集成学习框架下的个人信用评分模型研究
2020-08-16陈磊范宏
陈磊 范宏
[摘 要]在大数据时代背景下,建立适当的个人信用评分模型对用户违约风险进行有效预测,对于预防互联网金融风险极其重要。文章基于人工智能前沿技术,引入Bagging、Boosting以及Stacking集成学习框架来构建个人信用评分模型,并在融360平台近3.5万的用户贷款数据集上进行实证研究。首先,选用随机森林、GBDT以及XGBoost算法分别建立了单一信用评分模型;其次,将以上三种同质集成树算法作为Stacking异质集成框架第一层的基分类器,以Logistic regression为第二层的元分类器,进行模型融合。结果表明,Stacking异质集成模型在三种评估角度下均表现优异。
[关键词]信用评分模型;同质集成算法;异质集成算法;随机森林;GBDT;XGBoost
[DOI] 10.13939/j.cnki.zgsc.2020.20.164
1 引言
近年来,互联网金融在我国发展势头猛烈,但繁荣与风险往往相伴而生,那些隐藏的风险也不容小觑。特别地,针对信贷领域的个人违约风险,需要建立大数据时代下的高精度个人信用评分模型对用户个人信贷风险进行有效预测。针对单一算法的预测效果有限且泛化能力不佳,Stephen(2010)指出集成学习算法能有效降低偏差、方差,提升信用风险评估模型的准确度与稳定性[1]。当下比较流行的集成方法是基于不同训练集将若干个同一类型的弱分类器融合成一个强分类器的同质集成学习算法,主要分为Bagging和梯度提升Boosting这两大族。后来,周志华研究发现,Stacking异质集成学习框架更为强大,可通过某种策略将多个不同的分类器融合在一起[2]。
2 集成学习框架下的个人信用评分模型
2.1 算法机理
本文选用的基分类器是Bagging并行训练决策树得到的随机森林,Boosting串行训练决策树得到的GBDT以及改进GDBT后得到的XGBoost。Boosting集成技术主要以降低偏差为主,其集成的模型在拟合能力上更有优势;Bagging集成技术主要是降低方差,其集成的模型有更优秀的泛化能力。不同于Boosting和Bagging这两种采用相同的分类算法训练单个分类器的同质集成方式,Stacking属于一种异质集成方法,通过融合不同的基分类器,以修正其偏差的方式提高模型的泛化能力。从结构上看,Stacking集成框架是一种分层结构,将第1层的分类器称为基分类器,而第2层用于结合的分类器则称为元分类器。
2.2 数据及特征处理
本文的实验数据来源于融360网络金融服务公司,全部样本量有33465万,其中,30465条数据是有类别标签的被接受客户样本,这30465个接受样本中违约样本有1837个,履约样本有28628个,违约率为6.03%;有类别标签的被拒绝客户样本数据有3000条,这3000条拒绝样本中违约样本有361个,履约样本有2639个,违约率达到12.03%。本文的数据集中测试集的构成是1300个有类别标签的接受样本与3000个有类别标签的拒绝样本,即本文实证划分出的训练集是29165个有类别标签的接受样本,测试集是4300条有类别标签的接受/拒绝样本数据。
在特征工程阶段,首先,将每个样本包含的6745维特征用变量f1.f6745来进行特征转换。其次,选择皮尔森相关系数分析法结合未训练的XGBoost重要特征筛选法来做特征筛选,本文筛选出2000个特征作为建模输入。
2.3 超参数优化
分类模型训练的重点之一就是确定并优化超参数集。由于本文选用的基分类器都是树模型,因此确定需要优化的超参数有:单棵树的最大深度(max_depth)、树的学习率(learning rate)、树的数目(n_estimators)以及随机采样率(Subsample)。
实验采用grid search法来调节超参数,得到如下的最优超参数集为:Random forest 、GBDT、XGBoost的max_depth分别为5、6、10;learning rate分别为无、0.061、0.1;n_estimators分别为100、180、400;Subsample分别为无、0.998、0.904。
2.4 评价结果分析
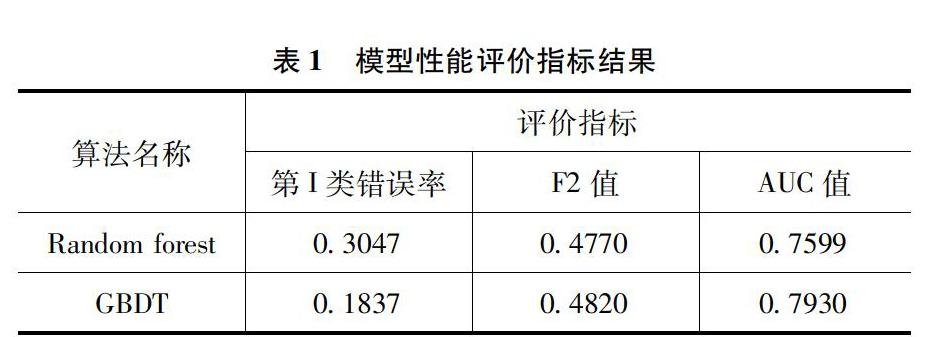
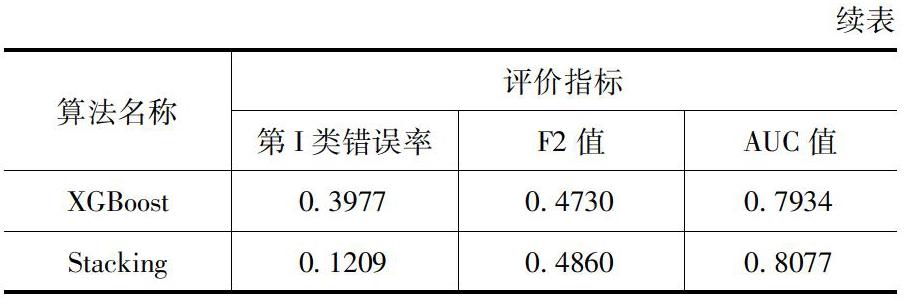
本文的评价标准主要是三个方面:一是误判经济成本的角度来评价模型的分类效果,选用的指标是第Ⅰ类错误率;二是模型在正类预测上的性能的角度,选用的指标是F2值;三是从模型整体预测能力和泛化能力的角度,选用的指标是AUC值。
由表1可以看出,Stacking异质集成模型的第I类错误率是0.1209,四个模型中最低,说明它的误判经济成本最低;F2值为0.4860,四个模型中是最高的,说明它在正类上的预测性能最優;AUC值达到了0.8077,也是最高的,说明经过异质集成后的模型的预测能力更高,泛化能力更强。
3 结论
本文建立了集成学习框架下的个人信用评分模型,并从误判经济成本、兼顾误判经济成本和模型在正类预测上的性能以及模型整体的预测能力和泛化能力三个角度对随机森林、GBDT、XGBoost这三种同质集成树模型以及Stacking异质集成学习模型的优劣进行了评估。实证表明,融合了三种同质集成树算法的Stacking异质集成学习模型表现出了强大的性能,在三种评估角度下均表现优异。不但经济误判成本最低,同时能较好地兼顾在正类上的预测性能(即能较好的识别出违约客户),还具备最优异的总体分类效果和泛化能力。
参考文献:
[1]DEFU ZHANG,XIYUE ZHOU,STEPHEN C H LEUNG,et al.Vertical bagging decision trees model for credit scoring[J]. Expert Systems with Applications, 2010(37): 7838.7843
[2]周志华.机器学习[M].北京:清华大学出版社,2016.
[作者简介] 陈磊(1995—),女,汉族,江苏南通人,东华大学旭日工商管理学院,硕士研究生,统计学专业,研究方向:金融信用风险研究;范宏(1971—),女,汉族,上海人,东华大学旭日工商管理学院,教授,日本东京大学博士,研究方向:金融网络风险分析。
