基于标准时序生成的科研热点预测及加速方法
2020-09-02韩英昆齐达立
马 艳 ,韩英昆 ,齐达立 ,刘 科
(1.山东电力研究院,山东 济南 250003;2.国网山东省电力公司电力科学研究院,山东 济南 250003)
0 引言
科技情报对国家、社会、企业的战略、计划的制定以及实施都发挥了重要作用。科研热点预测是科技情报领域较新的应用需求。科研工作者、科研项目管理者在选题、立项必须有一定的前瞻性,即立足于当前科学技术现状与社会发展情况,对未来可能产生的新理论或者产生应用价值的新技术做出判断[1-2]。
按照研究主体,科研热点预测分为对网络文章和学术文献的研究。PageRank算法是由Google提出的较为经典的网络文章热点预测算法[3]。基于文本分析的网络文章热点预测也取得了较好的效果[4]。
在没有引入机器学习算法以前,对学术文献的热点预测严重依赖于本领域高级专业人员通过文献查阅与市场调研的方法确定。比如,根据科学引文索引数据库对论文的文献分类分别统计每个分类中的论文数量,用数字来说明文献科研热点集中在哪些领域;还可以根据文献分类分别统计每个分类中的研究作者数量,用客观的数值来表明科研热点的研究热度所在和科研力量集中点[5]。
近年来,利用机器学习技术对学术文献进行科研热点的预测分析得到普遍关注[6]。2003年著名的LDA(Latent Dirichlet Allocation)算法在 pLSI基础上被提出[7],既是一种文档主题生成模型,又是一个包含词、主题和文档三层结构的贝叶斯概率模型。LDA是一种非监督机器学习技术,可用来识别大规模文档集或语料库中潜藏的主题信息。
然而,国内外目前建立的科研热点预测模型,从应用效果上分析还存在以下问题:1)当一个新的理论与技术诞生后,其关联应用领域还需要大量的工作去发掘。2)科研领域中,科研热点词汇数量巨大,每种热点呈现的走势不尽相同,基于标准的机器学习模型拟合热点走势准确率不高。
因此,亟须设计一种考虑时序关系的科研热点预测算法和系统,可对未来一段时间的科学研究热点较为快速准确地预测出来,辅助科研工作者及科研项目管理者的工作。
1 科研热点预测与推送框架
目前,每种科研热点呈现各种各样的时序走势。以某热点科研词汇的点击量为例,其随着时间变化的趋势完全不同,如图1所示。不同的时序走势,导致标准机器学习算法在直接使用时预测准确度不高。这就须设计一种可适应多样时序趋势的预测模型和框架。
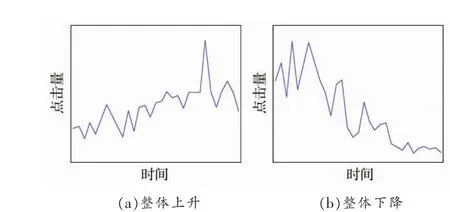
图1 科研词汇的点击量时序趋势
基于上述问题,提出一种基于标准时序生成的科研热点预测框架,使得用户可以及时获得未来一段时间科研热点主题预测推荐。框架分为5个模块,如图2所示,包括时序数据爬取模块、热点数据标记模块、时序聚类模块、热点预测模块、预测加速模块。
时序数据爬取模块利用爬虫技术在科技新闻网站、文献数据库爬取科技信息文章;热点数据标记模块负责标记1个周期的所有热点关键词,并且生成关键词的历史时序数据;时序聚类模块负责对热点时序进行聚类,并且根据聚类结果生成标准热点时序;热点预测模块负责对各关键词的权重TF-IDF时序进行检测,找出热点关键词;预测加速模块负责对热点预测任务进行加速。

图2 科研热点预测与推送框架
2 科研热点预测过程
基于上述框架,给出基于标准时序生成的科研热点预测方法的实施过程,如图3所示。
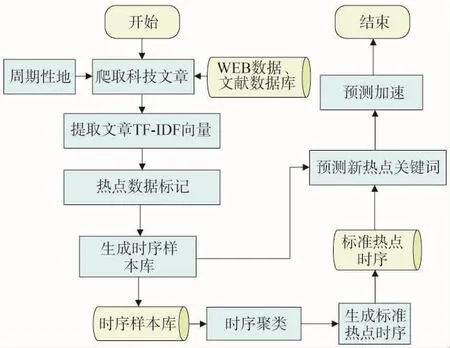
图3 基于标准时序的科研热点预测方法流程
2.1 时序数据爬取模块
时序数据爬取模块将爬取的文章文本化,设一段时间内抓取的科技信息文章集合为Tt,其中t表示周期序号。基于权重TF-IDF算法获得Tt的关键词向量,记为 at={bi|i∈Q},Q 为科技词库中词的数量。设ai为词库中词汇分量第i个关键词,bi为对应关键词ai所得权重TF-IDF值。
计算bi的具体步骤为:
1)设tj是 Tt的一篇文章,基于标准 TF-IDF算法获得tj第i个词汇的TF-IDF值,设为
2)设tj的下载量或阅读量为nj,引用量为mj。那其中分别表示该周期内所有文章nj与mj的平均值。
在具体实施过程中,bi的计算可以基于下载量、阅读量、引用量,也可以基于浏览时长、转发率。
2.2 热点数据标记模块
热点数据标记模块负责标记一个周期的所有热点关键词、生成关键词的历史时序数据,并将这些时序数据加入样本库,用以模型训练。具体方法如下:
1)设置bi的热点阈值,当bi>时,则标记bi对应的ai为热点关键词。
2)生成 ai的 权 重 TF-IDF 时 间 序 列 Bi={bi,t,t=1,2,…,n},其中 bi,t表示第 t个周期 bi的值。 bi,t应从历史数据中获取。
3)筛选首次热点出现序列。首次热点出现序列是指之前关键词ai不是热点词汇,而本周期变为热点词汇,基于此序列训练预测模型可以有效感知未来的热点关键词。设当前周期为t,若bi,t≥且bi,t-1<,则标记Bi为首次热点出现序列。
4)设 Bi,(t-s+1,t)为首次热点出现序列的一个截取样本,Bi,(t-s+1,t)={bi,x,x=t-s+1, …,t-1,t},s 为截取长度,所有的样本长度固定为s。
5)将该样本加入样本集,供时序聚类使用。
2.3 时序聚类模块
该模块通过对热点时序进行聚类[8]生成标准热点时序。通过聚类一组时序数据生成一个标准热点时序的示意见图4。模块的具体流程如下:
1)对样本库的时序数据样本聚类。
首先,基于动态时间规整算法(DTW)计算两个时序样本 Bi,(t-s+1,t)、Bj,(x-s+1,x)的距离,x、t表示起止时间可不同。公式如下:
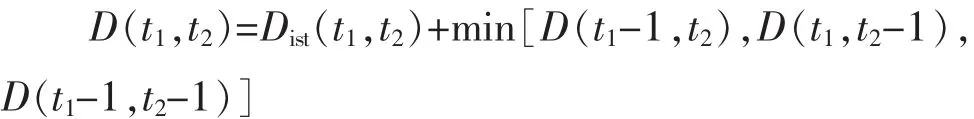
式中:D(t1,t2)为两个时序分别在 t1周期与 t2周期的DTW 距离;Dist(t1,t2)=|bi,t1-bi,t2|。
其次,基于DBSCAN聚类算法对样本库的时序数据样本进行聚类,设生成的聚类为 Cβ|β=1,2,…,n。
2)生成标准热点时序,即基于一个时序聚类中所有时序数据样本计算出一个标准时序,作为该聚类的标准示例。 用 Bβ(t-s+1,t)表示标准热点时序,其计算公式如下为 Bi在 t周期的值,t=1,2,…,S。S为周期的数量。每个时序聚类对应生成一个标准热点时序,设Z为生成标准热点时序的集合,Z={Bβ|β=1,2,…,n}。
3)计算每个聚类中的时序样本与其标准热点时序最远DTW距离。Cβ的最远DTW距离设为mβ。
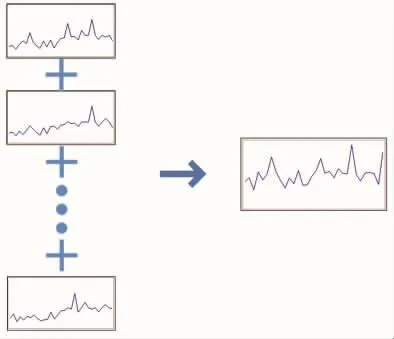
图4 标准热点时序生成
2.4 热点预测模块
该模块负责对各关键词的权重TF-IDF时序进行检测,找出热点关键词。方法如下:
1)过滤掉过低 bi,t的关键词 ai,以减少检测数量。设置过滤阈值 γ,若当前周期其中bi表示近s′个周期bi,x的平均值,则认为关键词ai有可能成为热点关键词,进行检测。反之,则不进行检测。
2)设 ai通过第 1)步过滤,则生成 ai检测序列Bi,Bi={bi,t,t=1,2,…,n}。
过低的γ会导致过多的检测样本,预测效率降低;而过高的γ会导致一些热点关键词被过滤掉,降低热点关键词查全率。在具体实施过程中,可设置
2.5 预测加速模块
本模块负责对热点预测任务进行加速。在热点预测模块,每个关键词都要与每个标准热点时序进行DTW距离计算,因此其时间复杂度为w·|Z|,其中w为模块4(热点预测模块)步骤1)过滤后关键词的数量,|Z|为Z标准热点时序的数量。此方法比较耗时,本模块基于时序特征前置比较的方式,加快预测时间。方法如下:
1)提取每个 Bβ|Bβ∈Z的时序特征。 这些时序特征包括均值、方差、最大值、最小值等,Bβ的时序特征用Vβ表示。
2)初步检测ai检测序列Bi与Bβ的距离。提取Bi的时序特征Vi,基于欧氏距离计算Vi与Vβ的距离,若此距离小于阈值v·,则再进行模块4的热点预测;若大于v·则放弃Bi与DTW距离计算。
3 性能验证
本节验证提出科研热点预测及加速方法的实验性能。提出的算法简称为PASSG(Prediction and Acceleration based on Standard Sequence Generation);无加速模块的算法简称为PSSG算法,即PSSG算法仅包含前4个模块。基准算法使用循环神经网络(RNN)作对比分析,性能指标使用查全率、查准率及预测时间实施评价。

图5 算法查全率和查准率对比分析
首先,验证PASSG和RNN算法对不同样本数量情况下的查全率和查准率,如图5所示。样本数据是指随机抽取热点关键词的样本数量。样本数量分别选定 500、1 500、2 500、3 500。 从图 5 看出,PASSG算法比RNN算法查全率平均提高25.75%,查准率平均提高28.25%,特别是在样本数量较大时。RNN方法将所有样本放入模型进行训练,然而时序具有多样性,其用一个样本拟合,效果不佳。
其次,设置样本数量为3 500,考察参数γ值对PASSG算法查全率与预测时间的影响,如图6所示。横轴为γ大于任意热点标准时序均值的百分比。从图中看出,查全率和预测时间都随着γ的增大递减。因此,算法需要根据实际需求,折中的设置γ值。当对耗时敏感时,应选择较高的γ,而对查全率要求较高时,应选择较低的γ。
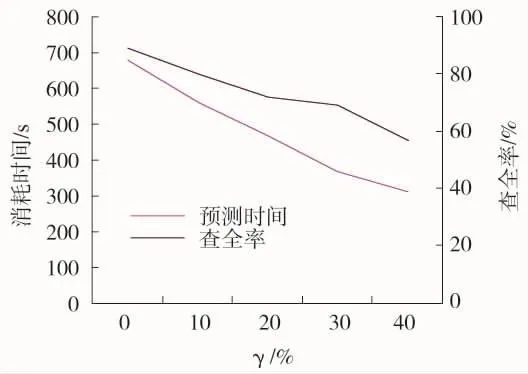
图6 γ值对查全率与预测时间的影响
最后考察预测加速模块的性能表现,如图7所示。设置样本3 500。PSSG是指不用第2.5节的模块5进行加速,直接用第2.4节模块4进行预测。结果表明,使用加速方法的PASSG算法较PSSG算法不仅可以大幅提高预测效率,而且预测的精度损失较小。
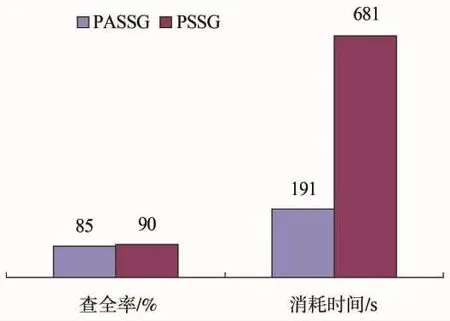
图7 加速方法查全率和消耗时间性能分析
4 结语
提出一种科研热点预测及加速框架,该框架基于权重TF-IDF获取爬取信息的特征向量,兼顾信息的时序变化关系,并基于时序特征前置比较的方式提高预测效率。实验表明,提出框架和方法不仅具有较高的查全率和查准率,预测时间亦在可接受范围内,且随着样本数量的增大,查全率、查准率和预测时间优势明显。
