效性对5G NR产业链的发展和产品研发起着重要的推动作用[1]。唯亚威公司生产的符合3GPP标准的TM500网络测试仪被认为是无线网络测试的事实标准,在5G研发生命周期的测试中被市场广泛采用,并被应用于新服务推出前的网络性能压力测试。5G NR基于毫米波的多载波聚合技术可以给用户提供超高速及短时延的服务,但这对基站及基站测试仪表性能都提出一个不小的课题。
2 多载波聚合技术原理
载波聚合(Carrier Aggregation,简称CA),通过将多个连续或非连续的载波(Component Carrier,简称CC)聚合成更大的带宽,从而提高频谱资源的利用率,提升上下行速率。下行N个小区载波聚合的最大吞吐率计算公式如公式(1)所示。
式中:J 表示聚合的载波个数,表示每个小区的层数,表示每个小区的最大调制方式,为调节因子,可以配置为1、0.8、0.75和0.4,Rmax为常数,值为 948/1024,为每个小区的最大带宽,为每个小区的平均每子帧的OFDM符号数,参数在FR2下行时配置为0.18。以FR2 120 kHz子载波间隔的8载波为例,当每小区为2层,PDSCH调制方式为256-QAM,小区带宽为100 M时,下行最大速率可达8.6 Gbps。
3 5G NR系统下行链路载波聚合方案设计
3.1 TM500的架构设计
每个5G小区对应一个独立的基带服务器,运行在Dell R630 Intel(R) Xeon(R) Gold 6140 CPU @ 2.30GHz上。由于载波聚合后的下行数据要在MAC层聚合,所以有一台层2服务器运行在Dell R630 CPU: E5-2687W v4 @ 3.00GHz上,负责运行L2协议栈以及管理8个基带服务器。另外一台层3服务器负责运行实时的L3协议栈。TM500作为基站负载测试仪表,可以模拟每个eMBB小区的256个UE,而每个UE的PCC,SCC1,SCC2…SCC7可以随意分布在任何一个基站服务器上。
因此层2服务器作为TM500架构的中心节点,要同时接收并处理来自8個基带服务器的各个UE的下行数据,在MAC层聚合后传给RLC和PDCP层处理,并再对各个UE遍历其所有基带服务器的下行数据CRC结果,汇总后计算其HARQ反馈的码本,再把计算结果发送给其PCC对应的基带服务器。TM500架构设计示意图如图1所示。
3.2 下行载波聚合的HARQ反馈设计
根据3GPP协议,在下行载波聚合时,其DL的HARQ反馈是承载在PCC的PUCCH信道上的(当有上行载波聚合时,也可以承载在SCC的PUSCH信道上)。因各个基带服务器每个时隙独自解码下行PDCCH和PDSCH信道,并把解码结果通过消息发送给L2服务器。L2服务器接收到信息后,保存到HARQ反馈目标时隙,并计算该基带服务器目标时隙上PUCCH的SR信息。当等齐系统中全部基带服务器的消息后,L2服务器轮询每个UE在各个载波上的HARQ反馈并计算码本,保存到目标时隙。然后L2服务器还需要计算各个基带服务器在目标时隙上PUCCH的CSI信息。最后根据每个UE的PCC所对应的基带服务器位置,发送PUCCH的SR/CSI/HARQ反馈信息给相应的基带服务器。
3GPP在dl-DataToUL-ACK中规定了下行HARQ反馈的值域(后用HARQ RTT代替)为0~15个时隙,以FR2 120 kHz子载波间隔中常用配置的4个时隙来计算。手机只有4 × 125us/slot = 500 us的反馈时延预算。再扣除下行解码和上行编码的开销,实际留给L2服务器计算时间只有100 us左右。由于各个基带服务器的编解码优化空间是有限的,所以解决系统时延的关键在于L2服务器。
4 系统延时优化设计
4.1 L2服务器代码重构
Dell R630为戴尔双插槽机架式服务器,属于第13代PowerEdge服务器,采用E5-2687W v4 @ 3.00GHz处理器和四通道DDR4 ECC内存。拥有12核,开启超线程时可同时运行24个线程,L3缓存为30 MB。
在代码重构前,3.2章节所述的L2服务器的HARQ反馈模块是一个线程运行在一个核上,其运行时间约为50 us。在1载波和2载波时,系统的时延还是能满足的。可当系统扩展到8载波时,发现整个模块需要350 us的时间才能运行完,远远大于100 us的预算。但同时,服务器上还有很多核处于空闲状态,并没有把Dell R630的性能发挥到极致,可以通过把该模块并行运行在多个核上,以此来获取并行处理的增益。但如3.2章节所述的,该模块需要轮询各个基带处理器的数据来计算码本的步骤,由于各个基带处理器上报的消息到达顺序不同、计算量不同,简单的多核多线程并行处理就会有线程间空闲数据竞争的风险。
4.2 下行多载波L2服务器并行处理设计
首先为该模块启动8个线程,每2个线程在一个核上。指定核#0上线程#0为主线程,其余为辅线程。8个线程分别和一个基带服务器绑定,接收其上报的下行解码数据,并预计算其上PUCCH的SR信息。主线程计算完后负责检查其他辅线程是否也计算完毕PUCCH的SR信息,而其他辅线程计算完毕SR信息处于等待状态。
当主线程发现全部线程都计算完PUCCH的SR信息后,开始遍历全部基带服务器的下行解码数据,并汇总计算HARQ反馈码本,保存在目标时隙的该UE的PCC所在的基带服务器的缓存里。当所有UE的HARQ反馈码本计算完毕后,主线程通知各个辅线程可以开启后续计算。
接下来8个线程同时并行计算其所对应的基带服务器上PUCCH的CSI信息。最后再分别并行,把PUCCH的CSI/SR/HARQ反馈信息一起发送给其对应的基带服务器,基带服务器完成PUCCH信道编码。
这其中多线程之间的同步是设计的关键。Linux下提供了多种方式来处理线程同步,最常用的是互斥锁、条件变量、信号量和读写锁。但为了节省耗时,采用了原子操作、内存屏障和挥发变量相结合的方法。
原子操作是一种基于基本数据类型的同步形式,底层用汇编锁来控制变量的变化,保证数据的正确性,好处在于不会block互相竞争的线程,且相比锁耗时很少。
内存屏障则是为了达到最佳性能,编译器通常会对汇编级别的指令进行重新排序,从而保持处理器的指令管道尽可能的满。作为优化的一部分,编译器可能会对内存访问的指令进行重新排序(在认为不会影响数据正确性的前提下),然而,这并不一定都是正确的,顺序的变化可能导致一些变量的值得到不正确的结果。内存屏障是一种不会造成线程拥塞的同步工具,它用于确保内存操作的正确顺序。内存屏障像一道屏障,迫使处理器在其前面完成必须的加载或者存储的操作。内存屏障常被用于确保一个线程中,可被其他线程访问的内存操作按照预期的顺序执行。
挥发变量是另外一种针对变量的同步工具。众所周知,CPU访问寄存器的速度比访问内存速度快很多,因此,CPU有时候会将一些变量放置到寄存器中,而不是每次都从内存中读取(例如for循环中的i值)从而优化代码,但是可能会导致错误。对一个变量加上volatile关键字,可以迫使编译器每次都重新从内存中加载该变量,而不会从寄存器中加载。
因此,在判断SR数据是否收集齐处加上原子或的操作,来检查各个辅线程是否完成了PUCCH的SR计算。而每个辅线程在判断是否遍历完毕处会有一个原子异或的操作来表示其已经完成,由主线程完成HARQ码本计算后,通过原子与的操作来释放辅线程进行后续的计算,并通过空循环来等待主线程完成该处的同步释放工作。通过定义挥发变量的操作,以此来保证各个辅线程从内存中读取同步变量。遍历完毕后,调用了内存屏障,从而确保各个辅线程再次计算时内存访问次序的正确性。
5 仿真与结果分析
在和基站联调运行1个UE,FR2 120 kHz子载波间隔的下行8载波聚合的用例时可知,在代码重构前,由于HARQ反馈来不及反馈给基站,出现了一定概率的HARQ重传,最大速率只能达到1.2 Gbps。而在代码重构后,则可以稳定达到理论上的最大峰值速率4.2 Gbps。重构前后指标对比见表1。
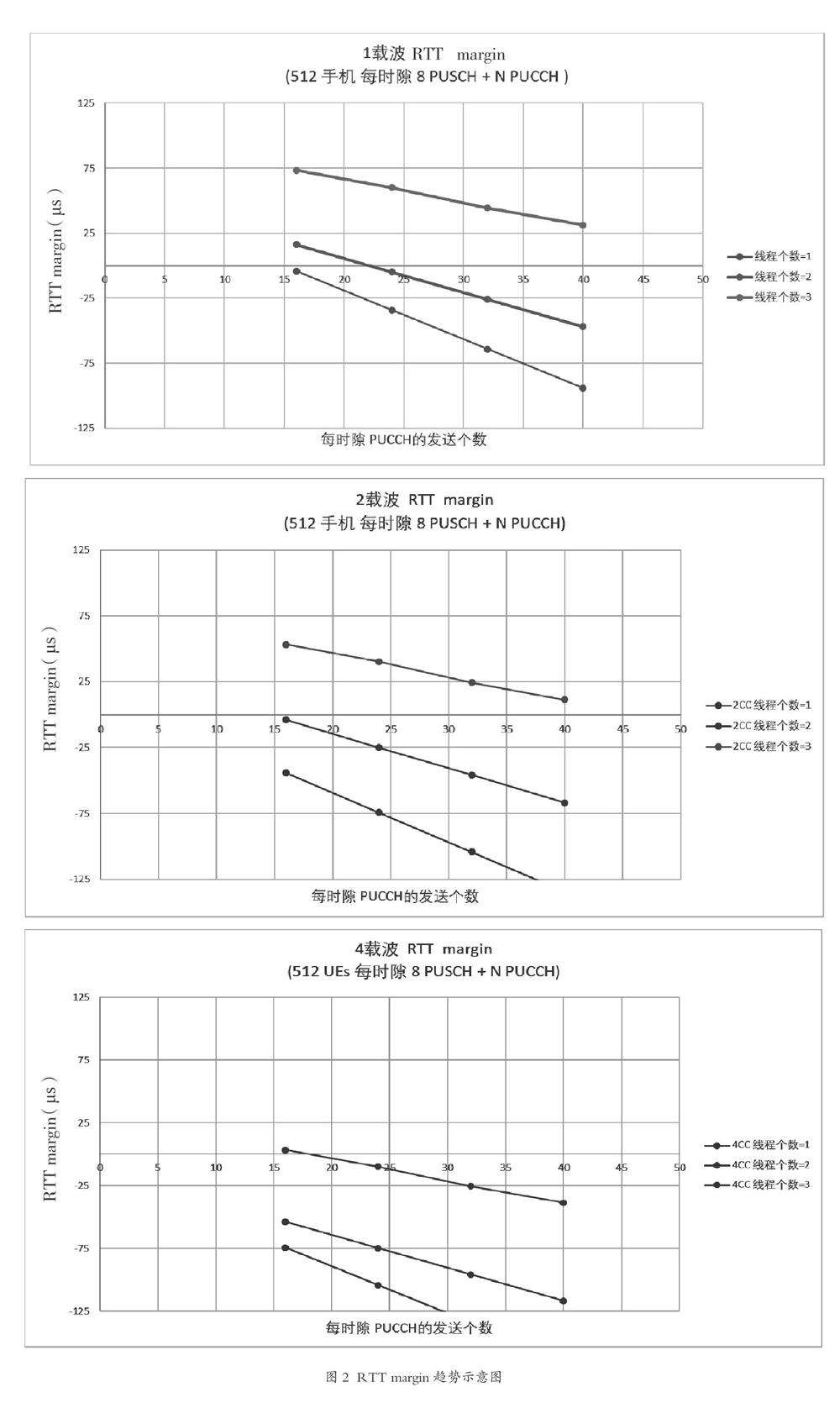
但随着模拟UE个数的增加,發现每个时隙需要上报的PUCCH个数也会增加,从而导致L2服务器的该模块负载也在增加,并最终会导致来不及上报PUCCH的信息(RTT margin为负数)。从图2中可见,RTT margin的趋势不仅和小区数目有关还和UE数目有关。而当线程增加后,对RTT margin是有所提高的。
另外,L2服务器上其他模块如PDCP、RLC在下行8载波聚会时,也存在负载过高的现象,会出现丢包现象,并对发包率、加密算法以及包的大小敏感。
6 结论
该文提出的利用Dell R630服务器E5-2687W v4 @ 3.00GHz多核多线程并行计算的方法,可以有效解决TM500基站测试仪表在FR2 120KHz子载波间隔,下行8载波,64-QAM时的最大吞吐率和HARQ反馈时延的问题。也意识到多核多线程增加了代码的复杂度和调试难度,不同线程间的同步方法各有利弊,如果根据架构实际情况合理设计和利用,可以获得最大化收益。但也看到了在UE个数增加时依旧面临的问题。在未来载波聚合的小区有可能达到32个或者更多,除了升级更高级的硬件服务器之外,更加充分地利用多核多线程并行计算的优势,或许是在不增加产品成本下的一个不错的解决方案。
参考文献
[1]王顺.载波聚合下行吞吐率测试的设计与实现[J].软件,2015,36(10):68-71.
