基于不均衡数据与迁移学习的面部微表情识别
2020-08-05孔慧芳钱世超闫嘉鹏
孔慧芳, 钱世超, 闫嘉鹏
(合肥工业大学 电气与自动化工程学院,安徽 合肥 230009)
0 引 言
微表情是短而不自觉的面部表情,可以在不知不觉中反映出人的内心情绪[1]。因为有助于理解内心自发情绪,微表情研究已在刑侦和商务谈判等领域中发挥重要作用。关于微表情的首次报道出现在1960年的心理学文献中,后续研究逐渐增多[2-3]。文献[4]开发了微表情训练工具(Micro-Expression Training Tool,METT),它可以帮助人们检测微表情。近年来,计算机视觉技术和机器学习算法开始应用到这个领域,这些方法使用手工特征描述子,如局部二值模式 (Local Binary Pattern,LBP)[5]、方向梯度直方图(Histogram of Oriented Gridients,HOG)[6]等来提取特征。文献[7]提出一个识别自发面部微表情的框架,并利用三正交面局部二值模式(Local Binary Patterns from Three Orthogonal Planes, LBP-TOP)描述子来处理动态特征;文献[8]使用六交点局部二值模式(Local Binary Patterns with Six Intersection Points,LBP-SIP);文献[9]使用了时空完成局部量化模式(Spatiotemporal Completed Local Quantized Patterns,STCLQP),这些研究都极大促进了微表情研究,但是手工提取的特征表达能力有限,限制了采用手工特征的面部微表情识别系统的性能[10]。
深度卷积神经网络能够自动提取层次特征的特性使其在许多机器学习应用领域正变得越来越广泛。训练深度卷积神经网络时需要大量数据,但由于微表情图像采集难度大,导致微表情识别模型训练数据不足,常采用迁移学习方法将已训练好的模型参数迁移到新的模型来帮助新模型训练[11]。另外目前对微表情识别的研究主要集中在“中性”、“幸福”、“惊喜”、“恐惧”、“厌恶”、“悲伤”、“压抑”等7个微表情,其中部分微表情区别不明显,各类别的标注难度不一,造成了数据集的类别不均衡[12]。文献[13]探索了深度学习在微表情识别任务中的应用,并提出了一个特征选择框架来区分提取的特征;文献[14]提出一种通过学习具有表达状态约束的时空特征表示来识别微表情的方法。
本文引入预训练网络人脸识别模型VGGFace[15]迁移先验的人脸识别领域知识,即采用VGGFace作为特征提取器从原始图像中提取初级特征,并结合迁移学习方法和数据增强技术在一定程度上减轻数据不足的影响。文献[16]发现在训练中情绪类别不平衡增加了模型预测较大比例类别的倾向;文献[17]首次对微表情识别领域的类别不平衡问题作了研究。类别不平衡也是现有微表情数据集的常见缺陷,是影响微表情识别的不利因素。为此,本文引入聚焦损失函数(Focal Loss,FL)[18]作为目标函数来解决类别不均衡问题。
本文在CASME II微表情数据集[19]上进行的对比实验表明,该方法在类别不平衡处理方面优于传统的微表情识别方法,准确率可达到45.06%,而F1值达到34.57%。
本文研究主要包括以下3点:① 使用端到端的深度卷积神经网络自动提取特征;② 将人脸识别领域的知识迁移到表情识别领域,以缓解数据不足问题;③ 引入FL作为目标函数来应对类别不平衡问题。
1 基于迁移学习的面部微表情识别
本文提出的微表情识别模型总体结构如图1所示,模型由预处理、特征提取、分类3个部分组成。

图1 微表情识别模型总体结构
1.1 预处理
对人脸数据预处理就是在去除背景、头发、衣服等干扰信息的同时,捕获感兴趣的人脸区域进行人脸归一化。人脸归一化包括人脸检测、人脸裁剪、人脸对齐。
首先采用OpenCV[20]内置Haar级联检测器[21]检测和裁剪感兴趣的面部区域;然后利用Dlib库[22]提取用来定位和表示脸部区域的面部关键点[23],如眼睛、眉毛、鼻子、嘴巴、下颌线等。基于这些面部关键点,可以确定基本特征点;最后通过计算人眼质心之间的角度进行人脸比对,应用仿射变换完成头部姿态校正。
完成上述工作后,将所处理图像裁剪为224×224像素,完成几何归一化;然后归一化灰度,提高图像的亮度,使图像细节更清晰,减少光和强度的影响。
1.2 特征提取
本文使用从大型人脸数据集训练得到的人脸识别模型VGGFace作为原域,微表情识别作为目标域,考虑到两者数据和任务的相关性,通过迁移学习将已经学到的模型参数分享给新模型从而加快并优化模型的学习效率[24]。人脸识别中提取的初级特征与面部表情识别提取的初级特征相似,利用VGGFace作为特征提取器与分类器相结合,通过对模型最后一层微调实现微表情分类。各层参数设置见表1所列。
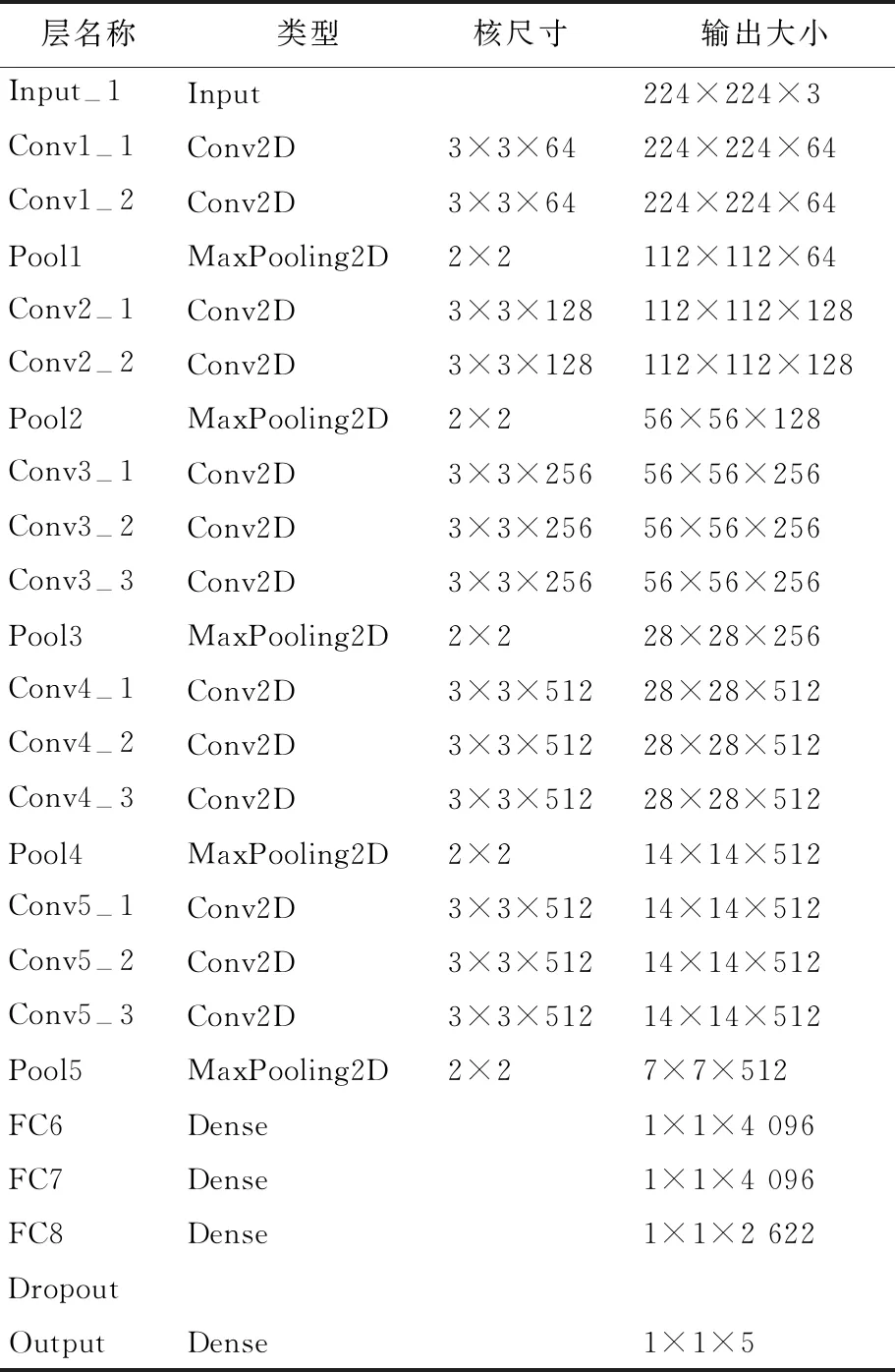
表1 迁移结构参数设置
模型由5个卷积块组成,每个卷积块包括2~3个卷积层、1个ReLU函数激活单元、1个池化层、3个全连接层及1个softmax层,对“幸福”、“惊喜”、“厌恶”、“压抑”、 “其他”等5种情绪进行分类,简称“5分类”。为抑制过拟合,在最后一个全连接层后引入Dropout层[25],比值设为0.3。另外,VGGFace的最后一个输出层被替换为5分类的softmax分类层,并加上L2正则化,比率设置为0.01。训练时冻结Input-1层至FC8层,设置学习率为0,模型需要拟合的所有参数都在最后两层之间。测试时使用留一交叉验证法,最后训练得到26个不同模型。
1.3 分类
本文引入FL提升模型的多类别分类性能。FL起源为二值分类的目标函数交叉熵 (cross-entropy,CE) 损失函数,针对解决目标检测场景下训练集中前景类和背景类类别不均衡的问题,通过配置权重因子和调制参数取得了分类性能的有效提升,本文在处理微表情多分类时将FL从2类分类扩展到多类分类,缓解微表情识别中的类别不均衡问题。
多分类情况下,CE损失函数定义为:
CE(p,y)=
(1)
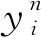
(2)
其中,α为当前样本属于类别i的权重因子,1-α为当前样本不属于类别i的权重因子;γ为调制参数,用于分配对于易分和难分样本的注意力。
2 实 验
2.1 微表情数据集
CASME II数据集由中国科学院心理研究所在CASME数据集[26]基础上改进得到,采样率为200 帧/s,分辨率为280×340像素。数据集包含了从2 500多个面部表情中选出的247个自发的面部微表情,共分为以下5类微表情(括号中数字为样本数):“幸福”(32)、“惊喜”(25)、“厌恶”(64)、“压抑”(27)及“其他”(99)。实验中去除样本数过少的2个类别,即“恐惧”(2)和“悲伤”(7)。
数据集记录了26位参与者的面部微表情,从微表情样本数统计结果可以看出,“其他”的数量几乎是整个数据库统计中“惊喜”、“幸福”及“压抑”的总和。26个采集对象面部微表情组成分布如图3所示。
从图3可以看出,各采集对象含有的类别种类和数量差异较大,这样的不均衡分布在留一交叉验证时产生的不利影响尤为明显。
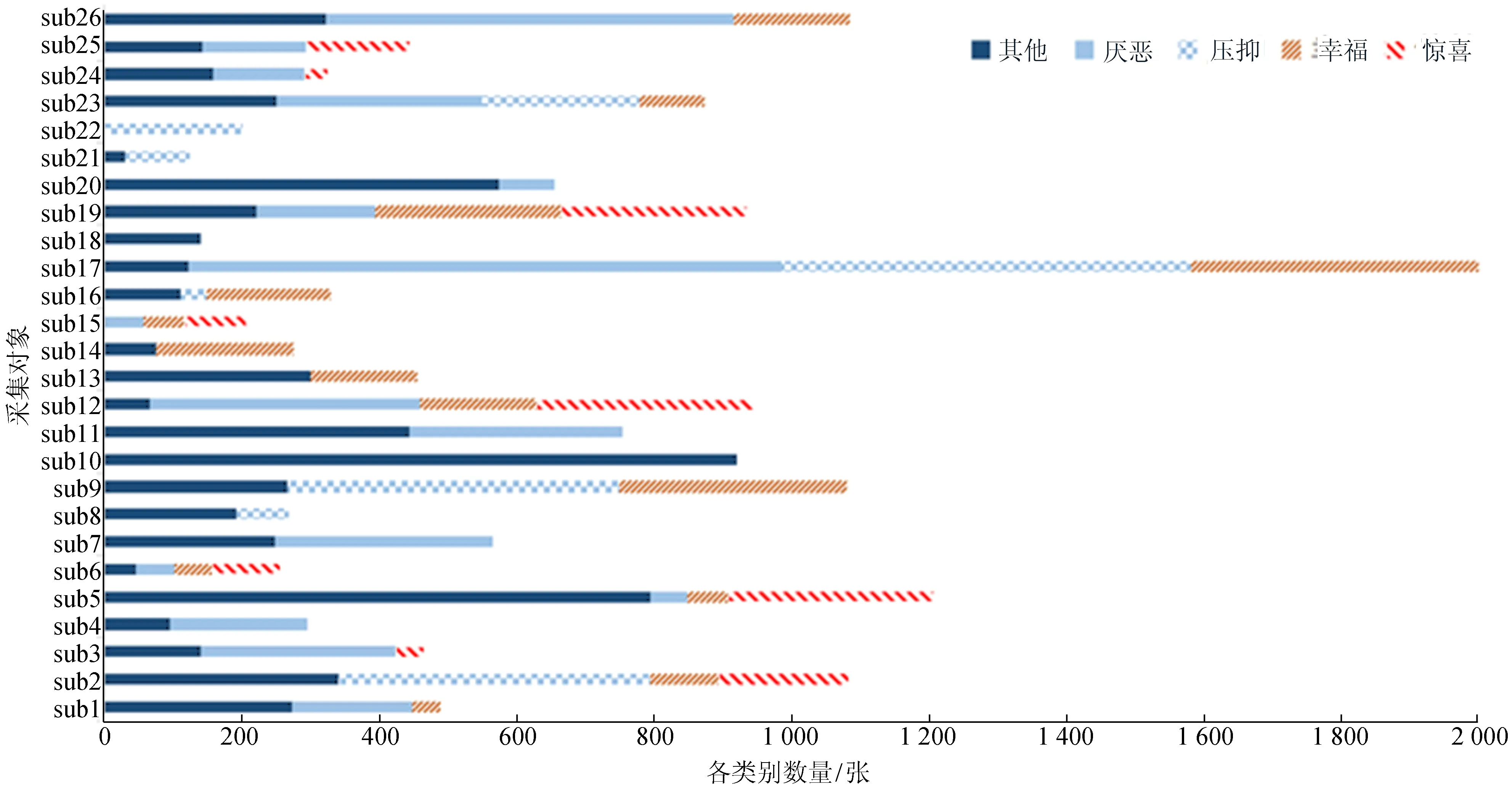
图2 CASME II数据集中26个采集对象面部微表情类别数量分布
2.2 实验设置
实验预处理部分使用OpenCV、Dlib库及基于图形处理单元(graphics processing unit,GPU)的框架Keras(使用Tensorflow[27]后端)完成。所有实验都是使用AMD Ryzen 1700、Nvidia GTX 1070 CUDA及8 GiB的GPU。实验环境为Linux Ubuntu 16.04 LTS、NVIDIA CUDA框架9.0及cuDNN 8.0库。
原始图像大小为224×224,将每个样本均值预处理为0后送入模型,经过卷积、池化、全连接层处理,最后对分类输出层进行处理。初始学习率设为0.000 5,每批次包含32张图片。为防止训练集和测试集中含有同一个对象的数据,本文采用留一交叉验证法,即将每个对象分别作为测试集。对于CASME II数据集,共进行了26个训练-测试过程。
衡量分类器对每个类别的性能时,通常使用F1值(F1-score)、准确率(P)及召回率(R)[26]。文献[17]研究了微表情数据集的类别不平衡性,指出由于分类器很难从数量较少的类中较好地拟合参数,准确性指标可能高度倾向于具有更多数量的类别,因此,F1值更能全面衡量分类器的性能。
F1值、P、R的定义分别为:
(3)
(4)
(5)
其中,tp、fp、fn分别为真阳性、假阳性、假阴性的个数。
分类器总体性能通过对所有类取平均值计算。另外,由混淆矩阵得到的预测精度也是衡量分类器性能的一个很好的指标。
2.3 结果分析
使用留一交叉验证法处理从视频序列中提取的图像帧,进行5种方法的对比实验。
实验1使用手工设置的LBP-TOP描述子提取特征,结合AdaBoost分类器[25]。
实验2首先使用手工设置的LBP-TOP描述子提取特征,然后结合AdaBoost分类器和选择迁移状态机(Selective Transfer Machine, STM)[25]。
实验3使用时域插值模型(temporal interpolation model, TIM)[25]提取时域特征,使用LBP-TOP提取空间特征,结合AdaBoost和STM。
实验4在对VGGFace进行迁移的基础上使用CE作为目标函数。
实验5本文提出的基于端到端的方法,联合应用VGGFace与FL。
5种方法对比实验结果见表2所列。实验1、实验2得到准确率和F1值的最佳结果分别为39.45%、26.09%,实验3考虑时域特征后准确率和F1值分别为43.78%、33.37%;实验4在不考虑时域特征的情况下迁移VGGFace的应用使准确率和F1值比实验1均提高了2%;实验5中不考虑时域特征,迁移VGGFace和FL的联合应用使准确率和F1值比实验1分别提高了6%、8%,比实验3分别提高了2%、1%,获得了更好的性能,并且端到端的方法相对于手工提取特征过程更简洁。

表2 使用留一交叉验证法的对比实验结果 %
另外,实验4只将准确率提升到了41.51%,而F1值的提升也不明显,这是由于CE对所有类的权重是一样的,造成数量较少的类不能很好地学习。而实验5中VGGFace与FL的结合使用提高了准确率和F1值,这是由于FL对数量较少而难以区分的类别增加了更多的权重,使分类器可以更好地学习到较少的类别。
实验4、实验5的平均混淆矩阵分别见表3、表4所列。

表3 实验4使用CE损失函数得到的混淆矩阵 %
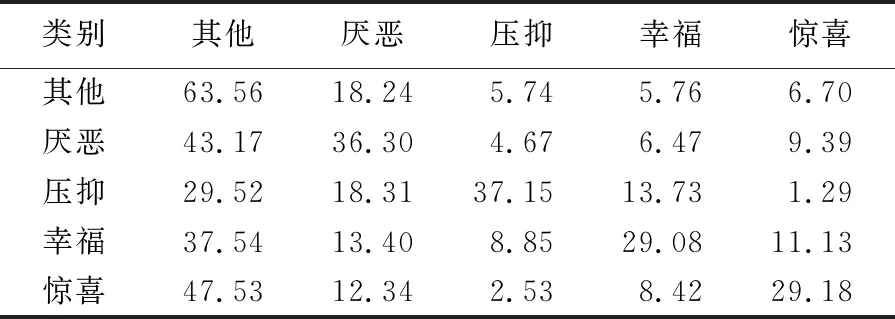
表4 实验5使用FL得到的混淆矩阵 %
在这2个实验中,由于“其他”的样本数较多,其获得的预测精度较高,实验5为63.56%,与实验4的60.69%相比提升了近3%。由于“厌恶”、“压抑”及“惊喜”的样本数较少,在一定程度上更难区分,实验5通过FL改善了预测精度;尤其是样本数最少的类“惊喜”效果最好,在实验5中的精度与实验4的20.57%相比提高了9%。由此可以看出,在微表情识别中,FL可以在不平衡的数据集上获得更好的性能。
3 结 论
本文以VGGFace作为特征提取器,利用端到端的深度卷积神经网络进行微表情识别,引入FL来解决微表情识别领域常见的类别不均衡问题;在CASME II数据集上进行了对比实验,验证了深度卷积神经网络自动提取特征的有效性。实验结果表明,本文方法提高了微表情识别准确率和F1值,取得了分类性能的提升。
