基于句法差异的汉-越平行句对抽取
2020-09-10于志强高明虎陈宇星
于志强,高明虎,陈宇星
(云南民族大学 信息与网络中心,云南 昆明 650500)
2014年以来,神经机器翻译(neural machine translation)[1-2]得到了迅速发展.作为一种基于数据驱动的新型翻译方式,神经机器翻译对用于模型训练的平行语料有较高要求.在资源丰富型语言对上(如英-法、汉-英),神经机器翻译已经全面超越统计机器翻译,取得了更好的翻译效果.然而,在低资源环境下,受制于平行语料的规模和质量,神经机器翻译的效果欠佳[3].汉-越神经机器翻译作为典型的低资源型机器翻译,同样面临平行语料匮乏问题.然而由于地理及文化因素,两国存在大量对同一事件进行类似叙述的文本,形成了较易获取的可比语料资源,可比语料可被视为主题对齐但非句子对齐的文本集合.相较于成本较高的人工构建等方式,利用机器学习方法从可比语料中抽取伪平行语料的方式更加可行.
针对循环神经网络的研究表明,循环神经网络可以成功地学习从变长序列到连续向量表示的复杂映射.许多自然语言处理任务已经成功地应用了循环神经网络模型,包括手写生成[4]到机器理解[5]等,在机器翻译任务中,针对平行句对抽取问题,一些研究者通过并行组合2个同构的循环神经网络,形成孪生结构的循环神经网络[6],与文本相似度计算方法[7]结合后有效地改进了平行句对抽取效率.
1 相关工作
传统平行句对抽取方法通常使用多模型联合方式.2005年,Munteanu等[8]以统计词对齐模型和最大熵分类器为基础,提出了基于统计的平行句对抽取模型,实现了从新闻文本中自动抽取平行句对,作者将其投入到统计机器翻译训练并获得了性能提升.Adafre等[9]发现了维基百科上文章的平行特性,证明了可基于维基百科生成机器翻译可用的平行语料.Smith等[10]对这2种方法进行了扩展,他们利用Wikipedia文章对的结构和元数据引入了几个新特性,随后通过条件随机场方法在20个手工注释的Wikipedia文章对中应用上述特性,取得了当时最先进的结果.Abdul-Rauf等[11]提出了1种不同的方法,他们不使用分类器,而使用小规模平行语料库构建统计机器翻译系统,通过其翻译可比语料库的源语言部分,以在目标语言部分找到候选句子.针对上述方法中相似度计算复杂性较高的问题,Azpeitia等[12]提出了1种简化方法,其中,2个句子之间的相似度定义为源与目标词之间的Jaccard相似系数的平均值.
随着神经机器翻译研究的普及,近年来,出现了一些基于神经网络的平行句对抽取研究.Chu等[13]训练神经机器翻译模型,基于模型的编码器获得句子的向量表示,将其作为额外特征输入到Munteanu所提出的模型[8].与此类似的是,Cristina等[14]同样基于神经机器翻译模型的编码端获取句子的向量表示,但通过计算余弦相似度方式来判断句对是否平行.Grover等[15]则提出了不同的方法,他们首先通过Luong等[16]的方法学习双语词向量表示,随后使用基于相似矩阵的卷积神经网络来实现平行句对判断.近期,Gregoire等[17]提出了1种利用孪生神经网络抽取平行句对的方法,他们利用双语平行语料训练得到句子的向量表示,建立前馈层,在其上通过改进的相似度计算方法实现平行句对判断.本文方法与其不同之处为:①不完全依赖双语语料,利用低资源环境下更容易获得的单语语料来首先产生句子的向量表示,利用双语语料进行微调;②通过在词嵌入层上叠加词性嵌入层,将句法差异信息融入到词嵌入过程,使其更加适用于汉-越平行句对抽取任务.
2 汉-越平行句对抽取方法
2.1 汉越句法差异

1) 修饰名词或名词性短语的形容词后置;
2) 修饰动词或形容词的副词后置;
3) 多个形容词修饰同一名词或名词性短语时,形容词依次逆序(相对于汉语中的顺序)后置排列.
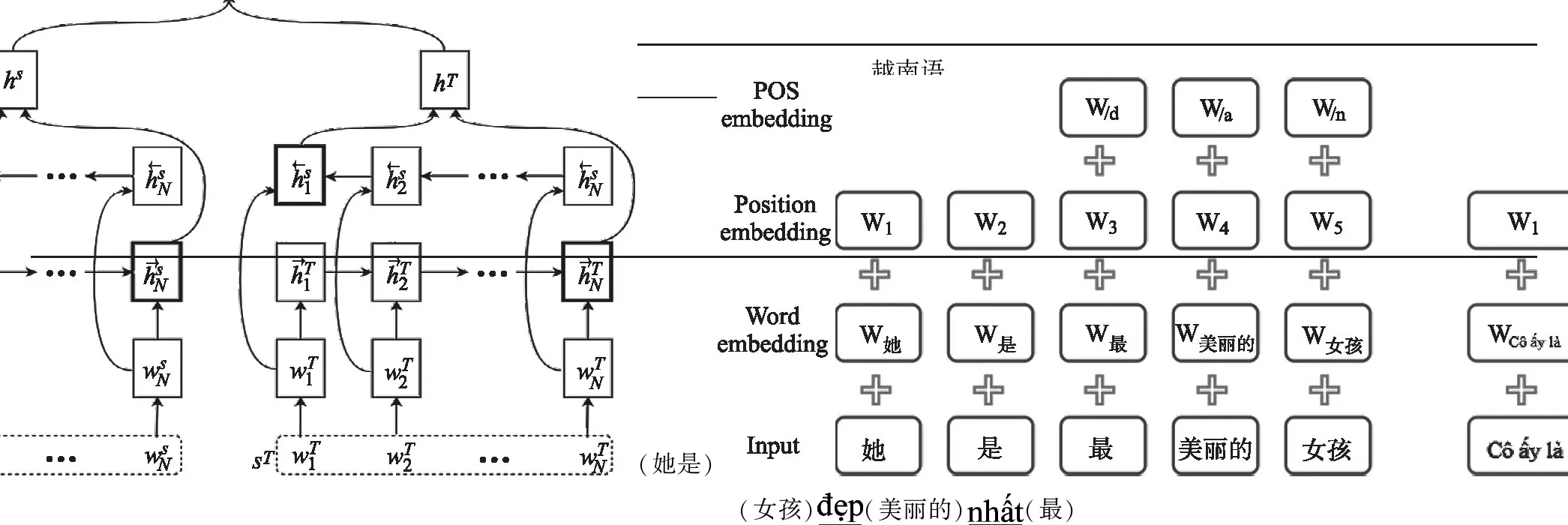
表1 汉语-越南语间语言差异示例
2.2 模型
Gregoire等[17]于2018年提出了孪生神经网络双语句对抽取方法,如图1所示,该方法首先利用平行句对训练将双语词汇映射到统一的向量空间进行表示,随后利用孪生结构[19]的双向循环神经网络(BiRNN)将一对句子编码成2个特征向量hS和hT,最后通过前馈网络判断特征向量间的相似性,得到句子是否平行的分类结果(0代表不平行,1代表平行).
不同于Gregoire等方法的应用场景,我们所面对的汉越翻译场景下,平行语料比较匮乏,因此本文使用Zhang等[20]的方法,先利用单语语料来训练得到对齐的向量空间,通过其产生句子的向量表示,随后使用Mikolov等[21]的方法,利用双语语料进行微调.除此以外,通过在词嵌入层上叠加词性嵌入层,将能体现句法差异的词性信息融入到词嵌入层,使其更加适用于汉-越平行句对抽取任务.
改进后的模型词嵌入层结构如图2所示,在传统的词嵌入(word embedding)层上,首先通过叠加位置嵌入层,使词嵌入更好的体现位置特征.接着通过叠加词性嵌入层,融入能够体现汉越句法差异部分的词性特征,主要为后置关系相关的动词、名词、形容词和副词的词性.最终的词嵌入表示为:
W=We+WP+WPOS.
(1)
其中,We为传统的词嵌入,WP为位置嵌入,WPOS为词性嵌入.
词嵌入层之上,本文沿用Gregoire等[17]方法结构,利用孪生结构的双向循环神经网络(BiRNN)将一对句子编码成2个特征向量hS和hT,随后通过前馈网络判断特征向量间的相似性,具体过程如下:
(2)
(3)
(4)
p(yi=1│hi)=σ(Vhi+bsigmoid).
(5)
其中,σ(·)为sigmoid函数,W1、W2和V为可训练的参数矩阵,btanh和bsigmoid为偏置项.
3 实验
3.1 数据设置
汉越平行句对抽取问题可视为二分类问题,因此构建了平行句对库和不平行句对库,规模均为10万对.其中,平行句对库来自于互联网爬取的8万和亚洲语言树库(asian language treebank, ALT)提供的2万汉越平行句对,不平行句对库由随机抽取于中文维基百科与越南语维基百科中的句子组合而成.句对库中的每组句对后都添加了是否平行标签.测试集由 5 000 汉越句对组成,其中 2 500 句对为汉越平行句对, 2 500 句对为不平行句对.汉语词性标注采用结巴分词工具进行,越南语的词性标注采用VnCoreNLP工具进行.
3.2 训练设置
本文使用基于Tensorflow深度学习框架所实现的BiRNN模型进行实验.BiRNN模型为单层双向结构,使用LSTM作为基本网络单元,词向量维度设置为512,隐藏层节点数设置为512.前馈神经网络的隐藏层节点数设置为256.采用Adam作为优化算法,学习率设置为0.002,批次大小设置为128.为了避免梯度爆炸,使用梯度剪枝,阈值设置为5.测试时利用集束搜索(beam search)算法进行解码,窗口宽度设置为4.
3.3 基线系统与评测标准
本文使用Gregoire等[17]所提方法作为基线系统,为公平起见,基线系统也采用本文得到的词嵌入向量作为基础的词嵌入.抽取的句子质量评测标准为准确率.
3.4 候选句对筛选
真实抽取过程中,需要对可比语料库中的待抽取句子进行笛卡尔积操作,即将句子两两组合后输入网络,通过前馈网络层的sigmoid层输出结果(0或1)来判断是否平行.以规模为106句的可比语料库为例,笛卡尔积操作后的待判断句对数为106×106=1012,随着句子规模的上升,带来巨大的系统开销.因此,本文构建了候选句对筛选器,抽取之前,首先通过筛选器对平行概率过低的句子进行排除.筛选器主要的过滤特征为:排除长度比大于2的句对;排除词共现度小于50%的句对;排除动词、名词、形容词和副词数量差距大于2的句对.
3.5 实验结果
句对抽取准确度结果如表2所示,其中Ours(+P)表示在基础的词嵌入层上叠加了位置嵌入层后的结果,Ours(+POS)表示叠加词性潜入层.可以观察到,加入位置信息和词性信息后,本文方法在汉越句对抽取任务上较基线系统提升了1.73个点.
抽取得到的句对示例如表3所示,可以观察到,在有易区分标记的情况下,例如9.1%,方法抽取的句对效果较好.其他情况下则易存在一些噪声,例如“经常下雨”和“将迎来一轮降雨”在语义上有区别,但在主题(下雨)上基本保持一致.实验结果说明,本文方法可以有效的从汉越可比语料中抽取平行句对.

表2 句对抽取准确度
4 总结
本文针对汉-越低资源环境下平行句对抽取效率的较低问题,提出了一种基于句法差异的汉-越平行句对抽取方法,首先分析汉语和越南语间的句法差异,通过词性标签对差异进行表述;其次,我们利用孪生结构的循环神经网络,在编码过程中融入句法差异信息,从句法规则角度更好的指导抽取过程.实验表明,本文所提方法能够有效地基于汉越可比语料抽取出高质量的汉越平行句对.
