基于改进YOLOv3的合成孔径雷达图像中建筑物检测算法
2020-08-14李响苏娟杨龙
李响, 苏娟, 杨龙,3
(1.火箭军工程大学 核工程学院, 陕西 西安 710025; 2.96823部队,云南 昆明 650000;3.96873部队, 陕西 宝鸡 721000)
0 引言
建筑物是重要的人造目标,遥感图像中的建筑物检测在城市规划、灾情评估、军事侦察等方面具有重大意义[1]。在遥感图像处理领域,因合成孔径雷达(SAR)图像具有高分辨率、成像全天时、全天候的特性,SAR图像中的建筑物检测技术一直受到广泛关注和研究。
传统SAR图像中建筑物检测算法主要分为以下3种:1)基于先验知识的检测方法;2)基于模型的检测方法;3)基于机器学习的检测方法。其中基于机器学习的检测方法主要基于数据驱动,通过训练分类器自动建立目标模型,实现对目标的检测。Konstantinidis等[2]设计方向梯度直方图- 局部二值模式特征描述符,用于训练支持向量机(SVM)分类器,实现对建筑物的分类。刘静等[3]提出了马尔可夫随机场模型的高分辨率SAR图像建筑物轮廓提取方法。姜萍等[4]提出将基于像素的训练SVM条件随机场(SVM-CRF)模型扩展到面向对象的多尺度SVM-CRF模型,使之能同时有效地描述建筑物突出的“面状”特征及其层次、空间上下文相关性。上述方法提高了检测精度和检测效率,给建筑物检测带来了新的思路。缺点是模型提取的特征与分类器的设计有关,导致提取的特征深度受到限制。
利用卷积神经网络能够从数据中自动学习特征的深度学习算法,在计算机视觉领域得到广泛应用,基于深度学习的目标检测算法在可见光领域得到迅速发展。在SAR图像目标检测领域,深度学习同样被应用在坦克目标检测[5]、舰船目标检测[6]、飞机目标检测[7]、SAR图像道路分割[8]、大场景下建筑物检测[9]、SAR图像生成[10]等领域,深度学习通过卷积层的相互组合,自动提取、学习图像中的结构化特征,使检测精度大大提升,克服了传统检测算法提取特征不够深、检测模型鲁棒性差、检测时间长等缺点。
成熟的深度学习检测网络主要分为双阶段检测和单阶段检测。其中双阶段检测代表算法主要有区域卷积神经网络(R-CNN)[11]、Fast R-CNN[12]、Faster R-CNN[13]等,单阶段检测代表算法主要有YOLO[14]、单次多盒检测器(SSD)[15]、YOLOv2[16]、YOLOv3[17]等。其中YOLOv3是目前为止速度和精度最为均衡的目标检测网络,其在目标检测任务中性能表现尤为突出。
由于SAR数据获取成本高,遥感图像图幅面积大、解译所需的专业知识要求高等特点,目前已知公开的SAR图像目标检测数据集主要有运动和静止目标的获取与识别数据集、SAR舰船目标检测数据集[18]。在SAR图像建筑物检测领域,目前还没有公开的SAR建筑物数据集(SBD)。因此SBD的制作对于SAR图像中建筑物检测技术的研究和发展具有重要意义。
本文将YOLOv3算法应用到SAR图像建筑物检测中,针对SAR图像领域公开数据集匮乏问题,自行制作SBD;改进YOLOv3网络结构,以提高建筑物检测任务的精度。相比直接使用原始YOLOv3算法,平均检测精度得到提高。
1 SBD制作
1.1 数据来源
搜集各类SAR图像,通过人工查找、裁剪等方法,从大场景SAR图像中获取不同背景下、不同表现形式的建筑物数据,制作SBD. 数据集共包含1 000张图片,数据集图片像素大小为416×416、512×512;数据来源包含X波段,C波段等Terra SAR、高分3号卫星、美国桑迪亚国家实验室等机载、星载平台拍摄的经过几何校正的SAR图像;图像分辨率分别为0.5 m、1 m、1.25 m、5 m等;极化方式包括交叉极化(VH、HV)、同极化(HH、VV)。数据集中建筑物类型包括一般独立建筑、外形不规则特殊建筑、规则建筑群,图1所示为3种典型建筑物示例图。
1.2 数据集标注
利用标注软件LabelImg对获取到的含有建筑物的图像切片进行标注。LabelImg软件是基于Python语言编写的用于深度学习数据集制作的图片标注工具,主要用于记录目标的类别名称和位置信息,并将信息存储在可扩展标记语言(XML)格式文件中。
具体标注流程如下:首先对图像中的建筑物进行人工识别,确定其为建筑物目标;然后用垂直的最小外接矩形框将建筑物目标依次选中,同时设置类别标签为“building”。矩形框的标记信息(x,y,h,w)储存在标签XML文件中,其中(x,y)为矩形框的左上角坐标,h、w分别为矩形框高度和宽度。数据标注示例图如图2(b)所示,其中绿色矩形框为标注为建筑物目标,(x1,y1)为矩形框左上角坐标,(x2,y2)为矩形框右下角坐标。根据YOLOv3训练要求,将XML文件转化为以类别、目标坐标为内容的文本(TXT)格式文件,为下一步训练做准备。标注数据类型转换如图2(c)所示,其中左侧紫色文件为XML格式的标注信息,右侧TXT格式文件中第1个数值为类别对应的序号,后4个数值分别表示以图2(b)左上角为原点的标注矩形框的左上角和右下角横纵坐标。

图2 数据标注示意图Fig.2 Data labeling diagram
在数据集制作过程中,由于SAR图像数据有限,本文尽可能加入不同尺度、不同形状和表现形式的建筑物,改变同一图像的分辨率大小,并在训练预处理中对数据进行增广处理,即进行旋转、独立目标裁剪、颜色抖动、随机平移等操作,并修改相应的标签数据,最终数据集大小为1 438张图像。数据增强效果示意图如图3所示。数据增强的目的是增加训练样本的多样性,避免训练过程出现过拟合,提高网络泛化能力。

图3 数据增广示意图Fig.3 Schematic diagram of data augmentation
1.3 数据集分析
SBD一共含有1 438张图像,建筑物总数为13 457个。图4(a)所示为数据集中每张图像所含建筑物个数的统计直方图,图4(b)所示为每个目标像素占所在图像像素比例的统计直方图。目标平均像素大小为2 687.103 5,目标平均与原图的比例为0.013 2.

图4 数据集中目标信息统计直方图Fig.4 Statistical histogram of target information in dataset
由图4(a)可知,数据集中每张图像上的目标数量有较大变化,大部分图像中有1~10个目标,其他图像中有10个以上的目标,图像中目标数量较多,分布较密集。由图4(b)可知,建筑物目标像素大小存在多样性且在图像中占比很小,因此建筑物属于小目标,图像中存在较多背景信息。
李健伟等[18]分析了Faster R-CNN算法在可见光数据集目标检测中取得较好效果、在SAR图像舰船目标检测中性能不佳的原因,指出SAR图像中舰船目标在图像中像素占比小、预训练特征不适用于SAR图像等。同理,从SAR图像成像特性来看,相比于可见光图像中的建筑物,SAR图像中建筑物的成像形式不受建筑物本身外观颜色变化的影响,主要与建筑物与雷达波束的方向夹角和自身高度有关,成像模型具有规律性和稳定性。但相比于高分辨率可见光图像,SAR图像中建筑物的细节纹理信息不明显,一些非建筑金属物体在SAR图像中的表现形式类似于建筑物,从而容易导致检测结果存在虚警,且SAR图像中的斑点噪声也会对检测效果带来影响,因此需要准确识别建筑物,记录正确的标签信息,确保训练模型的有效性。
针对20类目标在图像分类、目标检测、图像分割等领域进行算法评估的VOC2007数据集含有9 963张图像,因此图像数量为1 438,目标类别仅有一类的SBD能够满足SAR图像建筑检测算法性能的检验。从SBD可知:在不同图像中建筑物数量变化较大,同一张图像中建筑物可能同时存在多种尺度和多种位置、朝向等分布情况;不同波段、不同极化方式下建筑物和背景噪声的表现形式有所不同;不同分辨率下,建筑物尺寸大小、细节纹理的表现形式也会有区别;相比于图像大小而言,建筑物属于小目标。结合图4的分析可知,针对建筑物目标的检测需要研究多尺度检测网络模型,保留细节信息,充分利用建筑物的空间信息等。
综上所述,SBD可应用于SAR图像建筑检测模型的研究,在构建检测模型时,需要从建筑物的细节信息、形状特性、多尺度特征出发。
2 SAR图像建筑物检测
2.1 YOLOv3算法的基本原理
YOLOv3算法是YOLOv1和YOLOv2算法的改进版本,同时吸收了其他检测网络的优势特征,是目前深度学习检测网络中检测效果最佳的单阶段检测网络之一。YOLOv3算法是基于Darknet框架实现的,Darknet是基于C语言与CUDA运算平台的开源深度学习框架,具有结构清晰、可移植性强、轻量化、不依靠依赖项的特点。
YOLOv3算法采用全卷积神经网络,在以残差结构为主体的Darknet-53骨架网络基础上,增加了跳过连接层和上采样层,共75个卷积层。在特征提取过程中,输入图像大小默认为416×416像素时,借鉴特征金字塔网络思想,在3个尺度大小(13×13、26×26 和 52×52)的特征图上,给每个尺度分配3个不同大小的预选框,然后基于图像的全局信息进行目标预测,从而实现端到端的检测。在下采样中YOLOv3算法使用步幅为2的卷积层对特征图进行卷积,减少池化步骤导致的小目标信息丢失。YOLOv3算法检测流程和Darknet-53网络结构如图5所示。图5中,a、b为图像大小,n为通道数。张量拼接模块的作用是将Darknet网络中间特征层与上采样后的特征图进行拼接,拼接后张量维度也随之叠加增大。
YOLOv3算法的损失函数由位置误差(中心坐标预测误差、边界框预测误差)、分类误差、置信度误差3部分组成,损失函数公式如下:
Loss=5×(exy+ewh)+1×ec+
1×eoc+0.5×enc,
(1)
式中:Loss为损失函数;位置误差分为exy和ewh,exy为目标中心相对于所在网格左上角的偏移量误差,ewh为锚点框的长度和宽度误差,位置误差权重为5;ec为分类误差,权重为1;置信度误差分为eoc和enc,分别表示目标置信度误差和非目标置信度误差,权重分别为1和0.5.
2.2 改进YOLOv3的检测算法
2.2.1 SAR-YOLOv3算法检测网络
建筑物在图像中的位置信息和轮廓信息丰富,这是建筑物的重要特征。深度卷积神经网络中,浅层卷积网络主要是提取图像的轮廓形状特征,深层卷积网络主要是提取语义信息。因此通过分析SAR图像中的建筑物特性、分布规律,提出适合SAR图像建筑物检测任务的SAR-YOLOv3检测算法,以下简称S-YOLOv3算法。S-YOLOv3算法网络结构和检测流程如图6所示,图中ResX为改进的残差模块,SFF为浅层特征融合模块。在YOLOv3算法的Darknet-53网络基础上,增加轮廓信息比重,即将浅层特征下采样后与原始3个尺度的特征图进行融合,再在新的特征图上预测;同时改进残差结构,增加通道信息的利用,扩展网络宽度,在不增加网络计算量的基础上提高检测精度。
2.2.2 结构改进
2.2.2.1 SFF模块
SAR图像中建筑物目标的轮廓、尺寸、灰度特性等浅层特征在目标检测中起到重要指导作用,相比于全局特征和语义特征,浅层特征在建筑物检测过程中应具有更大的权重。因此在兼顾计算量和特征信息保持性的同时,将原图像下采样4倍后大小为104×104像素的特征图从骨架网络中抽取出来,经过3次下采样后分别与原始3个尺度的特征层融合,再在新的多尺度特征图上进行检测。待融合的浅层特征图如图7所示,3个尺度(13×13、26×26 和 52×52)下的特征融合图如图8所示。
由图7(a)和图8(a)可以直观看出,通过卷积层进行特征提取得到的特征图与原始图像相比表现形式有较大的差异,难以解释和辨别。由图7(c)可以发现,浅层特征图中建筑物边缘轮廓和纹理信息比较明显,随着经过的卷积层层数增加,图像尺寸越来越小,多次卷积操作会导致原始图像中的细节信息逐渐丢失。如图8(a)52×52尺度所示,原始YOLOv3在52×52尺度特征图上建筑物轮廓信息不明显,仅剩下语义信息,但图8(b)52×52尺度增加浅层信息后特征图像中的建筑物轮廓纹理更加明显,对建筑物检测具有重要意义的轮廓纹理特征比重有所增加,使图像所含信息更加丰富。
2.2.2.2 ResX模块
YOLOv3算法中的Darknet-53骨架网络是借鉴残差网络(ResNet)[19]模型、以多个相同的残差单元堆叠构成的,通过增加网络深度可以获得更大感受野,减少超参数的设计。ResNet 的定义和模型结构如(2)式和图9所示,将模型的学习过程转化为对残差F(x)的拟合,通过学习使残差最小,最终使映射H(x)接近输入x.

图5 YOLOv3算法检测流程和Darknet-53网络结构Fig.5 Flow chart of YOLOv3 and Darknet-53 structure

图6 S-YOLOv3算法网络结构图Fig.6 Network structure of S-YOLOv3

图7 原始SAR图像和待融合的浅层特征图Fig.7 Original SAR image and shallow feature map to be fused
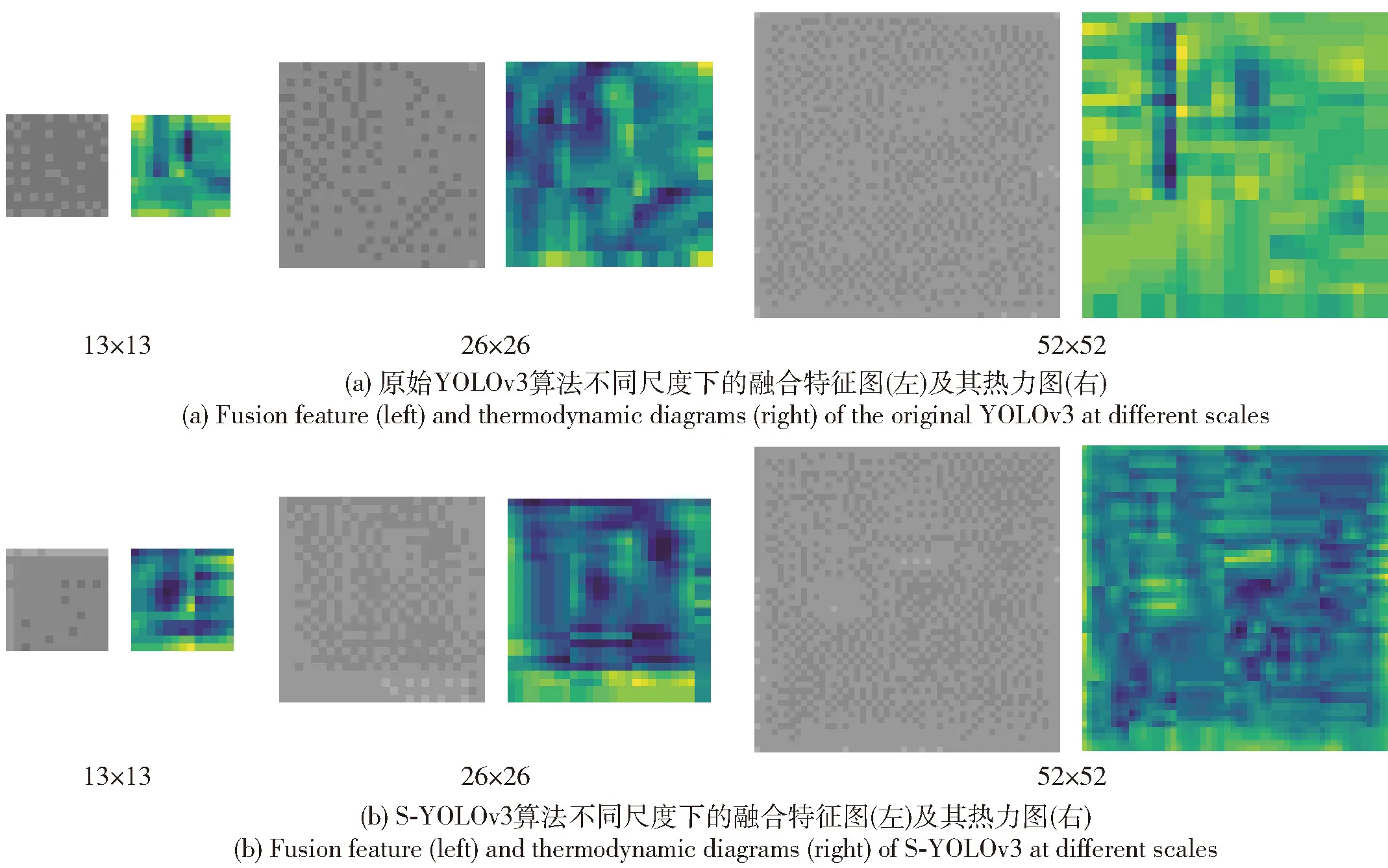
图8 不同尺度下的待检测融合特征图Fig.8 Fusion features to be detected at different scales
H(x)=F(x,{wi})+x,
(2)
式中:wi为投影系数,用以使残差和输入维度保持一致。
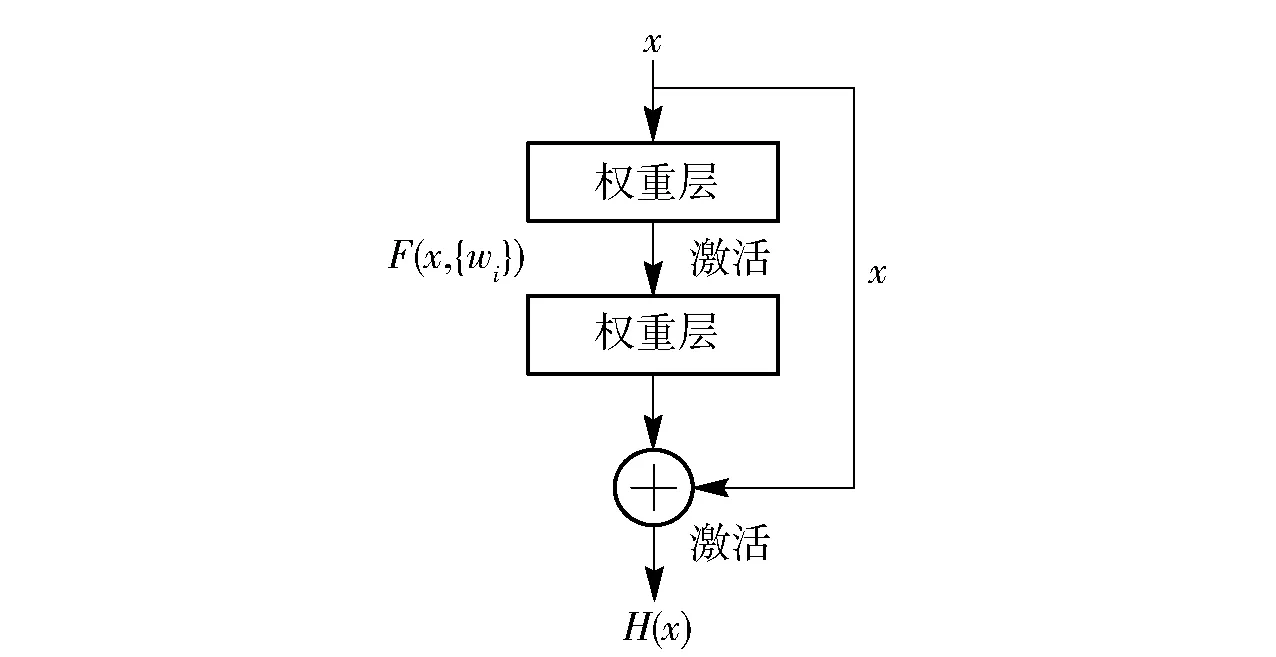
图9 ResNet模块结构示意图Fig.9 Network structure of ResNet module
相比于YOLOv2算法,YOLOv3算法引入了残差结构,增加了网络深度,取得较好的检测效果。但随着网络深度增加,运算量也会增加,且网络在增加深度的同时没有充分利用通道信息,因此再次加深网络并不是提高检测精度和检测效率的最佳选择。本文借鉴深度神经网络的聚合残差转换(ResNeXt)[20]思想,将改进后的残差模块引入YOLOv3算法中,扩展网络宽度,在不增加网络计算量的同时提高检测精度。
ResNeXt模型采用拓扑模块堆叠而成,是Inception[21]模块在ResNet结构上的应用。ResNeXt的定义和模型结构如(3)式和图10所示。
(3)
式中:C为分组卷积的组数;Ψi(x)为分组卷积中每一路卷积。

图10 ResNeXt模型结构示意图Fig.10 Network structure of ResNeXt model

图11 改进后骨架网络结构图Fig.11 Diagram of improved skeleton network structure
ResNeXt模型中,原始ResNet网络模型中的卷积被分解为以基数为单位的卷积组,然后将各通道信息进行合并,最后与卷积前的特征图相加。ResNeXt模型同时结合了ResNet网络超参数选择少和Inception网络资源利用率高等优点。
本文将Darknet-53网络结构中第33层~第36层、第58层~第61层、第71层~第74层之间的残差模块改进为多路ResX模块,即在原始残差结构中间增加多路卷积,得到ResX模块结构图如图11所示。
如图11所示,将3组原始残差模块中的单路卷积改为结构一致的多路卷积。ResX模块中第1层1×1卷积的目的是进行降维、降低计算量,3×3卷积层组的目的是提高特征图的感受野,最后1层1×1卷积目的是恢复特征图的维度以实现跨通道信息融合。改进后网络深度增加了3层卷积层,ResX模块计算量公式为
(4)
式中:amount为计算量。当C=4、n=256时,对一个ResX模块计算量amount和Res模块计算量amountRes进行比较:
amount=256×1×64+4×(64×3×3×64)+
64×1×256=180 224,
amountRes=256×1×128+128×3×
3×256=327 680.
通过计算可以发现,改进后一个残差模块的计算量减少了45%,由此可知改进后的残差模块没有引入额外的计算量。
2.2.3 非结构改进
2.2.3.1 预设锚点框的选择
预设锚点框是通过K均值(K-means)聚类算法聚类得到的,聚类中心数设为9. 随机化初始位置,计算标注信息中每个标注框与聚类中心点的距离,将标注框分给距离最近的聚类中心,分配完成后重新计算聚类中心点,直至聚类中心不发生变化。而传统K-means算法是采用欧氏距离作为相似性度量,但在检测算法中,设置合理尺寸锚点框的目的,是使预测值和真实值取得更好的交并比。因此YOLOv3算法采用以交并比为距离度量的K-means算法得到,距离公式如下:
d(r,o)=1-IOU(r,o),
(5)
(6)
式中:d(r,o)为预测框r和聚类中心o之间的距离;IOU(·)为平均交并比函数;rpt为预测框;rgt为实际框。
原始YOLOv3算法中的9个预设锚点框是通过对上下文中通用对象(COCO)数据集聚类得到的,分为3组:((116,90)、(156,198)、(373,326));((30,61)、(62,45)、(59,119));((10,13)、(16,30)、(33,23)),分别对应3个尺度(13×13、26×26和52×52)特征图,进行目标边界框的预测。由于COCO数据集包含的目标类别丰富且目标尺寸差异较大,通过人工判读发现SAR图像中建筑物目标外形以长而窄的矩形为主,因此原始设定的预选框不适合用于本文单类建筑物数据集,同时在实验中发现训练过程中采用原始预选框会出现某一尺度上无法检测到目标的情况。本文通过K-means算法对SBD数据进行重新聚类,得到适合SAR建筑物数据的预设锚点框。通过10次聚类,求得平均聚类结果为:((65,53)、(83,31)、(118,86));((36,23)、(50,19)、(56,29));((20,11)、(30,14)、(35,43))。如图12所示,原始预设锚点框不能很好地适应SAR图像建筑物目标,而重新聚类后的锚点框比例大小能够符合SAR图像建筑物数据的形状特点。

图12 预设锚点框对建筑物目标的作用范围示例图Fig.12 Example diagram of the preset anchor frame on a building target
2.2.3.2 上采样改进

图13 转置卷积原理示意图Fig.13 Transposed convolution
由图5可知,YOLOv3算法将底层特征图进行上采样,然后与同等大小的浅层特征进行融合,最后在融合得到的3个尺度特征图上进行目标分类和位置回归。在原始YOLOv3算法中上采样层采用最近邻插值算法。最近邻插值算法主要求解步骤为:1)计算输出图像某一像素点在原始图像中所对应的坐标点位置;2)将对应坐标点的相邻4个像素点中距离最近的像素点灰度值作为插值大小。该方法简单、易行,但容易造成上采样后图像灰度不连续的情况。
因此本文用转置卷积[22]替代最近邻插值算法,将简单插值过程转变为学习过程,通过卷积运算进行像素插值,以减少灰度的细节特征丢失。首先对输入图像进行补0,然后将卷积核按设定的步长在图像上滑动,计算对应像素点所需的插值。转置卷积运算过程如图13所示。图13中,k为卷积核尺寸,p为补0的行列数。
转置卷积后图像尺寸大小计算公式为
Io=(Ii-1)×s+k-2×p,
(7)
式中:Ii和Io为输入图像和输出图像大小;s为卷积核的滑动步长。当s=2、k=4、p=1时,输出图像尺寸为原来尺寸的两倍。
3 实验结果与分析
3.1 实验设置
本文使用的硬件平台有:中央处理器Intel(R) Core(TM) i5-3210M @2.50 GHz×2,图形处理器NVIDIA GTX 1080Ti ×2,64 GB内存;使用的网络框架为Darknet;编程语言为C语言和Python语言;操作系统为Ubuntu 16.04;使用的数据集为本文制作的SBD.
在SBD上进行SAR建筑物检测模型的训练,并在验证集上进行检测。训练集和验证集按照7∶3的比例进行随机分配。预设训练参数为:动量0.9,权重衰减系数0.000 5,前1 000次迭代的学习率0.001,迭代到40 000次时学习衰减十分之一,最大迭代次数50 200,类别数1,预测层的前一层卷积核数18.
使用以对象为基准的评估指标进行效果评估,即平均准确率AP、召回率Recall、平均交并比IOU、检测速度FPS和准确率- 召回率(P-R)曲线,公式定义为
(8)
(9)
式中:TP被预测为“+”,实际为“+”;TN被预测为“-”,实际为“+”;FN被预测为“-”,实际为“-”;FP被预测为“+”,实际为“-”。
3.2 模型测试实验
为测试本文方法在SAR图像建筑物检测中的效果,设置实验1和实验2进行检测效果评估。其中实验1是预置条件和非网络结构改进(预训练权重、预设锚点框、上采样方式)对SAR图像建筑物检测结果的影响进行评估,以确定最优的初始条件并论证模型的非结构改进作用;实验2是在实验1取得最优检测结果的模型基础上,增加网络结构改进并与原始YOLOv3算法检测效果的比较。通过两个实验评估网络结构改进模块对SAR图像建筑物检测结果的影响,以此确定最优的检测模型。
选取检测精度最好的迭代次数对应的训练权重作为最终训练好的模型。不同实验方案对应的实验结果分别如表1、表2所示。表2中FPS表示每秒处理的图片数量。

表1 实验1结果

表2 实验2结果
由表1第1行和第3行数据、第2行和第4行数据对比可知,根据实际数据集对预设锚框进行重新设置,平均检测精度和召回率均得到显著提高,表明锚点框的设置对于检测精度具有促进作用。由第2行和第5行数据、第4行和第6行数据对比可以看出,采用转置卷积进行上采样,对于检测效果有0.5%~0.8%左右的略微提高。
通过比较实验1前4行数据可以发现,预训练权重的使用与否,对于SAR图像建筑物检测效果影响没有较大影响。主要原因是官方提供的预训练模型是通过可见光数据集在Darknet-53骨架网络训练得出的,而SAR图像与可见光图像在成像机理、图像表现形式上有较大差异,且本文对骨架网络进行了改进,因此在实验2中没有使用预训练权重。
由表2可知,相比原始YOLOv3算法,增加了ResX模块和SFF模块的YOLOv3算法在保持较快检测速度的同时提高了检测精度。残差结构ResX中卷积组数的增加有利于提升模型性能,同时保持网络结构的灵活性。浅层特征融合SFF模块对于检测精度的提升效果显著。表明两个模块相结合的S-YOLOv3算法平均检测精度提高了9.2%,召回率提高了6.3%.
由实验2结果可以看出:改进后的YOLOv3算法和原始YOLOv3算法检测速度相差不大,能够在1 s内实现40张以上数量的图像检测,保持较快的检测速度。
P-R曲线可以同时衡量模型的准确率和召回率,曲线与坐标轴的面积越大,模型表现越佳。不同网络结构的YOLOv3的P-R曲线如图14所示。
由图14(a)可以发现,YOLOv3-ResX(C=2)、YOLOv3-ResX(C=4)和YOLOv3-SFF算法的P-R曲线比原始YOLOv3算法下降趋势更慢,在保持较高召回率的同时能够保持较高检测精度,表明ResX模块和SFF模块对检测效果的提升有促进作用,其中SFF模块对检测效果的提升作用大于ResX模块。图14(b)为结合ResX(C=4)和SFF两个模块的S-YOLOv3算法和原始YOLOv3算法的P-R曲线。由图14(b)可以看出,S-YOLOv3算法的P-R曲线比原始YOLOv3算法的P-R曲线位置更高、下降幅度更慢,曲线与坐标轴的面积更大,表明S-YOLOv3算法比原始YOLOv3算法在SAR图像建筑物检测任务上表现更佳。

图14 不同算法间的P-R曲线比较图Fig.14 Comparison of P-R curves of different algorithms
3.3 模型性能评估实验
通过对SBD进行学习、训练得到检测模型,对模型性能进行评估,得到建筑物检测结果如表3所示:其中第1行为4种典型场景下待检测建筑物的地面分布情况,图中的矩形框为数据集标注框,本文对于数据集中的建筑物统一采用垂直的外接矩形框进行标注,且标注过程中将间距过小、过于密集的建筑物视为整体,检测结果的表现形式与标注情况一致;第2行图像为原始YOLOv3算法的检测结果;第3行图像为S-YOLOv3算法针对同一数据的检测结果。
根据SBD的统计特性可知,建筑物分布存在多样性,目标大小存在多尺度特性,目标成像表现形式也不同。表3的结果表明:检测结果与基准标注图表现形式一致,原始YOLOv3算法和S-YOLOv3算法对SBD中分布规则且具有明显建筑物成像特征的数据具有较好检测效果;原始YOLOv3算法对SAR图像中背景复杂、建筑物成像特征不明显和大场景下建筑物目标占图幅比例小的数据漏检率较高,而S-YOLOv3算法能够克服以上缺点、降低漏检率。由此表明改进后的YOLOv3算法能够更好地适应SBD数据集的数据特性。
4 结论
本文对SAR图像中建筑物自动检测算法进行了研究,通过分析SAR图像数据集,针对SBD中目标的特点对YOLOv3检测算法进行了改进,并使用改进YOLOv3算法对建筑物进行检测。得到以下主要结论:
1)相比原始YOLOv3算法,改进YOLOv3检测算法的平均检测精度提高了9.2%,召回率提高了6.3%.
2)ResX模块和SFF模块能够在扩展网络宽度、提高信息利用率的同时,保持较快检测速度,促进检测模型性能的提升。
3)改进YOLOv3算法能够更好地适应SBD的数据特性。

表3 建筑物检测结果对比
总之,通过将在可见光数据集的目标检测任务中取得较好效果的YOLOv3检测算法成功应用到SAR图像建筑物检测领域,表明深度学习算法在SAR图像建筑物检测中的可行性,对后续SAR图像中建筑物检测算法的深入研究具有一定指导意义。
