不完整数据聚类算法研究
2020-08-12冷泳林孙晓红
冷泳林,孙晓红
(1.渤海大学 信息科学与技术学院,辽宁 锦州 121000;2.渤海大学 管理学院,辽宁 锦州 121000)
0 引 言
电子政务是国家机关在政务活动中,应用信息、网络和办公自动化技术进行办公、管理和为社会提供公共服务的一种全新的管理模式。电子政务系统产生的数据除了具有海量、异构和实时等特性,还具有价值密度低的特性[1]。具体地说,表现为采集数据中具有大量不正确、不精确、不完全、过时陈旧或者重复冗余的数据。其中以不完全特性表现的尤为突出。导致电子政务中数据缺失的原因包括数据采集终端的智能化,如传感器发生错误时导致数据不能被采集到,网络传输故障或人为因素造成的采集错误或漏填等[2-3]。
由于缺失数据的存在,给决策者的数据分析及公民数据参考都带来了巨大的挑战。聚类是一种无监督的数据挖掘算法,该算法依据数据间的特点将数据划分成不同的类,使得类别内的数据相似性较大而类别间的数据相似度较小[4]。针对不完整数据集,传统方法都是采用数据填充或丢弃缺失数据对象的方式构成完整数据集后再进行聚类。而数据填充或丢弃缺失数据对聚类结果有极大的不确定性,影响聚类精度[5]。
针对以上问题,文中提出一种基于KNN的不完整数据AP聚类算法(IAPKNN)。算法首先利用近邻传播(affinity propagation,AP)聚类算法对数据集中的完整数据进行聚类[6],然后利用KNN思想将完整数据集中的吸引度矩阵和归属度矩阵扩展至整个数据集,继续迭代,直至收敛[7]。
1 基于区间划分的相似度度量方式
计算数据对象间的相似性是数据聚类的重要前提,对于完整数据,可以使用欧几里距离、马氏距离,余弦相似度等方法计算对象间的相似性[8]。但这些传统的度量方法都不适用于不完整数据。另外,在不完整信息系统理论中[9],当任意两个数据对象的所有属性值已知并且对应的值不相等时,它们之间的相似性就为0。很明显,这是不符合数据对象的相似度规律。针对以上问题,文中重新定义了连续数值型和分类型数据的相似性度量方法。
1.1 归一化处理
为了消除因为属性取值范围不同所产生的不平衡性,需要将所有的属性值归一化到一个确定的数值范围内,使不同的属性拥有相同的权重值[10]。文中采用标准方差来归一化属性集中的连续特征值。设数据集中每个属性的完整对象数目为q,其中每个数据对象oi由m个属性{a1,a2,…,am}组成的m维空间的特征向量{ai1,ai2,…,aim}来描述。则数据集中所有向量的属性值的均值和方差分别为:
(1)
(2)

(3)
通过以上处理,去掉了数据对象中各属性之间的量纲,使数据对象服从N(0,1)的正态分布。下一步式(5)通过max-min方法将数据归一到[0,1]之间的连续值:
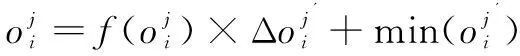
(4)
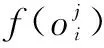
(5)
(6)
至此,完成数据的归一化处理。
1.2 连续数值型数据
对于连续数值型数据,文中提出了一种基于区间划分的相似性度量方法。假设属性aj是一个数值型属性,其值域范围是[x,y]。设avg(aj)为属性值aj的平均值,则avg(aj)∈[x,y]。定义α和β是两个相似度的度量系数,它们取值如下:
(7)
对于数据集O中任意两个数据对象o1和o2,它们在属性aj下取相同值的概率定义如下:
(8)
其中,|Vj|表示属性aj所包含的不同元素的个数。由于数值型数据的连续性,在真实的数据集中,|Vj|的取值非常大,1/|Vj|的取值则非常小。为了解决这种问题,文中采用离散化的方法将连续数值型数据转化成离散值,|Vj|就可以表示离散后类别数目,用Dc表示。
常用的离散器有比例离散器(proportional discretizer,PD)和固定频率离散器(fixed frequency discretizer,FFD)[11]。用Dc和Dr表示离散器中所包含类别数目和每个类别中所包含的数据数目。则Dc和Dr满足DcDr=n。在比例离散器中满足Dc=Dr=在固定频率离散器中,Dr可以根据实际情况自己设定,Dc=「n/Dr⎤。图1给出了PD和FFD离散器在连续数值型属性a下的离散结果。数据集中共包含16个数据对象,在比例离散器中,Dc=Dr=4。设固定频率离散器中Dr=2,则Dc=8。理想的离散结果应满足:
(1)同一离散类别中的离散数据相近;
(2)不同类别间不能存在相同数据。
但由图1可以看出,比例离散器不满足条件(1),而固定频率离散器不满足条件(2)。为此,提出了一种等步长离散器(equal step length discretizer,ESLD)。
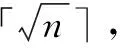
(9)
则属性a的第i个对象的离散后所对应的类别为:
(10)

图1 三种离散器原理
1.3 分类型数据
分类型数据通常代表数据的分类,数据之间不存在大小关系。假设属性b对应的是分类型数据,用|Vb|=n表示属性b中分类型数据的分类数。两个数据对象o1和o2,它们在属性b下取相同值的概率定义如下:
(11)
依据上述定义,在不完整数据集中,度量两个对象的相似性可以使用式(12):
(12)
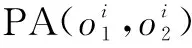
2 基于KNN的不完整数据聚类算法
2.1 矩阵扩展
对于不完整数据集,如果通过度量数据对象间的相似性后直接聚类,由于缺失数据的存在,聚类的精度必然受到影响。文中采用两步聚类的方式,提高不完整数据的聚类精度。首先,采用传统的AP聚类方法在完整数据集上执行聚类,获得完整数据集的吸引度矩阵和归属度矩阵。然后依据K近邻思想,将吸引度矩阵和归属度矩阵扩展到不完整数据空间,然后继续迭代整个数据集,直到聚类收敛,完成整个数据集的聚类[12]。
AP在聚类完整数据集后,完整数据集中的每个数据对象已经累积了一些支持,即通过迭代的消息传递,吸引度矩阵和归属度矩阵中的元素已经是非0元素。当将矩阵扩展到不完整数据集时,两个矩阵中不完整数据对象间,不完整数据与完整数据对象间的吸引度和归属度都为0。如果直接进行消息传递,即使不完整数据中存在适合条件的聚类中心,也很难在迭代中找到它。基于此,采用KNN来扩展不完整数据对象的吸引度矩阵和归属度矩阵,即不完整数据对象与其k个近邻,不仅在聚类时更容易聚到一类,而且它在吸引度矩阵和归属度矩阵中对应的元素也与这k个近邻接近[13]。
给定吸引度矩阵Rt和归属度矩阵At,对于任意不完整数据对象Ii',其中t+1≤i'≤t+p,其k个近邻为KNN(Ii')={cq1,cq2,…,cqk},其中1≤q1,q2,…,qk≤t,则不完整数据的扩展矩阵Rt+p如式(13)所示:
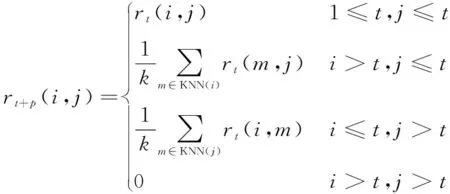
(13)
同理,归属度矩阵At+p可以描述如下:
(14)
2.2 基于KNN的不完整数据AP聚类算法
文中提出的基于KNN的不完整数据AP聚类算法主要包括以下几个步骤:
(1)将数据集O划分为完整数据集C与非完整数据集I,即O=C∪I。
(2)将C中所有数据对象的数值型属性值进行归一化处理。
(3)根据式(7)~式(12)计算数据集C中数据对象的相似度矩阵S。
(4)将C中吸引度矩阵R和归属度矩阵A的所有元素设置为0,根据AP聚类算法更新吸引度矩阵R和归属度矩阵A。
(5)直到聚类中心不再发生变化,或者已经完成了指定的迭代次数后,停止计算,否则重复。
(6)根据式(13)和式(14)扩展吸引度矩阵R和归属度矩阵A到不完整数据集I。
(7)继续迭代。
(8)对角线的值a(k,k)+r(k,k)>0的数据点k为自动发现的聚类中心,而对于数据点i,使其a(i,k)+r(i,k)最大的候选类中心为其真正归属的聚类中心。
(9)将非聚类中心数据分配到与其相似度最大的簇中心。
2.3 参数k的确定
参数k的取值,将影响不完整数据对象在吸引度和归属度矩阵中元素的取值。如果k的取值过小,意味着扩展矩阵元素取值的参照范围太小,其准确性将降低,如果取值过大,而混淆各子类间属性特征,也很难得到正确的估算结果。实验表明,在不同的数据集中k的取值也不是固定的。因此,文中在不完整数据聚类过程中增加了一步k值的预测模型,确定k的最佳取值[14]。
前文已经利用AP聚类算法在完整数据集C上执行聚类得到吸引度矩阵和归属度矩阵。对于该完整数据集C,随机从中选择一定比例的数据对象,计算当k的取值为2,3,…时,根据式(13)和式(14)计算这些对象所对应的吸引度矩阵和归属度矩阵元素估计值。然后将这些估计值和实际值进行比较,如果估计值和实际值小于阈值γ,则认为估计值是准确的,反之是不准确的。当k的取值不同,得到的估计准确率也不同,文中取估计值准确率最高时k所对应的值作为最近邻k的取值。
3 实验分析
3.1 数据集及环境设置
文中选择3个UCI标准数据集来验证提出算法的有效性,数据集描述如表1所示。UCI数据集中IRIS的数据属性是连续的数值型数据,而Heart和Abalone中既包含连续数值型数据也有分类型数据。在实验过程中,为了验证算法的性能,分别对每一个缺失率和数据集重复5次实验,并取5次实验的结果的平均值作为最终实验结果。

表1 数据集描述
为了比较聚类精度,并没有直接采用不完整数据集做实验,而是通过删除部分完整数据集中的数据对象方法来构成不完整数据集。数据的删除规则遵循下列两条[15]:
(1)每个不完整数据对象至少一个属性值是已知的;
(2)任意属性在数据集中至少保留一个完整值。
实验硬件环境为:Inter Xeon CPU@2.00 GHz×24 CPU处理器,20 GB内存和1 TB硬盘。软件环境为Linux操作系统,Java编程语言。
对原始数据集O中的数据,按缺失比例为0%、5%、10%、15%、20%、25%的情况将每个数据集生成6个不同的数据集。为了验证文中提出的不完整数据聚类算法的性能,进行如下的三组实验。
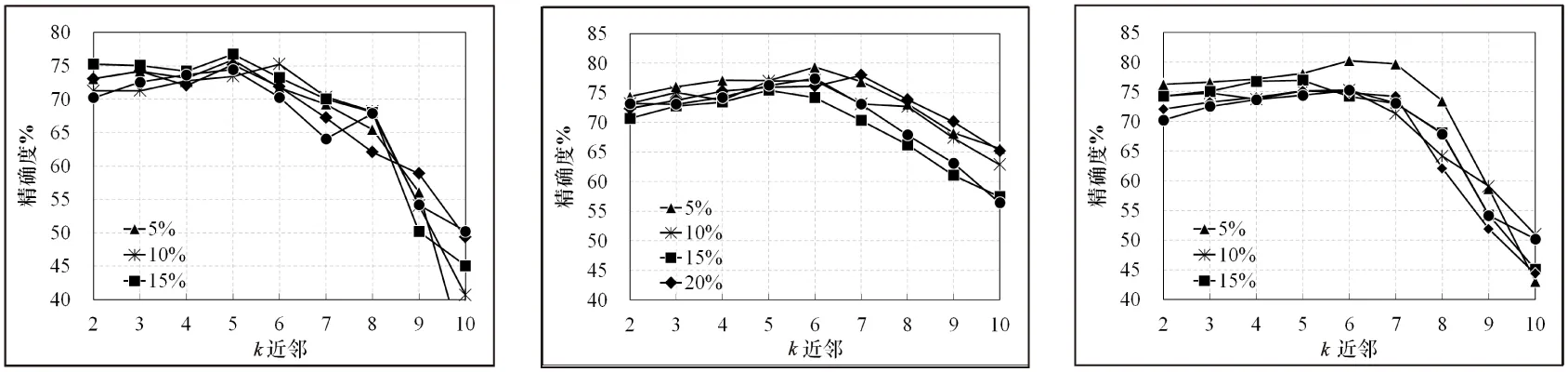
3.2 k的取值对扩展矩阵精度的影响
前文2.3中阐述了k的取值策略,本部分检验了k的取值为2~10时将扩展矩阵中去掉5%~25%元素时,根据式(13)和式(14)得到的扩展矩阵估计值的准确率。从图2中可以看出,对于IRIS数据集,当k的值在5或6时,扩展矩阵准确率最高,而Heart,Abalone的最高准确率均出现在k的取值是6或7时。文中依据此在后续实验中取k值的最好效果进行实验。
3.3 不完整数据聚类算法验证
为了测试文中提出的不完整聚类算法的聚类精度,将算法应用在数据集P、不完整数据集C+I和不完整数据集中的完整数据子集C上进行聚类。聚类精度使用如下公式描述:
(15)
其中,ωk表示聚类后的第k个集合,Cj表示数据真实分类的第j个集合。
图3显示了在不同缺失率下对几种数据集进行聚类的结果。其中IAPKNN-AP是执行在原始没有缺失的数据集P上的聚类精度,多次聚类结果相同,说明IAPKNN聚类算法在完整数据集上具有稳定性。在对完整数据子集C进行聚类时,由于不同缺失率下数据集C是不一样的,因此聚类结果也不相同。但其在数据集P的聚类结果上下浮动,有时数据缺失率高,聚类精度反而高。分析其原因是当删除的缺失值所对应数据集是数据集中造成负面影响的离群点时,IAPKNN对数据集C进行聚类时,受这些离群点的影响减小。因此,此时对数据集C的聚类精度高于对原始数据集P的聚类精度。反之,将低于对原始数据集P的聚类精度。在对不完整数据集C+I进行聚类时,由于受到非完整数据集I的影响,从整体上看,IAPKNN的聚类精度都低于对原始数据集P和完整数据子集C的聚类精度。而且数据缺失比率越高,聚类准确度越低。
3.4 IAPKNN同其他聚类算法的比较
本部分将所提出的不完整数据聚类算法IAPKNN同KNNI-AP和KNNM-AP聚类算法在聚类精度上进行了比较。图3表明,提出的IAPKNN算法在聚类精度上要优于这两种算法,其原因在于,首先KNNI-AP在计算对象相似度时忽略缺失属性,考虑对象中已有的属性信息,如2.3所阐述的,将影响k近邻的精度。而文中在确定对象k近邻时,采用概率的方法将缺失属性加以考虑,提高了k近邻的准确性。其次,KNNM-AP算法先用k近邻的均值进行缺失数据的填充,然后再聚类。而本身数据填充算法在填充精度上存在一定误差,即k近邻均值不能准确无误地表示出缺失数据,鲁棒性较差,再在填充数据集上进行聚类,聚类精度更低。
(a)IRIS (b)Heart (c)Abalone

(a)IRIS (b)Heart (c)Abalone
4 结束语
电子政务数据采集过程中,由于硬件、网络稳定性、隐私等问题不可避免地在数据采集过程中发生漏采集、传输丢失、漏填写等问题,进而导致数据的不完整性,阻碍数据分析的精度。文中提出了一种基于KNN的不完整数据AP聚类算法(IAPKNN),该算法不同于传统的先填充后聚类的算法思想,首先将数据集分为完整数据集和不完整数据集,然后针对完整数据集直接利用AP聚类算法。对于不完整数据,首先依据定义的不完整信息系统的数据相似度度量方法,然后利用KNN寻找数据k个近邻,并依据k近邻对不完整数据集的吸引度矩阵和归属度矩阵进行扩展,最后实现AP聚类。实验结果表明,该算法能够有效地对不完整数据进行聚类。
