面向土地交通整体规划的土地利用精细分类模型研究*
2020-08-26武凯飞王慧妮刘少博马晓凤
武凯飞 钟 鸣* 王慧妮 葛 靖 刘少博 马晓凤
(武汉理工大学智能交通系统研究中心1) 武汉 430063) (武汉理工大学国家水运安全工程技术研究中心2) 武汉 430063) (水路公路交通安全控制与装备教育部工程研究中心3) 武汉 430063)
0 引 言
城市交通与土地利用之间联系紧密,土地利用决定了人员数量和货物到发量,交通的发展使得土地利用特征发生变化[1].城市的土地开发使得区域出行量增加,交通需求也随之增加(见图1),在交通设施改善后,区域可达性提高,这又会促进区域土地价格上升,进而又会影响土地利用.如此循环,直到达到饱和状态,区域的土地开发受到抑制.

图1 土地利用与交通容量的关系
城市土地利用对城市交通的影响主要表现为,城市开发程度对交通量、交通方式的影响[2],城市土地利用模式对出行量、交通行为,以及公交系统的影响[3-5].城市交通对城市土地利用的影响主要表现在,城市交通系统的发展对城市空间形态的影响[6],交通系统对城市土地利用结构的影响,城市交通系统对土地利用价格的影响[7-9].土地交通整体规划模型综合考虑了土地利用与交通系统之间的互动关系,为解决土地利用和城市交通问题提供了科学的依据[10].土地利用信息作为模型的输入,对整体规划模型有很大的影响.如果能够将土地利用信息的粒度细化,那么所得到的研究成果的精度也将大幅提高.对于土地利用信息的提取,国内外学者都做了深入的研究.乔红等[11-12]利用高分辨率遥感影像,通过影像融合的手段提取出了水域、植被、耕地、林地等地物信息.姚蓓蓓等[13]对大尺度范围内的土地覆盖信息进行提取,其总体分类精度达到86.49%,Kappa系数为0.836 7.Ahad等[14]利用遥感数据和GIS数据先提取地物信息,在加拿大最小人口调查单元的水平上进行土地利用信息的分类,用地类型包括工业用地、商服用地、居住用地等,分类精度可以达到97.1%.Tuia等[15]从高分辨率的遥感影像中提取相关特征,利用支持向量机方法对其进行分类,最终得到居住用地、商服用地等用地类型,分类精度达到95.93%.
国内在土地利用分类的研究中,以提取地物信息为主,而非土地利用信息.地物信息是土地的自然属性,而土地利用信息则是与社会经济活动相关的土地的经济属性[16],二者不能等同.国外虽然有针对土地利用信息分类的研究,但这是建立在发达国家地块内土地利用种类单一的基础上的.我国单个地块内可能包含多种土地利用类型,致使分类的难度加大,直接利用国外的研究成果对我国的城市土地利用信息进行分类是不准确的.国外相关研究的分类单元以人口调查单元为主,粒度比较大.本研究将研究单元精细化到单个建筑物层面,开展城市土地利用的精细分类研究,为土地交通整体规划提供精细的土地利用信息.
1 分类体系的构建
城市的土地开发或土地使用性质发生变化,对城市交通有重要的影响.不同的用地类型决定了交通量、出行距离、交通方式选择和出行分布形态等,也对交通结构有较大的影响[17].各种用地类型具有不同的交通特性,对交通的影响也有不同.居住用地的人均出行次数与人口规模成反比,出行目的、出行方式具有多样性,对交通的影响具有峰期性和持续性[18].反过来,城市居住用地的布局、规模也受城市交通系统的性质和服务水平的影响[19].商业服务用地对交通可达性要求较高,对停车设施等交通基础设施的需求最大,该用地类型的交通吸引量和产生量都很大,出行方式也呈多样化,对周边道路造成了很大的交通压力[20].因此,商业服务用地的选址大多都在交通枢纽点、街道交叉口等交通便利的地方[21].而工业物流用地产生的交通需求相对于其他用地类型来说比较稳定,出行活动主要由上下班时间及业务特点决定[22].
在充分研究土地利用与交通规划之间的交互关系后,依据《武汉市城市用地分类和代码标准》来建立表1的分类体系.
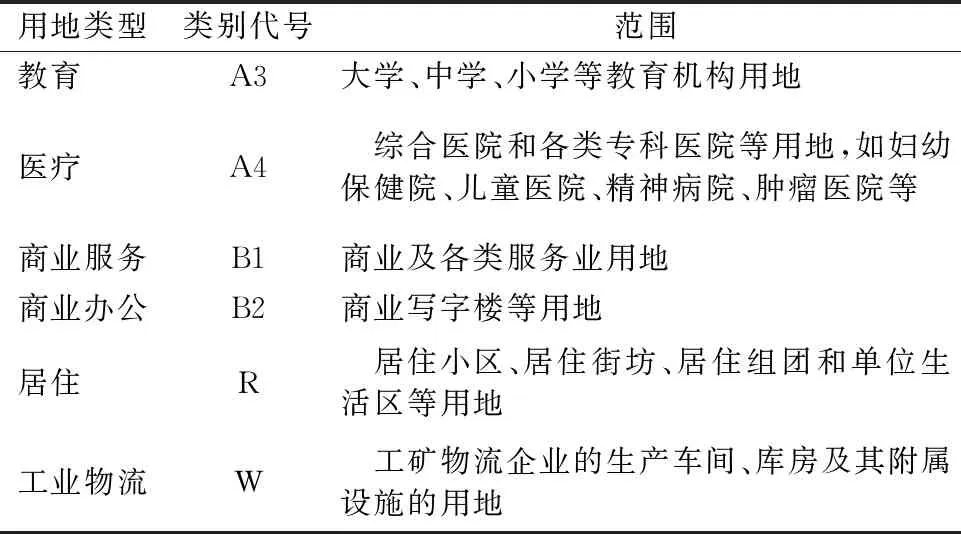
表1 分类体系表
2 构建分类模型
2.1 特征提取
建筑物的形态特征表示建筑物的物理属性,包括底面积、总建筑面积、周长、楼层数、容积率等[23].
建筑物的扩展特征指通过描绘建筑物各种几何边界而获得的特征,包括与封闭建筑物的面积最小的矩形、封闭建筑物的最小凸面、封闭建筑物的宽度最小的矩形及某建筑物的包络矩形等相关的特征.
2.2 分类模型
2.2.1单模型
决策树算法是一种基本的分类算法,被广泛应用于各个领域.在分类过程中,决策树基于特征对实例进行分类,可以认为是if-then规则的集合,或是特征空间与类空间的条件概率分布.在特征选择过程中,利用信息增益来选出当前最好的特征.
SVM算法[24]是一种常见的判别方法,可以用来进行分类或回归分析.其原理是在特征空间中找到能够将样本分隔开的超平面.该超平面是所有能够分隔样本的超平面中,与样本的几何间隔最大的超平面,以保证有充分大的确信度对训练数据进行分类.
随机森林是一种集成学习方法,基础分类器是决策树.所谓“森林”是决策树的集合,即随机森林建立了多个决策树,并将它们合并在一起以获得更准确和稳定的预测.它采用Bagging的思想,将多个弱分类器组成一个强分类器.
2.2.2基于Stacking思想的融合模型
本研究利用Stacking的思想[25-27]对单个模型进行融合,以提高分类结果精度.在利用Stacking思想对模型进行融合时,需要先用训练数据集构建出决策树、SVM、随机森林模型,将其作为一级模型,而后将三个模型的输出结果作为样本特征,对其进行整合,并把原始样本标记为新数据样本标记,生成新的训练集.选取Logistic Regression作为二级模型,利用新训练数据集训练该模型,最后利用该模型对样本进行预测,得到最终分类结果.
与单个模型的训练方式不同,利用Stacking思想进行模型融合时,单个模型是利用K折交叉验证法来训练的,即将整个数据集分成训练集和测试集,再将训练集分成K份,其中K-1份用于训练模型,最后一份用于验证模型.融合模型的训练过程见图2.一级模型中的验证集的预测结果作为二级模型中的训练样本,其测试集的预测结果经过加权平均后,成为二级模型的测试数据集.

图2 融合模型训练过程
对测试集的预测结果进行加权平均的公式如下,各个权重的确定是利用贪心的思想训练得到,即不断改变三个模型的权重,取二级模型在测试集上的预测结果精度最高时所对应的权重.
Pi=aPi1+bPi2+cPi3,i=1,2,…,6
式中:a,b,c为决策树、SVM、随机森林在测试集上的预测结果的权重;Pi1,Pi2,Pi3分别为各个模型将建筑物预测为第i种土地利用类型的概率.
2.3 空间位置关系分析
空间位置关系分析可以用来检验物体在空间上是否有联系,当物体在空间上有联系时,可以认为它们的用途是相同或相似的.研究使用Gabriel图来做空间位置关系分析,并通过设置连线的阈值来提高聚类的精度.Gabriel图可以依据建筑物之间的距离来连接建筑物,因此可以对建筑物进行空间上的聚类,见图3.当点c不在以lab为直径的圆内时,点a与点b视为邻近点,可以用线连接.

图3 Gabriel图
当|lab|2≥|lac|2+|lbc|2时,点c在圆内;
当|lab|2<|lac|2+|lbc|2时,点c在圆外;
利用Gabriel图进行空间位置关系分析时,先在地块内把所有满足Gabriel图的条件的建筑物点连接起来,再通过设定阈值来判定是否需要断开两点之间的连接,由此可以得到多个空间上独立的建筑群,且建筑群内的建筑可以视为同一类型.阈值可以通过距离大小、建筑物特征差异来设定.若超过一定距离时,则需要断开连接.当距离在阈值内,但建筑物的特征差异显著,则需要断开连接.阈值的设定需要反复试验,最终取能够使分类精度达到最大的那个值.
3 案例研究
3.1 实验数据
建筑物数据 建筑物数据来源于商业机构,总共有24 544条,覆盖范围为整个武汉市江岸区.每条数据包含8个字段:ID、建筑面积、建筑底面积、建筑周长、建筑楼层数、周长面积比、经度、纬度,见图4.
3.2 数据处理
原始建筑物数据中,单个建筑物可能由于局部高度不同而被分成若干个建筑物,因此需要先将建筑物进行融合.具体操作可以在ArcGIS软件中进行.建筑物融合后一些属性发生改变,如建筑面积、周长、底面积为融合前各个建筑物的总和.
3.3 模型构建
3.3.1特征提取
在融合建筑物后,对建筑物进行形态分析,提取各种建筑物相关特征.在ArcGIS中,利用建筑物数据,找出建筑物的最小几何边界即封闭建筑物的面积最小的矩形、封闭建筑物的最小凸面、封闭建筑物的宽度最小的矩形及某建筑物的包络矩形等,将得到的属性加到建筑物的原有属性中.最终得到特征见表2的特征向量.

表2 特征向量表
3.3.2选择样本
经过数据预处理和特征提取后,在建筑物数据集中选择样本.由于原始建筑物数据中没有建筑物的类别,因此需要对照百度街景地图和Google实景地图来对建筑物进行标注,最后得到593个样本.将样本按8∶2的比例分为训练集和测试集.分别对训练集和测试集的特征向量做归一化处理,使特征值的量纲一致,见表3.

表3 训练样本表
3.3.3训练单模型
训练模型所用的决策树、SVM、随机森林算法来源于sklearn机器学习包.算法的主要参数值均通过贪心的思想来获得,即取能使精度达到最高的参数值.在训练集上训练各个模型,并在测试集上进行结果比较.各个算法的主要参数见表4~6.

表4 决策树主要参数值

表5 SVM主要参数值

表6 随机森林主要参数值
利用贪心的思想,不断尝试拥有不同数量子树的随机森林,找到能使结果精度达到最高的子树数量.子树数量与测试精度的关系图见图5.由图5可知,在子树数量达到25和37时,精度最高.子树数量过多会使得模型过于复杂,因此选取25棵子树.

图5 子树数量与精度变化
经过训练后,将得到的模型在测试集上进行实验,得到各个算法的精度指标见表7.

表7 算法精度表
由表7可知,三种算法的精度都在0.60以上,其中随机森林算法的精度最高为0.71,模型的kappa系数为0.64,说明模型具有较好的一致性.
3.3.4训练融合模型
以上述决策树、SVM、随机森林算法为基础,利用3折交叉验证方法,训练出三个基础模型.利用贪心算法来计算三个模型的权重值,取训练时测试数据集预测结果精度最高时所对应的系数.融合模型中的Logistic Regression模型的参数见表8.融合模型精度值变化见图6,在系数为0.11,0.27,0.62时模型精度达到最高,精度为0.80.预测结果的混淆矩阵见表9.

表8 Logistic Regression主要参数值
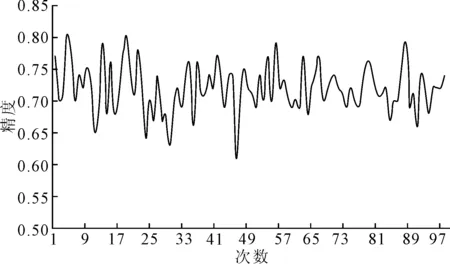
图6 融合模型精度变化

表9 融合模型的混淆矩阵
从融合模型的分类的结果来看,其分类精度达到了0.80.与单模型中的随机森林模型相比,分类精度提高了0.09.其原因在于融合模型通过二级模型的训练,减少了单个模型预测结果的片面性对结果精度的影响,因而其分类精度得到提高.从融合模型的混淆矩阵中可以看出,融合模型居住类型、工业物流类型的判断十分准确.
3.3.5空间位置关系分析
对建筑物初步分类后,用Gabriel图来判断建筑物之间的邻近关系,并结合建筑物的底面积、建筑面积及楼层数进行判断.Gabriel图中点a与点b之间的距离需要设定阈值,若两点之间的距离超过了阈值,则需要将将图中a,b两点之间的连线断开,即点a与点b虽然在空间上是最近的,但由于距离太远而不能被认为是相邻的两个建筑物.通过试验得到每个条件的取值与结果关系见图7.

图7 阈值取值与结果
由图7可知,空间位置关系分析与特征差异阈值结合后,产生邻近关系的判断条件,即当满足楼层数差异超过6层,底面积差异大于2 000 m2,建筑面积差异大于4 000 m2,距离大于100 m中的任意一个条件时,在Gabriel图中应该将两点之间的连线断开.
条件阈值判断前后建筑物的连接关系见图8.由图8可知,条件阈值使得属性差异较大的建筑物的连接关系中被删除,剩下的建筑物距离相近,属性也相似,因此更有可能是同一类型的建筑物.

图8 阈值判断前后的连接关系
对测试集的输出结果进行上述的空间位置关系分析,将建筑物间的距离阈值定为100 m,建筑物的底面积差异阈值定为2 000 m2,将建筑物的建筑面积定为4 000 m2,将建筑物的楼层数差异定为6层.经过空间位置关系分析后,得到建筑物的邻近关系.采用投票的方法选出互相临近的建筑物中,数量最多的那种建筑物类型作为该建筑群中所有建筑物的类型.经过实验后,测试集的分类精度从原来的0.80提升到0.83.
输出误分类纠正后的混淆矩阵见表10.由表10可知,经过误分类纠正后居住类类、商业办公类建筑物的分类精度有了较小的提升.

表10 误分类前后的情况对比个
4 结 论
1) 本研究基于Stacking思想对决策树、SVM、随机森模型进行融合,并利用LogisticRegression模型作为二级模型对城市土地利用类型进行预测.该融合模型可以有效地提高分类精确度,精度最高达0.80.最后通过空间位置关系分析对分类结果进行纠正,使得精度进一步提高到0.83.
2) 与其他相关研究相比,本研究在对城市土地利用类型进行分类时,将分类单元精细化到建筑物层面,从而极大得提高了土地利用信息的精细度,实现了为土地交通整体规划模型提供精细的土地利用信息.
3) 由于数据的短缺,本研究提取的特征种类有限,更多的是从建筑物本身物理特征中衍生出新特征.在之后的研究中,可以增加数据的种类,从而提取丰富的特征来表示各种建筑物.比如,可以使用建筑物的纹理、渗透性等数据.
