游客情感计算的文本大数据挖掘方法比较研究
2020-08-17李君轶任涛陆路正
李君轶 ,任涛 ,陆路正
(1.陕西师范大学地理科学与旅游学院,陕西西安710119; 2.陕西省旅游信息科学重点实验室,陕西西安710119)
0 引 言
旅游是一种人际交往和情感交流活动,情感贯穿于旅游活动的全过程。“情感是人对客观事物是否满足自己需要而产生的态度体验”。游客情感是游客在旅游活动中受个人因素或外部环境影响,对旅游活动是否满足个体的基本需求和社会需求而产生的愉快、兴奋、悲伤、愤怒、后悔等情感体验,并随着旅游进程呈现多样性和易变性[1]。这些情感不仅构成了游客重要的旅游经历,同时也对旅游动机、满意度、行为意图和人际互动等产生重要影响[2]。在旅游中,游客通过在线平台和社交媒体获取信息,分享自己的旅游体验。其发布的文本、图像、音视频成为旅游大数据的主要数据源[3],其中,文本内容以其方便、简单、直观、快捷和低门槛的特点为游客进行情感表达和信息交流提供了便利,在旅游大数据中占有越来越重要的位置。通过对文本数据的挖掘,可为旅游规划、市场营销等提供决策支持,使得旅游大数据中的情感分析成为旅游研究的热点问题[4]。
情感分析就是对信息进行有效的分析和挖掘,识别情感倾向[5]。MEDHAT 等[6]认为,情感分析是文本挖掘领域的研究重点,是对文本的计算处理。早期的情感分析主要是基于文本数据进行词语语义的情感倾向计算[7]和文本情感计算[8-9]。随着研究的深入,情感分析更加精细,出现了情感计算器[10]、情感摘要[11]、产品属性挖掘[12]等研究。近年来,随着大数据的发展,国内外已有许多情感分析模型和软件,为情感研究提供了有力支持[13]。
CHOI 等[14]利用文本数据研究了澳门旅游形象,并验证了“文本分析方法不仅可以进行定性研究,而且可以进行定量研究”;GOVERS 等[15]采用人工神经网络对7 个旅游目的地形象进行了文本内容分析。RADOJEVIC 等[16]利用欧洲 6 000 多家酒店的200 多万条在线评论数据,使用情感分析方法,发现评论是影响酒店满意度最显著的因素;国内学者主要通过ROST 系列软件对文本进行处理,对游客情感与行为互动[17],游客情感与气候舒适度相关性[18],居民、游客情感与空气质量相关性[19-20],目的地形象感知[21],出境旅游者情感特征[22],目的地品牌评价[23]和城市旅游社区形象感知[24]等领域进行了研究。
情感计算是对带有情感的文本进行分析,将其分为积极、消极等情感类型的过程[25]。如果将情感分为积极、中性、消极情感,则情感计算就是分类问题;如果情感为具体的数值或者给定区间上的有序值(如1~5 分),那么通过回归方法可计算情感值。基于文本的粒度差异,情感计算实质上可以视为词语、短语、句子、篇章及多篇章的多等级层次[26]。现有的游客情感研究中,主要采用高频特征词统计法、内容分析软件分析法、情感词典分析法和机器学习等研究目的地形象[27-31]和不同目的地的形象差异[32]。基于内容分析软件的方法,是在高频特征词统计法和情感词典的基础上,通过编写逻辑代码,将分词、词频统计、聚类、共现分析、同被引分析、语义网络、共现矩阵等分析方法集成在一个软件上,实现对文本的处理,常用的软件有CATPAC Ⅱ、ICTCLAS、ROST 等。情感词典分析法主要基于包含标记的情感词、情感短语和程度的一个或多个词典,并结合程度副词、否定词和连词以及句法结构来构建情感计算模型,进行情感分析[33-34]。利用机器学习进行游客情感计算,通过人工标注一部分表达积极情感或消极情感的文本,用这些文本训练机器学习算法,获得情感计算器,再通过此情感计算器对文本数据进行积极情感和消极情感计算,最终给出具体分值0 或1,也可以给出文本的积极概率和消极概率。在机器学习中,常用逻辑回归(logistic)、决策树(decision tree)、支持向量机(SVM)等方法分析情感[35-37]。
国内外学者通过不同分析方法对游客的情感开展研究,主要聚焦于目的地形象感知、满意度等。国内早期研究主要借助内容分析软件判断文本的情感特征。之后有学者在情感词典的基础上,通过设计情感计算规则计算游客情感。随着互联网和人工智能技术的快速发展,已有学者基于文本大数据,用机器学习方法进行游客情感计算研究[35-37]。目前采用深度学习方法进行游客情感计算的研究文献还较少见[38],对不同方法进行比较研究的文献更是少之又少,几乎空白。本文通过对现有情感计算方法的分析归纳,总结基于情感词典和基于机器学习方法的通用技术范式,通过对比分析各种方法的优劣,探索深度学习在游客情感计算中的应用,为后续研究提供技术指引。
1 游客情感计算的不同范式
1.1 基于情感词典的游客情感计算
基于情感词典对游客情感进行计算是对人类大脑处理情感问题的简单模拟,类似于人类大脑对情感处理的路径(见图1)。
1.1.1 情感词典的构建
情感词典的构建非常重要,直接影响计算效果[39]。情感词典主要包括基础情感词典、表情词词典、语气词词典、特殊标识符词典等8 个词典。为了得到更加完整的情感词典,需要不断收集情感词和相关语料进行扩建,如加入旅游专用词汇,有针对性地去杂、分类、更新,以提高情感计算的准确率。除了人工扩建情感词典外[39],还可通过自动或半自动方法进行扩建[10]。情感词典一般有2 种应用,一种是以情感词典为基础设计软件,通过软件对文本进行情感词抽取,根据软件中定义的语法规则和算法计算文本情感值,典型的有ROST[40]和MBEWC[41]。另一种是以情感词典为基础设计情感计算规则,通过逻辑/算法编程开展情感计算。目前以第一种应用为主。

图1 基于情感词典的游客情感计算过程Fig.1 Tourist emotion classification process based on emotional dictionary
1.1.1.1 基础情感词典
基于情感词典的情感计算技术发展至今,已积累了不少的情感词典资源。英文词典主要有general inquirer,LIWC,WordNet 等。中文词典主要有《知网词典》(HowNet)、《同义词词林》《台湾大学中文情感词典》(NTUSD)[42]、张伟等[44]编著的《学生褒贬义词典》、史继林等[45]编著的《褒义词词典》等。
在基础情感词典中,程度副词、否定词和连词对情感倾向有不同的影响,应根据实际情况区别对待。程度副词对情感倾向有加强或减弱作用,是影响情感计算的重要因素。比如,“我来西安玩,非常高兴”,其中“非常”作为程度副词,对于“高兴”的情感程度起到了加强作用。否定词能使句子的情感倾向发生反转,是十分重要的情感计算判断依据。例如,“我不喜欢西安”中的否定词“不”就是对“喜欢”的否定,整个句子由正向情感变为了负向情感。连词用来连接段落、句子、短语、词语等,在句子中表达不同的逻辑关系,可分为并列连词、递进连词和转折连词等,其中并列连词在句子情感倾向上是相同的,如“和”“同”等,而转折连词是相反的,如“虽然”“但是”等。
在基于情感词典的情感计算过程中,情感词典的质量决定了其计算效果,为了提高词典质量,学者们还构建了表情词词典、语气词词典、特殊标识符词典、停用词词典等粒度更细的辅助词典,以进一步提高情感计算准确率。
1.1.1.2 旅游情感词典
基础情感词典具有普适性,但不包含旅游的专业词汇,无法准确获取游客“非惯常环境下”的情感,因此,构建旅游专属情感词典是游客情感研究的一项重要基础工作。于静[46]较早就开展了旅游专属词典构建的研究,她从所收集的微博大数据中,经分词和词频统计共得到92 230 个词,通过人工判断方法筛选出带有情感色彩的词汇,共得到情感词、程度副词和否定词2 661 个,并将其分别划归到情感词词典、语气词词典、程度副词词典、否定词词典和特殊符号词典5个词典中。刘逸等[22,34]以HowNet 为基础词库,采用人工阅读筛选方式,从获得的大量游记、评论数据中,通过人工方式提取游客情感高频词,共包含317 个正面词汇和185 个负面词汇,之后对HowNet 进行修正,构建了旅游专属词典。毛超群[39]从“马蜂窝”“穷游网”等目前国内较知名的在线旅游社交网站中人工挑选当前使用较频繁的网络情感词,构成网络情感词典,并与HowNet 和《情感词汇本体》合并,构成旅游专属词典。
1.1.2 情感计算规则
基于情感词典的情感计算,核心是情感权重及情感计算规则,情感权重可由赋值得到,如积极情感词语赋予权重1,消极情感词语赋予权重-1,程度副词赋予权重2 或者-2 等;情感计算规则根据程度副词、否定词、连词、表情词、语气词等所在位置进行设计,如图2 所示。
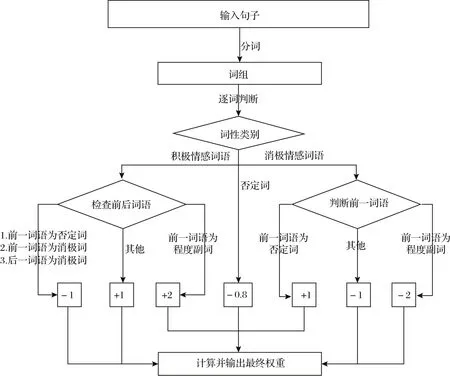
图2 情感计算规则举例Fig.2 Examples of emotional computing rule
图2 中,假设积极情感词语与消极情感词语的权重相等,实际操作中不同词语的情感权重赋值由人工逐个确定;另外,否定词由情感计算结果与人工情感判定结果的差异决定,当取值为-0.8 时,基于情感词典的旅游文本情感计算结果与人工判定结果之间的相对差异最小。在分词后,如果是情感词典中的积极情感词语或消极情感词语,则权重相加;如果是否定词则赋予负值,若为程度副词则情感值翻倍。最后由权重和计算规则计算句子的情感值,以总情感值的正负来判断句子是积极情感还是消极情感。在设计情感计算规则时,如果所有的积极情感词语和消极情感词语在权重上相等,会导致分类结果不精确,例如“恨”要比“讨厌”在情感上更为负向;同样,对于否定词和程度副词的权重处理,如果只是一个简单的反转或加倍,也会影响计算的精确性,比如“非常喜欢”显然比“挺喜欢”程度更深。修正方法是区别对待每个词语,赋予不同的值。为此,在构建情感词典初期,需要根据经验对词典中每个词人工设置权值,然后按照计算规则,通过情感词典中匹配的权重计算情感值。
1.2 基于机器学习的游客情感计算范式
基于机器学习开展的游客情感计算多采用监督学习的方法,意味着需要人工为文本数据标注“积极”和“消极”的分类标签以构建训练数据集,通过人工提取某些特征值,计算机可根据训练集学习模型输出结果(见图3)。
1.2.1 文本向量化
用计算机处理文本,须将文本数据转化为计算机能理解的语言。文本向量化就是将文本表示成一系列计算机可以识别且可以表达文本语义的数值向量,有词向量和句向量2 种。目前大部分对文本向量化的研究都是通过词向量实现的。词袋(bag of words)模型是最早以词为最小处理单元的文本向量化方法,产生的向量与词出现的顺序无关,与频率有关。词袋模型不包含任何语义信息,只是将词语符号化,该方法简单易行,但存在维度灾难、语义鸿沟和无法保留词序信息的问题。如“我喜欢这个地方”和“我讨厌这个地方”,两句话的特征词为“我、喜欢、讨厌、这个、地方”,文本向量如表1 所示。
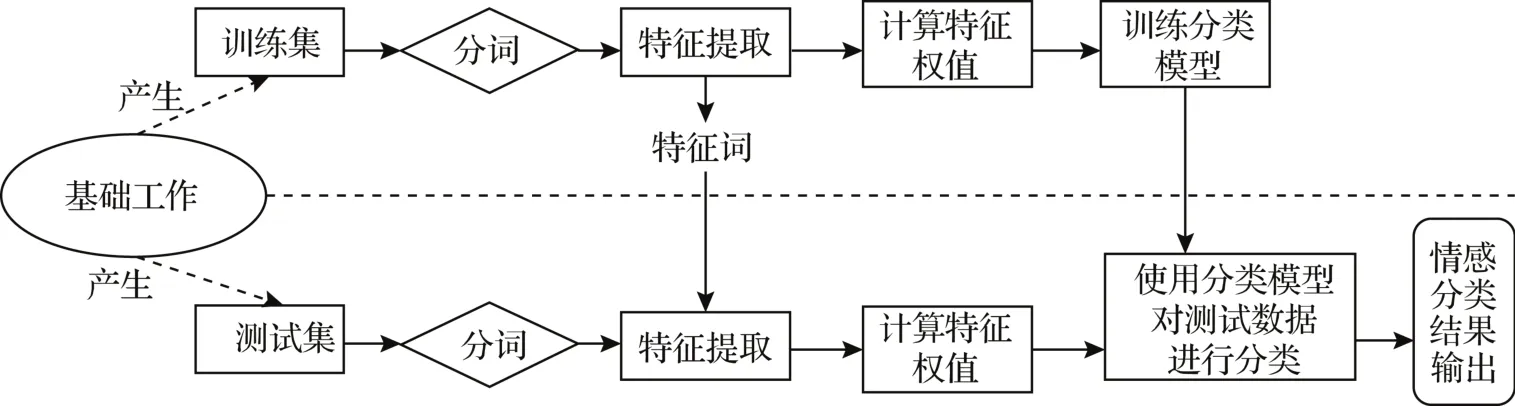
图3 基于机器学习的游客情感计算过程Fig.3 Tourist emotion classification process based on machine learning
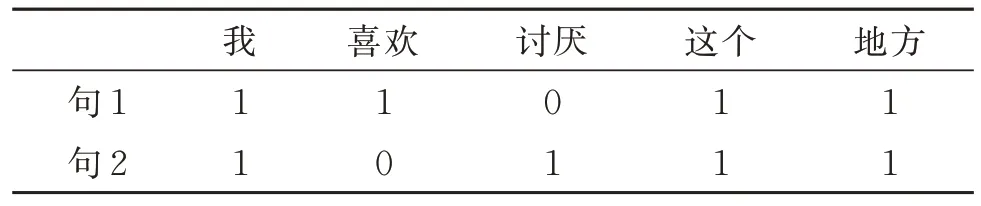
表1 文本向量化举例Table 1 Examples of text vectorization
1.2.2 特征提取与选择
文本由篇、段、句、词、字构成,词语作为中文文本中最小的语义单元,可以被定义为文本向量化中的特征,这些特征组合起来就表达了句子语义。对于中文文本来说,《新华字典》收录了52 万个词语,常用词语达5.6 万个,而在游客情感计算研究涉及的文本大数据中,所使用的旅游专业词语数量不少,因此,构造的特征向量往往会引起维度灾难并浪费存储空间。为避免文档向量维度过高引起向量矩阵稀疏问题,不能简单地将文档中所有的词语都作为特征,而应该在文本向量化的同时提取特征,进行有效特征选择。
以文本分词为例经词袋模型向量化后,得到一个数量庞大的词袋,词袋中有多少个词,此向量就有多大维度,然后把这些向量交与计算机计算(不需要文本),向量中的数字表示每个词的权重,代表这个词对文本的影响程度。其中需要解决如何计算权重、如何将词袋缩小、如何降低向量维度问题,特征提取与选择就是为了解决此3 个问题。需要说明的是,去停用词一定程度上也是给特征向量降维。
目前机器学习常用的特征提取与选择算法有:词频-逆文本频率指数(term frequency-inverse document frequency,TF-IDF)、信息增益(kullbackleibler divergence,KLIC) 、互 信 息 (mutual information,MI)、卡方检验(Chi-square test)。TFIDF 是一种常用的加权统计模型,用于评估单词对文件集或语料库中的某个文件的重要程度。在具体应用中,以 python 的 scikit-learn 为例,TF-IDF 权重计算方法主要有2类 :CountVectorizer 和TfidfTransformer,CountVectorizer 会将文本中的词语转换为词频矩阵,TfidfTransformer 用于统计vectorizer 中每个词语的 TF-IDF 值。
1.2.3 模型选择和模型训练
模型选择和模型训练是根据输入集建立并选择合适分类算法的系统过程。机器学习的算法选择一般有2 种:(1)对所有的算法进行研究测试,形成适用于旅游文本大数据和游客情感计算特定情境的分类模型,过程比较长,而且需要花费大量时间和人力;(2)查阅编程语言的说明文档,以前人研究成果为基础,从中寻找合适的分类模型,并经实际测试不断优化,最终形成适合旅游文本大数据和特定情境的旅客情感计算模型,其过程较长,人力投入也较大。以python 语言为例,以工具包scikit-learn 算法选择路径图,将机器学习算法分为分类(classification)、聚类(clustering) 、 降 维(dimensionality reduction)、回 归(regression)四大类。
模型选择是机器学习过程中一个重要步骤,但由于模型的参数未知,要想得到最佳参数,使模型可以准确地描述自变量和因变量的变化情况,就需要用已标注情感类型的数据集对模型进行训练和度量。已标注情感类型的数据集一般分为训练集、验证集和测试集。如果有一个大的标注数据集,那么可通过随机抽样获得这3 种数据集,在只有1 万条或者更少数据的情况下,三者的比例一般为8∶1∶1,当数据量为100 万条及以上时,三者的比例一般为98∶1∶1。确定模型后,用训练集训练模型的普通参数,训练完成后,用验证集验证模型,最后用测试集测试模型的准确率,完成模型的训练过程,在此过程中不断优化参数,得到最优参数分类模型。在具体应用中,因对数据集进行人工情感标记工作量较大,在特定领域,当已标注的数据集数据不充分时,一般可将数据集拆分为训练集和测试集两种,在训练集上训练和拟合模型,在测试集上评估模型效果。
基于机器学习的游客情感计算,其核心工作是文本数据的向量化、特征选择、降维及分类模型选择。每一步都有多种选择,不同方法的组合会产生不同的情感计算模型,通过对文本向量化特征及模型选择的优化,不断提高情感计算的准确率,经多次优化形成更优模型。该方法与基于情感词典的游客计算方法相类似。
1.3 基于深度学习的游客情感计算
深度学习在大数据TB 级别上性能卓越,并被广泛应用于认知模型。基于深度学习进行游客情感计算,即使用不同的人工神经网络模型,将文本大数据映射到向量空间得到词语的数值表示,再将用数值表示的这些词语输入深度学习模型,通过对模型的训练和参数优化获得最优模型。其过程与基于机器学习的情感计算大致相同,只是在文本向量化时对文本的特征提取和分类模型的选择与机器学习不同。
1.3.1 文本表示及特征选择(词向量表示)
人工神经网络只能接受数值输入,不能将一个单词作为字符串输入,为了使深度学习模型能够处理文本数据,首先需将自然语言表示为模型能识别的数值向量。自然语言文本已从基于规则方法表示发展到基于统计方法的演变,基于统计方法表示得到的模型称为统计语言模型。统计语言模型因其基于统计的思想,不考虑自然语言的时序特点,易出现维度灾难及词语相似性、模型泛化能力低、模型性能不高等问题。如何使“词表示”包含语义信息,且能更好地解决上述问题,就需要找到一种向量化单词的方式,这种“词向量”的每个维度均可对该单词的不同属性进行编码。word2vec 基于简单化的浅层人工神经网络,根据给定的大量语料库,通过训练和优化模型得到训练结果——词向量,此词向量可以快速有效地将一个词语表达成数值向量,并且能很好地度量词与词之间的相似性,从而表示该单词的不同属性。
Word2vec 实际上包含词袋(CBOW)和Skipgram 模型。CBOW 根据上下文预测当前词语,Skip-gram 根据当前词语预测上下文。这两种模型均以人工神经网络为算法,最初每个单词都是一个随机N维向量,经过训练获得每个单词的最优数值向量,即从训练语料的一大堆句子中选出不重复的单词进行建模,输出唯一的向量。word2vec 模型将数据集中的句子作为输入,并以一个固定窗口在句子中滑动,根据句子上下文预测固定窗口中词的输出概率,通过损失函数和优化方法对模型进行训练。word2vec 模型的输出被称为嵌入矩阵,此嵌入矩阵中包含训练集每个词的向量,且数据量很大。CBOW 较适合小规模语料,而Skip-Gram 在大型语料中表现更好。在具体应用中,用word2vec 模型对文本进行词向量化,一般通过TensorFlow、Keras、PyTorch、 Caffe、 Microsoft Cognitive Toolkit、Theano、Apache MXnet、DeepLearning4J 等 深 度学习框架实现。
1.3.2 深度学习模型构建
经word2vec 模型,得到人工神经网络的输入数据——数值向量。文本数据属于时间序列数据,每个词语的出现都依赖于其前一词语和后一词语,正是这种依赖的存在,大多情况下采用循环神经网络。
1.3.2.1 循环神经网络
循环神经网络(RNN)结构与一般神经网络结构不同,一般神经网络通常由输入层、隐藏层和输出层三部分组成,隐藏层可能有多个,而循环神经网络在三层结构的基础上增加了一个循环结构(见图4),图4 等号左侧为折叠式,等号右侧为展开式,xt为输入层,ht为输出层,A为隐藏层,其中每个A可以看作是一个神经元,每个神经元先存储之前输入的状态,再与当前输入相结合,运算后保留当前输入与之前输入的某些关系,从而具备“记忆”功能,可以捕获之前计算过的信息,保留前面输入的数据对后面数据的影响,具有很好的时序性。
1.3.2.2 长短期记忆网络
长短期记忆网络(LSTM)由RNN 演化而来,通过刻意设计计算隐藏层状态,避免了长期依赖的问题。RNN 和LSTM 均具有重复人工神经网络模块的链式结构,但在每个重复模块内部均存在4 个以特殊方式相互作用的神经网络层(见图5)。
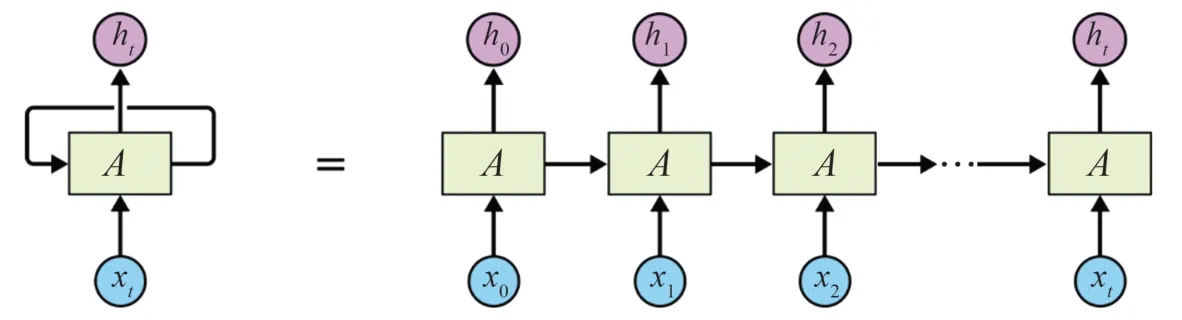
图4 循环神经网络结构Fig.4 Recurrent neural network structure
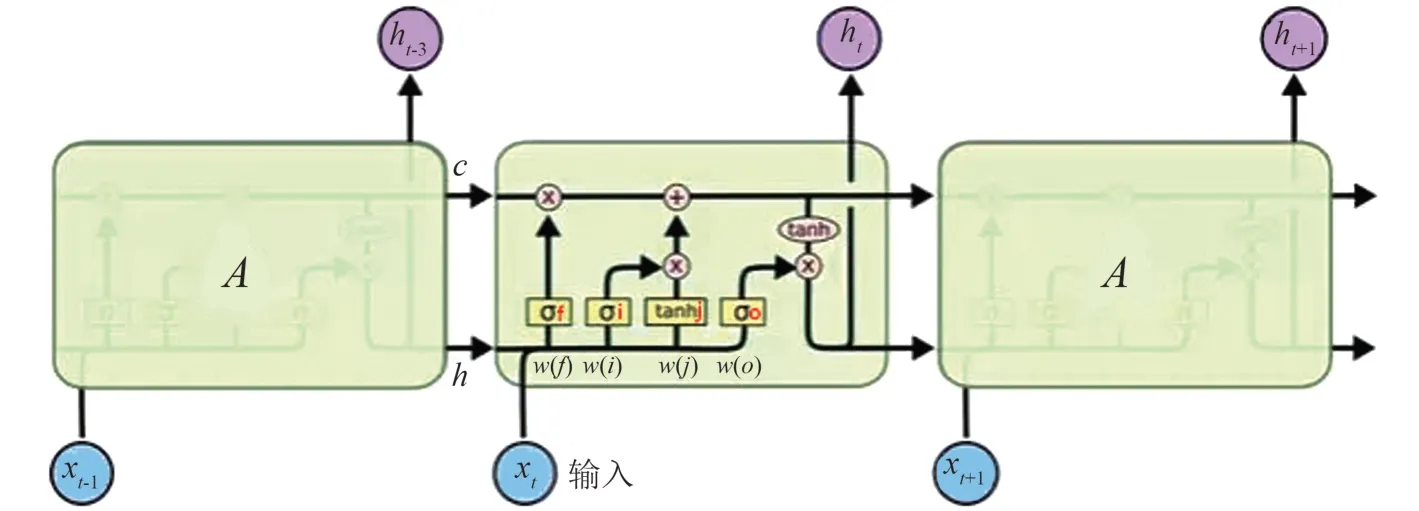
图5 LSTM 中的重复模块结构Fig.5 Repetitive module structure in LSTM
在LSTM 中,“记忆”被称为细胞状态,细胞状态在链式结构上像传送带一样运行,仅存在少量线性操作,如此使得信息在流经链式结构时可以保真。另外,为了捕获长期依赖关系,LSTM 通过被称为门(gate)的结构增添信息,门由单一sigmoid 神经网络层与单一点乘法运算构成,取值范围为0~1,根据数值来控制组件信息的通过与否。LSTM有3 个门,用于保护和控制细胞状态。第1 个门为“忘记门”,由sigmoid 层实现,将细胞状态中的信息选择性地遗忘;第2 个门为“输入门”,输入门的sigmoid 层确定更新哪些值,后续通过tanh 层创建的候选向量-Ct将新的信息有选择地记录到细胞状态中;第3 个门为“输出门”,其作用对象为隐藏层ht,通过sigmoid 层确定隐藏层的输出部分,后续将其通过 tanh 层,在(-1,1)内得到一个值,并将它与sigmoid 层的输出值相乘,确定需要输出的信息。在LSTM 网络中,通过3 个门选择记忆中的信息是保留还是删除,并将之前的状态、当前的记忆和输入进行组合,这种结构在捕获长期依赖上被证明是非常有效的。
1.3.2.3 门控循环单元
门控循环单元(GRU)是LSTM 的变种,可以很好地解决RNN 中的长依赖问题。LSTM 引入了3个门函数:输入门、忘记门和输出门来分别控制输入值、记忆值和输出值。GRU 中只有2 个门:重置门和更新门,重置门由新输入的信息和记忆构成;更新门实质上由LSTM 中的忘记门和输入门构成,较LSTM 结构更简单(见图6),图6 中,rt表示重置门,zt表示更新门。重置门rt控制前一状态有多少信息被写入当前的候选集h~t,重置门的值越小,前一状态的信息被忽略的就越多,写入的越少;更新门zt主要通过其自身的值来控制前置信息的通过量。
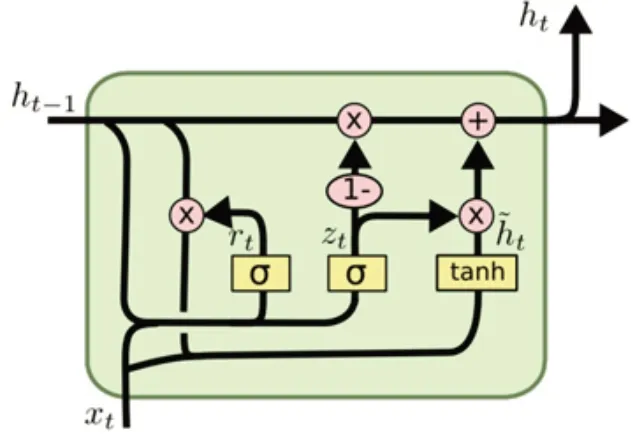
图6 GRU 内部结构Fig.6 Internal structure of GRU
LSTM 和GRU 均通过各种门函数将重要特征保留下来,从而保证在更长的传播中其特征不会丢失,有利于文本数据处理。此外,GRU 较LSTM 少了一个门,从而减少了几个矩阵乘法,参数数量也少于LSTM,当数据量很大时,GRU 的训练速度比LSTM 快,但分类效果还是取决于具体的应用场景。
1.3.2.4 基于word2vec 的RNN 深度学习情感计算模型
基于word2vec 将文本转化为分布式存储的词向量,然后通过RNN(LSTM 或GRU)深度学习,最后输出计算结果(见图7)。
具体步骤包括:(1)对旅游文本大数据进行基础性处理,得到原始输入语句;(2)采用word2vec 模型对原始输入语句进行词向量化处理,得到矩阵形式的词向量;(3)将矩阵形式的词向量xi输入RNN(LSTM 或 GRU)神经网络;(4)经 RNN(LSTM 或GRU)神经网络产生输出yi;(5)将yi连接至普通的全连接神经网络。最后,将全连接层的输出连接至softmax 层,输出正面情感或负面情感的概率y。
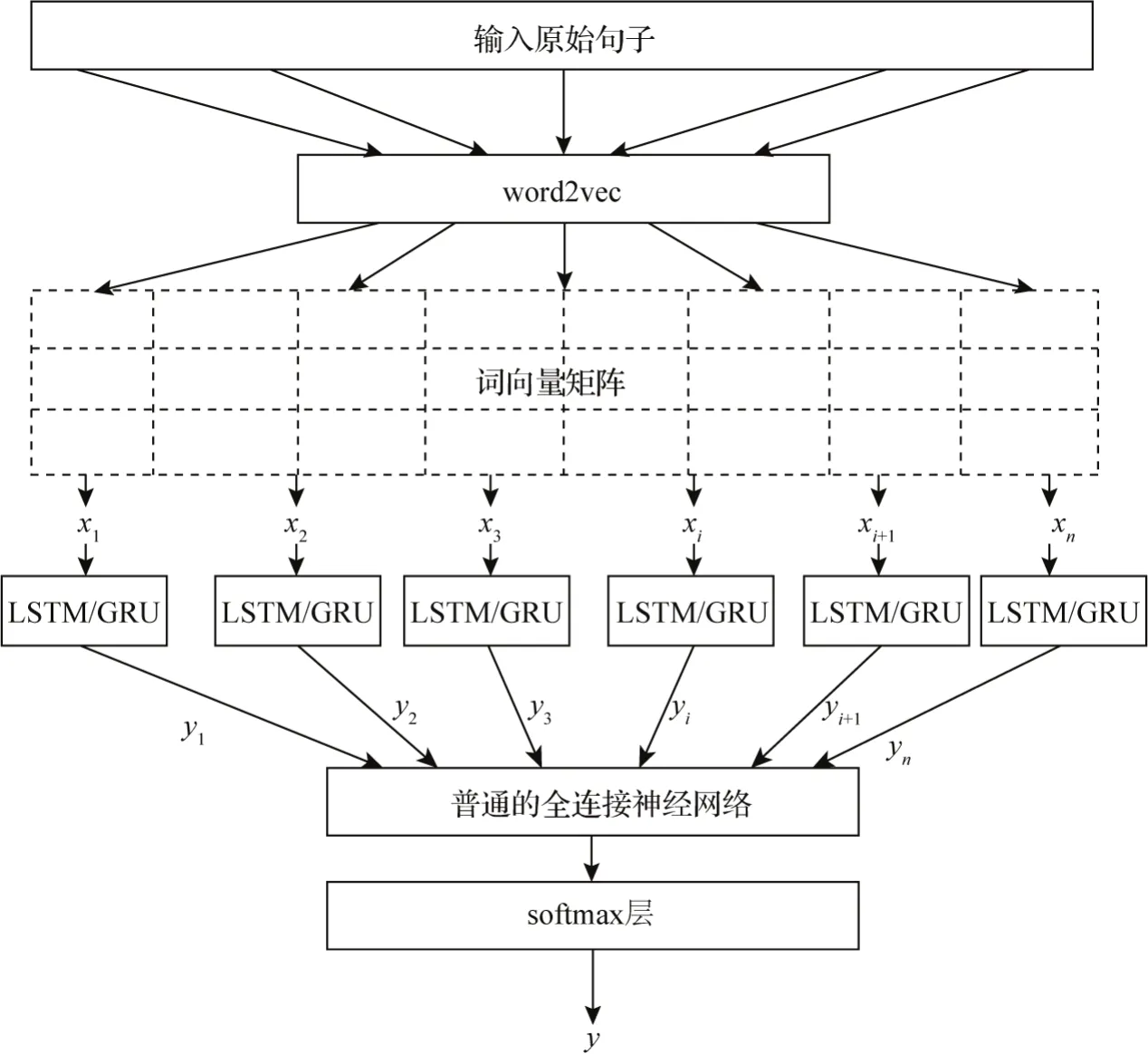
图7 基于word2vec 的RNN 深度学习情感计算模型Fig.7 Emotional classification model of RNN deep learning based on word2vec
2 模型检验与分析
2.1 模型评价方法和指标
根据情感计算实际与预测情况,可给出如表2所示的混淆矩阵,其中,1 代表正向类,0 代表负向类。TP 表示实际是正向,预测也是正向,分类正确;FP 表示实际是负向,预测是正向,分类错误;FN表示实际是正向,预测是负向,分类错误;TN 表示实际是负向,预测也是负向,分类正确。
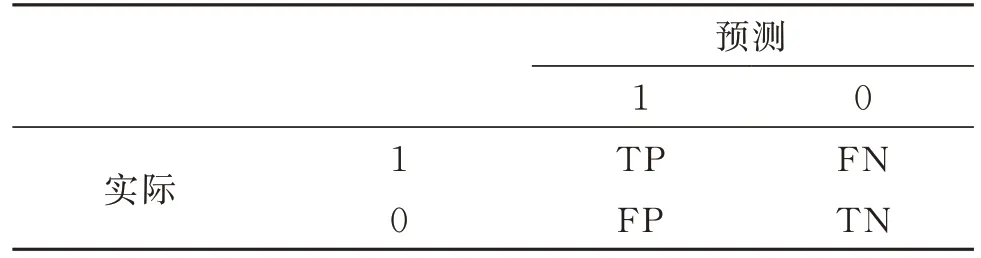
表2 混淆矩阵Table 2 Confusion matrix
基于混淆矩阵,情感计算一般采用准确率(accuracy,A),精确率(precision,P)、召回率(recall,R)和F1值4 种指标来评价计算效果。准确率A=(TP+TN)/(TP+FP+TN+FN),表示在所有样本中预测正确的样本数占总样本数的比例;精确率P=TP/(TP+FP),表示在预测为正向的数据中,预测的正确率;召回率R=TP/(TP+FN),表示在所有正向的数据中,预测的正确率。即准确率、精确率与召回率分别由不同的情感计算方法对文本大数据的情感计算效果来决定;为避免P和R两个指标相差过大,引入综合度量指标F,并将F作为分类的综合评价标准:

其中,∝为调节精确率(P)和召回率(R)两者之间关系的调节因子,通常取1。调整后的综合评价标准F1的计算公式为
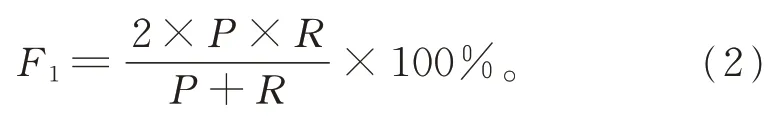
为检验基于word2vec 的RNN 深度学习游客情感计算模型的效果,选定能有效捕获序列数据长期依赖的LSTM 网络作为实验的深度学习模型,以谭松波标记过的酒店评论(见https://www.aitechclub.com/data-detail?data_id=29)作为语料,80% 做训练集,20%做测试集,在训练集上迭代20 次,训练过程中分别预测准确率和损失函数值,结果如图8 和图9 所示。
同时,设计实验对照组,使用谭松波标记过的酒店评论语料作为旅游文本大数据,其中正向情感样本5 322 个,负向情感样本2 444 个,共7 766 个样本构成数据集,按照准确率A、精确率P、召回率R、综合评价标准F1对不同游客情感计算方法进行评价。
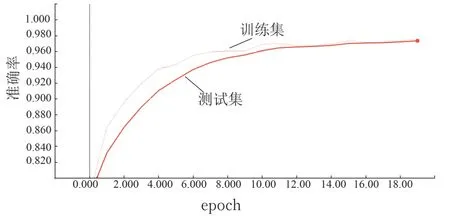
图8 准确率曲线Fig.8 Accuracy curve

图9 损失函数曲线Fig.9 Loss function curve
2.2 检验结果与分析
基于情感词典ER(emotion-rules)、机器学习SVM(support vector machines)、机器学习NBC(naive Bayesian classifier)和深度学习RNN(LSTM)的情感计算模型的检验结果如表3 所示。
由表3 可知,基于机器学习的游客情感计算方法比基于情感词典的游客情感计算方法更优,原因在于机器学习使用统计的方法抽取文本数据中的特征项,其非线性特征提高了情感计算的可靠性和准确率。
在机器学习方法中,NBC 在各项评价指标上的表现都较SVM 好,且在训练集与测试集上效果都比较稳定,原因在于NBC 作为机器学习中经典的分类模型,有着坚实的数学基础和稳定的分类效率。
深度学习方法LSTM 模型的准确率、召回率和F1值都较 ER、SVM 和 NBC 有较大提升,主要源于LSTM 模型对文本数据特征提取与学习方式上的智能化,深度学习依靠大数据与大量参数自动拟合非线性预测函数,强调模型结构的深度,突出特征学习的重要性,并通过逐层特征变换将原始空间中样本的特征表示转换为新的特征空间。与机器学习人工构造特征的方法相比,LSTM 模型充分体现了其大数据优势。
在基于word2vec 的RNN 深度学习游客情感计算模型中,word2vec 用高维向量将词语转换为实数向量并精确保留其语义信息,LSTM 模型不但发挥了深度学习对高维数据的强处理能力,还保留了旅游文本数据良好的时序性,同时结合其循环神经网络注重邻近位置的特点,有效地将高维向量重构并转化为低维的抽象语义信息,因此,word2vec 与LSTM 深度学习模型的结合取得了比基于情感词典和基于机器学习更好的计算效果。
深度学习作为机器学习的一种新模式,其优势在于强大的特征自学习能力和情感判别能力,非常适合旅游文本大数据多粒度、无标签和规模性、多样性的特点,有效解决了旅游大数据时代游客情感研究中情感计算数据量大、文本间的关系难度量、高度依赖人工构建情感词典、人工构建特征复杂及问题泛化能力受限等问题。
3 结论与讨论
3.1 结 论
综上,基于不同方法的游客情感计算的优势、不足和适用性如表4 所示。

表3 不同方法情感计算模型的检验结果Table 3 Test result of tourist emotion calculation model based on different methods

表4 基于不同方法的游客情感计算的优势、不足和适用性Table 4 The advantages,insufficients and applicability of different methods of tourist emotion calculation
3.1.1 基于情感词典的游客情感计算
该方法利用词语的情感极性、出现位置、句子语法等规则,通过情感词典对情感词加权计算得到情感计算结果,核心是情感词典和情感计算规则。其优点是简单、易实现,适用的语料范围广。但缺点也很突出,(1)自然语言千变万化的特点,在词典匹配中易产生较大误差;(2)性能高度依赖词典的质量,需要投入大量人力扩充高质量的情感词典,而当今呈指数型上涨的旅游文本更为词典的构建增加了难度;(3)情感词典和情感计算规则都需要设计,因此,精确与否在很大程度上取决于经验,推广能力较差。
3.1.2 基于机器学习的游客情感计算
该方法利用已标注情感类别的数据训练机器学习算法得到分类模型,而后通过模型计算文本的情感极性。基于机器学习的情感计算过程较易实现且计算量小,但易受训练数据规模和专业性及文本特征选择的影响,一定程度上限制了其在复杂问题上的泛化能力。运用统计学方式抽取文本中的特征项,通过机器学习方法建立计算模型,进而实现情感计算,有效解决了对情感词典的依赖,相对于基于情感词典的线性特征,其非线性特征极大地提高了情感计算的准确率。这种有监督的机器学习方法要求利用已知情感极性的数据作为训练集,但在现实中要获得大量已标注情感极性的数据难度很大,有时甚至无法获取;同时其对语料的依赖具有专业性;另外,这种方法将情感文本视为一个“词袋”,在忽略了数据集规模情况的同时,也忽略了上下文的信息,TF-IDF 具有高维度高稀疏性,缺乏语义,特征表达能力较弱,需要经过复杂的人工设计特征和提取特征过程,特征的选择和降维操作所需工作量巨大。
3.1.3 基于深度学习的游客情感计算
该方法解决了基于情感词典和基于机器学习无法考虑词序信息和语义特征的问题,提高了情感计算的准确率,为游客情感计算提供了新的思路。通过word2vec 用高维向量将词语转换为实数向量并精确保留其语义,使特征具有语义信息,且通过神经网络保留了其大部分词序信息。与传统机器学习的计算模型相比,深度学习的深度神经网络可以自动发现特征,不用人工设计和提取特征,大大减少了特征设计和提取的工作量。word2vec 在产生向量矩阵的同时降低了特征维度,加上深度学习模型可以通过GPU 加速训练,大大缩短了训练时间和实际使用时间;此外,由于深度学习不依赖专业领域词典和专业领域的特征提取,使得其进行情感计算的实用性更强,泛化能力更好。但深度学习采用深层神经网络,其模型较传统机器学习模型复杂,对数据集的要求高,大规模训练数据缺乏已经成为深度学习在情感计算中的瓶颈,同时,多层神经网络的结构、内部运行规则难以理解,对计算结果的解释性较差。
3.2 不足与展望
技术只是实现目标的一种手段,技术手段和方法要配合实际研究需求。在实际应用中,技术手段的使用不但要考虑准确性、误差率等情况,而且还应考虑其运行速度(时间复杂度)、资源消耗程度(空间复杂度)以及实施性和稳定性。
在开展相关工作时,突破技术范式的束缚,寻找合适的方法,探索最优的组合,从而形成最适模型。本研究在前人研究基础上,对游客情感研究中的情感计算进行了归纳,总结了常用的技术范式,并探索性地将新技术应用于游客情感计算研究,由于涉及的技术较多,研究尚欠深入,如基于机器学习和深度学习多种算法在游客情感计算上的深入比较等,今后可在以下几方面展开进一步研究:
· 多种方法的组合使用。游客的情感是在“非惯常状态”下的活动产生的情感,游客情感分析是在旅游这一特殊情境下进行的。下一步可以考虑构建旅游专属的情感词典,并将旅游专属的情感词典与机器学习、深度学习方法相结合来研究游客情感计算。
· 大数据的测试研究。数据量的大小决定情感模型的可信度,下一步可考虑在获取大规模旅游文本大数据的情况下,研究不同情感计算技术在时间复杂度、空间复杂度、实施性、稳定性上的优劣,为大数据时代游客情感计算研究奠定基础。
