基于表情和语气的情感词典用于弹幕情感分析
2020-08-12邱全磊崔宗敏
邱全磊,崔宗敏,喻 静
(九江学院 信息科学与技术学院,江西 九江 332005)
0 引 言
近年来,随着网络视频行业的快速发展,网络视频用户规模的不断扩大,弹幕评论越来越受到人们的欢迎。弹幕是一种新兴的,及时更新的互动评论系统,它以滚动字幕的方式直接显示在视频界面上,有助于加深观众对视频内容的理解,也可以促进观众之间的交流。随着弹幕功能在各大视频网站的流行,弹幕中的情感信息越来越具有普遍性和参考性,这些情感信息能准确地反映用户在观看视频的即时情感和褒贬评价。
目前,国内外对于弹幕的研究取得了一定的研究成果,但是主要是从传播角度出发,关注用户心理、传播结构和运营模式等[1-4]。由于弹幕本身的特点,比如文本内容较短,口语化现象突出,网络用语较多,用语不规范等,所以对弹幕进行精准的情感分析仍然存在很大的挑战。
现有的对弹幕进行情感分析的方法中[5-9],没有考虑颜文字表情对情感分析的影响,颜文字表情在文本预处理阶段经常会被过滤掉,同时也忽视了语气词在情感表达中的作用,语气词通常被认为是没有意义可以被省略的停用词,这影响了情感分析的准确率。
为了解决以上问题,构建了一种新的基于表情和语气的情感词典用于弹幕情感分析,即EMBA方法(emotional dictionary based on emoticons and modal for barrage sentiment analysis)。该方法针对弹幕中颜文字表情的大量使用情况,提高了情感分析的准确率,同时,考虑了语气词的作用,增强了弹幕情感分析的效果。实验结果表明,该方法比现有的方法在弹幕情感分析领域具有更好的性能。
1 构建情感词典
1.1 基础情感词典
文中采用BosonNLP情感词典作为基础情感词典,与传统的情感词典[10]相比,BosonNLP情感词典是从微博、新闻、论坛等数据来源的上百万篇情感标注数据当中自动构建的情感极性词典。因为标注包括微博数据,该词典囊括了很多网络用语及非正式简称,对非规范文本也有较高的覆盖率。BosonNLP情感词典收录了114 472个情感词汇,按照情感倾向和情感强度对情感词进行了赋权。其中,褒义情感词的权重为正,贬义情感词的权重为负,情感词的权重范围为[-7,7]。
1.2 弹幕表情词典
自从第一个表情符号“:-)”于1982年在Carnegie Mellon公告牌上创建以来,这些基于ASCII的表情符号已被广泛用于表达人类的情感[11]。颜文字表情能够生动形象地表情达意,在弹幕中深受人们的欢迎。文中使用的颜文字表情来自搜狗输入法颜文字表情词库,包括21个类别的802个表情符号。目前对于颜文字表情的研究主要以传播学为主[11-13],将颜文字表情应用于情感分析的研究很少,如何确定颜文字表情的权重是一个挑战。文中通过调查统计的形式让九名研究人员根据表情类别确定表情权重,最后取平均值得到表情类别对应的表情权重。最终得到了21类表情符号及其对应的情感值,表情词典格式如表1所示。

表1 表情词典
1.3 弹幕领域词典
由于网络文化与时俱进的发展和弹幕文本的特殊性,弹幕中仍会不断出现新的领域情感词汇,这些词汇都无法在现有的情感词典中找到。因此,文中使用SO-PMI算法[14]构建弹幕领域词典对基础情感词典进行扩展。首先确定基准词,然后获取情感词候选词,通过计算确定候选词的情感倾向,最后将候选词汇加入弹幕领域词典中。
SO-PMI是将PMI方法引入计算词语的情感倾向中,从而达到捕获情感词的目的。作为SO计算的一部分,Pointwise Mutual Information (PMI)对于根据正面和负面陈述计算短语之间的强度至关重要[15]。它的基本思想是计算同时出现在文本中两个单词的概率,概率越大,相关性越大,连接越接近。PMI计算公式如公式(1)所示。
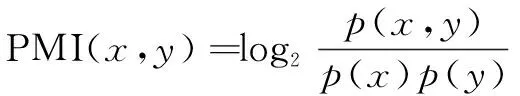
(1)
其中,p(x,y)表示两个词语word1与word2共同出现的概率,p(x)是word1单独出现的概率,p(y)是word2单独出现的概率。如果word1和word2之间存在真正的关系,则p(word1&word2)出现的概率将远大于p(word1)p(word2),log(word1word2)大于0。
使用SO-PMI计算未记录单词word1的情感值的公式如下:
(2)
其中,Pwords是一组褒义词,Nwords是一组贬义词,这些情感词倾向性非常明显,非常具有代表性。通过SO-PMI值与阈值0的比较,将未记录词word1分类成积极,中性或消极的情感词,比如word1的SO-PMI值大于0时, word1被识别为积极的情感词。
1.4 语气词典
语气词通常被认为是没有意义的词汇,被列入停用词当中被过滤掉,然而,因为弹幕口语化、极简化的特点,弹幕中存在许多完全由语气词组成的弹幕,如弹幕“哈哈”“嗷嗷”。如果把这些语气词当作停用词过滤掉,将影响弹幕的情感分析效果。
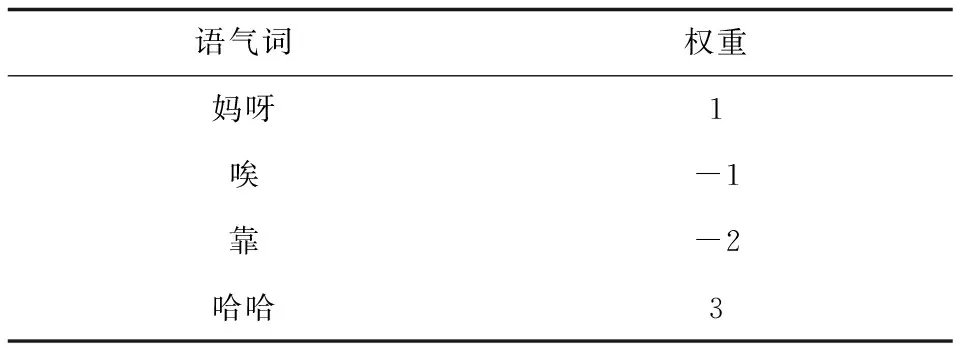
表2 语气词典
文中利用1.3中提到的SO-PMI算法构建弹幕语气词典。因为语气词的情感强度低于普通的情感词强度,所以设定语气词情感值范围为[-3,3]。利用SO-PMI算法,从弹幕文本中提取出语气词,根据语气词的SO-PMI值确定其情感值:当语气词的SO-PMI值处于0到5范围内,语气词情感值为1;当SO-PMI值大于15时,语气词情感值恒等于3,以此类推。将语气词及确定的情感值加入语气词典,最终的语气词典格式如表2所示。
1.5 程度词典
文中采用知网提供的程度级别词典,在实际对弹幕文本进行分析时,发现弹幕里存在网络流行词汇以及非正式的词汇当作程度副词使用的情况,如“灰常”表示程度副词“非常”,“敲”表示程度副词“超”,走召”表示程度副词“超”,将这些特殊的词汇整合添加进程度词典中,以提高情感分析的准确度,最终得到了由228个程度副词组成的程度词典。程度副词级别及权重如表3所示。
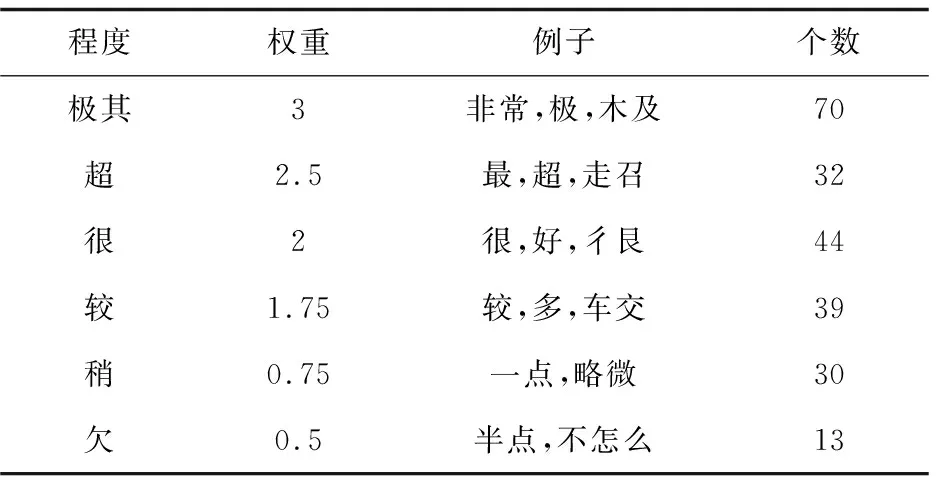
表3 程度词典
1.6 否定词典
当否定词修饰情感词时,情感倾向一般都会发生反转,文中整理了弹幕中常用的71个否定副词构成否定词典,否定词权重设为-1。
1.7 网络词典
随着互联网的快速发展,产生了很多网络词汇,这些词汇不同于传统的词语,它们更加精简以及口语化,部分网络词汇具有强烈的情感色彩,例如“赛高”,“笔芯”“打call”。文中从搜狗输入法的词库中整理筛选出最常用的网络情感新词并赋予其情感值,从而完成了网络词典的创建。
2 程度计算
如果一条弹幕说“好看”,另一条弹幕说“非常好看”,还有一条弹幕说“不好看”,若这3个弹幕的情感值一样,显然是不合理的,因此,需要对弹幕的情感程度进行量化,用以区分不同程度的“好看”。同理,一个人发出撒花的弹幕,如果撒花后面加了感叹号,显然情感强度应该和没加的时候不同。下面给出相关定义。
2.1 情感词程度计算
定义1(程度词)。当情感词前面被程度词修饰时,情感词修正权重的计算规则为:
W=Wdeg*Wk
(3)
定义2(否定词)。当情感词前面被否定词修饰时,情感词修正权重的计算规则为:
W=(-1)n*Wk
(4)
情感词前面同时出现负面词和程度词的情况分为两类,一类是“否定词+程度词+情感词”,这种表达方式对情感强度的影响较弱。另一种是“程度词+否定词+情感词”,这种表达方式对情感强度有增强作用。这两种方式对句子情感权重有一定的影响。例如,“不太好看”和“太不好看”,显然,第一句话的情感强度弱于第二句话。
定义3(程度词+否定词)。当情感词前面被程度词+否定词修饰时,情感词修正权重的计算规则为:
W=(-1)n*Wdeg*Wk*2
(5)
定义4(否定词+程度词)。当情感词前面被否定词+程度词修饰时,情感词修正权重的计算规则为:
W=(-1)n*Wdeg*Wk*0.5
(6)
其中,W是修正以后的情感词情感值,Wdeg是程度词对应的修正系数,Wk是情感词情感值,n为否定词的个数。
2.2 句型程度计算
定义5(弹幕句型)。不同句型的弹幕对应的情感强度各不相同,定义句型影响系数X,X默认为1。
规则1:如果弹幕类型为感叹句,即弹幕里出现了“!”或“!”,X=2。
规则2:如果弹幕类型为疑问句,即弹幕里出现了“?”或“?”,且弹幕中没有出现反问标志词(例如“难道”),X=1。
规则3:如果弹幕类型为反问句,即弹幕出现了“?”或“?”,且弹幕中出现了反问标志词(例如“难道”),X=1.5。
综上所述:弹幕句型修正计算公式如下:
Mi=Si*X
(7)
其中,Mi为经过句型修正之后的第i个句子的情感值,Si为弹幕中第i个句子的初始情感值,X是句型影响系数。
3 弹幕情感值计算
在第一章构建好情感词典和第二章确定程度计算规则的基础上,下面对弹幕的情感值进行计算。
3.1 句子情感值计算公式
Si=∑W+∑Em
(8)
其中,W是修正后的情感词的情感值,Em是颜文字表情的情感值,Si是弹幕中第i个句子的情感值。
3.2 弹幕情感值计算公式
设弹幕的最终情感值为C,最终弹幕情感值C的计算公式如下:
C=∑Mi
(9)
如果C>0,则将这条弹幕判定为积极的弹幕;如果C=0,则将这条弹幕判定为中性的弹幕;如果C<0,则将这条弹幕判定为消极的弹幕。
4 实验分析
4.1 实验数据
文中爬取了哔哩哔哩网站动画,番剧,音乐,舞蹈,科技,生活,鬼畜,娱乐,影视,放映厅等10个类别里截止2018年3月30日近期热度最高的前三个视频的弹幕数据,共获得30个视频的63 006条弹幕。通过对这些弹幕进行预处理,去除完全由标点符号构成的噪音弹幕之后,得到高质量的弹幕文本数据。从每个类别的弹幕里面随机选取100条弹幕,共选取1 000条弹幕作为测试数据。通过人工标注测试数据的情感极性,将测试数据标注为积极、中性、消极三种类别。最终标注的测试数据类别统计情况如表4所示。

表4 弹幕测试数据统计
4.2 实验性能评估指标
文中采用在自然语言处理领域被广泛认可和使用的准确率(precision)、召回率(recall)以及F值作为实验性能的评估指标,分别定义如下:
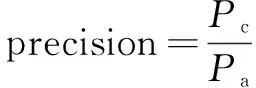
(10)
其中,Pc表示判断正确的该类别弹幕数量,Pa表示判断为该类别的弹幕数量。

(11)
其中,Rc表示判断正确的该类别弹幕数量,Ra表示应该判断为该类别的弹幕数量。
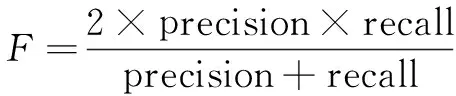
(12)
4.3 实验结果与分析
为了验证文中提出的表情和语气对情感分析的影响以及EMBA方法的有效性,通过表5中的方法对测试数据进行了测试,六组实验的实验结果如表5所示。
通过以上6组实验,对实验结果进行如下分析:
(1)现有的方法[6]采用大连理工情感词典作为基础情感词典对弹幕进行情感分析,实验一和实验二将大连理工情感词典与BonsonNLP情感词典进行比较。一方面,大连理工情感词典的情感词是情感色彩鲜明的传统情感词,所以准确率更高;另一方面,因为弹幕网络用语较多,用语不规范的特点,大连理工情感词典错误地将大量积极和消极弹幕分类成了中性弹幕,正确识别的弹幕数量很少,这导致了积极和消极弹幕召回率和F值低于BonsonNLP,而中性弹幕的召回率达到了100%。实验结果表明,基于网络文本构建的BonsonNLP情感词典在性能上优于基于传统文本构建而成的大连理工情感词典。

表5 实验结果
(2)对比实验二和实验三的结果可以发现,在增加了表情词典之后,情感分析的各项指标都得到了显著提升,对数据进行分析发现,在加入了颜文字表情词典之后,对于“⊙▽⊙”“(:3[▓▓]”等表情弹幕可以正确分类,从而提高了情感分析的准确度。实验结果证明了颜文字表情对于弹幕情感分析的影响,也说明了构建颜文字表情词典的必要性。
(3)通过对比实验三和实验四的结果可以发现,在增加了语气词典之后,情感分析的各项指标都得到了一定的提升,这说明语气词也有助于对弹幕的情感分析。对数据进行分析发现,在加入了语气词典之后,对于“冲呀”“嗷嗷”等弹幕,可以通过识别其中的语气词进行正确地分类。实验结果证明了语气词对弹幕情感分析的影响和构建弹幕语气词典的重要性。
(4)现有的对弹幕的情感分析研究较少,且运用情感词典对弹幕进行情感分析的方法较为简单,实际情感分析的效果较差。文中选用在微博文本情感分析领域具有影响力和代表性的ESD方法[16]作为对比方法。ESD方法的核心是通过拓展情感词典并结合语义规则对微博文本进行情感分析,与文中方法的相同之处在于都选用了现有的情感词典组成基础词典;都构建了程度词典,否定词典,表情词典,网络词典;都分析了语义规则的影响。不同点在于文中构建了能识别颜文字表情的表情词典;利用SO-PMI算法构建了弹幕领域词典和弹幕语气词典;利用输入法词库构建网络词典,而不是人工搜集网络词汇。实验五和实验六的结果表明,提出的EMBA方法在各类弹幕的性能上都优于ESD方法,这证明了EMBA方法的有效性和实用性。
5 结束语
对弹幕进行精准情感分析的关键在于情感词典的构建,情感词典囊括的情感词范围越大,准确性越高,情感分析的效果就越准确。文中构建了一种新的基于表情和语气的情感词典用于弹幕情感分析,该词典由基础情感词典、弹幕领域词典、弹幕语气词典、程度词典、否定词典、网络词典组成。该方法针对弹幕评论中颜文字表情的大量使用情况,提高了情感分析的准确率,同时考虑了语气词的作用,增强了弹幕情感分析的效果。同时,还研究了语义规则对于弹幕情感分析的影响,实验结果证明了该方法的有效性。
