基于最小二乘生成对抗网络的人脸图像修复研究
2020-08-14谢卓然寸怡鹏姜德航
谢卓然 寸怡鹏 姜德航 王 菲
0 引言
随着计算机硬件的飞速发展,深度学习的出现使得计算机视觉课题中的许多难题迎刃而解。但即便在这种情形下,要想让计算机学习并拥有修复一张图片中的缺失部分的能力依然是一件很有挑战性的事。而本文讨论的图像修复方法正是结合深度学习中的生成对抗网络(Generative Adversarial Network,后称GAN),并以最小二乘作为GAN 损失函数的一种图像修复方法。我们称这种网络结构为:最小二乘生成对抗网络(LeatSquare GenerativeAdversarial Network,后称 LSGAN)。
1 现存图像修复方法及问题
1.1 Criminisi 修复
Criminis 算法[1]的本质是将图像本身的纹理“复制粘贴”到破损区进行修复。

图 1 Criminisi 修复算法原理
如图1 所示为Criminis 算法修复残缺图片的过程:Ω是图像中待修补的部分,则可以用∂Ω 表示其边界;Φ 为图像剩余区域;算法在边界先选一以p 点为中心的区域Ψp 作为当前修复目标 ,再到已知的Φ 中搜索一与其纹理最为相似的Ψq,如图1(b)所示。最后复制粘贴到破损部分进行修复形成图1(c)的结果,以此类推。
1.2 数据驱动修复
数据驱动修复图像[2]的方法不将图像修补的素材局限在破损图像本身,而是利用互联网上丰富的图片来解决Criminisi 算法中,不能在剩余图像中找到与待修复区相匹配的纹理的问题。
该方法首先从互联网中挑选数百个与待修复图像最为相似的图片,并用Oliva A 等人[3]计算图像匹配特征向量。接着根据上下文的匹配误差,选择最佳的补全位置。最后返回20 个最佳补全结果供用户挑选。
这种方法抛弃了Criminisi 算法中修补材料只能来源于破损图片的局限性,为如何修复图像提出了新思路。
1.3 Context-Encoder 修复图像
继数据驱动修复之后,Pathak D 等人[4]在2017 年CVPR(IEEE Conference on Computer Vision and Pattern Recognition,IEEE 国际计算机视觉与模式识别会议)上提出,利用卷积神经网络来学习图像中的高级特征,再用这些特征来指导图像破损区域的重新生成。其网络结构如图2 所示。

图2 Pathak.D 等人提出的用修补图像网络
Context-Encoder(后称 CE)将 Encoder-Decoder 网络和GAN(生成式对抗网络)相结合:两个网络各司其职:Encoder-Decoder 负责实现同时学习图像特征以及生成修补素材的两大功能,而GAN 部分则用来判断修复结果的真实性。当Encoder-Decoder 生成的素材与破损图像无缝衔接,且GAN 也判断不出图像是否为人工合成时,认为该方法达到最佳效果。
与数据驱动法相比,这种方法不需要连接图片库,当网络训练好以后,它可以省去大量用于图片搜索的时间。
1.4 现存修复方法中存在的问题
Criminisi 的算法只能很好的修复含大量重复性纹理的图像,算法效率较低,且对其他大部分图片都不适用。
数据驱动算法允许引入更多的外部内容对图像进行修复,但在修复过程中使用的特征仍然是较低级的特征,在测试场景与数据库映像有显著差异时很容易失败。
CE 算法利用深度卷积神经网络,克服了前两种算法中存在的问题。但由于其训练网络时,直接将含有固定破损形状的图像作为神经网络的输入,导致其只能很好的修复某特定类型的破损图片。当图像破损部分与用来训练网络的图片的破损形状不一致时,修复出的结果就很难令人满意了。
相比之下,本文所使用的方法在这一方面具有显著优势:它与CE 同样用到了GAN 网络作为模型核心,但它在训练网络时不需要加入带掩码的图片,因此对于任意形状的破损区域,也能获得较好的修复结果。
2 本文方法
2.1 GAN 工作原理
生成式对抗网络的理念起初是在 Ian Goodfellow 等人的开创性论文“Generative Adversarial Nets”[5]中提出的。GAN 网络原理结构如图3 所示。其中,G 是图像生成网络,向他输入一单位随机向量z 以生成图片G(z)。D 是判别网络,用于判断图片来源的真实性。其输的图像x 可以来源于现实环境或生成器G 伪造而成,最终输出一结果D(x)表示图像来源为真实图像的概率。

图 3 GANs 结构模型
在训练过程中,D 和G 网络之间形成动态博弈。生成网络在一次次训练中逐渐增加伪造图像在判别网络处的得分。而判别网络则希望将生成网络合成的图片和真实的自然图像准确区分开。我们将上述过程循环执行足够多的次数,D(G(z))的值将趋近于50%,此时生成网络合成的图像已经足够自然,网络训练完成。
2.2 构造LSGAN 修复网络
文献[12-13]指出,原始GAN 训练过程很不稳定,这很大程度上是GAN 使用交叉熵函数(Sigmoid cross entropy)作为判别器损失函数导致的。这将导致那些仍然远离真实数据的、但又在决策边界被分类为真的假样本停止继续迭代,而这些样本的梯度是梯度下降的决定方向。于是当我们再用这些样本反过来更新生成器的时候,训练过程就变得不稳定了,容易发生梯度消失的现象,导致生成器生成的图片质量很差。
Mao Xudong 等人[8]提出,用最小二乘函数替换交叉熵做判别器损的失函数可以很好解决这个问题。因为使用最小二乘函数的LSGAN 会对处于判别成真的那些远离决策边界的样本进行惩罚,把远离决策边界的假样本拖进决策边界,有效避免梯度消失,从而提高生成图片的质量。
图4 展示了交叉熵和最小二乘损失函数的区别,可以看出GAN 采用的交叉熵函数右侧存在大片梯度为0 的饱和区域,当样本落入这个范围时,对生成器不再起到任何更新作用。反观最小二乘函数,只在1 个点发生饱和,这使LSGAN 的训练过程可以一直进行下去,生成比GAN 更清晰的结果。
设原GAN 的目标函数如下:
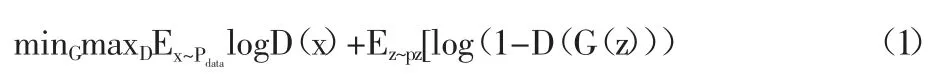
其中,x~pdata表示图像来源于真实数据,z~pz来表示图片是伪造生成。对生成器 G,希望 D(G(z))最大,或(1-D(G(z)))最小。而对于判别器D,则希望当数据来源于真实图像式 D(x)最大。
改进后的损失函数如下:

对上式 a,b,c 有:b-c=1 且 b-a=2。本文选取 a=0,b=1,c=1。
与CE 修复图像的方法不同,该网络并不是直接将破损的图片直接作为输入来修复,而是先用生成器生成一人脸图像,将其对应的破损区域剪裁下来并粘贴到破损图上,用泊松编辑[9]做边界融合,这使得本文的修复方法将不受到图像破损形状的约束,修复效果优于CE。
本文用到的LSGAN 图像修复网络结构如图5 所示。生成网络G 的输入是一个从[-1,1]之间的均匀分布绘制的随机100维矢量,经过数次微步幅卷积运算,最终生成64*64*3 的图像。鉴别模型D 与生成模型G 呈现镜像:输入层是尺寸为64*64*3的图像,随后是一系列卷积运算,最后经最小二乘函数输出一个0 到1 之间的单值作为概率。
此外,我们还在卷积神经网络的结构上做了一些调整,以提高样本的质量和收敛的速度,包括:
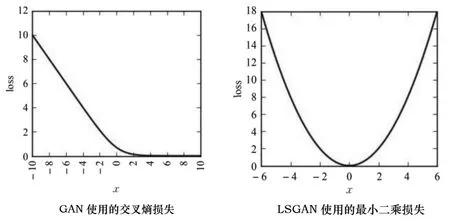
图4 交叉熵损失与最小二乘损失对比

图5 LSGAN 图像修复网络结构
(1)将所有池化层都改为带步长卷积运算。这能让网络学习到自己去学习一种采样方式。
(2)用全局平均池化(global average pooling)替换全连接层,这虽然会影响收敛速度但是能增加模型的稳定性。
(3)使用批归一化,使输入到每一个节点的数据的平均值都为0,方差都为1,从而稳定训练。这个方法能防止模型只输出相同的样本,又称为Helvetica Scenario 现象,而这个现象是GAN 在实际使用中遇到的最大的问题。
(4) 生成模型中除了输出层的激活函数使用tanh 以外,其余激活函数都用ReLU。这能够让模型在训练中更快地达到饱和并且能对彩色图片有更好的处理效果。
(5)用Adam 优化算法[7]代替梯度下降法。原始的随机梯度下降算法在更新参数的过程中学习率始终保持不变,当研究非稳态或非线性问题时性能差。而Adam 算法结合了AdaGrad 和RMSProp 算法最优的性能,能为不同的参数设计独立的自适应性学习率,调参过程简单,默认参数就可以处理绝大部分的问题。
2.3 设置损失函数
假定现在网络生成了一个G(z)'能与破损图像完美拼合。设图片待修复区域为y,并用一个与y 相同大小二进制掩码M来标注破损区域,破损区域的值均为0,其余部分为1,则我们可以用下列算式来表示修补后的图像。

为使G(z)'生成的图像与y 有高度相似性,我们定义两个损失函数Lc与Lp,其中,环境损失Lc表示破损图与生成器伪造图像素材的匹配程度,先验损失Lp表示生成人像的真实程度,有:

损失越小,G 生成的图像与残缺图像剩余的部分越相似,图像越真实。但在实验过程中,我们发现公式(5)的设定并不合理,因为它对破损图像中的所有像素均做等同处理。实际上我们应该使靠近破损区域的像素获得更高的权重。因此,添加参数W 衡量待修复人像中像素对环境损失的影响大小:
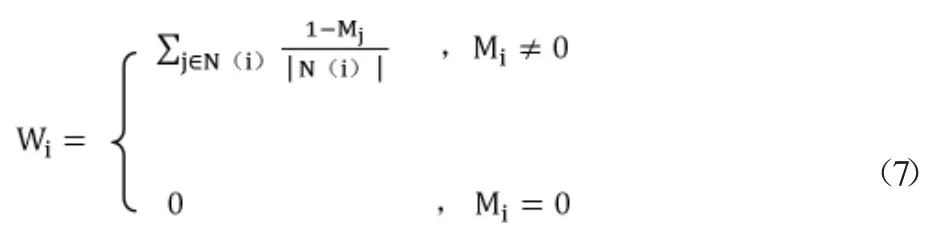
其中N(i)代表的是像素i 周围的一个邻组,它的绝对值则表示该邻组的像素基数。经试验发现,范数1 的效果比范数2更佳,因此我们重新定义环境损失为。

现在整个修复图像过程的损失函数L(z)可以表示。

其中λ 为超参数,当λ 值大于1,说明先验损失在图像修补过程中更受重视;当λ 的值小于1 时,则环境损失更受重视。本文选取λ=0.003。
2.4 准备工作
实验环境为基于Linux 内核的Ubuntu 14 操作系统,采用python3.5 下的Tensorflow 深度学习框架。我们把从CelebA(CelebFaces Attributes Dataset)上下载的202 599 张数据集放入一个单独命名好的文件夹中,表明这个数据集是未经加工的图片。利用OpenFace 的排列工具,将所有图像统一处理成64×64像素的大小。再将这些图片打包分为训练集、测试集和验证集。用这些素材训练LSGAN 生成人脸以及修复图像,运行50 个周期,每个周期2 000 次,监控图像修复过程中的参数变化,并将结果与现有的深度学习修复方法相比较,分析不同的网络的性能差异。
3 结果展示
3.1 修复过程
经过5 个周期后,修复效果如图6 所示。

图6 LSGAN 修复破损人脸图像的效果
其生成模型生成人脸的过程,以及对应损失值的变化分别如图7 和图8 所示。可以看出,在最初250 次损失下降最快,200 个周期以内损失值降为最初损失的一半(红色虚线标记)。1 个周期之后,损失就已经足够小了。
3.2 质量分析
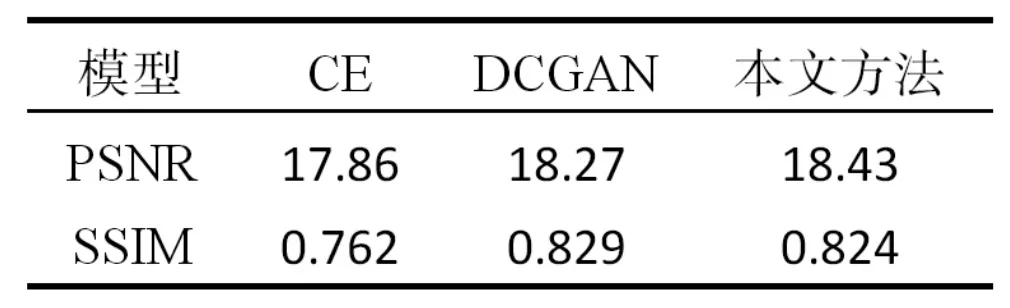
表1 质量评价表
将本文对中心区域破损图像的修复效果与同样运用了GAN 结构的DCGAN 和CE 方法相比,结果如图9 所示。表1 展示了每1 000 次修复结果中的平均峰值信噪比PSNR[10]和结构相似性SSIM[11]来定量评价各模型的修复效果。PSNR 是最普遍和使用最为广泛的一种图像客观评价指标,然而它是基于对应像素点间的误差,即基于误差敏感的图像质量评价。SSIM 可以分别从亮度、对比度、结构三方面度量图像相似性。这两种指标的数值越大,表示效果越好。
为保证结果客观,除中心区域破损的图像修复外,我们也展示了LSGAN 模型对一些特殊图像的修复,包括戴眼镜的人像,黑白人像,半张人脸图像,以及局部破损人像等,并在图10中展示了一些较理想的修复结果。可以看出在应对不同类型的修复任务时,本文方法也能提供让人满意的效果。
4 结论与展望
本文提出了一种基于最小二乘生成对抗网络的图像修补方法。与传统的基于纹理的修复方法相比,这种方法弥补了大面积缺失的图像的复原中找不到匹配纹理的问题;与数据驱动的方法相比,该方法不需要储存数据库,且运算速度快;与同样结合生成对抗网络的CE 算法和DCGAN 相比,由于采用最小二乘损失,这种方法的训练过程稳定,判别器分类更加严格,因此生成的图片质量更好。本文在训练生成网络时,无需连同遮挡图像的掩码一起训练,能够很好的解决任意破损区域的修复,这是CE 做不到的。从对中心区域破损的人脸修复实验的结果来看,本文方法具有更高的峰值信噪比和结构相似度,修复效果更自然。

图7 LSGAN 生成图像的过程

图8 损失值变化曲线(左右分别对应图6 女性人脸和男性人脸)

图9 不同模型修复效果比较

图10 图片类型或破损区域不同的图像修复结果
