一种用于视频推荐的基于LDA的深度学习模型
2020-08-12崔宗敏
程 涛,崔宗敏,喻 静
(九江学院 信息科学与技术学院,江西 九江 332005)
0 引 言
随着通讯技术与大数据产业的高速发展,信息资源在网络中以指数爆炸式增长的同时,信息载体携带的信息量也逐渐增大。其中作为人们常见的信息媒体之一,视频已成为人们消遣娱乐的主要方式。如今,抖音、B站、爱奇艺等视频业务蒸蒸日上,视频资源也日益增多,用户开始困于无法在短时间寻找到自己喜爱的视频,他们迫切需要一种既可以节约时间又可以向他们进行个性化视频信息推荐[1-2]的推荐系统。为此,视频推荐系统以其独特的解决视频信息过载[3]的能力开始渐渐地走入了人们的生活,在近几年也受到了越来越多的重视。
传统的视频推荐方法主要包括协同过滤[4-5]、基于内容的推荐方法[6]和其他混合推荐方法[7-8]等,其中协同过滤是目前应用最为广泛的推荐算法,然而由于经典的协同过滤方法采用浅层模型,其无法学习到用户和项目的深层次特征[9]。比如在现实生活中,用户的兴趣和视频的属性总存在着大量交互关联,拥有“漫威”兴趣属性的用户喜欢看拥有“漫威”属性的视频。倘若能考虑到这些丰富的关联,将大大提高视频推荐系统的性能,然而目前提出的方法[10-12]都是通过计算向量的距离,矩阵分解,文本分析等方法进行相关的视频推荐。它们都更多关注于通过改进距离计算和矩阵分解提高推荐效果,大多忽略了交互关联的潜在作用。
考虑类似属性的传统算法便是基于内容的推荐方法[13],通过自动分析视频内容提取的视频视觉特征,提出了一种新的基于内容的推荐系统[14]。通过从候选视频的标题中提取的关键字与目标词进行比较,提出一种基于视频标题的视频推荐系统。这些方法主要通过用户观看过的视频属性为其推荐其他具有类似属性的视频,其依赖于人工设计特征,需要对视频属性特征进行有效的提取,是一种依赖于人工设计特征传统的浅层模型,因此其有效性和可扩展性非常有限。
作为人工智能的一个热潮,深度学习于近几年在图像处理、自然语言理解和语音识别[15-16]等领域取得了突破性进展,为个性化推荐的研究带来了新的机遇。深度学习常见的模型包括玻尔兹曼机、RNN、LSTM,以及[17]提出的MLP和GMF等通过将不同的数据映射到一个相同的隐空间,使其具备能够获得数据的统一表征的能力,因此,基于深度学习的融合传统推荐方法能够有效利用多源异构数据[18]对用户进行个性化推荐,缓解传统推荐系统中存在的数据稀疏和冷启动问题。当然,目前常用的深度学习模型也存在花费巨大和依赖大数据的问题,当需表征得数据过大时,会面临训练耗时延长等问题。
为了解决上述问题,文中结合传统的基于LDA模型[19]的视频推荐算法和当下火热的深度学习,充分利用用户兴趣和视频丰富属性间的关联,使用视频LDA主题模型对视频的丰富属性进行聚类,从而降低数据维度以减少深度学习的负担,然后基于近期提出的神经协同过滤框架[17]进行建模训练从而得到推荐结果。
1 LDA模型
LDA(latent Dirichlet allocation)是2003年由David Blei等提出的一种文档主题生成模型[20],也称为一个三层贝叶斯概率模型,包含词、主题和文档三层结构。它是利用先验分布对数据进行似然估计并最终得到后验分布的一种方式,如式(1)所示:
P(Word|Document)=P(Topic|Document)*P(Word|Document)
(1)
对每一篇文档,从主题分布中抽取一个主题,然后从上述被抽到的主题所对应的单词分布中抽取一个单词,这样重复上述过程直至遍历文档中的每一个单词。其生成方式为首先从Dirichlet分布α中取样生成文档的主题分布θm,从主题的多项式分布θm中取样生成文档m第n个词的主题Zm,n,然后从Dirichlet分布β中取样生成主题Zm,n对应的词语分布∅m,n,最后从词语的多项式分布 ∅m,n中采样最终生成词语Wm,n。
2 LIVR模型
众所周知,每个视频都有相当多的文档信息,比如介绍信息以及评论信息等,倘若将这些相关信息看作一个整体的文档,便可以通过LDA主题模型,获得每个电影文档的主题-概率分布,然后可以利用这些概率预测每个视频的主题属性,从而根据用户历史观看数据预测出用户感兴趣的主题。首先进行对数据的爬取,通过对这些数据的处理构建训练样本以及相关词典。对于爬取的视频信息文本文档,先进行jieba分词,并将分词结果作为语料进行LDA模型训练。然后通过视频LDA训练结果预测出用户的兴趣主题集和视频的属性主体集,再基于神经协同框架将用户/视频与他们相关主题属性进行建模,通过对两种模型的结合,便构成了LIVR模型。最后,只需用户的隐式反馈便可以训练出最优模型,从而对用户生成推荐列表。
2.1 视频LDA模型
传统的基于LDA模型的文本分析方法中,比如用于微博的文本分析方法,其常是单纯的进行语料爬取,然后将语料经去停用词和分词后直接进行LDA训练得到文档-主题概率分布。考虑到所有视频的信息文档都具有视频媒体类的特征,传统方法可能会把《钢铁侠》和《生化危机》聚为一类即视频类,因为它们的信息文档中都存在大量的视频类的特征词,诸如“主演”“导演”“演员”等等。并且尽管jieba有着新词识别能力,但是一些关键的特征词诸如“美国队长”可能会被分成“美国”和“队长”,这样将严重降低分词的正确率。为了提高聚类效果,在传统的基于LDA模型的文本分析方法的基础上,引入了视频词典和干扰词典进行改进视频文档的聚类效果。
定义1(视频词典):由所有视频的标题属性和爬取的输入法中的影视词汇构成的词典定义为关键词典,记为Udic。
定义2(干扰词典):由所有会影响到聚类效果的词汇定义为干扰词,记为Iw∈Iws,Iw构成的词典定义为干扰词典,记为Iws。
定义3(特征词):将视频整体文档D中具有实体意义的词定义为特征词,记为Fw,所有Fw构成的集合定义为特征词集,记为Fws。
根据以上定义,将一个视频的整体文档中的标题属性和所有的关键属性诸如导演、演员、标签等直接作为这个视频的特征词Fw,通过对视频的文本属性进行去干扰词和视频词典的验证,可以将每个视频的特征词词集描述为:
Fws=(Jb-Jb∩Iws)∪At
(2)
其中,Jb为导入视频词典后的jieba分词结果,At为相关关键属性集合。
2.2 构建主题兴趣集和主题属性集
通过视频LDA模型,可以预测出每个视频的视频-主题概率分布,进一步将其描述为一个矩阵VT:

(3)
将该视频的每个主题预测的概率作为该主题所占的属性主题权重,然后通过设置阈值s,从视频的所有主题中挑选出概率大于s的主题构成这个视频的属性主题集ATS(Attribute-Tfs),若ATS为空则取前3个主题。
然后可以利用用户的观看历史构建的交互视频集IFVs和视频-主题矩阵VT预测出他的主题兴趣集ITS(Interest-Tfs)。首先根据用户观看过的所有视频记录,利用式(4)计算出用户偏爱的兴趣主题权重。
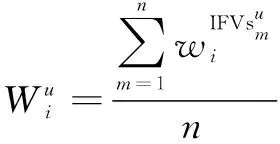
(4)

2.3 生成推荐列表
利用神经协同过滤框架对用户/项目和视频LDA模型预测的ITS和ATS进行建模训练,考虑到要想建模用户/视频和它们的主题属性之间的成对关联,以及它的属性之间的所有嵌套关联,最常用的便是神经网络建模中的池操作,因此,决定使用文献[21]提出的pairwise-pooling操作进行建模。如式5建模用户u和他的兴趣主题集ITS的成对关系,其中u',ITSu'为用户,用户兴趣主题集的K维嵌入量,|ITSu|为兴趣主题集的长度,⊙表示两个逐元素相乘。同理,如式6建模视频v和他的属性主题集ATS的成对关系。
pariwise(u,{ITSu})=
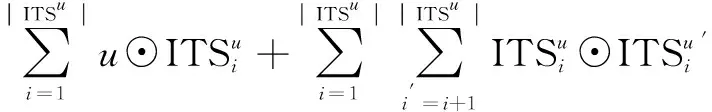
(5)
pariwise(v,{ATSv})=
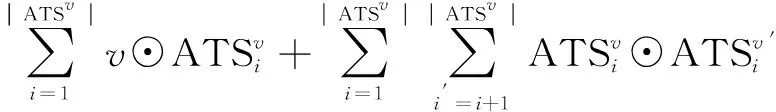
(6)
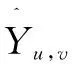

(7)
E1=σ1(W1(pairwise(u,ITSu)⊙pairwise(v,
E2=σ2W2σ1+b2
……
El=σl(Wlσi-1+bl)
(8)

3 实验检测
3.1 实验数据与测试模型
爬取了豆瓣电影网中的1 204部电影的相关信息,966个用户,96 255条评分记录作为实验数据集。然后对爬取到的评论与简介信息进行传统LDA方法中的同义词处理,将中文常用的比如”黄渤”改为“黄勃”,“周星弛”改为“周星驰”,使用python的gensim库进行LDA模型训练,通过评估perplexity来确定最优主题个数为K=30,通过预测样本的主题兴趣集和主题属性集构成神经网络的样本集。然后对样本集随机取70%作为训练集,30%作为测试集,并在python中使用Keras深度学习框架进行神经网络的训练。最后通过对比传统深度学习模型MLP(多层感知机)和GMF(广义矩阵分解),对三种方法进行评估与分析。
3.2 实验性能评估指标
使用离线实验方法进行评测,最终结果取3次实验数据的平均值。评价指标选用准确率、召回率和F值。召回率描述有多少真正产生过行为的物品包含在最终的推荐列表中,计算公式为:
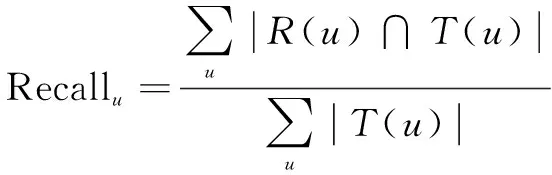
(9)
准确率描述最终的推荐列表中包含多少真正产生过行为的物品,计算公式为:
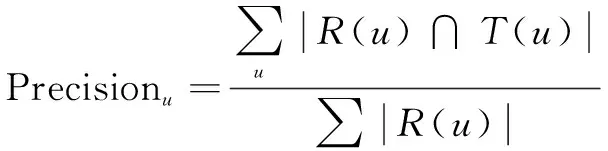
(10)
F值是准确率和召回率之间的调和平均值。用户u在测试集合上产生过行为的物品记为T(u),计算公式为:
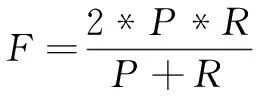
(11)
3.3 实验结果与分析
图1为在推荐视频个数K=10,LIVR模型的LDA主题个数为30时,不同模型随迭代次数的增加F值的变化曲线。
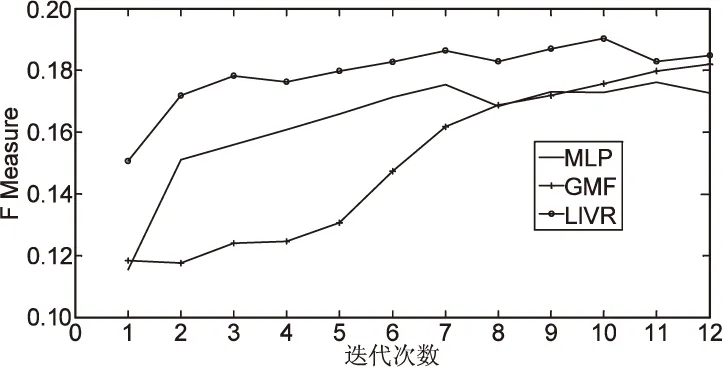
图1 F值变化曲线
从图1可以看出,随着迭代次数的增加,LIVR性能的改善速率虽然没GMF以及MLP快,但两种模型在前10次迭代过程中均远远落后LIVR,且LIVR在第10次时最快迭代时达到最优,即使是10次迭代之后仍处于优势,其中可以看出,由于过拟合的原因,添加了隐层的LIVR和MLP在第8次迭代后的准确度和召回率都开始下降。关于过拟合问题,可以通过正则化[22]缓解,这里就不再累述。而GMF的准确度和召回率仍处于上升阶段,但是这并不能说明MLP和GMF的回归表现比GMF差,因为这里展示的只是具有3层隐层的MLP和LIVR。
图2~图4分别表示各方法随着K的变化precise、recall和F值的变化。可以看出,在三种模型中,随着K的增大,LIVR在三种评价指标下都明显处于上风,通过图中MLP与GMF的表现比较,MLP较GMF的三种评价指标都低,但是这并不能说明MLP的比GMF的表现差,因为MLP模型可以通过添加更多的隐藏层来进一步改进,值得一提的是,LIVR同样具有MLP的这个特点。
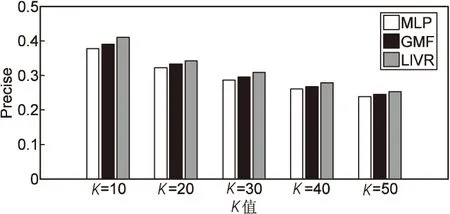
图2 precise的比较

图3 recall的比较
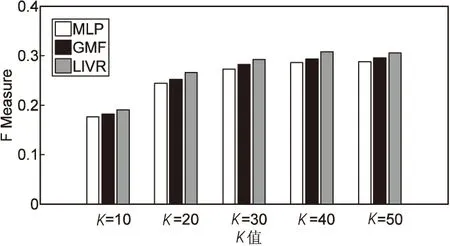
图4 F值的比较
从三种方法的对比中可以看出LIVR表现最好,这都归功于隐藏层前使用了poolingwise操作,充分地对用户/视频与视频LDA主题模型的预测主题集的相关性建模。由图可以看出,与其他两种方法相比,LIVR在训练阶段准确率和召回率上都有很大的提升,对比准确率和召回率之间的调和平均值,相比于MLP模型,LIVR大约提升1.9%,相比于GMF,大约提升1.1%。值得一提的是受干扰词的影响,LIVR样本仍存在些许脏数据,然而样本的数据质量是可以通过人工标记进行进一步改善的,LIVR效果也可以得到进一步的提升。
4 结束语
针对如何利用现实生活中用户和视频间丰富的属性关联提高推荐系统性能的问题,提出了一种基于LDA主题属性感知深度学习模型。通过构建的LDA视频模型对视频进行聚类,从而预测出用户与视频的相关主题属性,并利用pooling-wise操作改进的神经协同框架进行学习。最后通过实验验证,该模型在一定程度上在神经协同框架传统模型上提高了推荐质量。面对日益增多的视频文档信息,用户与视频数据量的急剧增加,首先考虑到模型的扩展性问题,当文本数据量达到一定水平时,模型聚类效果将渐渐降低,因此下一步的重点是解决系统的扩展性问题。
