基于C-AdaBoost模型的乳腺癌预测研究*
2020-09-03陈思萱
李 勇,陈思萱,贾 海,王 霞
(1.西北师范大学计算机科学与工程学院,甘肃 兰州 730070;2.甘肃省人民医院药剂科,甘肃 兰州 730000)
1 引言
健康是人类全面发展的基础。全球乳腺癌的发病率自20世纪70年代末开始呈上升趋势,乳腺癌在女性患者中的发病趋势更为突出。美国一项调查显示,2016年有1 685 210例新癌症病例和595 690例癌症死亡,其中乳腺癌是20~59岁女性的主要癌症死亡原因[1]。近年,我国乳腺癌发病率的增长速度高于发达国家的,严重影响妇女健康,为此中华全国妇女联合会、卫生部于2009年开始积极实施与推广全国农村妇女“两癌”筛查项目,并于2016年全面铺开,帮助妇女提高保健、预防意识,降低乳腺癌发病率[2]。
在进行检查时,细胞的大小、形状、肿块厚度等特征被认为是区分肿瘤良性或恶性的标准,而年龄、肿瘤大小、绝经情况、受侵淋巴结数、是否放疗等特征被认为是影响乳腺癌是否复发的因素。医生很难根据复杂的特征数据人工地确定乳腺癌是否为良性以及乳腺癌复发情况,但计算机技术可以对现有数据进行分析和预测。现有机器学习方法在医学领域的应用帮助医务工作者提高了工作效率,减轻了工作负担。人们在将计算机技术应用到医学领域的同时也在不断尝试对传统的算法进行改进。集成策略[3]将传统单一算法训练器进行整合,从而达到更好的效果。
在已有研究中,Latha等人[4]使用多种特征的组合作为训练集,采用集成策略对心脏病发病率进行预测,该方法将弱分类器的预测准确率提高了7%,实验准确率在84%左右,但没有对算法参数进行优化。Bennett等人[5]提出一种自适应的半监督集成方法,该方法可与Cost-Sensitive分类算法结合进行二分类或多分类任务。Street等人[6]在大规模数据上使用启发式替换策略组合多个弱分类器,建立针对大型流数据分类的快速算法,效果较好。Muzammal等人[7]将无线人体穿戴式网络BSN(Body Sensor Network)中获取的数据输入Ensemble分类器中,以进行早期心脏病的预测,实验达到了较高准确率。Fitriyani等人[8]提出了一种基于集成学习的疾病预测模型DPM(Disease Prediction Model)对糖尿病和高血压进行监测,以降低疾病突发带来的风险。
目前研究者们已经使用深度学习或机器学习方法对不同的乳腺癌数据进行研究,但还未将多个机器学习分类器进行结合,达到强分类的效果。Khan等人[9]使用迁移学习和深度学习相结合的方法对乳腺癌细胞进行检测和分类,达到了较高的准确率。Abbass等人[10]提出基于微分进化算法和局部搜索的神经网络方法进行乳腺癌的预测,其测试准确率的标准差比Fogel等人[11]的降低了0.459。Abdikenov等人[12]使用进化算法NSGA III(Non-dominated Sorting Genetic Algorithm-Ⅲ)初始化深度神经网络并优化其超参数后,用于乳腺癌预后。Liu等人[13]提出端到端的深度学习系统,结合全卷积网络提取乳腺区域数据,其结果与病理学家所做的诊断有较高的相关性。Lu等人[14]提出一种新颖的基于遗传算法的在线梯度增强GAOGB(Genetic Algorithm-based Online Gradient Boosting)模型,通过在线学习[15]技术,实时预测乳腺癌的诊断和预后。以上研究表明,将人工智能应用于医疗领域是实用且行之有效的。
本文基于C-AdaBoost模型对乳腺癌疾病数据进行分析,主要研究成果如下:
(1)通过大量乳腺癌相关数据分析发现,集成学习模型的预测准确率明显优于SVM、KNN等机器学习模型的预测准确率;
(2)使用逐步回归法发现了乳腺癌数据集最优特征组合;
(3)使用C-AdaBoost找到模型最优学习率,实验准确率较传统机器学习以及常用集成优化组合模型的准确率提高至多19.5%。
2 理论与方法
2.1 总体思路框架
根据数据集特征,本文在数据预处理阶段使用SQL脚本和归一化方法对数据进行处理,然后使用C-AdaBoost模型对多个弱分类器进行训练,以达到最终分类效果,本文实验的总体思路如图1所示。

Figure 1 Overall framework of the experiment图1 本文实验总体思路框架
2.2 特征筛选
数据和特征决定了机器学习所能取得效果的上限,而模型和算法只是使效果逼近这个上限[16]。逐步回归[17]是一种使用线性回归模型选择自变量的方法,其基本思想是将变量逐个引入模型,每引入一个变量后都要进行F检验,并对已选入的变量逐个进行t检验。当引入的变量对当前结果影响不显著时,剔除该变量,以确保最后得到最优的变量集合。逐步回归法中,前向法选择变量的具体步骤如算法1所示。
算法1逐步回归前向算法
输入:特征自变量X1,X2,…,Xp,i∈{1,…,p},回归系数βi,偏置ε,显著性水平α,最优属性集合Attribute。
输出:回归方程Y。
步骤1建立一元回归模型。
fori∈{1,2,…,p}do
Y=β0+βiXi+ε
(1)
endfor
步骤2计算变量Xi相应回归系数的F检验的值,并求最大值。
fori∈{1,2,…,p}do
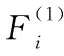
(2)
endfor
步骤3对给定的显著性水平α,记相应的临界值为F(1)。

Attribute={Xi1}
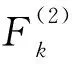
fori∈{2,…,p}do
(3)
endfor
步骤5对给定的显著性水平α,记相应的临界值为F(2)。

Attribute={Xi1,Xi2}
步骤6考虑因变量子集(Xi1,Xi2,Xk)的回归,其中,Xk∈Attribute,k∈{1,…,p},重复步骤4和步骤5,最终得到特征回归方程:
Y=βiAttribute+ε
(4)
2.3 模型选择
集成策略从概念上讲并非是单个的机器学习算法,而是通过结合多个机器学习器来完成学习任务,主要思想是利用多个训练器进行训练,并要求这些训练器都是弱训练器,然后将这些训练器进行组合,生成一个强训练器,进而达到比弱训练器更好的预测效果。
2.3.1 Bagging算法描述
Bagging算法[18]又称袋装算法,该算法中各个弱训练器之间不存在强依赖关系,可并行化地执行训练,其主要思想是分别训练多个不同的模型,然后使用投票法、平均法等对各个模型的输出进行综合决策。算法流程如图2所示。
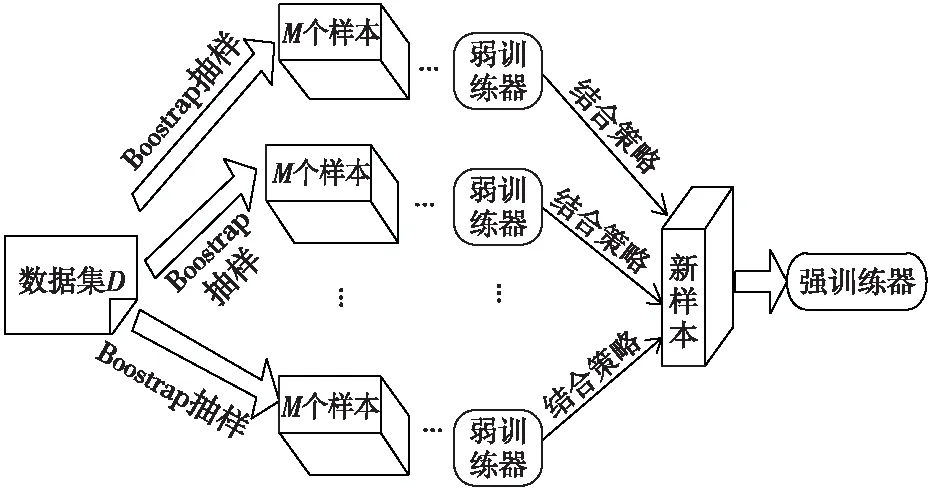
Figure 2 Process of Bagging algorithm图2 Bagging算法流程
Bagging算法中,已知原始数据集D={(x1,y1),(x2,y2),…,(xd,yd)},训练集数据T={(x1,y1),(x2,y2),…,(xn,yn)},x为样本特征,y为样本标签,xi=(X1,X2,…,Xp),ξ为弱训练器,执行K轮抽样。Bagging算法如算法2所示。
算法2Bagging算法
输入:执行轮次K,数据集D={(x1,y1),(x2,y2),(x3,y3),…,(xd,yd)}。
输出:集成分类器G。
步骤1数据集采样,使用Boostrap从数据集中抽样K个大小为M的训练集Di={(x1,y1),(x2,y2),…,(xM,yM)}。
fori∈{1,2,…,K}do
Boostrap(Di)
endfor
步骤2训练模型hi。
fori∈{1,2,…,K}do
hi=ξ(Di)
endfor
步骤3将测试数据集T输入至已训练好的模型hi中,采用投票法对测试结果进行汇总,得到最终分类结果Pmax。
Pmax=argmax ∑ξ(T)
(5)
2.3.2 Boosting算法描述
Boosting算法是一种集成算法[19],该算法中各个弱分类器之间存在强依赖关系,需串行地执行训练,其主要思想是从初始训练集中训练一个弱训练器,随后根据弱训练器的表现调整初始训练样本的分布,将调整后的样本输入到下一个弱训练器,最后将所有的弱训练器进行结合,得到强训练器。算法流程如图3所示。
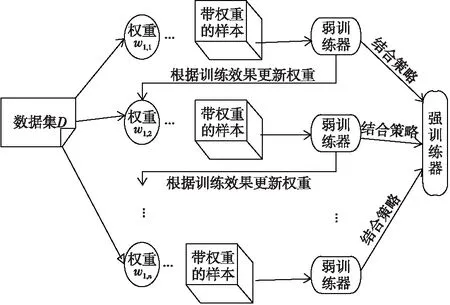
Figure 3 Process of Boosting algorithm图3 Boosting算法流程图
AdaBoost是Boosting集成策略中的代表性算法,在该算法中,已知原始数据集D={(x1,y1),(x2,y2),…,(xn,yn)},执行m轮抽样,I为指示函数,当I函数括号内的表达式为真时,函数取值为1,否则取值为0。算法步骤如算法3所示。
算法3AdaBoost算法
输入:数据集D={(x1,y1),(x2,y2),…,(xn,yn)},L个基本分类器Gm,m∈{1,…,L},权值W1=(w1,1,w1,2,…,w1,i,…,w1,n)。
输出:集成分类器G。
步骤1初始化训练数据的权值分布。
fori∈{1,2,…,n}do
(6)
endfor
步骤2使用具有权值分布的训练集Dm,训练弱分类器Gm。Gm(xi)是Gm对xi预测的标签。
form∈{1,2,…,L}do
Gm(xi)
endfor
步骤3计算弱分类器Gm在训练集上的分类误差率,计算Gm的系数αm。
fori∈{1,2,…,n}do

(7)
(8)
endfor
步骤4更新训练数据的权值分布。
fori∈{1,2,…,n}do
(9)
(10)
endfor
步骤5构建基本分类器的线性组合。
fori∈{1,2,…,n}do
(11)
endfor
步骤6根据结合策略,最终得到强分类器。
fori∈{1,2,…,n}do
G(xi)=sign(f(xi))=
(12)
endfor
2.4 C-AdaBoost算法描述
本文使用AdaBoost集成策略的同时,使用函数C对算法进行循环迭代,找到每个集成分类器下最优的学习率,进而使得训练器达到最优的预测效果。C-AdaBoost的核心思想就是通过集成算法寻找最佳准确率对应的最优学习率。具体过程如算法4所示。
算法4C-AdaBoost算法
输入:训练集D={(x1,y1),(x2,y2),…,(xn,yn)},xi是特征,yi是类别,特征数为p,测试集Test={(x1,y1),(x2,y2),…,(xn,yn)},优化函数C,参数γj,1≤j≤100。
输出:分类结果Ypre,集成分类器G。
步骤1数据预处理。
fori∈{1,2,…,p}do
根据式(1)~式(3)得到最优特征组合方程Y=βiAttribute+ε
endfor
fori∈{1,2,…,p}do
endfor
步骤2权重处理。
fori,j∈{1,2,…,n}do
Initwi,j=1/n
根据式(6)和式(7)更新权重。
endfor
步骤3生成线性组合。
fori∈{1,2,…,n}do
f(xi)=sum(αmGm(xi))
endfor
步骤4在函数C下执行分类器,得最优解。
G(xi)=signC(f(xi))
(14)
步骤5输入测试集数据进行分类。
Ypre=G(Test)
2.5 评估方法
对于最终的分类结果,本文采用准确率(Accu)、精确率(Precise)、召回率(Recall)和F1值(F1)4个指标进行评估。定义如下:
设乳腺癌疾病的二标签数据集,包含n个样本(xi,yi),i=1,2,…,n,yi∈Y,Y={0,1}是标签集合。设G是分类器,G(xi)是G对样本xi预测的标签,则4个评估指标的计算公式如式(15)~式(18)所示:
(15)
(16)
(17)
(18)
3 实证分析
3.1 数据描述
本文使用加州大学UCI数据库中乳腺癌复发数据集(DataSet1)和乳腺癌肿瘤数据集(DataSet2)对模型进行训练和测试。DataSet1数据集中有9个特征,DataSet2数据集中有10个特征,数据集的特征中包括数值型数据和类别型数据。具体的特征表述信息如表1所示。
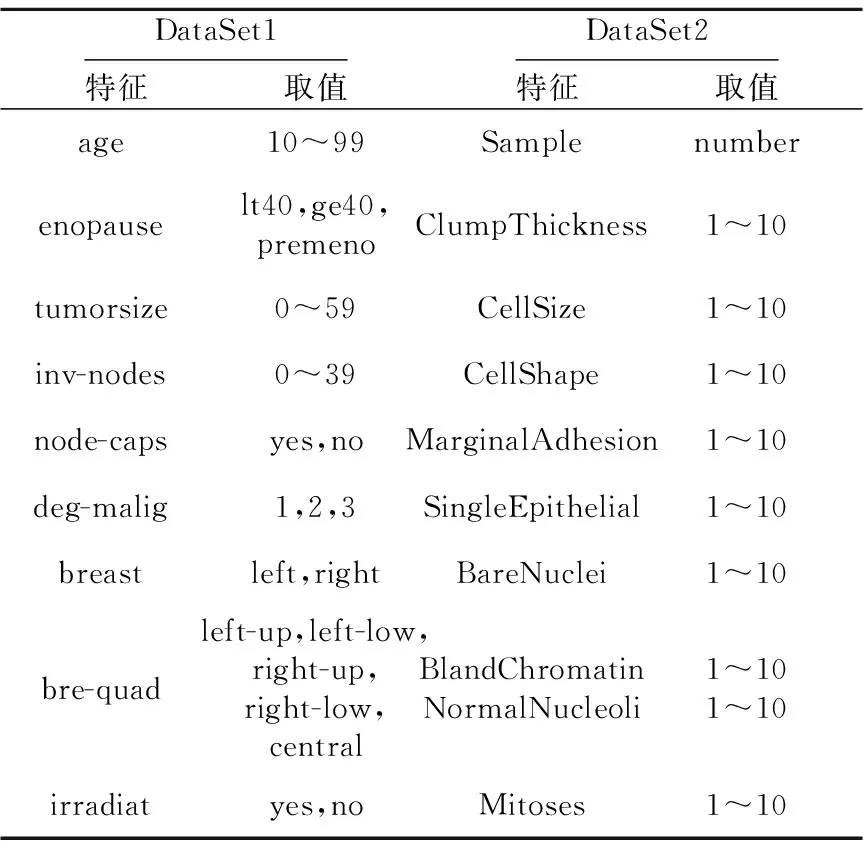
Table 1 Description of characteristic information表1 特征信息描述
3.2 特征选择
本文在选择数据的特征时,希望挑选出更为重要的特征的组合作为最终特征集,因此使用了2.2节提出的逐步回归算法对3.1节中所描述的特征进行二次选取。最终选取的特征和回归系数如表2所示。
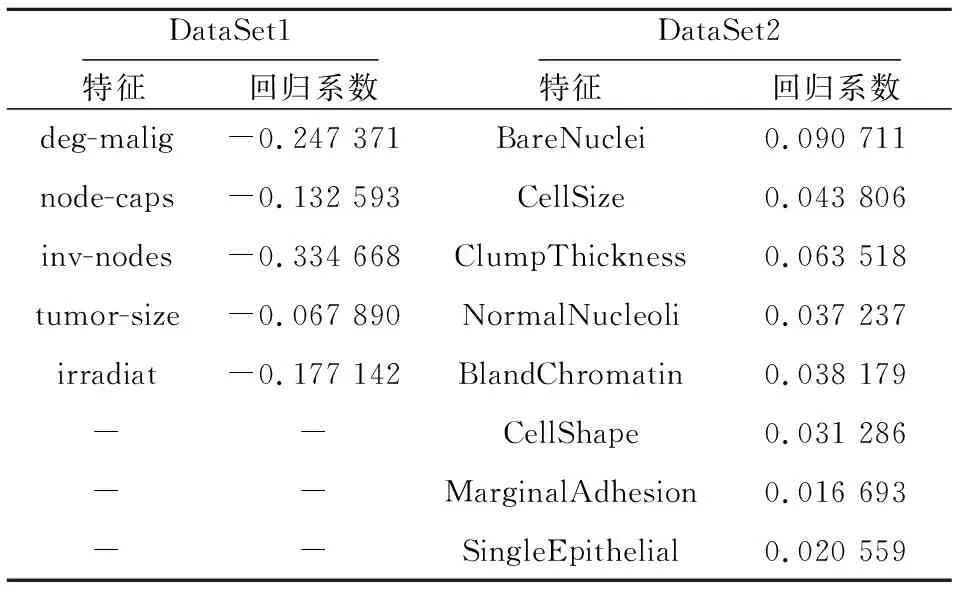
Table 2 Optimal feature combinations and regression coefficients表2 最优特征组合及回归系数
由表2可知,在DataSet1数据集中,通过逐步回归方法,从原始的9个特征中选取了deg-malig、node-caps、inv-nodes、tumor-size和irradiat作为最终的特征组合;同理,在DataSet2数据集中选取BareNuclei、 CellSize 、 ClumpThickness等8个特征作为二次特征选取的结果。
用βi表示特征的回归系数,Attribute表示特征集合。在DataSet1中,回归方程的截距为0.985 365,则回归方程如式(19)所示:
(19)
在DataSet2中,回归方程的截距为1.505 412,则回归方程如式(20)所示:
(20)
3.3 模型优化
集成模型训练过程中,为使AdaBoost训练器尽可能达到相对理想的效果,本文使用优化函数C对算法进行迭代优化,以得到不同参数值下的训练准确率,进而得到最优训练结果。本文使用NB(Navie Bayes)[20]、RandomForest[21]、SVM[22]3组弱分类器进行C-AdaBoost集成,使用DataSet1和DataSet2 2个数据集进行训练和测试,详细结果如图4和图5所示。

Figure 4 Comparison of model’s accuracy under different parameters (DataSet1)图4 不同参数下模型的准确率(DataSet1)

Figure 5 Comparison of model’s accuracy under different parameters (DataSet2)图5 不同参数下模型的准确率(DataSet2)
由图4可以看出,使用SVM作为弱分类器,并且C-AdaBoost模型的参数γj=0.08时,乳腺癌复发预测准确率最高,达到90.1%。
由图5可以看出,使用NB作为弱分类器,并且C-AdaBoost模型的参数γj=0.04时,乳腺癌复发预测准确率最高,达到99%。
结合图4和图5可以发现,在使用NB作为弱分类器执行C-Boosting集成策略时,参数的变化会对实验结果产生较大的影响,而随着参数的不断变化,RandomForest和SVM的训练器相对稳定。
3.4 实验对比
本文将数据集的70%作为训练集,30%作为测试集进行实验,进行如下的实验对比:
实验1使用KNN[23]、NB、RandomForest、SVM和MLP[24]5种机器学习算法作为弱分类器进行Bagging[18]和Boosting算法的集成。
实验2基于实验1的结果,选取Boosting集成算法中的GBDT、XGBoost和 AdaBoost 3种常用的集成策略作为对比模型,进行对比实验。
3.4.1 不同弱分类器下的集成模型对比
使用KNN、NB、RandomForest、SVM和MLP[24]5种机器学习算法作为弱分类器进行Bagging和Boosting算法集成。由于Boosting算法中AdaBoost可进行多种弱分类器的集成,因此选取AdaBoost模型作为Boosting算法的代表模型。实验的准确率、精确率、召回率和F1值4个指标的结果对比分别如表3和表4所示。
表3中的结果表明,DataSet1数据集上使用SVM作为弱分类器的C-AdaBoost模型判断乳腺癌是否复发的F1=0.945,同时召回率达到0.984。
表4中的结果表明,DataSet2数据集在集成策略下的Precise、Recall和F1值整体优于弱分类器。其中,以NB为基本分类器的C-AdaBoost模型的预测效果最好,最高F1值达到0.986。
由表3和表4可得,常用的3种集成方法的实验准确率都明显高于使用单一分类器的准确率。其中,在DataSet1数据集上,准确率最优达到90.1%,在DataSet2数据集上,集成方法的准确率最高达到99%。综上,使用C-AdaBoost模型的准确率最优,能将准确率最多提高19.5%。
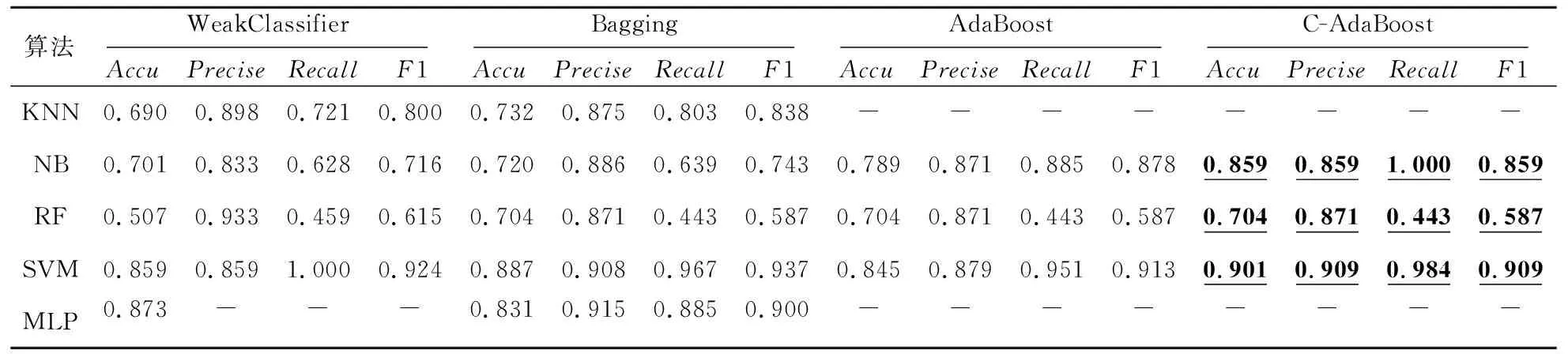
Table 3 Comparison of accuracy, Precise,Recall and F1 (DataSet1)表3 准确率、精确率、召回率和F1值对比(DataSet1)

Table 4 Comparison of accuracy, precise,recall and F1 (DataSet2)表4 准确率、精确率、召回率和F1值对比(DataSet2)
3.4.2 集成优化模型对比
由实验1得出,在本文实验数据集上,Boos-ting集成算法的实验结果优于弱分类和Bagging集成算法。本节实验选取Boosting集成策略常用的GBDT、XGBoost和AdaBoost 3种集成优化模型与本文提出的C-AdaBoost模型进行对比,具体实验结果如表5所示。
由表5可知,基于C-AdaBoost的集成模型在乳腺癌数据集上的实验效果明显优于其他3种常用集成优化模型的实验效果。

Table 5 Comparison of integrated optimization models表5 集成优化模型对比
常用集成模型的准确率的柱状图如图6所示,图示可清晰呈现使用C-AdaBoost集成模型的实验准确率最优,最优可达到99%。
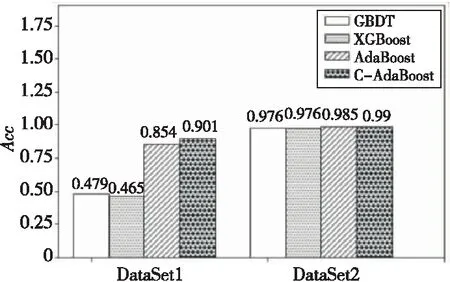
Figure 6 Accuracy comparison of ensemble optimization models图6 集成优化模型准确率对比
本文使用C-AdaBoost模型分别对乳腺癌复发和乳腺癌肿瘤预测进行分析,结果表明C- AdaBoost模型对于不同的乳腺癌数据集均具有较高的预测性能。
4 结束语
本文使用集成策略将不同传统机器学习算法进行结合,基于乳腺癌数据集进行训练和测试,将机器学习和数据分析技术应用于医学领域,提高了疾病预测的准确率,从而可以更好地辅助医生进行诊断,提高工作效率。
本文的贡献主要有:(1)通过大量实验发现,使用集成算法替代单个机器学习分类器,可在疾病预测问题上得到更高的预测准确率;(2)使用逐步回归算法可得到数据中最优的特征组合,实验发现恶性肿瘤程度、肿块所在象限、绝经情况等特征对预测乳腺癌复发数据集的纯度影响较大,细胞大小、染色体数量、细胞形状是判断肿瘤是否为良性的重要属性;(3)找到了最优学习率,使得预测准确率最佳,大量实验发现,采用C-AdaBoost模型能将预测准确率最高提高19.5%。这些发现可以辅助医生进行更有针对性的检查,并做出准确诊断。
本文采用的数据是UCI数据库中已经打好标签的乳腺癌数据集,在以后的研究中,可考虑将电子病历EMR(Electronic Medical Record)等文本数据输入至BERT(Bidirectional Encoder Representations from Transformers)模型[25]进行训练,在非结构化的文本数据中自动训练并抽取较为重要的临床特征信息、语义信息,减少人工标注。在算法上,使用C-AdaBoost模型还可更加详细地呈现不同参数下的训练结果,以促进开展后续与医学信息数据挖掘相关的研究。
