基于改进深度注意神经网络的语义角色标注
2020-09-04梁志剑
梁志剑,郝 淼
(中北大学 大数据学院,山西 太原 030051)
0 引 言
传统语义角色标注方法(semantic role labeling,SRL)[1-3]主要依赖句法分析结果,增加了语义角色标注系统的复杂性。基于端到端[4]和基于长短期记忆神经网络[5](long-term and short-term memory,LSTM)的语义角色标注模型,虽然在一定程度上降低了标注系统的复杂性,但在任意长度序列的预测任务中对句子长短和语句结构的依赖性强。王明轩等提出的深层双向长短期记忆神经网络(deep bidirectional long short term memory,DBLSTM)[6],易于实现且能进行并行处理,在任意长度序列的预测任务中效果良好,但随着网络模型深度的增加,标注效果质量下降。Zhixing Tan等[7]提出了基于注意力机制的深度注意神经网络模型DEEPATT(deep attention neural network),自我注意机制可实现任意两个实体之间的直接连接,即使句子中距离很远的论元也可以通过较短的路径建立联系,使得信息更加通畅,但标签之间具有很强的依赖关系,且模型深度过大也会加重梯度消失,影响了标注准确率。本文提出了一种基于自注意力机制的DEEPATT模型的优化方法,通过在模型的层与层之间使用Layer Normalization进行归一化处理,并引入Highway Networks优化的DBLSTM替代DEEPATT模型中的RNN,增强了模型的稳定性,提高了标注准确率。
1 相关工作
1.1 语义角色标注
当给定某一个语句,语义角色标注的任务就是用来识别每个目标动词并对其进行分类。例如:“小红昨天从小明那儿借了一辆自行车”,SRL会产生如下输出:[ARG0 小红][J借来][ARG1一辆自行车][ARG2向小明][AM-TMP昨天]。其中ARG0代表借方,ARG1代表被借方,ARG2代表借方实体,AM-TMP表示动作发生的时间,J是动词。语义角色标注任务的第一步是标识,为给定的谓语动词标注属性类别,第二步需要为它们分配语义角色。
本文提出的模型则是将语义角色标注作为一个序列标注问题,以上文语句为例,构建一个详细词汇表,用向量V表示,V={小红,昨天,向小明,借来,一辆自行车},向量V的长度等于5。除了词汇表中相应单词索引处的元素外,其余元素使用0表示,词汇表编码为:小红=[1,0,0,0,0]T,昨天=[0,1,0,0,0]T,向小明=[0,0,1,0,0]T,借来=[0,0,0,1,0]T,一辆自行车=[0,0,0,0,1]T,这些编码代表五维空间,其中每个词都占据一个维度,且相互独立,与其它维度无关。这意味着上面语句中的每一个词都是相互独立的,词语和词语之间没有任何关系。而语义角色标注的目的是为了让具有相似背景的词语占据紧密的空间位置,即在数学上,这些矢量之间角度的余弦值应接近1,即角度接近0。为此引入词嵌入向量(Word Embedding),直观地说是引入了一个词对另一个词的依赖性。用词嵌入向量可以用更低维度的特征向量代替高维度的特征向量,这些嵌入向量作为新的输入被送到下一层。本文用改进的DEEPATT作为基本模型,以捕捉句子之间复杂的嵌套结构和词语标签之间存在的潜在依赖关系。
1.2 优化后的深度注意神经网络模型
DEEPATT模型是基于注意力机制[8]的神经网络模型,本文采用DEEPATT模型作为整体架构,每一层神经网络都包含一个注意力机制子层和一个非线性变换子层,第N层神经网络的数据通过SoftMax输出层输出,完成最后的分类。DEEPATT模型中探讨了3种非线性子层,即递归子层、卷积子层、前馈子层。本文首先在层与层之间使用了Layer Normalization来进行全局优化,其次还针对非线性子层的RNN进行了优化,优化后的模型如图1所示。

图1 优化模型
1.2.1 注意力机制子层
近两年,注意力机制的提出为语义角色标注领域带来了新的活力。目前很多研究者开始将注意力机制运用于自己的研究领域,也用注意力机制来搭建整个模型框架。Zhixing Tan等同样将注意力机制应用到了语义角色标注任务中,在CoNLL-2005和CoNLL-2012两个数据集中取得了很好的训练效果。本文运用DEEPATT模型作为整体架构,它的注意力机制层计算步骤主要分为3步,第一步是计算query和key的相似度,得到权重。第二步是用SoftMax函数来做归一化处理。第三步是将得到的权重和相应的value计算求和。计算公式如式(1)所示
(1)
其中,Q表示query vectors,K表示keys,V表示values,d表示网络隐藏单元。
1.2.2 非线性变换子层
DEEPATT模型中的深度注意神经网络模型的非线性变换子层可由递归子层、卷积子层以及前馈子层组成,本文也针对3种非线性子层做了讨论。
对于递归子层,RNN用递归关系来传播网络的信息。神经元节点连接形成一个有向图,对于信息有部分记忆能力。循环神经网络可以使用其内部状态来处理输入序列。
对于卷积子层,本文使用Dauphin等在2016提出的门控线性单元 (gated linear units,GLU)。与标准卷积神经网络相比,GLU更容易学习,在语言建模和机器翻译任务上都取得了令人印象深刻的成绩。给定两个过滤器W∈RK×d和V∈RK×d, GLU的输出激活计算过程如式(2)所示
GLU(X)=(X*W)⊙(X*V)
(2)
滤波器宽度K被设置为3。
对于前馈子层,它由两个中间隐藏ReLU非线性的线性层组成,计算过程如式(3)所示
FFN(X)=ReLU(XW1)W2
(3)
1.2.3 SoftMax输出层
模型通过一层层非线性子层和注意子层的训练,最后通过SoftMax的输出层输出。SoftMax回归是逻辑回归的一种形式,它将输入值归一化为值向量,该值向量遵循总和为1的概率分布,且输出值在[0,1]范围之间。在数学中,SoftMax函数,也称为归一化指数函数。它将K个实数的向量作为输入,并将其归一化为由K个概率组成的概率分布。也就是说,在应用SoftMax之前,一些矢量分量可能是负的,或者大于1,并且可能不等于1,SoftMax函数通常作为神经网络分类器的最后一层,即输出层,经过自注意力机制子层和非线性子层的训练,最后通过输出层输出,完成最后的分类。
1.3 加入Layer Normalization全局优化后的模型
在DEEPATT模型的层与层间加入Layer Normalization[9]进行全局优化,对同一层网络的输出作标准的归一化处理,使模型训练时更趋于稳定。其计算如式(4)至式(5)所示
(4)
(5)
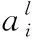
1.4 优化的LSTM单元
1.4.1 LSTM单元
如上文所说,深度注意神经网络模型的灵活变换性主要由于它的非线性变换子层,而非线性变换子层的灵活性主要因为循环神经网络的存在。在语义角色标注任务中,循环神经网络的应用无处不在。谷歌在科研过程中广泛使用循环神经网络来进行语义角色标注,并将其应用于机器翻译,语音识别以及其它一些NLP任务。实际上,通过利用循环神经网络实现了几乎所有与NLP相关的任务,然而传统的循环神经网络对于上下文信息的存取是有限的。随着深度学习框架TensorFlow的兴起,Hochreiter等发明了LSTM[10],将一个称为细胞的存储单元引入网络来解决这个问题,LSTM结构如图2所示。
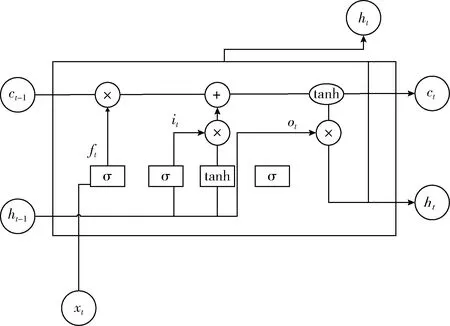
图2 长短期记忆神经网络单元结构
图2中xt表示LSTM单元在t时刻的输入向量,ft表示LSTM单元在t时刻忘记门的激活矢量,it表示LSTM单元在t时刻输入门的激活矢量,ot表示LSTM单元在t时刻输出门的激活矢量,ht表示LSTM单元在t时刻隐藏状态向量也称为LSTM单元的输出向量,ct表示LSTM单元在t时刻的细胞状态向量。W、U、b表示训练时间需要学习的权重矩阵和偏差以及矢量参数,其计算公式如式(6)至式(10)所示
ft=σg(Wfxt+Ufht-1+bf)
(6)
it=σg(Wixt+Uiht-1+bi)
(7)
ot=σg(Woxt+Uoht-1+bo)
(8)
ct=ft*ct-1+it*σc(Wcxt+Ucht-1+bc)
(9)
ct=ot*σh(ct)
(10)
其中,σg表示sigmoid函数,σc,σh表示双曲正切函数。从图2的LSTM结构图可以看出,LSTM单元最后的输出不仅仅与上一层网络的输入有关,还与隐藏状态向量有关。于是本文用Highway Networks优化的DBLSTM代替DEEPATT模型中的RNN来解决SRL序列标注问题,以此来获得标签之间更复杂的依赖关系。
1.4.2 深层双向长短期记忆神经网络
首先对于DBLSTM来说,第一层LSTM正向处理输入的句子序列,得到的输出结果作为第二层的输入,同时反向处理得到输出结果,以此循环。这样就可以从向前和向后两个方向来处理LSTM单元的原始输入。实际上在标注过程当中,对于一个句子的信息是同时提取的,DBLSTM相比于LSTM的优点在于将两个经过不同方向处理的输入得到的输出相互连接,不仅可以利用过去的信息,还可以充分利用未来的信息,在一定的参数下,该方法能在空间上训练出更深层次的神经网络模型。
其计算公式如式(11)至式(14)所示:
图2中从左向右循环神经网络层的公式为
(11)
图2中从右向左循环神经网络层的更新公式为
(12)
双向LSTM的计算公式为
(13)
在这种拓扑结构中,第l层的输入恰好就是第l-1层的输出,第l层的输出公式如式(14)所示
(14)
根据式(14)可以得出,训练更深层次的神经网络会增加网络模型的表达能力,但更深层次的神经网络模型会为训练带来更大的复杂性,训练起来也会更加困难。因此,为了解决神经网络训练达到更深层数时带来的梯度消失、梯度爆炸问题,本文引入Highway Networks来优化DBLSTM替换DEEPATT模型中的RNN来构建非线性子层,相对于DEEPATT(RNN)的结果取得了明显的进步,有效减缓了由于神经网络层数加深导致梯度回流受阻而造成的深层神经网络训练困难问题。
1.4.3 基于Highway Networks优化的DBLSTM
神经网络的深度在一定程度上决定着训练结果的准确性,Highway Networks就是受到长短期记忆网络LSTM的启发,使用自适应门控单元来调节信息流。即使有数百层,也可以通过简单的梯度下降直接训练高速公路网。加入Highway Networks优化的DBLSTM就在一定程度上缓解了训练模型的复杂性。
Highway Networks的基本公式如式(15)至式(22)所示
y=H(x,WH)⊙T(x,WT)+x⊙C(x,Wc)
(15)
其中,y向量由两项组成。T表示转换门transform gate,C表示携带门carry gate。C和T的激活函数都是sigmoid函数
T=(a1,a2,…,an)
(16)
C=(b1,b2,…,bn)
(17)
C=1-T
(18)
y=H(x,WH)⊙T(x,WT)+x⊙C(1-T(x,WT))
(19)
最后得
(20)
雅可比变换
(21)
最后的输出公式为
yi=Hi(x)*T(x)+xi*(1-T(x,WT))
(22)
其中,x,y,H(x,WH),T(x,WT)是同维度向量,不够的话用0补全。或者我们想更改x的维度从A变成B的话,只需要引入一个维度为A×B的矩阵做乘法。由式(21)可以看出,最终通过sigmoid变化,当T(x,WT)=0时,原始输入直接输出,不做任何改变;当T(x,WT)=1时,原始信息在转换之后输出。即使训练层数加深时,也可以用这种方法来收敛层数,从而减少由于网络层数的增加而带来的复杂性,并且可以降低训练模型的难度。
2 实验分析和结果
本文所用实验环境:MacBook Pro;处理器是2.5 GHz Intel Core i7;图形加速卡:Intel Iris Plus Graphics 640 1536 MB;内存:16 GB 2133 MHz LPDDR3;操作系统:IOS;使用Google 开源深度学习框架 TensorFlow 以及anaconda构建神经网络,并在PyCharm软件平台上运行python进行实验。
2.1 实验数据
CoNLL-2005共享任务数据集和CoNLL-2012共享任务数据集。
2.2 实验方法
本文的模型的设置如下。字嵌入和谓词掩码嵌入的维度设置为100,隐藏层的数量设置为10。我们将隐藏神经元数量d设置为200。且采用了Dropout机制来防止神经网络过拟合。
2.3 实验结果与分析
实验结果见表1、表2。

表1 优化模型测试结果(CoNLL-2005)
由实验结果表1、表2可知,在加入Layer normalization[11]改进后的模型在CoNLL-2005共享任务数据集的表现中比之前最好模型DEEPATT的结果优化了0.12个百分比,在CoNLL-2012共享任务数据集的表现中比之前的最好模型DEEPATT的结果优化了0.03个百分比。本文同时也针对DEEPATT模型中的RNN进行了优化,引入基于Highway Networks优化后的DBLSTM替代原模型的RNN层,在CoNLL-2005共享任务数据集中优化后的结果比DEEPATT(RNN)模型的结果提高了0.34个百分比,在CoNLL-2012共享任务数据集中优化后的结果比DEEPATT(RNN)模型的结果提高了0.22个百分比。这说明本文优化后的模型提高了标注准确率。同时也间接说明了Layer normalization和Highway Networks对深度注意神经网络模型训练的重要性。
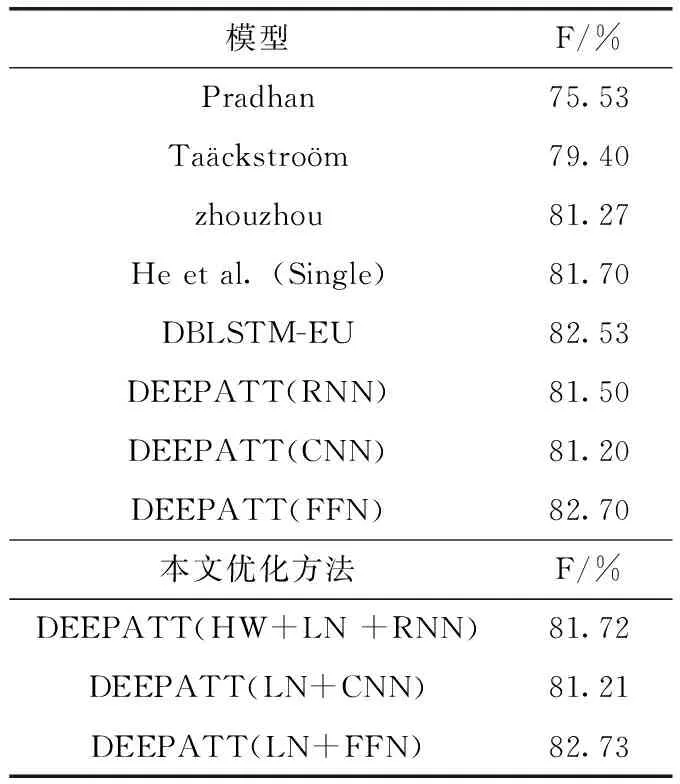
表2 优化模型测试结果(CoNLL-2012)
3 结束语
本文提出了一种基于注意力机制的DEEPATT模型的改进方法,首先对DEEPATT模型的层与层之间使用Layer Normalization进行归一化处理,其次引入Highway networks优化的DBLSTM对DEEPATT中的RNN进行了优化,用来解决语义角色标注过程中存在的问题。本文的实验结果验证了Highway Networks对于解决深度注意神经网络模型训练困难的能力,以及Layer Normalization对于提高深度注意神经网络模型稳定性的能力。虽然本文优化后的方法较之前最好的模型DEEPATT取得的结果有所进步,但本文优化后的模型仍然有可以改进的地方。本文并没有在标注速度上取得很明显的成果,所以笔者接下来将对这一方面进行深入探索。
